大数据平台架构及主流技术栈
标签: 大数据
标签: 大数据
【数据开发】大数据岗位,通用必备技术栈(数据分析、数据工程、数据科学) 文章目录 1、岗位与技术要求 1.1 常见岗位介绍 1.2 行业发展方向 1.3 附部分JD 2、数据开发技术栈 2.1 数据处理流程 2.2 学习路线与框架 ...
大数据相关的技术名词特别多,这些技术栈之间的关系是什么,对初学者来说很难找到抓手。我一开始从后端转大数据的时候有点懵逼,整体接触了一遍之后才把大数据技术栈给弄明白了。
Flink是一个开源的流式数据处理和批处理框架,旨在处理大规模的实时数据和离线数据。它提供了一个统一的系统,能够高效地处理连续的数据流,并具备容错性和低延迟的特点。Flink的设计目标是在一个系统中同时支持流式...
常见开源CDC方案比较如下:如上图,如果需要做全量+增量同步,FlinkCDC是一个不错的选择。(支持的下游生态更丰富、操作更简单Flink SQL)
岗位都需要什么技能呢?Spark,Hadoop,数据仓库,Python,SQL,Mapreduce,Hbase等等大数据的方向的切入是全方位的,基础语言...在这种趋势下,大数据技术越来越重要。所以说,未来大数据是我们打工人的必备技能之一。
大数据技术栈相关介绍

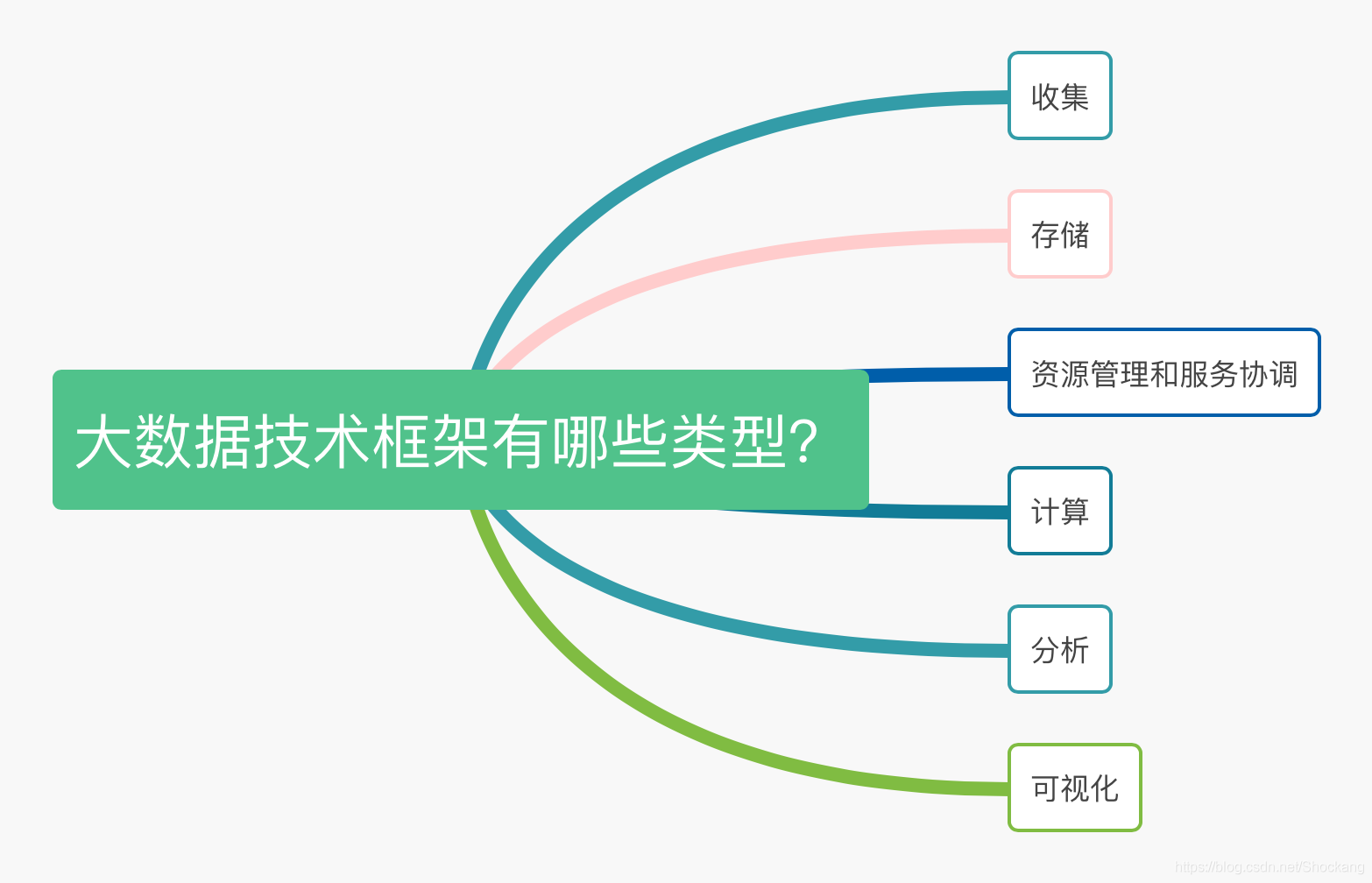
大数据技术栈思维导图 大数据常用软件安装指南 一、Hadoop 分散文件存储系统 —— HDFS 多元计算框架——MapReduce 集群资源管理器 —— YARN Hadoop单机伪集群环境搭建 Hadoop 云服务环境搭建 HDFS使用Shell命令 ...
大数据技术栈思维导图 大数据常用软件安装指南 包括Hadoop、Hive、Spark、Storm、Flink、HBase、Kafka、Zookeeper、Flume、Sqoop等技术的学习 Hadoop 分布式文件存储系统 —— HDFS 分布式计算框架 —— MapReduce ...
