反爬虫的方式有:不返回网页、返回数据非目标网页、增加获取数据的难度。
”Python反爬“ 的搜索结果

Python反爬平台搭建(小白快速入手Web爬虫)
[Python爬虫]常用反爬技术
python 爬虫 请求百度翻译之详细翻译(解决第二个反爬:Cookie)
Python常见反爬类型
标签: 爬虫
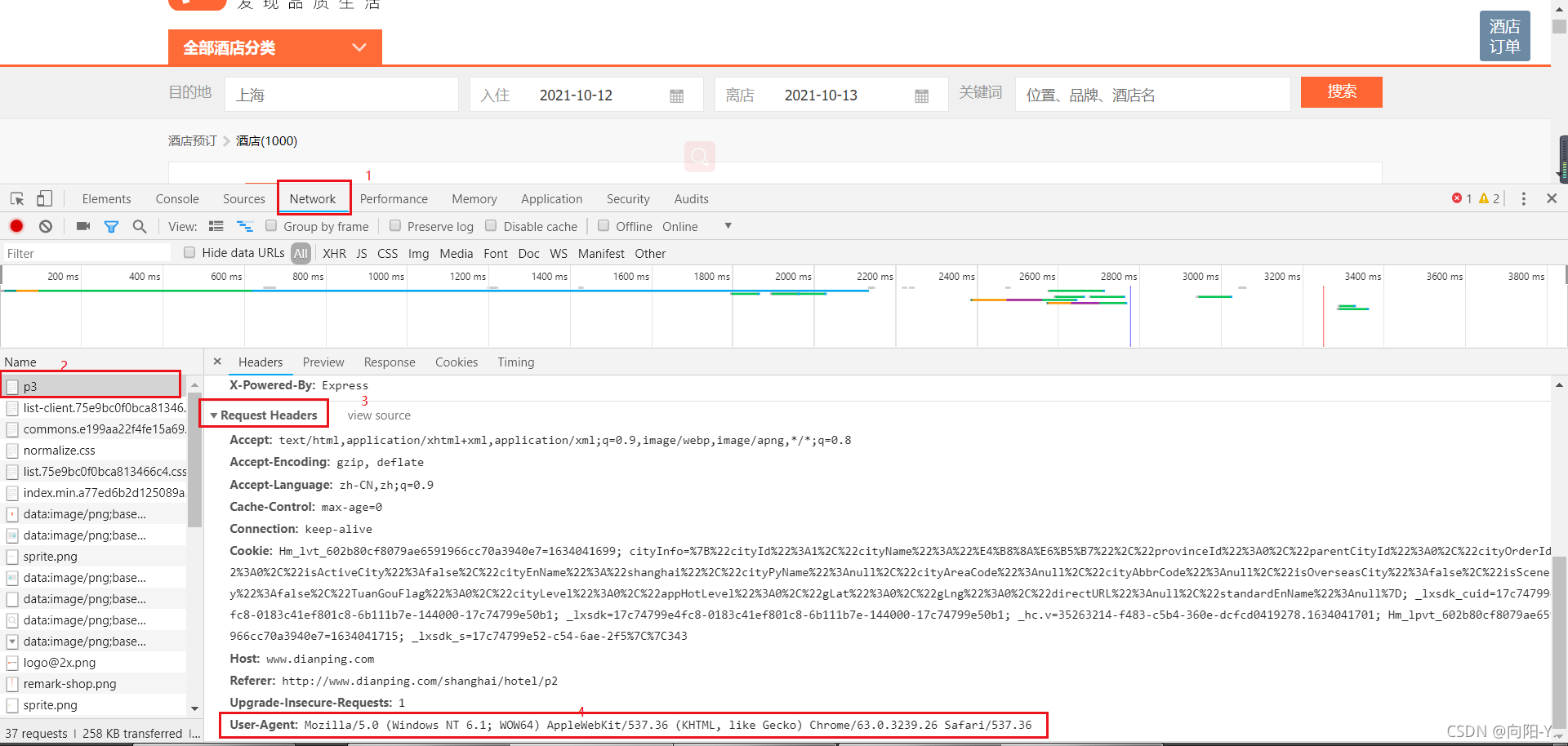
User-Agent、Host、Refer等反爬 Cookie反爬虫(常见如某红书,不过它还有其他的反爬机制类型) 签名验证反爬(js加密) 2. 动态渲染型 ajax动态加载 3.特征识别类型 webDriver识别 浏览器特征 隐藏链接 4. ...
Python字体反爬猫眼电影和实习僧
python字体反爬 https://www.cnblogs.com/xiang-wu/p/11603426.html https://blog.csdn.net/hacklyc/article/details/77101965 http://ftp.acc.umu.se/pub/GNOME/binaries/win64/gtk+/2.22/ ...
Python爬虫基础知识和反爬机制(案例) Python爬虫基础知识和反爬机制(案例) Python爬虫基础知识和反爬机制(案例) Python爬虫基础知识和反爬机制(案例) Python爬虫基础知识和反爬机制(案例) Python爬虫基础...
网上关于这网页的详细解析挺多的,就不一一说明了。 1.ttf文件是被加密,需要解密再下载到本地。 2.观察得到编码是英文的one,two…..,需要转变为数字0,1…..,然后取数字列表的下标。 直接上代码。...
Python爬虫作为一种自动化程序,对于一些需要大量抓取数据的场景非常有用。但是由于网站担心被爬虫非法获取数据,常会采取多种反爬手段,以阻挡或限制爬虫的工作。下面将介绍一些常见的反爬技术及相应的应对方法。


