agent 没有错,可以用, 但是如果网站反爬措施强一点,用固定的请求头可能就有点问题, 所以我们就需要设置一个随机请求头,在这里,我分享一下我自己一般用的三种设置随机请求头方式, 学到的就点个..
”Python反爬“ 的搜索结果
Cookies的处理作用保存客户端的相关状态在爬虫中如果遇到了cookie的反爬如何处理?手动处理在抓包工具中捕获cookie,将其封装在headers中应用场景:cookie没有有效时长且不是动态变化自动处理使用session机制使用场景:...

看到它返回的HTML代码,下面的数据也是空的,也就是说,网站现在是检测到我们使用的是selenium,然后就被反爬了,不输出数据。那么我们这时候就需要回头看一下,selenium是怎么被反爬的。
好久没有更新博客了,心里空落落的,这次分享我的Python爬虫反爬策略三部曲,拥有这三步曲就可以在爬虫界立足了,哈哈哈~~~~~~ 浏览器伪装 IP代理池和用户代理池构建 动态页面加载解决方法 网站反爬机制常用的...
我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了。 我把js反爬分为参数由js加密生成和js生成cookie等来操作浏览器这两部分,今天说的是第二种情况。 目标...
今天给你分享一下篇反反爬的实例。一个思路,也许给你带来些许启发..也许你会遇到这样的请款:打开某个网站,可以看到页面是正常显示的,但是当你通过 Python去请求的时候,你会得到一堆无厘头的 JS..像这样的操作,...
现在很多网站为防止爬虫,加载的数据都使用js的方式加载,如果使用python的request库爬取的话就爬不到数据,selenium库能模拟打开浏览器,浏览器打开网页并加载js数据后,再获取数据,这样就达到反反爬虫,selenium...
pyppeteer防反爬干扰脚本 selenium爬虫可能会被检测到,此脚本配合pyppeteer等可以完美绕过

Python爬虫反反爬总结
标签: 爬虫
针对以下各反爬手段的反制措施 Headers 最基本的反爬手段,一般被关注的变量是UserAgent和Refer,可以考虑使用浏览器里的。其中的ContentLength字段requests包会填写,可以不用。Content-Type字段是post表单的格式...
【代码】Python DB小小反爬。
Python征指纹反爬是一种反爬虫技术,它通过识别请求中的特定特征指纹来检测和阻止爬虫。其中,JA3指纹是一种用于识别TLS客户端的指纹算法,可以在改变IP地址和User Agent(UA)的情况下仍然识别到请求的来源。 要在...
我们都知道Python用来爬数据,为了不让自家的数据被别人随意的爬走,你知道怎么反爬吗?今天播妞带着大家一起见识见识常见的反爬技术。 首先我们来看一下爬虫程序和反爬虫之间的一张逻辑图: 以下说4种网站反爬虫...
大家在日常生活中经常需要查找不同的事物的相关信息,今天我们利用python来实现这一个小功能,1.部署爬虫时要先思考好大步骤,最好能把步骤写下来,然后一步一步逐步去写代码; 2.再仔细去浏览网页,确然好你爬的信息...

