Datanode是HDFS文件系统的工作节点,它们根据客户端或者是namenode的调度进行存储和检索数据,并且定期向namenode发送它们所存储的块(block)的列表。
”datanode“ 的搜索结果
在HDFS中,NameNode和DataNode之间通过RPC进行通信,以实现元数据的交换和数据的读写操作。具体来说,当NameNode需要与DataNode通信时,它会通过RPC调用DataNode的特定方法,如发送数据块、接收数据块等。同时,...
因业务需要搭建一个新hadoop集群,并将老的hadoop集群中的数据迁移至新的hadoop集群,而且datanode节点不能全部上线,其中还可能会出现节点上线或下线的情况,这个时候就很容易出现机器与机器之间磁盘的均衡的情况,...
TCP 50010 dfs.datanode.address 数据传输端口 TCP 50020 dfs.datanode.ipc.address ipc 服务器 TCP 50075 dfs.datanode.http.address http 服务器 TCP 50475 dfs.datanode.https.address https 服务器 例子 docker ...
HDFS DataNode定义的存储目录不正确或HDFS的存储规划变化时,需要修改DataNode的存储目录,以保障HDFS的正常工作,假定我们现在对应的HDFS数据盘位置为:/hadoop/hdfs/data; 预将数据目录迁移至/data/hadoop/hdfs/...
DataNode职责
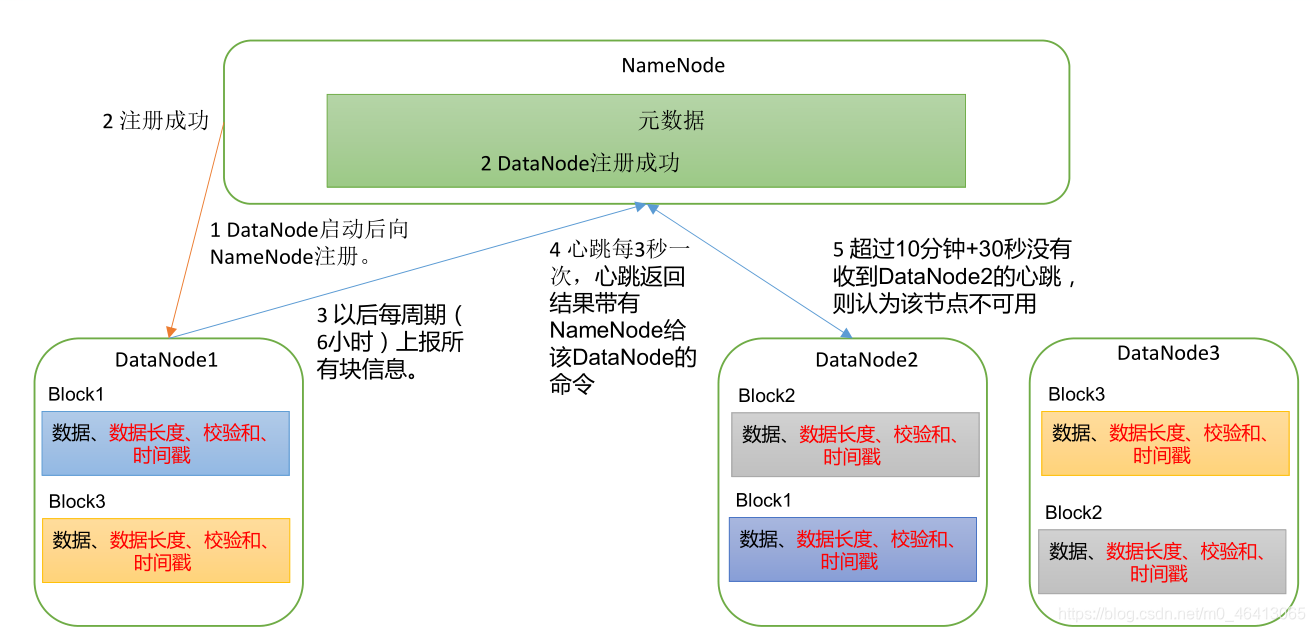
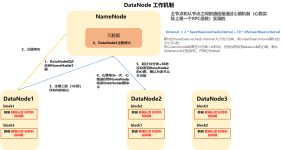
1. DataNode工作机制 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。 2)DataNode启动后向NameNode注册,通过后,...
本文主要分析了hadoop客户端read和write block的流程. 以及client和datanode通信的协议, 数据流格式等
Hadoop datanode重新加载失败无法启动解决.docx
生产环境需要把VERSION里面的数据拷贝到datanode里面.正常启动后是这样的。最后重启把namenode和datanode里面数据删除掉。重新格式化,再启动hadoop集群,就解决了。这里也没有节点数据,而是空的,这个图是正常的。...

