不平衡数据(Imbalanced Datasets)分类的例子对不平衡数据的处理朴素随机过采样(上采样,over-sampling)朴素随机欠采样(下采样,under-sampling)随机采样的优缺点过采样的改进:SMOTE与ADASYNSMOTESMOTE的改进:...
”数据不平衡“ 的搜索结果

数据不平衡问题虽然不是最难的,但绝对是最重要的问题之一。在学术研究与教学中,很多算法都有一个基本假设,那就是数据分布是均匀的。当我们把这些算法直接应用于实际数据时,大多数情况下都无法取得理想的结果。...
处理数据不平衡问题的方法有多种,以下是一些常用的方法:过采样(Oversampling):增加少数类样本的数量,使得正样本和负样本的数量更加平衡。过采样的方法包括随机复制样本、SMOTE(SyntheticMinority Over-...
处理数据不平衡是在机器学习任务中常遇到的问题,特别是在分类任务中,某些类别的样本数量远远超过其他类别的样本数量。选择合适的方法取决于具体的数据集和任务特性。在实际应用中,通常需要进行实验比较不同方法的...

如何处理数据不平衡问题
标签: 机器学习
一、什么是数据不平衡问题 数据不平衡也可称作数据倾斜。在实际应用中,数据集的样本特别是分类问题上,不同标签的样本比例很可能是不均衡的。因此,如果直接使用算法训练进行分类,训练效果可能会很差。 二、如何...
数据挖掘:数据预处理——数据不平衡处理 一、什么是数据不平衡? 不平衡数据集指的是数据集各个类别的样本数目相差巨大,也叫数据倾斜。以二分类问题为例,即正类的样本数量远大于负类的样本数量。严格地讲,任何...
数据不平衡问题虽然不是最难的,但绝对是最重要的问题之一。 一、数据不平衡 在学术研究与教学中,很多算法都有一个基本假设,那就是数据分布是均匀的。当我们把这些算法直接应用于实际数据时,大多数情况下都无法...


数据不平衡的解决方法 1:什么是数据不平衡 以二分类举例,数据不平衡是指数据集中正类和负类的比例严重失调,比如正:负为9:1。数据不平衡会导致模型学习偏差,模型会倾向于学习比例高的数据特征,对比例低的数据...
R语言解决数据不平衡问题 一、项目环境 开发工具:RStudio R:3.5.2 相关包:dplyr、ROSE、DMwR 二、什么是数据不平衡?为什么要处理数据不平衡? 首先我们要知道的第一个问题就是“什么是数据不平衡”,从字面...

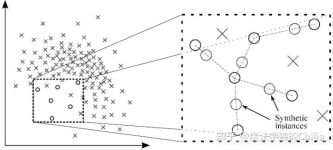
有些问题其原始数据的分布就存在不平衡,如通过卫星雷达图片检测海面石油油污、监测信用卡非法交易、发掘基因序列中编码信息以及医学数据分类等。 所谓的数据不平衡是指:数据集样本类别极不均衡。不平衡数据的学习...
数据不平衡是机器学习任务中的一个常见问题。真实世界中的分类任务中,各个类别的样本数量往往不是完全平衡的,某一或某些类别的样本数量远少于其他类别的情况经常发生,我们称这些样本数量较少的类别为少数类,与之...


最近有被频繁的问到数据不平衡(样本比例失衡)问题,而这一部分在日常数据处理中也算是比较重要的一部分了,处理的好坏对后续的模型训练结果还是会有很大的影响的,今天就专门归纳总结一下,以供以后参考。1.数据不...
1.数据不平衡 1.1 数据不平衡介绍 数据不平衡,又称样本比例失衡。对于二分类问题,在正常情况下,正负样本的比例应该是较为接近的,很多现有的分类模型也正是基于这一假设。但是在某些特定的场景下,正负样本的比例...
对于二分类问题,正负样本比例为1:2、1:3、2:3都是...数据量较大的情况下,使用欠采样方法较为合适。 本文使用的数据集正负样本比例约为1:15,使用欠采样方法将比例调整为1:3,即保留正样本,并从负样本中进行抽样。

1.数据不平衡1.1 数据不平衡介绍数据不平衡,又称样本比例失衡。对于二分类问题,在正常情况下,正负样本的比例应该是较为接近的,很多现有的分类模型也正是基于这一假设。但是在某些特定的场景下,正负样本的比例却...
数据不平衡经常出现在分类问题上,数据不平衡指的是在数据集中不同类别的样本数量差距很大,比如,在病人是否得癌症的数据集上,可能绝大部分的样本类别都是健康的,只有极少部分样本类别是患病的。下面介绍几个常用...
如果不考虑数据平衡的问题,模型的性能会出现问题。 原因: 1.对于不平衡类别,模型无法充分考察样本,从而不能及时有效地优化模型参数。 2.它对验证和测试样本的获取造成了一个问题,因为在一些类观测极少的情况下...
类别失衡会给预测任务带来挑战,并且会导致少数类别的预测效果较差因为大部分机器学习算法的假设场景是类别(数据)平衡的前提。 本文原始链接 MLSMOTE 分类是一种有监督学习技术,是将目标数据分类至提前已经定义...

推荐文章
- 手写一个SpringMVC框架(有助于理解springMVC) 侵立删_springmvc可以用来写安卓后端吗-程序员宅基地
- 线性判别分析LDA((公式推导+举例应用))_lda推导-程序员宅基地
- C# 结构体(Struct)精讲_c# struct-程序员宅基地
- 支付宝Wap支付你了解多少?_阿里wap支付-程序员宅基地
- Java计算器编写,实现循环输入_java简易计算器可使用户多次输入-程序员宅基地
- 【多维Dij+DP】牛客小白月赛75 D-程序员宅基地
- Android之内存优化与OOM-程序员宅基地
- Azure Machine Learning - 视频AI技术_azure ai 視頻索引器-程序员宅基地
- 个人知识管理软件使用感受-程序员宅基地
- WWDC2019 ------深入理解App启动_wwdc app启动-程序员宅基地