”attention“ 的搜索结果

@inproceedings{wiegreffe-pinter-2019-attention, title = "Attention is not not Explanation", author = "Wiegreffe, Sarah and Pinter, Yuval", booktitle = "Proceedings of the 2019 Conference on ...
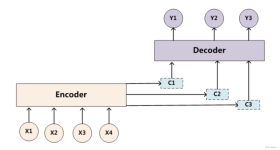
Attention的原理和实现 目标 知道Attention的作用 知道Attention的实现机制 能够使用代码完成Attention代码的编写 1. Attention的介绍 在普通的RNN结构中,Encoder需要把一个句子转化为一个向量,然后在Decoder中...

Attention 正在被越来越广泛的得到应用。尤其是 BERT 火爆了之后。 Attention 到底有什么特别之处?他的原理和本质是什么?Attention都有哪些类型?本文将详细讲解Attention的方方面面。 Attention 的本质是...
cnn+lstm+attention对时序数据进行预测 博客链接: https://blog.csdn.net/qq_30803353/article/details/121875376 1、摘要 本文主要讲解:bilstm-cnn-attention对时序数据进行预测 主要思路: 对时序数据进行分块,...
1.由来 在Transformer之前,做翻译的时候,一般用基于RNN的...输入的x1,x2x_{1},x_{2}x1,x2,共同经过Self-attention机制后,在Self-attention中实现了信息的交互,分别得到了z1,z2z_{1},z_{2}z1,z2,将z1,z2
论文“具有自适应Attention-GRU模型的品牌级排名系统[C]”的代码。 (接受IJCAI 2018) 运行命令:python train.py --buckets“ ./data/” --checkpointDir ./log/ --exp debug --m1 1 --m2 0 --m3 1 参数:“ ...
Attention-BiLSTM模型结构及所有核心代码: 1.model中实验的模型有BiLSTM、ATT-BiLSTM、CNN-BiLSTM模型; Attention与BiLSTM模型首先Attention机制增强上下文语义信息,并获取更深层次特征,最后通过Softmax进行回归...
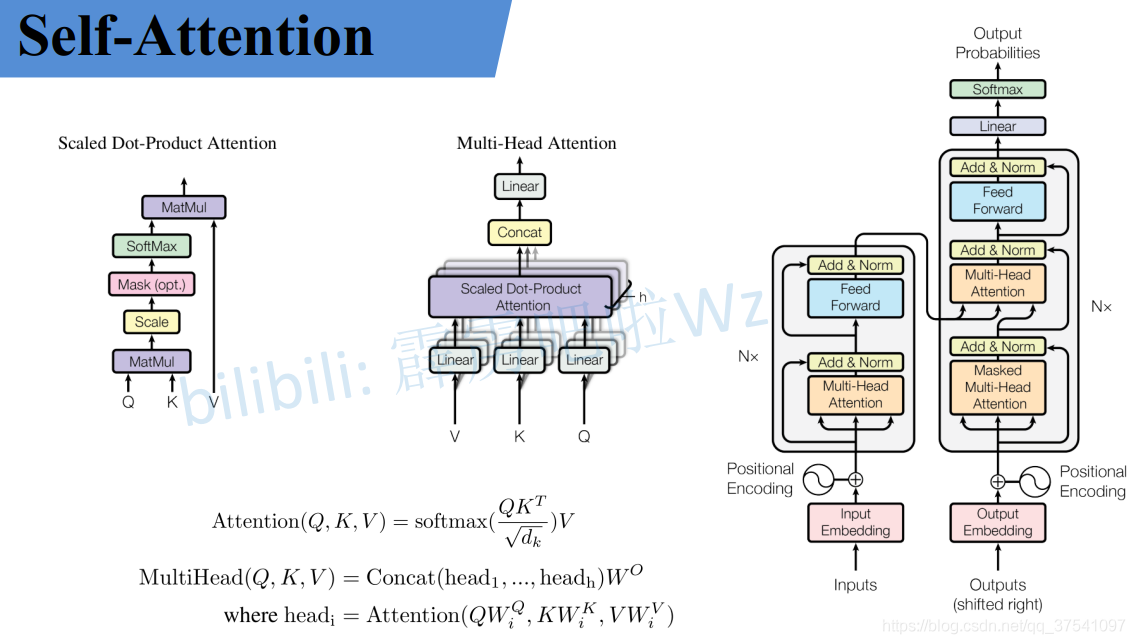
Attention Is All You Need
为了更准确地提取文本特征并提高化工事故分类的准确性,该文提出了一种基于Attention机制的双向LSTM (BLSTM-Attention)神经网络模型对化工新闻文本进行特征提取并实现文本分类.BLSTM-Attention神经网络模型能够...