相信很多学Java的同学都有想转大数据或者学大数据的想法,但是一看到网上那些大数据的技术栈,就一脸懵逼,什么Hadoop、HDFS、MapReduce、Hive、Kafka、Zookeeper、HBase、Sqoop、Flume、Spark、Storm、Flink等等...
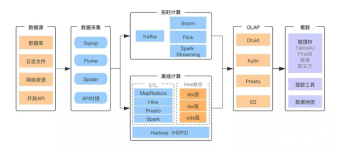
上图是一个简化的大数据技术栈思维导图。 大数据的处理流程如下: 技术涉及以下5个方面! 1.1 数据收集 大数据处理的第一步是数据的收集。现在的中大型项目通常采用微服务架构进行分布式部署,所以数据的采集需要在...
大数据技术板块划分 数据采集 flume kafka logstash filebeat ... 数据存储 mysql redis hbase hdfs ... 数据查询 hive impala elasticsearch kylin ... 数据计算 实时计算 storm sparkstrea...
1. 数据采集和传输层 Flume ...ELK工作栈的一员,也常用于数据采集,是开源的服务器端数据处理管道 Sqoop Sqoop主要通过一组命令进行数据导入导出的工具,底层引擎依赖于MapReduce,主要用于Hadoop
标签: 大数据
大数据技术栈思维导图
Hadoop与Spark开源大数据技术栈: 随着大数据技术的快速发展,目前开源社区已经积累了比较完整的大数据技术栈,目前市场上应用最广泛的是以Hadoop与Spark为核心的生态系统。该生态系统分为5个层级分别是:数据收集,...
前言文本已收录至我的GitHub仓库,欢迎Star:https://github.com/bin392328206/six-finger种一棵树最好的时间是十年前,其次是现在叨絮其实今天...
ETL(数据仓库技术)ETL的概念ETL的三个阶段一、 数据的抽取(Extract)二、数据的清洗转换(Cleaning、Transform)三、ETL日志、警告发送ETL特点 ETL的概念 ETL是英文Extract-Transform-Load的缩写,用来...
有关聚美优品在大数据领域的,数据库相关技术选型,方案。以及在选择的过程中的技术栈构建和思考路径。尤其是在大数据领域,需要兼顾数据的OLAP、OLTP的场景化考量。