爬虫是 Python 的一个常见应用场景,很多练习项目就是让大家去爬某某网站。爬取网页的时候,你大概率会碰到一些反爬措施。这种情况下,你该如何应对呢?本文梳理了常见的反爬措施和应对方案。
在本文中,我们深入探讨了网络请求和反爬虫的知识点,以及如何使用Python进行网络请求并应对常见的反爬虫策略。首先介绍了HTTP协议与请求方法,详细解释了GET、POST、PUT、DELETE和HEAD等常见请求方法的用途。接着,...

人生苦短,快学Python!随着互联网的发展,Python的崛起,很多网站经常被外面的爬虫程序骚扰,有什么方法可以阻止爬虫吗?阻止爬虫也就称之为反爬虫,反爬虫涉及到的技术比较综合,说简单也简单,说复杂也复杂,看...
通过网络访问服务器时,服务器端会通过IP地址知道是谁来对其进行访问,我们在爬虫过程中,如果经常使用一个IP地址对同一个URL进行访问,此IP很有可能被服务器拉入黑名单,就访问不了此URL了,这是针对具有IP反爬措施...
原标题:分享python爬虫常见反爬措施 1.IP封锁常见网站反爬虫首先考虑到会不会对用户产生误伤,举个例子,在校园网内,有台机器对网站持续高频繁产生请求,校园网涉及用户过多,但是如果封锁IP那么会对校园中的用户...
【1】Headers反爬虫 ... 2.1) 网站根据IP地址访问频率进行反爬,短时间内限制IP访问 2.2) 解决方案: a) 构造自己IP代理池,每次访问随机选择代理,经常更新代理池 b) 购买开放代理或私密代理IP c) 降低爬取的速度
python3爬虫
Python应用实战代码-如何用Selenium 实现反反爬方案
Python抓包及反爬解决方案主要学习爬虫的反爬及应对方法。 1. 了解 服务器反爬的原因 2. 了解 服务器常反什么样的爬虫 3. 了解 反爬虫领域常见的一些概念 4. 了解 反爬的三个方向 5. 了解 常见基于身份识别进行反爬 ...
Python模拟谷歌浏览器获取网页内容,反反爬虫 今天爬取网页内容和文件遇到了 反爬虫,找到了一个比较好的示例代码。

来源:编程派爬虫是 Python 的一个常见应用场景,很多练习项目就是让大家去爬某某网站。爬取网页的时候,你大概率会碰到一些反爬措施。这种情况下,你该如何应对...
在使用 Python 爬取付费音乐时,有几点需要注意: 侵犯版权是违法行为,因此您需要确保您有权进行爬取。 如果您想爬取付费音乐,可能需要使用一些反爬虫技术来避免被网站封禁。这可能包括使用代理服务器、随机化...
那么今天就是我们python爬虫基础知识的第一节课,即:如何通过网页状态码来判断我们的请求是否成功、爬虫程序是否已被网站的反爬技术检查到? 【视频教程】 【图文教程】 首先我们要知道,网页的状态码有很多,我们...
推荐文章
- 机器学习之超参数优化 - 网格优化方法(随机网格搜索)_网格搜索参数优化-程序员宅基地
- Lumina网络进入SDN市场-程序员宅基地
- python引用传递的区别_php传值引用的区别-程序员宅基地
- 《TCP/IP详解 卷2》 笔记: 简介_tcpip详解卷二有必要看吗-程序员宅基地
- 饺子播放器Jzvd使用过程中遇到的问题汇总-程序员宅基地
- python- flask current_app详解,与 current_app._get_current_object()的区别以及异步发送邮件实例-程序员宅基地
- 堪比ps的mac修图软件 Pixelmator Pro 2.0.6中文版 支持Silicon M1_pixelmator堆栈-程序员宅基地
- 「USACO2015」 最大流 - 树上差分_usaco 差分-程序员宅基地
- Leetcode #315: 计算右侧小于当前元素的个数_找元素右边比他小的数字-程序员宅基地
- HTTP图解读书笔记(第六章 HTTP首部)响应首部字段_web响应的首部内容-程序员宅基地