基于attention文本分类代码基于attention文本分类代码基于attention文本分类代码
自关注与文本分类 本仓库基于自关注机制实现文本分类。...$ python imdb_attention.py 比较结果 算法 训练时间(每纪元) Val准确率 Val损失 所需Epoch数 LSTM 116秒 0.8339 0.3815 2 双向LSTM
各种Unet模型用于图像分割的实现-Unet,RCNN-Unet,注意力Unet,RCNN-Attention Unet,嵌套式Unet细分Unet细分-Pytorch-Nest-of-Unets各种Unet模型用于图像分割的实现UNet- U-Net:用于生物医学图像分割的卷积网络...
安装$ pip install local-attention用法 import torchfrom local_attention import LocalAttentionq = torch . randn ( 8 , 2048 , 64 )k = torch . randn ( 8 , 2048 , 64 )v = torch . randn ( 8 , 2048 , 64 )...
基于torch实现cnn+lstm+attention 模型时间序列预测代码模板 通用
$ pip install axial_attention 用法 图像 import torch from axial_attention import AxialAttention img = torch . randn ( 1 , 3 , 256 , 256 ) attn = AxialAttention ( dim = 3 , # embedding dimension
ResNet_Attention(CBAM,SE) 官方说明: , 所需环境Ubuntu20.04 GTX 1080Ti Python3.7 PyTorch 1.7.0 CUDA10.2 CuDNN7.0使用方法(带有CIFAR10的trian) 该模型的主干是ResNet。 在我们的培训中,我们使用CIFAR10...
以下代码创建了一个注意力层,它遵循第一部分中的方程( attention_activation是e_{t, t'}的激活函数): import kerasfrom keras_self_attention import SeqSelfAttentionmodel = keras . models . Sequential ()...
matlab,代码详细说明,自己出的,完全可运行使用
为此,以网络层次结合的方式设计了CRNN并引入attention机制,提出一种Text-CRNN+attention模型用于文本分类。首先利用CNN处理局部特征的位置不变性,提取高效局部特征信息;然后在RNN进行序列特征建模时引入...
class channel_attention ( tf . keras . layers . Layer ): """ channel attention module Contains the implementation of Convolutional Block Attention Module(CBAM) block. As described in ...
基于卷积-双向长短期记忆网络结合SE注意力机制(CNN-BiLSTM-SE Attention)的分类预测Matlab完整程序 基于卷积神经网路-双向长短期记忆网络结合SE注意力机制的数据分类预测 1.运行环境Matlab2020b及以上; 2.输入12...
gpu-attention-mse: 6124.498347838368 gpu-attention-rmse: 78.25917420876844 gpu-attention-r2: 0.2341441452949955 lstm-mse: 131972.16113071027 lstm-rmse: 363.27972848854404 lstm-r2: -15.502845869115102 ...
主要功能:数据清洗、文本特征提取(word2vec / fastText)、建立模型(BiLSTM、TextCNN、CNN+BiLSTM、BiLSTM+Attention) 注:资源内包含所有第三方模块的对应版本,百分百可运行,诚信。 博客链接:...
$ pip install nystrom-attention 用法 import torch from nystrom_attention import NystromAttention attn = NystromAttention ( dim = 512 , dim_head = 64 , heads = 8 , num_landmarks = 256 , # number of...
Attention Is All You Need主要的序列转导模型基于复杂的递归或卷积神经网络,包括编码器和解码器。性能最好的模型还通过注意机制连接编码器和解码器。我们提出了一种新的简单网络结构,即Transformer,它完全基于...
相关文章程式码范例多头注意力import torchfrom self_attention_cv import MultiHeadSelfAttentionmodel = MultiHeadSelfAttention ( dim = 64 )x = torch . rand ( 16 , 10 , 64 ) # [batch, tokens, dim]mask = ...
推荐文章
- Response使用 application/octet-stream 响应到前端_application/octet-stream;charset=utf-8-程序员宅基地
- 利用MultipartFile实现文件上传_实现了multipartfile file上传文件时要选择一个栏目,传给后端一个栏目id,如何实现-程序员宅基地
- muduo之Singleton_muduo singleton-程序员宅基地
- html5 动态存储 localStorage.name 和localStorage.setItem()的差别_localstorage.setitem('aa')和localstorage.aa一样吗-程序员宅基地
- 02.loadrunner之http接口脚本编写_http脚本-程序员宅基地
- The server time zone value ‘�й���ʱ��‘ is unrecognized or represents more than one time zone.-程序员宅基地
- 如何打造企业短视频账号的人设?_做的比较有人格化的公司短视频账号-程序员宅基地
- 一个会做饭的程序员如何每天给女朋友带不同的便当?-程序员宅基地
- PendingIntent重定向:一种针对安卓系统和流行App的通用提权方法——BlackHat EU 2021议题详解 (下)_getrunningservicecontrolpanel-程序员宅基地
- python 之 面向对象(反射、__str__、__del__)-程序员宅基地