维基百科中文预训练数据
标签: BERT
用于BERT预训练,Bidirectional Encoder Representation from Transformers
标签: BERT
用于BERT预训练,Bidirectional Encoder Representation from Transformers

作者|马树铭MSRA研究员整理 |DataFunSummit目前,多语言神经机器翻译受到越来越多的研究人员的关注,多语言预训练模型对神经机器翻译可以起到非常重要的作用。预训练模...

数据集和预训练模型-附件资源
PyTorch 加载预训练权重
入门大模型训练的第一步:预训练(从根上学透大模型)
标签: facenet
facenet预训练的模型文件,用于人脸识别的模型调用,解压后,通过程序加载
在自然语言处理领域中,预训练语言模型(Pre-trained Language Model, PLM)已成为重要的基础技术,在多语言的研究中,预训练模型的使用也愈加普遍。为了促进中国少数民族语言信息处理的研究与发展,哈工大讯飞联合...
TensorFlow VGG-16 预训练模型,用于SSD-TensorFlow的Demo训练.

机器阅读理解 冠军亚军代码及中文预训练MRC模型
NLP领域预训练模型,采用自监督 学习方法,将大量无监督文本送入模型中进行学习,得到可通用的预训练模型。NLP领域有大量的无监督学习数据。大量研究工作表明,大量的数据可以不断提高模型的性能表现,与此同时压缩...


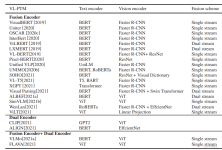
最近要学生学习下预训练模型的使用和发展 写了一篇学习笔记 编者按:自然语言处理(NLP)是AI领域中的一项重要技术,它可以使机器模仿人类的思考方式,以具备阅读、解读且理解人类的语言,从而完成文本分类、情感分析...


基于BERT预训练的中文命名实体识别TensorFlow实现-附件资源
ultralytics / yolov5,官方预训练权重yolov5l.pt,从drive.google下载下来的
基于PaddlePaddle实现的密度估计模型CrowdNet预训练模型

预训练模型
预训练模型专题_GPT2_模型代码学习笔记-附件资源


由于第一阶段预训练会冻结transformer参数,仅训练embedding模型,因此,收敛速度较慢,如果不是有特别充裕的时间和计算资源,建议跳过该阶段。第二阶段预训练使用LoRA技术,为模型添加LoRA权重(adapter),训练...
参数高效微调(PEFT)是自然语言处理(NLP)中使用的一种技术,用于提高预训练语言模型在特定下游任务上的性能。它涉及重用预训练模型的参数并在较小的数据集上对其进行微调,与从头开始训练整个模型相比,这可以...