在传统的批处理中,数据被存储起来,...流处理引擎:实时处理数据流的系统。数据存储:处理后数据的存储系统。查询和分析:对流数据进行查询和分析的工具。我们首先定义一个数据源,这里假设是一个不断产生随机数的源。
”实时流处理“ 的搜索结果
1.背景介绍 1. 背景介绍 Apache Flink 是一个流处理框架,用于实时数据...Flink 的实时分析应用案例非常广泛,包括实时数据流处理、实时数据分析、实时报警等。在这篇文章中,我们将深入探讨 Flink 的实时分析应用...
实时流处理运行步骤环境准备参考Flink开发指南》环境准备》准备安全认证进行Flink安全认证在Flink Client端conf目录下添加keystore、t
Apache Flink 是一个流处理框架,用于实时数据流处理和大数据处理。Flink 可以处理大规模数据流,并提供低延迟和高吞吐量。Flink 支持流处理和批处理,可以处理各种数据源和数据接收器,如 Kafka、HDFS、TCP 流等。...
一. 业务现状分析 1.需求 统计某视频学习平台主站上每个(指定)课程访问的客户端(PC/APP)、地域信息分布。 ... 地域信息:由IP进行转换; 客户端:通过useragent获取 以上两个操作都是可以采用离线的方式(Spark/...
实时流处理简单概述:实时是说整个流处理相应时间较短,流式技算是说数据是源源不断的,没有尽头的。实时流处理一般是将业务系统产生的数据进行实时收集,交由流处理框架进行数据清洗,统计,入库,并可以通过可视化...
该程序实现topN功能和实时更新黑名单功能,并且能够预测未来点击流趋势。
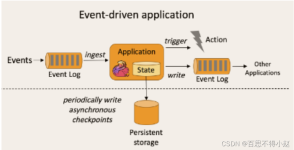
谈flink实时流处理
标签: flink
但随着数据的不断增长,新技术的不断发展,人们逐渐意识到对实时数据处理的重要性,企业需要能够同时支持高吞吐、低延迟、高性能的流处理技术来处理日益增长的数据。 相对于传统的数据处理模式,流式数据处理则有着...
什么是数据实时处理? • 数据从生成->实时采集->实时缓存存储->实时计算->实时落地->实时展示->实时分析。这一个流程线下来,处理数据的速度在秒级甚至毫秒级。 • 某电子商务网站双十一大屏,...
Storm是Twitter开源的分布式实时计算系统,Storm通过简单的API使开发者可以可靠地处理无界持续的流数据,进行实时计算,开发语言为Clojure和Java,非JVM语言可以通过stdin/stdout以JSON格式协议与Storm进行通信。...
使用Beam实现游戏积分排行榜的实时流处理,涉及窗口、触发器和累加模式的设置,以及处理“迟到”数据。文章示范了数据流水线设计,提供宝贵的经验和技术指导。读者可探讨优化配置,分享学习体会。
本文介绍了使用Apache Beam实现糖果传奇游戏的实时积分排行榜,强调了实时数据处理的优势和缩小延时的方法。通过定义类、使用Bigtable读取数据、自定义Composite Transform等步骤,实现了每周更新一次的游戏积分排行...
