假设存在如下数据集mtk: 0 1 2 0 1 3 16250 1 4 1 14501 2 3 3 27772 3 1 3 29743 4 4 3 22985 mkt.rename(columns={0:'first',1:'second',2:'third'},inplace=1) 生成如下: ...
”pandas的那些事“ 的搜索结果
Python之sklearn-pandas:sklearn-pandas库函数的简介、安装、使用方法之详细攻略 目录 sklearn-pandas库函数的简介 sklearn-pandas库函数的安装 sklearn-pandas库函数的使用方法 1、基础用法 2、案例...

一.假设有数据集df df.isnull() 返回DateFrame,元素为空或者NA就显示True,否则就是False 二....df.isnull().any() ...当列有为空或者NA的元素,就为True,否则False ...三....,iris.columns[iris.isnull().any()].tolist() ...
使用pandas展示数据的所有行

Pandas日期时间格式化 当进行数据分析时,我们会遇到很多带有日期、时间格式的数据集,在处理这些数据集时,可能会遇到日期格式不统一的问题,此时就需要对日期时间做统一的格式化处理。比如“Wednesday, June 6, ...

Practice1-利用pandas创建Excel文件,并在其中添加一些内容。 在python中导入pandas库,注意这里可能还要下载 “openpyxl” -pip install openpyxl 才可以正常创建一个excel表格。程序如下: Excel文件: ...
1.按列取、按索引/行取、按特定行列取 ...from pandas import DataFrame import pandas as pd df=DataFrame(np.arange(12).reshape((3,4)),index=[‘one’,‘two’,‘thr’],columns=list(‘abcd’)) df[‘a’]
modin.pandas 确实能使得一部分函数使用多核cpu进行加速处理,但是现在有些功能还不完善,有些函数还是用的默认pandas处理… 具体哪些函数是可以加速的可以往下看看 主要测试了apply,groupby,read_csv 一、Modin....
版本兼容问题numpy和pandas


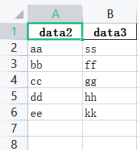
通过列名称来提取指定列。

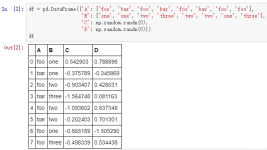
pandas 修改单元格的值 dfc = pd.DataFrame({'a':[1,2,3,4,5,6],'b':[2,3,4,5,6,7]}) dfc.loc[3, 'b'] = 'english' # 修改第3行b列的值 dfc.loc[4, 'b'] = 'english' # 修改第4行b列的值 # 条件修改 # 将'b'列行值...
一、 Pandas简介 1、Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具...
Pandas 显示所有行列数据 pd.set_option()函数
1.分组groupby ...pandas中,也有对应的groupby操作,下面我们就来看看pandas中的groupby怎么使用。 2.groupby的数据结构 首先我们看如下代码 def ddd(): levels = ["L1", "L1", "L1", "L2", "L2", "L3",
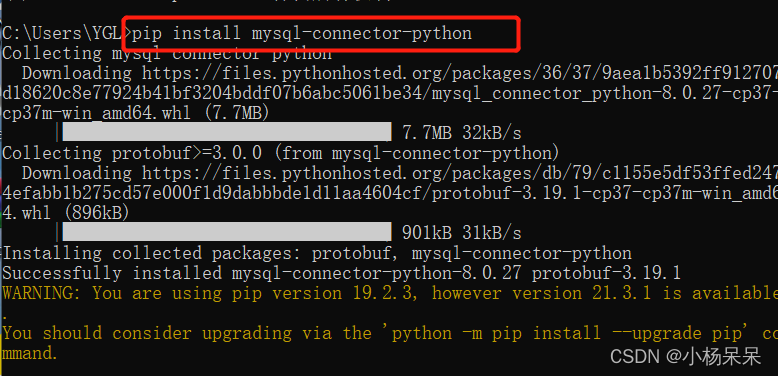
import pandas as pd # 连接数据库 connection = pymysql.connect( host='localhost', port=3306, user='root', password='123456', database='py' ) # 数据库操作 cursor=connection.cursor().

| 对应or & 对应and ~ 对应not

你可以使用PyCharm的软件包管理器来安装Pandas库。在PyCharm中,打开菜单栏中的“File”,然后选择“Settings”,然后选择“Project Interpreter”,然后点击右下角的“+”号,在弹出的搜索框中输入“pandas”,然后...
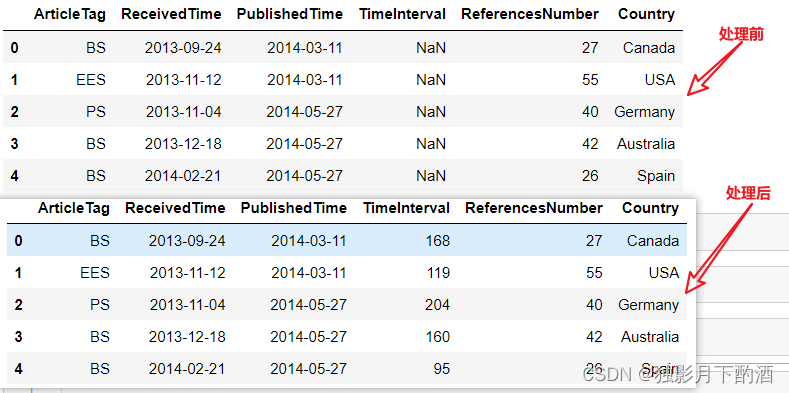
import pandas as pd import numpy as np df = pd.read_excel('附件1.xlsx') df['累计治愈人数']=0 df['累计治愈人数']=df.groupby('城市')['新增治愈'].cumsum() print(df) 日期 城市 新增确诊 新增治愈 新增死亡 ...
推荐文章
- php 上传图片 缩略图,PHP 图片上传类 缩略图-程序员宅基地
- scrapy爬虫框架_3.6.1 scrapy 的版本-程序员宅基地
- 微信支付——统一下单——java_小程序统一下单接口-程序员宅基地
- (已解决)报错 ValueError: Tensor conversion requested dtype float32 for Tensor with dtype resource-程序员宅基地
- 记录el-table树形数据,默认展开折叠按钮失效_eltable一刷新展开的子节点展开按钮消失-程序员宅基地
- 设计模式复习-桥接模式_csdn天使也掉毛-程序员宅基地
- CodeForces - 894A-QAQ(思维)_"qaq\" is a word to denote an expression of crying-程序员宅基地
- java毕业生设计移动学习网站计算机源码+系统+mysql+调试部署+lw-程序员宅基地
- 14种神笔记方法,只需选择1招,让你的学习和工作效率提高100倍!_1秒笔记 高级-程序员宅基地
- 最新java毕业论文英文参考文献_计算机毕业论文javaweb英文文献-程序员宅基地