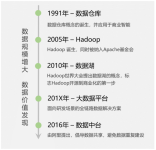
大数据4“V”: 数据量大(Volume) 数据类型繁多(Variety) 处理速度快(Velocity) 价值密度低(Value) 大数据对思维方式的影响:全样而非抽样、效率而非精确、相关而非因果。 大数据的基本处理流程:数据采集、...
”大数据开发复习整理“ 的搜索结果
大数据期末复习题目汇总
第一章Hadoop大数据开发环境的思维导图
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。 既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶...
Hadoop概述在VirtualBox上安装虚拟机Hadoop安装前的准备工作。
期末复习的时候对课本进行了系统的整理,现在发上来希望能对大家有用www 正文 第1章 引言 数据库系统由一个互相关联的数据的集合和一组用以访问这些数据的程序组成。这个数据的集合通常称作数据库。 DBMS的主要特性 ...
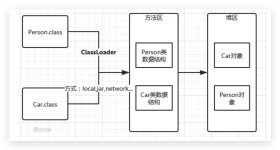
•BulkLoad是指将数据直接转换为StoreFile文件,放入Hbase中,不经过Hbase的内存,避免大量数据进入内存,又从内存进入HDFS•应用:大数据量批量写入Hbase。
如何成为一名大数据开发工程师,工作经验总结 原画心旗2019-11-06 13:35:22 首先,我个人进入大数据行业也纯属偶然,当年实习的时候做的是纯纯的Java开发,后来正式毕业了以后找了份Java开发的工作,本以为和...
大数据的概念: 大数据的4个“V”是指:数据量大、数据类型繁多、处理速度快、价值密度低 大数据的基本处理流程主要包括数据采集、数据存储、数据分析和结果呈现。 大数据的计算模式主要包括批处理计算、流处理计算...
2020大数据面经整理
标签: 大数据
一、快手大数据开发工程师面经 作者:恶魔木魅妈妈咪 链接:https://www.nowcoder.com/discuss/392528 来源:牛客网 一面(40min) 1、自我介绍? 2、Spark任务调度(源码)? SparkDeploySchedularBackend : ...
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。 既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶...
二本学校毕业5年,在某已倒闭手机厂商做安卓开发3年,到银行外包写SQL1年,现在在某大厂做大数据开发工作即将一年,月处理数据量PB级别。 2.为什么要转型 转型有两个原因,一个是技术相关的,刚毕业心态没...
1下面哪个选项属于大数据技术的“数据存储和管理”技术层面的功能? A、利用分布式文件系统、数据仓库、关系数据库等实现对结构化、半结构化和非结构化海量数据的存储和管理 B、利用分布式并行编程模型和计算框架,...
1.R语言(quantmod)安装与使用过程: 安装过程:(1)连网时,用函数install.packages(),选择镜像后,程序将自动 下载并安装程序包(2)安装本地zip包:①路径packages>install packages from local ...
•BulkLoad是指将数据直接转换为StoreFile文件,放入Hbase中,不经过Hbase的内存,避免大量数据进入内存,又从内存进入HDFS•应用:大数据量批量写入Hbase。
•BulkLoad是指将数据直接转换为StoreFile文件,放入Hbase中,不经过Hbase的内存,避免大量数据进入内存,又从内存进入HDFS•应用:大数据量批量写入Hbase。

体现的是 A对象(凤凰)可以包含B对象 (翅膀、爪子等)。A作为整体, B作为部分。体现的是A对象(学校)可以包含B对象(老师、学生),但B对象不是A对象的一部分。如果A没了,B也就没了。凤凰没了, 它的翅膀也是...
信息科技为大数据时代提供技术支持 存储设备容量不断增加 CPU处理能力大幅度提升 网络带宽不断增加 大数据4V特征 数据量大 数据类型繁多 处理速度快 价值密度底 大数据对思维方式的影响 全样而非抽样 效率而非...
临时抱佛脚之大数据期末复习
标签: 大数据


⑤ SparkContext就建成DAG图,DAGScheduler将DAG图解析成Stage,每个Stage有多个task,形成taskset发送给task Scheduler,由task Scheduler将Task发送给Executor运行。2)应用程序层面的调优:过滤操作符的优化降低...

作为一名大数据专业学生、爱好者,深知面试重要性,很多学生已经进入暑假模式,暑假也不能懈怠,正值金九银十的秋招接下来我准备用30天时间,基于大数据开发岗面试中的高频面试题,以每日5题的形式,带你过一遍常见...
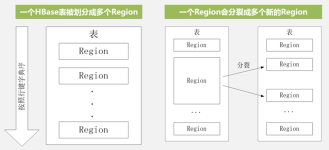
•Hive是通过构建元数据,映射HDFS文件构建成表,本质还是HDFS,实现。:Hbase中允许一列存储多个版本的值,并通过数据写入的时间戳来区分不同版本。:行健,类似于主键的设计,唯一标识一条数据并且作为Hbase中的...
今天我们复习了面试中常考的Spark相关的五个问题,你做到心中有数了么?网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。需要这份系统化的资料...
1)粗粒度:启动时就分配好资源, 程序启动,后续具体使用就使用分配好的资源,不需要再分配资源;优点:作业特别多时,资源复用率高,适合粗粒度;缺点:容易资源浪费,假如一个job有1000个task,完成了999个,还有...
推荐文章
- java/php/node.js/python减肥小程序【2024年毕设】-程序员宅基地
- 剪格子 蓝桥杯-程序员宅基地
- 鸿蒙系统APP应用开发初尝试——Hello World!_鸿蒙app开发-程序员宅基地
- Ext Js 搭建及核心组件介绍(一)_ext-all.js-程序员宅基地
- yolov5s模型转tensorrt+deepstream检测+CSI和USB摄像头检测_arguments not right! ./yolov5 -v [.engine] // run -程序员宅基地
- 在Windows系统上使用MinGW构建re2c_如和再windows安装源码re2c-程序员宅基地
- Untiy插件 -MAST(Modular Asset Staging Tool)使用说明与Voxel免费资源分享-程序员宅基地
- Scala语言会取代Java的吗?-程序员宅基地
- Springboot旅游景点订票系统 计算机毕设源码68524_springboot广州长隆购票系统-程序员宅基地
- C语言中的多线程编程如何实现?_c 多线程编程-程序员宅基地