关于urllib模块的详细解释,包括且不限于访问、异常处理解析、URL拆分拼接等方法。值得参考的学习笔记。
”urllib模块爬虫“ 的搜索结果
爬虫之URLLIB模块(一)
标签: python
URLLIB模块 第一章 URLLIB访问 其实趋向URLLIB模块,我更想用Requests模块 当然更多也是为了系统学习爬虫 认识下urllib模块: > urllib.request 打开和读取 URL > urllib.error 包含 urllib.request 抛出的...
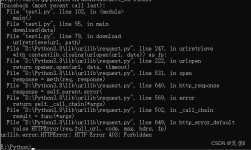
主要介绍了python爬虫 urllib模块反爬虫机制UA详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。...res = urllib.request.urlopen(req)html = res.read().decode(‘utf-8’)dic = json.load
通过分析我们发现在爬取过程中速度比较慢,所以我们还可以通过禁用谷歌浏览器图片、JavaScript等方式提升爬虫爬取速度。

主要介绍了python urllib爬虫模块使用解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
urllib 模块是 Python 标准库,其价值在于抓取网络上的 URL 资源,入门爬虫时必学的一个模块。 不过更多的爬虫工程师上手学习的模块已经更换为 requests 了。 在 Python3中 urllib 模块包括如下内容。 urllib....
urllib模块发起的POST请求 案例:爬取百度翻译的翻译结果 1.通过浏览器捉包工具,找到POST请求的url 针对ajax页面请求的所对应url获取,需要用到浏览器的捉包工具。查看百度翻译针对某个字条发送ajax请求,所对应...
urllib模块在Python2在Python3中的区别:python 3.x中urllib库和urilib2库合并成了urllib库。其中一些函数调用也有了一些小小变动。记录如下:一、python2中用urllib、urllib2模块爬取网页以爬取CSDN网页为例:...
2.发送请求:urlopen()方法========================================================================================urloprn() 方法由urllib.request模块提供,以实现基本的http请求,并接受服务器端返回的响应...
client: fanyideskwebsalt: 16417380413821sign: 6545acd2d928b39eb5bead9349a2d4fflts: 1641738041382bv: fdac15c78f51b91dabd0a15d9a1b10f5doctype: ...import urllib.requestimport urllib.parseimport jsonk
r1 = http.request(‘GET’, url, retries=5) # 发送GET请求,设置5次重试请求r2 = http.request(‘GET’, url, retries=False) # 发送GET请求,关闭重试请求print(‘默认重试请求次数:’, r.retries.total)print(...
这样就正常显示了。1.3 重试请求urllib3可以自动重试请求,request()方法...import urllib3 # 导入urllib3模块urllib3.disable_warnings() # 关闭ssl警告url = ‘https://www.httpbin.org/get’ # get请求测试地址。
爬虫之urllib模块
标签: python
urllib用于获取网页内容 urllib.request 请求模块 urllib.error 异常处理模块 urllib.parse 解析模块
url = ‘https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule’req = urllib.request.Request(url, data=data, headers=headers)res = urllib.request.urlopen(req)html = res.read().decode(...
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。别在网上瞎学了,我最近也做了一些资源的...
urllib模块在Python2在Python3中的区别:python 3.x中urllib库和urilib2库合并成了urllib库。其中一些函数调用也有了一些小小变动。记录如下: 一、python2中用urllib、urllib2模块爬取网页 import urllib import ...
urlliburllib模块是python3的URL处理包其中:1、urllib.request主要是打开和阅读urls个人平时主要用的1:打开对应的URL:urllib.request.open(url)用urllib.request.build_opener([handler, ...]),来伪装成对应的...
action: FY_BY_REALTlME代码示例如下:import urllib.requestimport urllib.parseimport jsonkey = input(“请输入内容:”)data = {“i”: key,“from”: “AUTO”,“to”: “AUTO”,“smartresult”: “dict”,...
url = ‘https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule’req = urllib.request.Request(url, data=data, headers=headers)res = urllib.request.urlopen(req)html = res.read().decode(...
urllib模块是python3的URL处理包 其中: 1、urllib.request主要是打开和阅读urls 个人平时主要用的1: 打开对应的URL:urllib.request.open(url) 用urllib.request.build_opener([handler, …]),来伪装成对应的...
主要介绍了python爬虫开发之urllib模块详细使用方法与实例全解,需要的朋友可以参考下
主要介绍了Python中使用urllib2模块编写爬虫的简单上手示例,文中还介绍到了相关异常处理功能的添加,需要的朋友可以参考下
import urllib.request # 1.指定url url = 'https://www.sogou.com/web?query=周杰伦' ''' 2.发起请求:使用urlopen函数对指定的url发起请求, 该函数返回一个响应对象,urlopen代表打开url ''' response = urllib....
urllib模块是Python标准库中的一个模块,它提供了一系列的方法和类,可以帮助我们进行URL处理、文件上传、cookie处理、代理设置等操作。这个方法用于打开一个URL地址,并返回一个类似于文件的对象。我们可以通过这个...

【代码】爬虫常用模块--urllib爬虫[头歌题解]
import urllib.request # 获取一个get请求 response = urllib.request.urlopen("http://baidu.com") print(response.read().decode("utf-8")) # 获取一个post请求 import urllib.parse data = bytes(urllib.parse....
推荐文章
- Java---简单易懂的KNN算法_jf.knn-%; 9 &-程序员宅基地
- 最新版ffmpeg 提取视频关键帧_从视频中获取flag-程序员宅基地
- 【ARM Cache 系列文章 11 -- ARM Cache 直接映射 详细介绍】
- Objective-C学习计划
- 【数据结构】最小生成树(Prim算法、Kruskal算法)解析+完整代码
- python访问组策略_python 模块 wmi 远程连接 windows 获取配置信息-程序员宅基地
- html把div做成透明背景,DIV半透明层 CSS来实现网页背景半透明-程序员宅基地
- 关机恶搞小程序
- mnist手写数字分类的python实现_TensorFlow的MNIST手写数字分类问题 基础篇-程序员宅基地
- wxpython窗口跳转_WxPython-用按钮打开一个新窗口-程序员宅基地