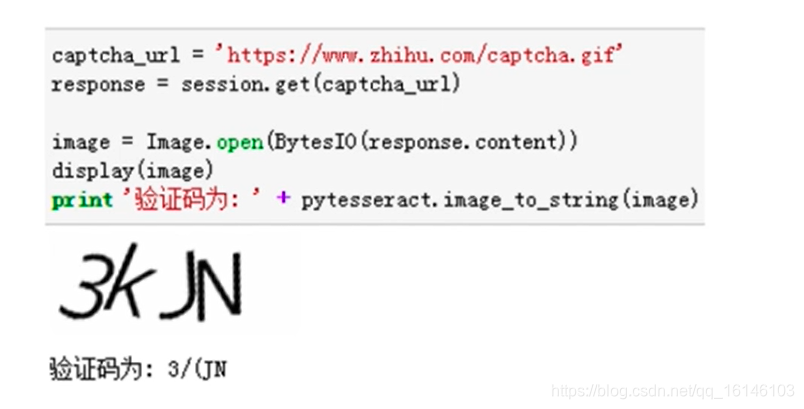
Python爬取图片时,有时会遇到一些反爬措施,下面是一些常见的反爬方法及对应的应对策略: 1. 验证码:有些网站在图片请求前会先返回一个验证码页面,要求用户输入验证码才能继续访问。对于这种情况,可以使用第三...
该楼层疑似违规已被系统折叠...对于Python爬虫来说,有哪些常见的反反爬策略呢?一、设置等待时间很多反爬策略都包含了检测访问频率,一旦发现了超人类访问速度,坚决封杀,既然如此,那就模仿人工访问频率,访问...
为了应对爬虫被网站的反爬虫机制所阻止的情况,可以采取一些反反爬的方法。其中一种常见的方法是模拟浏览器...总之,针对Python爬虫被反爬虫机制所阻止的情况,可以采取上述方法进行反反爬处理,提高爬取数据的成功率。
通过knn算法来识别网站的字体。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
爬虫与反爬爬虫:自动获取网站数据的程序,关键是批量的获取。反爬虫:使用技术手段防止爬虫程序的方法误伤:反爬技术将普通用户识别为爬虫,从而限制其访问,如果误伤过高,反爬效果再好也不能使用(例如封ip,只会...
字体反爬也就是自定义字体加密映射,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的。 2.查看字体软件font ...

最近在做python爬虫,爬取芜湖市民心声网站的时候,requests库爬取的html代码显示“请开启JavaScript并刷新该页”。郁闷了很久,百度也找不到解决办法。。。最终解决,现与大家分享: 在此之前,爬取其他网站到没有...
一、 什么是代理? 二、 代理服务器的作用 可以进行请求的响应和转发 三、 在爬虫中为何要使用代理 如果我们使用爬虫对一个网站在一段时间内发起一个高频请求,该网站会检测出这个异常的现象,并将异常的请求 IP...
该楼层疑似违规已被系统折叠...对于Python爬虫来说,有哪些常见的反反爬策略呢?一、设置等待时间很多反爬策略都包含了检测访问频率,一旦发现了超人类访问速度,坚决封杀,既然如此,那就模仿人工访问频率,访问...
基于Python3的JS逆向、反反爬、验证码处理、登录签到抽奖、数据可视化源码.zip 基于Python3的JS逆向、反反爬、验证码处理、登录签到抽奖、数据可视化源码.zip 基于Python3的JS逆向、反反爬、验证码处理、登录签到...
通过UA来判断不同的设备或者浏览器是开发者最常用的方式方法,这个也是对于Python反爬的一种策略,但是有盾就有矛啊 写好爬虫的原则只有一条: 就是让你的抓取行为和用户访问网站的真实行为尽量一致 1、伪造UA字符串...
推荐文章
- 企业级数据分析平台/springBoot-controller全局异常管理_naga数据分析平台-程序员宅基地
- Matlab 读取批量txt格式的气象数据_读取气象a文件-程序员宅基地
- c#使用WPD读取便携式设备信息一(枚举设备、连接设备及读取设备信息)_c#获取此电脑的便携设备信息-程序员宅基地
- Java乐观锁-程序员宅基地
- ibatis出现java.sql.SQLException: Io 异常: Connection reset_java.sql.sqlexception: connection reset-程序员宅基地
- Redis-布隆过滤器(Bloom Filter)详解-程序员宅基地
- js给div添加值_js给div添加内容-程序员宅基地
- oracle数据库中最常用的sql语句_oracle数据库常用sql-程序员宅基地
- map-server保存地图参数设置,使地图二值化_二值化 地图 生成器-程序员宅基地
- @ConditionalOnBean 与Bean注册优先级_conditionalonbean顺序-程序员宅基地