解决运行Hadoop不出现datanode或者namenode问题
”datanode“ 的搜索结果
1.DataNode是什么? 2.DataNode做什么? 3.DataNode怎么做? 1.DataNode是什么? Datanode是HDFS文件系统的工作节点,它们根据客户端或者是namenode的调度进行存储和检索数据,并且定期向namenode发送它们所存储...

在启动Hadoop之前,进行了多次的格式化,导致DataNode的ID发生了变化。 二、问题解决方法 我们可以让NameNode的clusterID与DataNode的clusterID一致,这样就可以解决这个问题了。 1.首先去到你的hadoop目录下 ...
start-all.sh无法启动datanode,start datanode也无法启动

网上已经有许多答案来说明为什么缺少DataNode了,(主要是我只知道个大概,不能误人子弟啊) 恕我在此直接上解决方法了。 note: 由于在启动hadoop之前,多次格式化,导致DataNode的ID改变, 由此把DataNode的ID改成...
配置完impala后重启集群,使用jps后发现所有datanode都没启动。
找到hdfs-site.xml文件下的dfs.data.dir 目录,然后对里面的data文件夹执行删除。首先可以查看master节点的datanode的日志文件,在启动时会有显示日志文件所在目录。然后再重新格式化名称节点。

HDFS集群包括,NameNode和DataNode以及Secondary Namenode。NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息;DataNode 负责管理用户的文件数据块,每一个数据块都可以在多个...

2021-12-07 13:50:58,734 ERROR datanode.DataNode (BPServiceActor.java:run(829)) - Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to dn27.hadoop.unicom/10....

lready been used. 2020-07-29 19:06:58,917 INFO org.apache.hadoop.hdfs.server.common.Storage: Storage directory [DISK]file:/opt/data2/ has already been used. 2020-07-29 19:06:58,948 INFO org.apache....
Hadoop的datanode进程无法启动解决方案 Hadoop含有path路径,在主节点执行start-all.sh,输入jps查看进程 start-all.sh jps 发现节点中DataNode进程没有启动。 解决方案 第一种: 每次格式化前,要先关闭,然后再...
多次重新初始化hadoop namenode -format后,DataNode或NameNode没有启动
在hadoop启动hdfs的之后,使用jps命令查看运行情况时发现hdfs的DataNode并没有打开。 笔者出现此情况前曾使用hdfs namenode -format格式化了hdfs 如有三个hadoop集群,分别为hadoop102,hadoop103,hadoop104 其问题...
查看日志如下: 2016-04-14 04:07:58,821 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool (Datanode Uuid unassigned) service to itcast01/192.168.1.20...
Error: DataXceiver error processing WRITE_BLOCK operation src: /x.x.x.x:50373 dest: /x.x.x.x:50010 Solution: 1.修改进程最大文件打开数 sudo vim /etc/security/limits.conf End of file ...
去DataNode节点执行jps命令,没有名为DataNode的进程; 解决 停止yarn和hdfs(我这里的hadoop部署在~目录下,请根据您自己的部署目录调整下面的命令): ~/hadoop-2.7.7/sbin/stop-yarn.sh && ~/


Hadoop datanode启动失败:Hadoop安装目录权限的问题

浅谈DataNode工作机制
另:因为hdfs自身复制机制,所以没必要在Datanode上使用RAID机制。**所需Datanode个数(当月):9.450/1800 ~= 6 **根据数据量及Hadoop参数计算Datanode的个数。如果要计算全年数据量所需要节点数,需考虑到月增长率。
当新的DataNode结点进入系统时,需安装Hadoop系统。 注意新创建的结点的用户名,需与其它结点相同(即集群中所有机器系统中用户名均一致),方便秘钥分发。 参见:Ubuntu安装Hadoop,并使用Python3调用...
但是在/opt/module/hadoop-2.7.2/data/tmp/dfs/data目录(datanode的目录)下没有内容。 - namenode和datanode是启动了的。 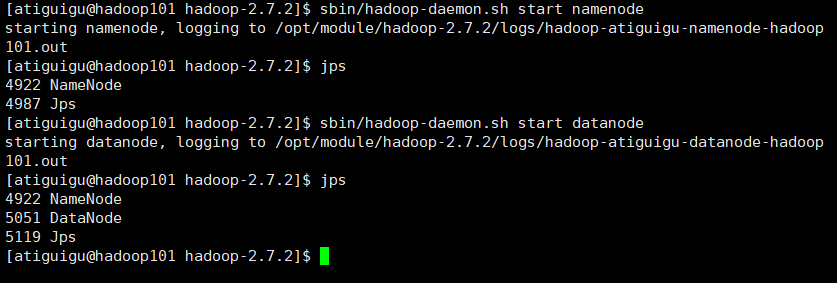 - ...
推荐文章
- Python爬虫绕过登录的小技巧_python 爬虫 跳过会员限制-程序员宅基地
- 安装 GMP、NTL、CTMalloc ,编译 OpenFHE_openfhe安装-程序员宅基地
- 外包干了2个月,技术退步明显。。。。。
- Copilot Venture Studio創始合伙人楊林苑確認出席“邊緣智能2024 - AI開發者峰會”
- Python协程(上)-程序员宅基地
- linux 磁盘管理
- 【华为】华为防火墙双机热备
- 企业计算机服务器中了helper勒索病毒怎么办?Helper勒索病毒解密处理流程
- 简单聊聊JavaScript数组作为索引
- SpringCloud学习笔记1——入门篇_子模块继承之后,提供作用:锁定版-程序员宅基地