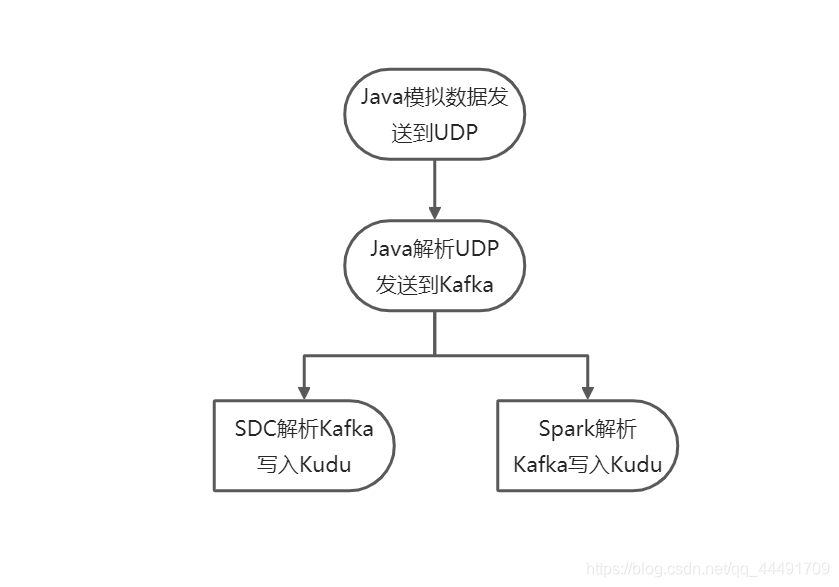
SparkStreaming 实时流处理项目实战视频,讲的内容还可以,适合入门,推荐想学的同学一起来学习下
面向实时流处理的多核多线程处理器访存队列.pdf
恒丰银行于2016年1月完成了传统数据仓库向大数据平台数据仓库的迁移,以新的数据仓库平台为基础,...大数据平台解决了大数据特征中四个V的大数据量(Volume)的处理,我们还需要引入实时处理技术能覆盖数据多样性...
Spark Streaming实时流处理项目实战.rar.rar
lambda-refarch-streamprocessing, 实时流处理的无服务器参考架构 无服务器参考体系结构: 实时流处理README Languages : DE | ES | FR | it | JP | KR | PT | RU | CN | TW你可以使用自动完成和亚马逊Kinesis来处理...
实时流处理:对于无界数据流,通常在数据生成时进行实时处理。因为无界数据流的数据输入是无限的,所以必须持续地处理。数据被获取后需要立刻处理,不可能等到所有数据都到达后再进行处理。处理无界数据流通常要求以...
这有助于提高数据处理效率和数据质量。常见的数据格式有JSON、CSV等。JSON是一种轻量级的数据交换格式,易于阅读和写入。在JSON格式中,数据以键值对的形式表示,结构清晰,易于解析和处理。CSV是一种简单的文本格式...
Apache Flink是一个用于无界和有界数据流的开源流处理框架。它提供了一个统一的API来处理批量和流数据,使得开发者可以轻松地构建高效的实时数据处理应用。Flink的核心优势在于其低延迟、高吞吐量和容错性强的特点,...

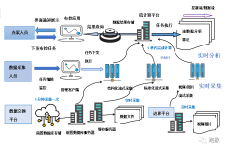
给大家分享一套大数据课程——基于Flink流处理的动态实时电商实时分析系统,含代码。
分布式流处理需求日益增加,包括支付交易、社交网络、物联网(IOT)、系统监控等。业界对流处理已经有几种适用的框架来解决,下面我们来比较各流处理框架的相同点以及区别。 分布式流处理是对无边界数据集...

#资源达人分享计划#
推荐文章
- com.netflix.discovery.shared.transport.TransportException: Cannot execute request on any known serve-程序员宅基地
- PAT乙级练习题1010 一元多项式求导_pat 乙级 1010-程序员宅基地
- You can also run `php --ini` inside terminal to see which files are used by PH P in CLI mode_you can also run `php --ini` in a terminal to see -程序员宅基地
- 对UDP校验和的理解_udp 数据包 校验和 checksum=0-程序员宅基地
- 递归遍历文件夹,以c:/windows为例-程序员宅基地
- git 本地与远程的链接_git如何本地和网页链接-程序员宅基地
- ArrayList与HashMap遍历删除元素,HashMap与ArrayList的clone体修改之间影响_在arraylist和hashmap遍历的同时删除元素,可能会导致一些问题发生-程序员宅基地
- Chapter2-软件构造过程和生命周期_iterative and agile systems development lifecycle -程序员宅基地
- 4.6 浮动定位方式float_c语言中float的左右浮动属性示例-程序员宅基地
- OSS上传【下载乱码问题】_阿里云oss文件名乱码-程序员宅基地