本项目是新词挖掘+预训练模型继续预训练: 新词挖掘用到了两种方法,分别是 基于频次的新词挖掘 基于自由凝固度以及左右邻字熵的新词挖掘 详细请看./data/新词挖掘.ipynb
”预训练“ 的搜索结果

预训练权重,顾名思义,就是预先训练好的权重,这类权重是在大型数据集上进行训练的,训练出来的权重是普遍通用的,因此不必担心是否符合自己的实际情况,我们个人往往很难训练出预训练权重的效果。...
将模型下载放入C:\Users\用户名\.cache\torch\checkpoints

具有分层预训练的Tensor神经网络:迈向有效答案检索
就是两个预训练模型,分别是ResNet-50的和ResNet-101的预训练模型。直接下载解压就行了。对了,是原版的RFCN哦,就是Caffe+Python的,不是tensorflow的model。
14G的中文预训练数据part1
标签: BERT
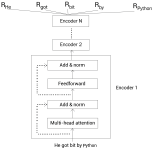
用于BERT预训练,Bidirectional Encoder Representation from Transformers
传送门:Deeplab预训练模型-附件资源

【CVPR 2020】StarGan V2预训练模型wing.ckpt

情绪识别使用预训练模型的keras进行情绪识别
如今,在训练深度学习模型时,通过在自己的数据上微调预训练模型来迁移学习已成为首选方法。通过微调这些模型,我们可以利用他们的专业知识并使其适应我们的特定任务,从而节省宝贵的时间和计算资源。本文分为四个...
基于ALBERT预训练模型实现答案预测分类——数据集基于ALBERT预训练模型实现答案预测分类——数据集基于ALBERT预训练模型实现答案预测分类——数据集基于ALBERT预训练模型实现答案预测分类——数据集基于ALBERT预训练...

windows下yolov8训练改进模型并使用自己的数据集
YOLOv5四个权重文件 yolov5s.pt yolov5m.pt yolov5l.pt yolov5x.pt
facenet谷歌预训练模型
标签: 模型
这是谷歌的预训练模型,而之前在facenet上的20170512的模型代码运行时会报错,所以分享出来不需要到谷歌云盘上下载了
理解预训练词嵌入的重要性 了解两种流行的预训练词嵌入类型:Word2Vec和GloVe 预训练词嵌入与从头学习嵌入的性能比较 介绍 我们如何让机器理解文本数据?我们知道机器非常擅长处理和处理数字数据,但如果我们向...
大家知道AI模型是怎么训练出来的吗?AI模型的训练训练过程分为如下三个阶段第一个阶段叫做无监督学习(PreTraining),就是输入大量的文本语料让GPT自己寻找语言的规律, 这样一个巨大的词向量空间就形成了,但是...


基于BERT预训练的中文命名实体识别TensorFlow实现-附件资源
预训练模型综述摘要:近年来,预训练模型的出现将自然语言处理带入了一个新的时代。本文概述了面向自然语言处理领域的预训练模型技术。我们首先概述了预训练模型及其发展历史。并详细介绍自然语言处理...


数据集和预训练模型-附件资源

推荐文章
- Android 编译so文件 MP4V2_android下编译mp4v2-程序员宅基地
- 通讯录Contact_02_contact文件内容-程序员宅基地
- Qt笔记(四十二)之QZXing的编译 配置 使用_qzxingfilterrunnable error:-程序员宅基地
- 关于画图软件Dia打开程序始终为英文界面的问题-程序员宅基地
- OpenCV从入门到精通实战(二)——文档OCR识别(tesseract)-程序员宅基地
- 详解avcodec_receive_packet 11_avcodec_receive_packet eagain-程序员宅基地
- OpenGL SuperBible 7th源码编译记录_superbible7-media github-程序员宅基地
- Wireshark简单使用-程序员宅基地
- MXNet 粗糙的使用指南_iou loss mxnet-程序员宅基地
- iOS对ipa包进行代码混淆《二》 ---代码混淆_ipa包混淆-程序员宅基地