
”爬虫Web“ 的搜索结果
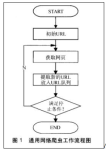
python爬虫web请求全过程剖析
Web爬虫是一种自动化程序,可以模拟人类浏览器的操作,从互联网上抓取数据。爬虫在很多领域中都发挥重要的作用,如搜索引擎、数据分析和监测等。本文将介绍一些关于爬虫的基本知识点,以帮助初学者入门。本文介绍了...
大家在读爬虫系列的帖子时常常问我怎样写出不阻塞的爬虫,这很难,但可行。通过实现一些小策略可以让你的网页爬虫活得更久。那么今天我就将和大家讨论这方面的话题。用户代理你需要关心的第一件事是设置用户代理。 ...
毕业设计-基于Scrapy-redis的分布式爬虫Web平台
web数据挖掘课:网站内容的爬取,包括文本、图片和文件等;其次是对于网站结构的爬取,包括网站目录,链接之间的相互跳转关系,二级域名等;还有一种爬虫是对于Web应用数据的挖掘,包括获取网站CMS类型,Web插件等。
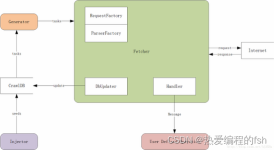
网络爬虫WebController和selenium的最新jar包,用于爬取新浪微博的个人主页信息
web of science论文爬虫程序(python),可以抓取web of science论文数据,也可以抓其它论文数据库的数据
爬虫技术:从Web中获取数据的利器 爬虫技术:从Web中获取数据的利器 爬虫技术:从Web中获取数据的利器 爬虫技术:从Web中获取数据的利器 爬虫技术:从Web中获取数据的利器 爬虫技术:从Web中获取数据的利器 爬虫技术...
2018先知白帽大会web2.0爬虫ppt2018先知白帽大会web2.0爬虫ppt2018先知白帽大会web2.0爬虫ppt2018先知白帽大会web2.0爬虫ppt2018先知白帽大会web2.0爬虫ppt2018先知白帽大会web2.0爬虫ppt

web爬虫程序(亲测可用,含sql文件) 有问题咨询[email protected] SohuNews.java第122行插入新闻时间有误,需要的可以自己改下
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
毕业设计web爬虫,基于web爬虫的疫情监测系统
业务需要爬取一个网站所有手机信息 ,最开始用了crawler4j这个框架,挺简单的,但是发现不能满足我的需求;只支持单页面信息抓取,但是我是要多页面抓取;...后来改成了webcontroller,发现可以实...
主要介绍了Python实现简易Web爬虫详解,具有一定借鉴价值,需要的朋友可以参考下
web技术爬虫可用很犀利
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本 爬虫入门程序 环境准备 JDK1.8 IntelliJ IDEA IDEA自带的Maven 环境准备 1.创建Maven工程itcast-crawler-first并给pom....
文章目录太长不看0....WOS_Crawler是一个Web of Science核心集合爬虫。 支持爬取任意合法高级检索式的检索结果(题录信息) 支持爬取给定期刊列表爬取期刊上的全部文章(题录信息) 支持选择目标文献类型...
该平台可供新手小白练习Web端爬虫技术,再也不怕新手入门找不到合适的网站了,该平台目前有七道大题,每个题目都是独立开发Web网页,并且每道题使用到的反爬技术都是不同的,很适合新人练手,后期也会进行更新题目。...
webcrawler:网络爬虫
标签: Java
网络爬虫建造gradle build fatJar 跑步java -jar build/libs/webcrawler-all-1.0.jar startURL depth [poolSize=10] 示例: java -jar build/libs/webcrawler-all-1.0.jar http://ya.ru/ 3 100待办事项将parent_id列...
一个网络爬虫程序,抓取网页上的内容 一个网络爬虫程序,抓取网页上的内容
在这种情况下,信息集成就更加需要Web爬虫来自动获取这些页面以进一步地处理数据。为了帮助用户完成这样的任务,提出一种用于搜集Deep Web页面的爬虫的设计方法。此方法使用一个预定义的领域本体知识库来识别这些...
为您提供ScrapyWeb爬虫框架下载,Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
ECommerceCrawlers包含了多种电商商品数据爬虫,整理收集爬虫练习。每个项目都是成员写的。通过实战项目练习解决一般爬虫中遇到的问题。包含:淘宝商品、微信公众号、大众点评、招聘网站、闲鱼、阿里任务、scrapy...
web爬虫合集.zip
标签: 爬虫
web爬虫合集.zip
Web Scraper是一款简单好用的谷歌插件,用于爬取网页数据。思维导图涵盖了爬取二级页面,表格,文本,翻页等基本爬虫的操作过程,适合入门学习。

推荐文章
- Apache Struts最新漏洞 远程代码执行漏洞预警 2018年11月08日_apache struts common fileupload远程代码执行漏洞-高风险-程序员宅基地
- SQL Server中的isnull()函数:_select isnull(zt,0) from uf_gszdmk-程序员宅基地
- 用VMWare笔记本一拖二,完美支持两套显示器键盘鼠标-程序员宅基地
- java用那个软件编,java编译软件 编写java程序用什么软件?-程序员宅基地
- 通过密钥远程登录(SSH)Kali(linux)_kali开启ssh秘钥登录-程序员宅基地
- QtCreator如何进行Qt开源程序包的源码调试_qt debug information file-程序员宅基地
- Promise in AngularJS-程序员宅基地
- android.util.AndroidRuntimeException: Calling startActivity() from outside of an Activity_android android.util.androidruntimeexception: call-程序员宅基地
- 集群资源调度系统设计架构总结_任务调度集群资源怎么写-程序员宅基地
- B-tree/B+tree/B*tree-程序员宅基地