Prompt是一种用于指导大型语言模型生成自然语言文本的文本片段。在使用大型语言模型时,我们需要提供一个Prompt,以指导模型产生符合我们期望的文本结果。Prompt可以是一个单词、一句话、一段话或一个完整的篇章。举...
”语言模型“ 的搜索结果
AI 应用程序正在总结文章、撰写故事和进行长时间对话——而大型语言模型正在承担繁重的工作。 大型语言模型或 LLM 是一种深度学习算法,可以根据从海量数据集中获得的知识来识别、总结、翻译、预测和生成文本和其他...
预训练)是语言模型学习的初始阶段。在预训练期间,模型会接触到大量未标记的文本数据,例如书籍、文章和网站。在大量未标记文本数据上训练语言模型。比如说在包含数百万本书、文章和网站的数据集上预训练像 GPT-3 ...
您无需从头开始构建模型来解决您的问题,而是使用针对更一般问题进行训练的模型作为起点,并使用特别策划的数据集在您选择的领域对其进行更具体的训练。它的数据集和模型都比用于 GPT-2 的数据大两个数量级:GPT-3 ...
语言模型(NNLM)
标签: 自然语言处理



选择适合的模型架构、对于底座大模型,考虑使用Transformer的架构,这种架构在自然语言处理任务中表现出色。根据模型评估的结果和反馈,可以进行迭代和改进,调整模型架构、数据预处理步骤或训练策略,以提高模型的...
[2] LangChain中文网 - LangChain 是一个用于开发由语言模型驱动的应用程序的框架:http://www.cnlangchain.com/》系列文章中,我们将专注于通用的LLM功能,而有关使用特定LLM包装器的详细信息,请参见具体的示例。...
一、语言模型基础 1.什么是语言模型 语言模型用来判断一句话从语法上是否通顺 总结起来的话,语言模型最主要的作用是保证文本的语法结构,得到通顺的语句。语言模型是一种概率统计的方法,已经训练好的语言模型...
GPT:GPT是一种基于Transformer的生成式预训练模型,其目标是通过自回归语言模型预训练来学习生成连贯文本的能力。BERT:BERT是一种基于Transformer的预训练模型,它的目标是通过双向语言模型预训练来学习上下文相关...
GPT-4是OpenAI公司3月推出的新一代人工智能预训练AI模型,是一个多模态大型语言模型,使用了1.5万亿个参数,是GPT-3.5的10倍之多,当然它也是世界上最大的人工智能模型。
人工智能大语言模型微调技术:SFT 监督微调、LoRA 微调方法、P-tuning v2 微调方法、Freeze 监督微调方法
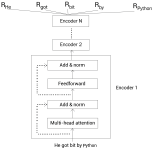
本文以QA形式总结对比了nlp中的预训练语言模型,主要包括3大方面、涉及到的模型有: 单向特征表示的自回归预训练语言模型,统称为单向模型: ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0; 双向特征表示的自编码预训练语言...
大语言模型(LLM,Large Language Model)是一种基于深度学习的自然语言处理技术,它使用深度神经网络来学习自然语言的统计规律,以便能够自动地生成、理解和处理自然语言。大语言模型(LLM)是指使用大量文本数据...


本指南涵盖了Prompt的基础知识,提供关于如何使用提示来互动和指导大型语言模型(LLM)的粗略概念。本章节主题包括:基础Prompt;有关大型语言模型的参数设置;标准Prompt;Prompt所包含的元素


大语言模型-NLP模型汇总
标签: python
NLP
kaldi中语言模型
作为一种主要的语言建模方法,在过去的二十年中,语言建模在语言理解和生成方面得到了广泛的研究,从统计语言模型发展到神经语言模型。最近,通过在大规模语料库上预训练Transformer模型,人们提出了预训练语言模型...

语言模型 语言模型可以对一段文本的概率进行估计,对信息检索,机器翻译,语音识别等任务有着重要的作用。语言模型分为统计语言模型和神经网络语言模型。下面一次介绍着两类语言模型。 统计语言模型 要判断一段...
本文提出了BLIP-2,一种通用且高效的预训练策略,它可以从现成的冻结预训练图像编码器和冻结大型语言模型中引导视觉-语言预训练。BLIP-2通过一个轻量级的来弥合模态差距,并在两个阶段进行预训练。第一个阶段从冻结...
ChatGLM2-6B是一个开源的、支持中英双语的对话语言模型,基于General Language Model (GLM)架构。自我认知:“介绍一下你的优点”提纲写作:“帮我写一个介绍ChatGLM的博客提纲”文案写作:“写10条热评文案”信息...


推荐文章
- MacOS 系统成功安装 tensorflow 步骤_mac装tensorflow-程序员宅基地
- ES(Elasticsearch)7.6.1安装教程_安装elasticsearch-程序员宅基地
- spring boot>>RabbitMQ中间件发送验证码_basevo依赖-程序员宅基地
- uiautomatorviewer拉取手机竖屏却显示为横屏的问题_uiautomatorviewer方向倒了-程序员宅基地
- 加密技术简介-程序员宅基地
- 使用迭代器Iterator遍历Collection_.keyset().iterator().next()-程序员宅基地
- 日常Java练习题(每天进步一点点系列)_callable的call方法返回值-程序员宅基地
- 已解决Using TensorFlow backend.-程序员宅基地
- ring0下的 fs:[124]_nsfs124-程序员宅基地
- 高德地图打包后不能使用,高德导航View不显示,高德地图导航组件黑屏的问题;_amap.amapwx打包成安卓后无法使用-程序员宅基地