DataNode启动分析 主方法 DataNode通过DataNode.java的main方法进行启动,因为经过的方法太多,只说几个重点的。 secureMain方法 public static void secureMain(String args[], SecureResources resources) { try ...
从节点JPS没有dataNode的解决办法查看logs日志文件,找到Hadoop的安装目录下logs目录,用cat hadoop-root-datanode-localhost.localdomain.log进行日志查看1、java.net.BindException: 无法指定被请求的地址另一种...
DataNode-Exporter
标签: 大数据
go语言编写的万能采集DataNode jmx指标二进制文件 所有CDH 版本 有DataNode实例机器均可执行。 没有不会报错,会一分钟重试。 采集了以下三类指标 Hadoop:service=DataNode,name=DataNodeActivity Hadoop:service=...
hadoop-3.3.0 dn启动源码
数据块在 DataNode 上以文件形式存储在磁盘上 : - 数据本身 - 元数据 : 数据块的长度,块数据的校验和,时间戳 流程 : 1. DataNode 启动后向 NameNode 注册 2. 以周期性 (6 小时) 向 NameNode 上报所有的块信息 ...

第6章 DataNode(面试开发重点) 6.1 DataNode工作机制 DataNode工作机制,如图3-15所示。 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块...
发现这两个id不一致,经查阅相关资料,id不一致会导致Initialization failed for Block pool。线上收到hadoop集群datanode掉线告警。然后再次尝试启动datanode进程。发现未存在datanode进程。
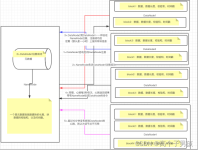
该问题因为多次对namenode进行format,每一次format主节点NameNode产生新的clusterID、namespaceID,于是导致主节点的clusterID、namespaceID与各个子节点DataNode不一致。当format过后再启动hadoop,hadoop尝试创建...
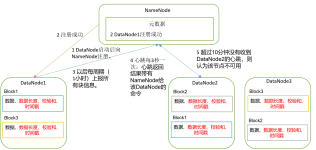

故每次启动的时候,datanode都有扫描一遍节点,将存储的文件信息(当前节点上所有block块信息)传送给namenode(这个关系每次重启都会动态加载)1 block 与文件的信息(fsimage,edits)namenode启动时会将元数据...
DataNode是什么
标签: hdfs
DataNode是一个在HDFS实例中单独机器上运行的软件节点。通常Hadoop集群包含一个NameNode和大量DataNode。DataNode通常以机架的形式组织,所有机架通过一个交换机将所有系统连接起来。 DataNode响应来自HDFS客户机...
推荐文章
- 计算机AMD方案不超过4000元,4000元左右AMD R5-1400配RX570全新芯片显卡电脑配置推荐...-程序员宅基地
- qt for ios扫描二维码功能实现-程序员宅基地
- 【漏洞复现】用友-U8C-反序列化-TableInputOperServlet-程序员宅基地
- 大型园区网络建设与管理-802. 1 x 认证体系7.4-程序员宅基地
- Unity Build IOS包_ios build unity-程序员宅基地
- Unity3d的安装-程序员宅基地
- Python爬虫周记之案例篇——基金净值Selenium动态爬虫-程序员宅基地
- STM32F103ZET6移植FreeRTOS_stm32f103zet6 free-程序员宅基地
- Maven之(一)Maven是什么_maven是什么?可以做哪些工作?-程序员宅基地
- 微信小程序(抖音小程序):手机号码解析失败解决方案_微信小程序解析手机号-程序员宅基地