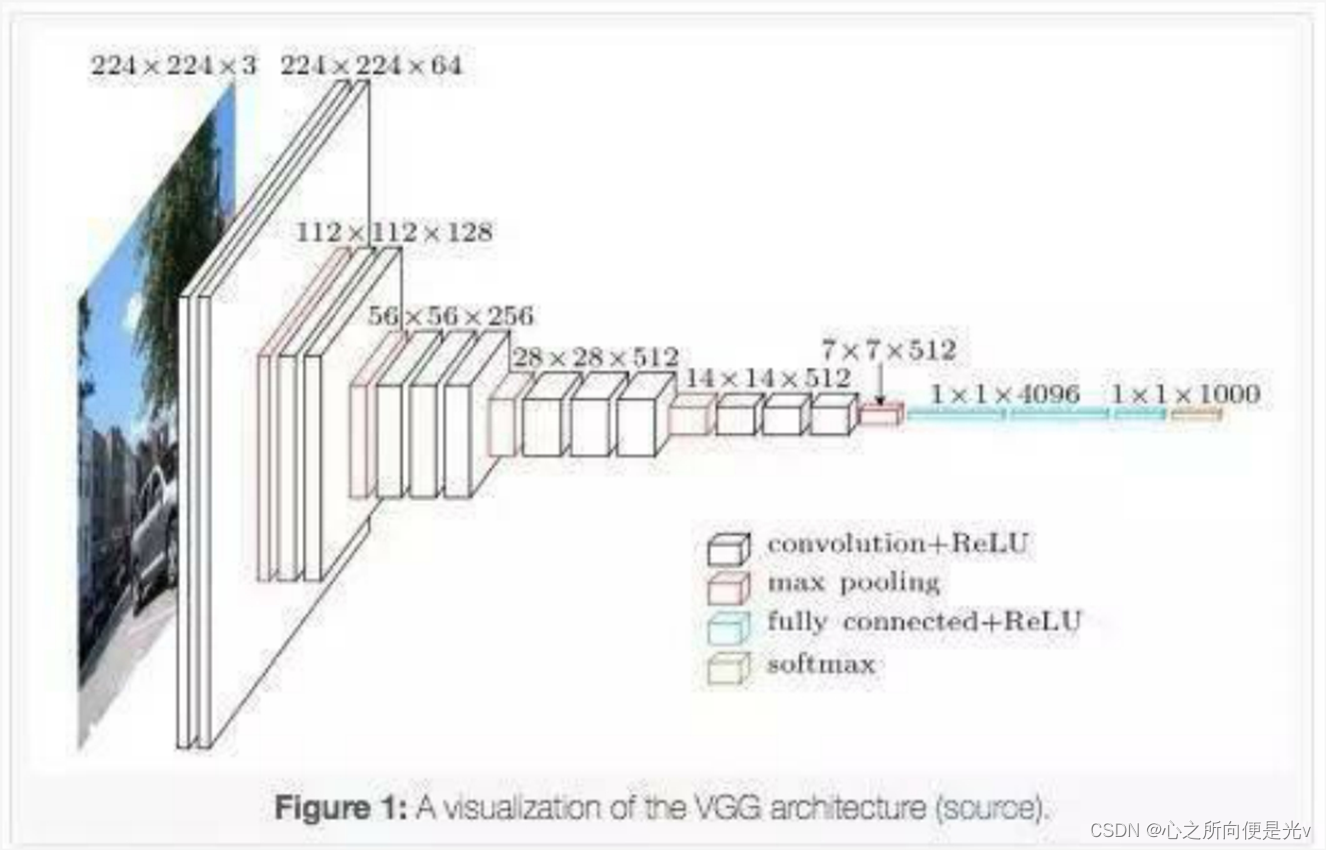
”预训练“ 的搜索结果

预训练是指在大规模数据集上进行的一种先验训练,目标是训练一个通用的模型,在后续任务中进行微调或迁移学习。直接训练的目标是直接优化模型在特定任务上的性能,需要使用特定的标记数据集进行训练。
PyTorch模型加载的时候,有预训练模型,通过使用预训练模型可以给模型使用带来很多的便捷,对于模型的使用以下给出了一些总结,如有错误恳请指正。一、直接加载预训练模型进行训练1、加载保存的整个模型torch.save...
ultralytics / yolov5,官方预训练权重yolov5m.pt,从drive.google下载下来的
预训练网络RESNET pytorch源码,天气数据四分类问题预训练网络RESNET pytorch源码,天气数据四分类问题

