本次采集的案例是点起中文,你可以随机打开一本目标xiaoshuo,检查一下网络请求中是否存在字体文件响应数据。
”Python反爬“ 的搜索结果

1.前期准备具体请查看上一篇2....具体思路企查查网站具有一定的反爬机制,直接爬取会受到网站阻拦,所以我们需要模拟浏览器请求,绕过反爬机制,打开企查查网站,获取cookie及一系列请求头文件,然后使用Be...
我们都知道Python用来爬数据,为了不让自家的数据被别人随意的爬走,你知道怎么反爬吗?今天播妞带着大家一起见识见识常见的反爬技术。 很多人学习python,不知道从何学起。 很多人学习python,掌握了基本语法过后...
刚刚对着视频爬了下豆瓣成功了,然后试了试CSDN,状态码400,是不是被反爬了
遇到字体反爬如何处理在爬虫中往往会碰到一些自定义字体的反爬,也就是在打开一个页面的时候,我们是可以看到对应的在页面是看的到的数据的,但是,通过检查发现在element中,我们是看不到真实的数据的,比如在猫眼...
在使用 Python 爬取付费音乐时,有几点需要注意: 侵犯版权是违法行为,因此您需要确保您有权进行爬取。 如果您想爬取付费音乐,可能需要使用一些反爬虫技术来避免被网站封禁。这可能包括使用代理服务器、随机化...


cookies的处理作用保存客户端的相关状态在爬虫中如果遇到了cookie的反爬如何处理?手动处理在抓包工具中捕获cookie,将其封装在headers中应用场景:cookie没有有效时长且不是动态变化自动处理使用session机制使用场景:...
最后的反爬机制示例展示了如何模拟登录以绕过一些网站的登录限制获取数据。 在爬虫过程中,有些网站可能会采取一些措施来防止被爬取,这就是反爬机制。反爬机制旨在阻止爬虫程序正常访问网站或获取数据,以保护网站...
Python爬虫是一个强大的工具,可以用于获取互联网上的各种信息。然而,随着反爬机制的不断发展,爬虫开发者需要不断学习和更新知识,以应对各种挑战。同时,也要遵守法律法规和网站的使用协议,尊重他人的权益。

【代码】Python 小小反爬。
Python Selenium是一个自动化测试框架,可以模拟人工操作浏览器,但是网站在防爬抓...总之,Python Selenium反爬需要我们根据实际情况不断分析,灵活运用各种技巧避开反爬机制,使得我们能够更有效率地获取网站的信息。
Python常见反爬与反反爬
标签: python
一.request请求头限制 accept:text/html,...q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 accept-encoding: gzip, deflate, br ...cache-control: max-age=0 cookie: tk_tra.
Python爬虫反爬手段讲解
标签: python
反爬方式的种类 1、判断请求头来进行反爬 这是很早期的网站进行的反爬方式 User-Agent 用户代理 referer 请求来自哪里 cookie 也可以用来做访问凭证 解决办法:请求头里面添加对应的参数(复制浏览器里面的数据...

