2种方式解决Flink报错Exception in thread "main" org.apache.flink.api.common.functions.InvalidTypesException
”flink“ 的搜索结果


flink error
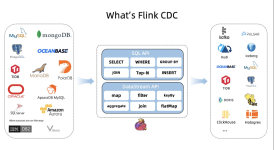
Flink CDC 是Apache Flink ®的一组源连接器,使用变更数据捕获 (CDC) 从不同数据库中获取变更。Apache Flink 的 CDC Connectors集成 Debezium 作为捕获数据更改的引擎。所以它可以充分发挥 Debezium 的能力。

直接上官网配置 JobManager 内存 | Apache Flink配置 JobManager 内存 # JobManager 是 Flink 集群的控制单元。它由三种不同的组件组成:ResourceManager、Dispatcher 和每个正在运行作业的 JobMaster。本篇文档将...
Flink整合Drools 将drl文件转换为字符串,存入到mysql中(将drools规则字符串,构造成KieSession对象),通过canal监听此表,存入kafka中,然后通过flink,当作广播流,主流中数据得到动态规则,进行匹配。 (1)drl...
flink 1.16 + flink-connector-mysql-cdc2.3 的依赖冲突问题总结。
根据下列文章,即可成功启动,这里偷懒直接参考下面这篇就好 https://blog.csdn.net/xinxin6193/article/details/112347736
1. 背景 Apache Flink 和 Apache Storm 是当前业界广泛使用的两个分布式实时计算框架。其中 Apache Storm(以下简称“Storm”)在美团点评实时计算业务中已有较为...而 Apache Flink(以下简称“Flink”)在近期倍.
Apache Flink入门到上手的视频教程,主要介绍了Flink的特性以及使用方式。
Flink技术栈及其适用场景
标签: Flink
Flink技术栈及其适用场景.pdf 这里介绍了flink组建的技术栈和使用场景,适合给使用Flink的同学进一步熟悉Flink


本文以案例的形式演示了 Flink CDC MySQL Connector 的使用。包括 MySQL 测试数据的准备、Flink CDC 源码编译、Flink 集群启动、Flink CDC MySQL Connector 与 Flink SQL 的结合使用。
导读:本文介绍如何导入Flink源代码,对源代码进行编译、构建及调试。作者:罗江宇 赵士杰 李涵淼 闵文俊来源:大数据DT(ID:hzdashuju)01 获取与导入Flink源代码1. ...
在Flink 1.6.0中,我们继续在较早版本中进行的基础工作:使Flink用户能够无缝地运行快速数据处理并毫不费力地构建数据驱动的数据密集型应用程序。 Flink的状态支持是使Flink在实现各种用例时如此通用和强大的关键...
本文的非常详细的介绍了 flink、如何进行大数据开发的,包含flink读取kafka、文本读取,hdfs
flink kafka实现反序列化: package Flink_Kafka; import com.alibaba.fastjson.JSON; import org.apache.flink.api.common.serialization.DeserializationSchema; import org.apache.flink.api.common.typeinfo....
flink
flink的yarn提交模式
Flink 的状态保存和恢复
标签: flink
flink介绍PPT
标签: flink
flink介绍的PPT,快速学习flink,了解最新批流处理框架

Flink入门及实战最新内容分享,包含Flink基本原理及应用场景、Flink vs storm vs sparkStreaming、Flink入门案例-wordCount、Flink集群安装部署standalone+yarn、Flink-HA高可用、Flink scala shell代码调试

推荐文章
- NSFuzz:TowardsEfficient and State-Aware Network Service Fuzzing-程序员宅基地
- 刘睿民畅谈大数据:政府应紧急设立首席数据官-程序员宅基地
- nginx 编译安装依赖包_nginx编译怎么添加新的依赖库-程序员宅基地
- Python+OpenCV+Tesseract实现OCR字符识别_python + opencv + tesseract-程序员宅基地
- 微型计算机主板上的主要部件,微型计算机主板上安装的主要部件-程序员宅基地
- 推荐一款可匹敌国际大厂的国产企业级低无代码平台_国产私有化 无代码-程序员宅基地
- UE4 蓝图 实现 数组的边遍历边删除_ue4 数组删不掉-程序员宅基地
- python爬虫之bs4解析和xpath解析_from bs4 import beautifulsoup xpath-程序员宅基地
- MySQL配置环境变量-程序员宅基地
- VGG16进行微调,训练mnist数据集_vgg16 tensorflow 2 mnist-程序员宅基地