
”PPO“ 的搜索结果
根据OpenAI 提供的伪代码,PPO算法中的第一步。 受的简单实现启发,通过使用Actor和Critic网络创建轨迹

强化学习记录-PPO
标签: python
rewards = (rewards + 8.0) / 8.0 # 和TRPO一样,对奖励进行修改,方便训练。action_dim = env.action_space.shape[0] # 连续动作空间。''' 处理连续动作的PPO算法 '''
包含两部分:self.action_mean将obs映射到动作均值,输入尺寸为(batch_size, obs_dim, 64),输出尺寸为(batch_size, action_dim)self.actor_logstd是一个(1, action_dim)大小的Parameter,用于形成动作方差的对数...
PPO(Proximal Policy Optimization,近端策略优化)是一种强化学习算法,由John Schulman等人在2017年提出。PPO属于策略梯度方法,这类方法直接对策略(即模型的行为)进行优化,试图找到使得期望回报最大化的策略...
PPO算法是一种强化学习中的策略梯度方法,它的全称是Proximal Policy Optimization,即近端策略优化1。PPO算法的目标是在与环境交互采样数据后,使用随机梯度上升优化一个“替代”目标函数,从而改进策略。PPO算法的...
PPO初学者 介绍 你好! 我叫Eric Yu,我写了这个资料库来帮助初学者开始使用PyTorch从头开始编写近端策略优化(PPO)。 我的目标是为PPO提供一个基本的代码(很少/没有花哨的技巧),并提供充分的文档记录/样式和...
盆式PPO关于沉思-PPO 这是Pensieve [1]的一个简单的TensorFlow实现。 详细地说,我们通过PPO而非A3C培训了Pensieve。 这是一个稳定的版本,已经准备好训练集和测试集,并且您可以轻松运行仓库:只需键入python train...
使用ppo算法学习minitaur四足机器人步态,环境代码来自于bullet3,.zip
1. 背景介绍 强化学习(Reinforcement Learning,RL)是机器学习的一个重要分支,它研究的是智能体如何在与环境的交互中学习并做出最佳决策。近年来,深度强化学习(Deep Reinforcement Learning,DRL)的兴起,将...
接着上面的讲,PG方法一个很大的缺点就是参数更新慢,因为我们每更新一次参数都需要进行重新的采样,这其实是中on-policy的策略,即我们想要训练的agent和与环境进行交互的agent是同一个agent;...
PPO算法基本原理及流程图(KL penalty和Clip两种方法)
[PYTORCH]玩超级马里奥兄弟的近战策略优化(PPO) 介绍 这是我的python源代码,用于训练特工玩超级马里奥兄弟。 通过使用纸张近端策略优化算法推出近端政策优化(PPO)算法。 说到性能,我经过PPO培训的代理可以...
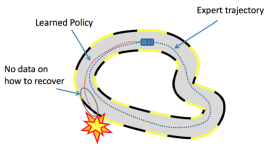
随着大模型的飞速发展,在短短一年间就有了大幅度的技术迭代更新,从LoRA、QLoRA、AdaLoRa、ZeroQuant、Flash Attention、KTO、PPO、DPO、蒸馏技术到模型增量学习、数据处理、开源模型的理解等,几乎每天都有新的...
基于gym的pytorch深度强化学习实现源码+项目说(PPO,DQN,SAC,DDPG,TD3算法.zip
总结来说,PPO和DPO在算法框架和目标函数上有共同之处,但在实现方式、并行化程度以及适用的计算环境上存在差异,DPO特别适用于需要大规模并行处理的场景。总结来说,PPO专注于通过剪切概率比率来稳定策略更新,而...
强化学习PPO算法详解
标签: 算法
也就是上图所描述的方法。接着上面的讲,PG方法一个很大的缺点就是参数更新慢,因为我们每更新一次参数都需要进行重新的采样,这其实是中on-policy的策略,即我们想要训练的agent和与环境进行交互的agent是同一个...
PPO算法是由OpenAI提出的一种新的策略梯度算法,其实现复杂度远低于TRPO算法。PPO算法主要包括两种实现方法,第一种通过CPU仿真实现的,第二种通过GPU仿真实现的,其仿真速度是第一种PPO算法的三倍以上。此外,与...
基于pytorch深度强化学习的PPO,DQN,SAC,DDPG等算法实现python源码.zip基于pytorch深度强化学习的PPO,DQN,SAC,DDPG等算法实现python源码.zip基于pytorch深度强化学习的PPO,DQN,SAC,DDPG等算法实现python源码.zip基于...
1. 背景介绍 1.1 强化学习的崛起 近年来,强化学习 (Reinforcement Learning, RL) 作为机器学习领域的一个重要分支,受到了越来越多的关注。它赋予了智能体在与环境交互的过程中学习和适应的能力,在游戏、机器人...
基于gym的pytorch深度强化学习实现源码+项目说明(PPO,DQN,SAC,DDPG,TD3等算法).zip 本人学习强化学习(PPO,DQN,SAC,DDPG等算法),在gym环境下写的代码集。 主要研究了PPO和DQN类算法,根据各个论文复现了如下改进: ...

PPO算法之所以被提出,根本原因在于在处理连续动作空间时取值抉择困难。取值过小,就会导致深度强化学习收敛性较差,陷入完不成训练的局面,取值过大则导致新旧策略迭代时数据不一致,造成学习波动较大或局部震荡。...
基于李宏毅课程总结
[PYTORCH]针对矛盾的最近策略优化(PPO) 介绍 这是我的python源代码,用于训练代理播放相反的声音。 通过使用纸张近端策略优化算法推出近端政策优化(PPO)算法。 供您参考,PPO是OpenAI提出的算法,用于训练Open...
PPO的简单学习笔记
1. 背景介绍 强化学习作为人工智能领域的重要分支,近年来取得了显著的进展。...PPO(Proximal Policy Optimization)算法作为策略梯度方法的一种,因其简单易用、稳定性强等优点,成为了强化学习领域的主流算法之一。
(1)在中国A股市场15只股票上的应用 (2)构建投资组合 (3)每日调仓 (4)绘制收益率曲线 (5)PPO算法
推荐文章
- I2C知识大全系列六 —— I2C应用之Linux下的I2C_linux控制i2c应用编程-程序员宅基地
- 微擎URL路由_noloading: true, noredirect: true-程序员宅基地
- 关于arduino程序编译成功但上传失败的情况_arduino编译完成但上传错误-程序员宅基地
- 机器学习中的数据预处理_机器学习数据预处理顺序-程序员宅基地
- 谈一次java web系统的重构思路_java web 如何做系统重构-程序员宅基地
- 如何一文认识 AngularJS_angularjs理解-程序员宅基地
- 编写C语言程序,输入每个学生的学号和身高,保存在二进制文件中,并统计每个身高的人数打印出来...-程序员宅基地
- R语言 最优子集选择与K折交叉验证_最优子集法做交叉验证-程序员宅基地
- antd From 中 Form.Item里含有自己封装的组件,获取不到值的解决方法_from.item 拿到组件无法获取参数-程序员宅基地
- 爬虫的基本原理-程序员宅基地