python爬虫 - 反爬之登陆状态二次验证
网站有没有反爬,如果你没有用爬虫抓取过,你是不可能知道的。就算要测试,你还要尝试不同的delay。如果设置的 delay 在网站的反爬频率外,那就测不出来。如果在频率内,那就被封。或者封ip,或者封账号。如果一定要...
Python爬虫常常会遇到反爬措施,以下是常见的反爬措施和应对方案: 1. 通过User-Agent来控制访问:某些网站会根据User-Agent来判断是否是爬虫,因此我们可以在请求中设置一个合理的User-Agent来模拟正常的浏览器访问...
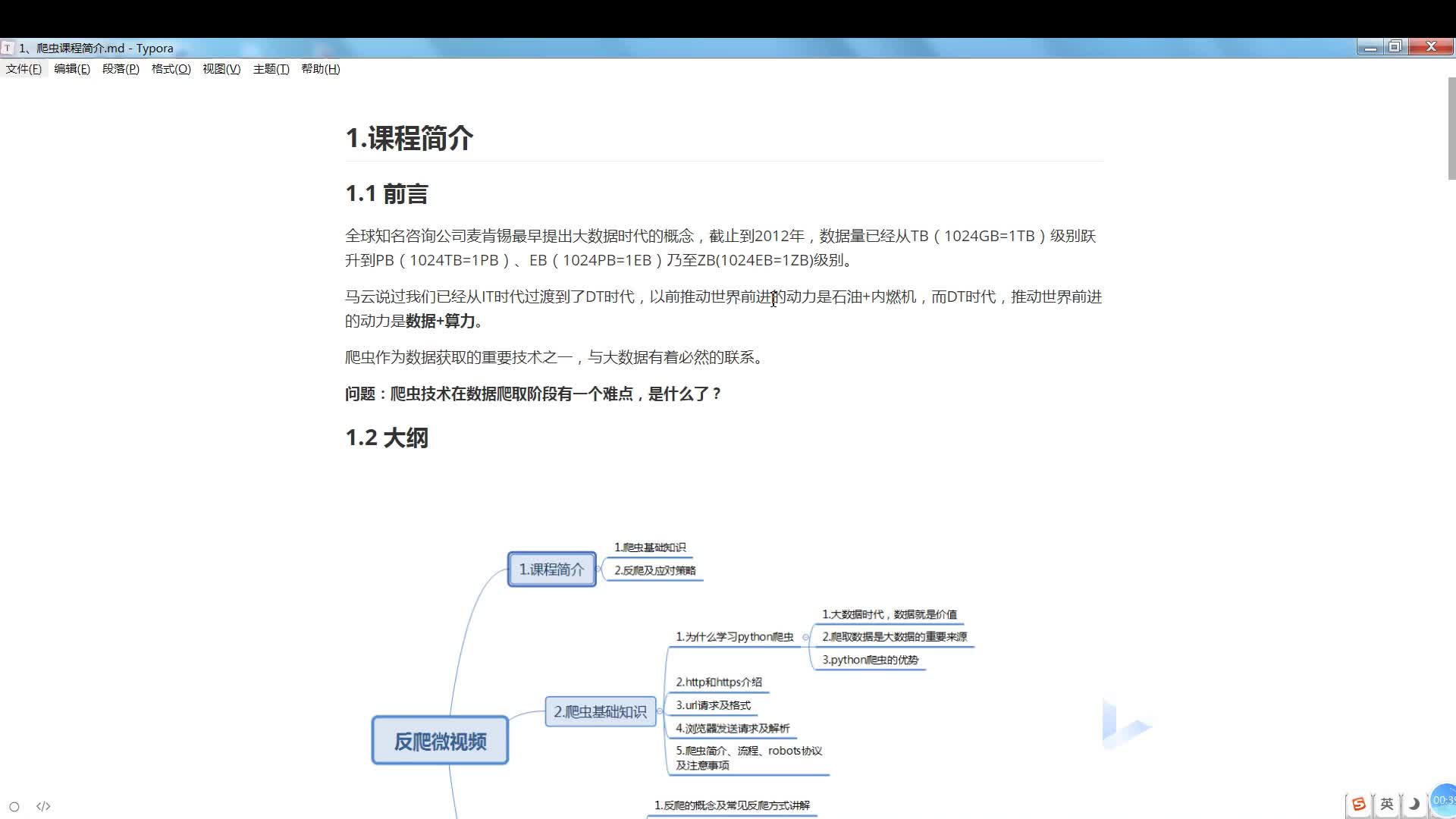
系列课程大纲 - Python爬虫技术精通 1. **Python爬虫入门基础** - 1.1 爬虫概念及其工作原理 - 1.2 Python环境搭建与爬虫库介绍 - 1.3 爬虫的合法性与道德规范 2. **网络请求与HTML基础** - 2.1 HTTP协议基础 -...
driver.get('http://cpquery.cnipa.gov.cn/') driver.find_element_by_xpath('//*[@id="username1"]').send_keys('13******')## 输入账号 操作点击或输入元素就拒绝访问 刷新就是一个空白页面,已经被这种反爬网站...
Python爬虫的反爬之路开始啦
目标爬取京东商城上iphone x用户评论数据;使用jieba对评论数据进行分词处理;使用wordcloud绘制词云图。进群:548377875即可获取数十套pdf哦!然后我们会发现这个接口地址是可以直接访问的,并不需要post参数,直接...
反爬比较严的网站会识别selenium driver中的js属性,导致页面加载识别,可以通过本地手动驱动浏览器解决。 启动方式:在windows或者mac下找到浏览器执行文件,然后运行:/Applications/Google\ Chrome.app/Contents/...
一、MD5加密 MD5加密是一种被广泛使用的线性散列算法,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整的一致性。且MD5加密之后产生的是一个固定长度(32位或16位)的数据。...
在使用 Python 的 requests 库进行爬虫时,可能会遇到反爬措施,这时需要进行一些对应的处理,以下是一些常用的反爬处理方法: 1. 伪装请求头:将请求头中的 User-Agent 设置为浏览器的 User-Agent,模拟浏览器的...
关于Python爬虫基础知识、爬虫实例和反爬机制 # Python爬虫基础知识 ## 什么是爬虫? 爬虫(也称为网络爬虫、网页抓取器)是一种自动化程序,用于从互联网上收集信息。它们通过HTTP请求访问网页,并从网页中提取...
推荐文章
- 阿里云企业邮箱的stmp服务器地址_阿里云stmp地址-程序员宅基地
- c++ 判断数学表达式有效性_高考数学大题如何"保分"?学霸教你六大绝招!...-程序员宅基地
- 处理office365登录出现服务器问题_o365登陆显示网络异常-程序员宅基地
- Nginx RTMP源码分析--ngx_rtmp_live_module源码分析之添加stream_ngx_rtmp_live_module 原理-程序员宅基地
- 基于Ansible+Python开发运维巡检工具_automation_inspector.tar.gz-程序员宅基地
- Linux Shell - if 语句和判断表达式_shell if elif-程序员宅基地
- python升序和降序排序_Python排序列表数组方法–通过示例解释升序和降序-程序员宅基地
- jenkins 构建前执行shell_Jenkins – 在构建之前执行脚本,然后让用户确认构建-程序员宅基地
- 如何完全卸载MySQL_mysql怎么卸载干净-程序员宅基地
- AndroidO Treble架构下HIDL服务查询过程_found dead hwbinder service-程序员宅基地