14G的中文预训练数据part3
标签: BERT
用于BERT预训练,Bidirectional Encoder Representation from Transformers
由于目标任务的数据规模有限,为防止出现模型训练过拟合现象的发生,对于backbone部分权重参数采用在大规模数据集ImageNet上预训练好的模型权重参数。模型参数加载后冻结部分网络层开展finetune操作。本博文主要讲述...
预训练模型就是一些人用某个较大的数据集训练好的模型 (这种模型往往比较大,训练需要大量的内存资源), 你可以用这些预训练模型用到类似的数据集上进行模型微调。 就比如自然语言处理中的bert。 1 预训练模型由来 ...
什么是预训练模型?

BERT是2018年10月由Google AI研究院提出的一种预训练模型。BERT的全称是Bidirectional Encoder Representation from Transformers。BERT在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上...
知乎—吵鸡凶鸭OvO 侵删原文 https://zhuanlan.zhihu.com/p/446812760本篇文章将介绍神经网络训练过程中的三个必备技能:使用预训练权重、冻结训练和断点...

pytorch中的基础预训练模型和数据集 (MNIST, SVHN, CIFAR10, CIFAR100, STL10, AlexNet, VGG16, VGG19, ResNet, Inception, SqueezeNet)
MobileNet_V1_SSD网络的VOC预训练模型



论文提出了一种点云自回归生成任务来预训练 Transformer 模型。该方法将输入的点云分割成多个点块,并根据它们的空间接近性将它们排列成有序序列。然后,基于提取器-生成器的 Transformer 解码器(使用双重掩码策略...
记住进入transfomer前后数据的维度不会发生变化,把transfomer当作一个黑盒,也就是transformer(X)的维度还是(1,10,768),接下来就是基于它来进行预测了,因为要预测哪个词,词的可能情况就是词表的大小,所以做...
『预训练语言模型分类 』 单向特征、自回归模型(单向模型): ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0 双向特征、自编码模型(BERT系列模型): BERT/ERNIE/SpanBERT/RoBERTa 双向特征、自回归模型“ XLNet 『各模型之间...

将“softmax+交叉熵”推广到多标签分类问题: https://zhuanlan.zhihu.com/p/138117543 SGM https://github.com/lancopku/SGM
并详细介绍自然语言处理领域的经典预训练模型,包括最经典的预训练模型技术和现在一系列新式的有启发意义的预训练模型。然后梳理了这些预训练模型在自然语言处理领域的优势和预训练模型的两种主流分类。最后,对预...

提示:最近在做文本情感分析,实现Electra预训练模型+BiLstm+attention。在github上找了一些代码,很多都是只有一部分,而且Electra预训练模型没有什么可以参考的代码。所以,记录一下学习过程,有错误的点,大家...
推荐文章
- c语言链表查找成绩不及格,【查找链表面试题】面试问题:C语言学生成绩… - 看准网...-程序员宅基地
- 计算机网络:20 网络应用需求_应用对网络需求-程序员宅基地
- BEVFusion论文解读-程序员宅基地
- multisim怎么设置晶体管rbe_山东大学 模电实验 实验一:单极放大器 - 图文 --程序员宅基地
- 华为OD机试真题-灰度图恢复-2023年OD统一考试(C卷)-程序员宅基地
- 【机器学习】(周志华--西瓜书) 真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)_真正例率和假正例率,查准率,查全率,概念,区别,联系-程序员宅基地
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地