语义搜索是一种先进的信息检索技术,旨在通过理解搜索查询和搜索内容的上...自然语言处理(NLP)上下文中的语义搜索是指应用NLP技术通过理解搜索查询和正在搜索的内容的含义和上下文来增强搜索结果的准确性和相关性。
”NLP语义识别“ 的搜索结果
随着技术的不断进步和创新,我们有...未来,可以探索多模态交互技术,将语音识别和NLP与其他模态结合起来,实现更加自然和丰富的人机交互。随着深度学习技术的不断发展,语音识别与NLP技术的精度和效率将进一步提高。
采用统计与规则相结合的混合策略,提出一种中国人名的自动识别方法.该方法利用知识库中的统计信息,对 中国人名作初步的提取,分析中国人名构成的内部特征和外部特征,提取出特征集,并总结出相应的识别规则,对...

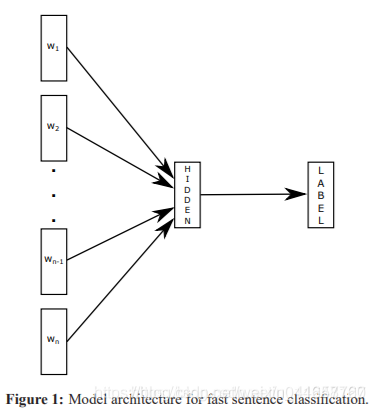
自然语言处理(NLP)是人工智能领域中的一个重要分支,它致力于让计算机能够理解并处理人类自然语言。语义识别是NLP中的一个重要技术,它可以使计算机更好地理解人类语言的含义和意图。在本文中,我们将探讨NLP语义...
自然语言处理面试题及其答案
标签: 自然语言处理
在自然语言处理领域,词向量是一种重要的技术,它通过将单词转换为密集向量的形式来表示语义信息。这些向量能够捕捉单词之间的语义相似性,从而为各种NLP任务提供了基础。利用词向量进行语义分析是指通过比较单词...
文本相似度及案例 在做自然语言处理的过程中,我们经常会遇到需要找出相似语句的场景,或者找出句子的近似表达,这时候就需要把类似的句子归到一起,这里面就涉及到句子相似度计算的问题。基本方法句子相似度计算...

斯坦福大学自然语言处理组是世界知名的NLP研究小组,他们提供了一系列开源的Java文本分析工具,包括分词器(Word Segmenter),词性标注工具(Part-Of-Speech Tagger),命名实体识别工具(Named Entity Recognizer),...


语义分析的任务可以分为几个子任务,这取决于它所发生的语言水平。 最重要的子任务是歧义词和短语的语义标注(Semantic Role Labeling)、指代消解。除此之外,我们还会介绍情感分析任务和单位的向量化(word2vec)...

Python语义识别是自然语言处理(NLP)中的一个分支,旨在识别和理解Python代码中的语义。 语义识别可以帮助开发人员快速查找代码错误,并确定代码的目的。它还可以帮助编写自动代码生成工具,以及评估代码的质量和...

语义分析(Semantic Analysis):指运用各种机器学习方法,学习与理解一段文本所表示的语义内容。...- 篇章语义分析旨在研究自然语言文本的内在结构并理解文本单元(可以是句子从句 或段落)间的语义关系。

伊瓦,家庭语音控制"假...它是一个伪AI项目,全部基于百度AI开放平台,语音识别指令,NLP语义理解;可以理解为带有大屏的假"智能音箱"。支持Ubuntu, Deepin, Fedora, Mac等类Unix系统下调试开发运行, 不支持Windows.
面向生产环境的多语种自然语言处理工具包,基于PyTorch和TensorFlow 2.x双引擎,目标是普及落地最前沿的NLP技术。HanLP实现功能完善,性能高效,架构清晰,语料时新,可自定义的特点。 穿越世界上最大的多语言种语料...
语义关系是指。这些关系可以是,也可以是。在自然语言处理(NLP)和文本挖掘领域,对于都是非常重要的。
刘知远2自然语言处理工具包spaCy介绍spaCy是一个Python自然语言处理工具包,诞生于2014年年中,号称“Industrial-StrengthNatural Language Processing in Python”,是具有工业级强度的Python NL...
自己目前没有做过自然语言处理,语音语义识别测试,本文为听一场语音语义识别测试分享学习所得,以及网上学习资料整理。 语音识别测试 主要考虑距离、噪声、不同手机机型或硬件、不同网络 噪音干扰识别...
大词汇量和上下文的理解:语音识别系统需要具备较大的词汇量,能够识别和理解各种常用词汇和专业术语,并能够根据上下文进行语义理解,提高识别的准确性。声音的多样性:不同人的发音、口音、语速、音调等都存在差异...
3、基于深度学习的语义角色标注(优点:自动学习,能够很好的理解复杂的语义词汇,新的词汇语境的学习能力很强,缺点:需要大量数据和硬件支持,运算速度慢)。基于深度学习的语义角色标注是一种利用神经网络进行...

记得第一次了解中文分词算法是在 Google 黑板报 上看到的,当初看到那个算法时我彻底被震撼住了,想不到一个看似不可能完成的任务竟然有如此神奇巧妙的算法。最近在詹卫东老师的《中文信息处理导论》课上...

中文分词词性标注命名实体识别依存句法分析语义依存分析新词发现 的golang界面 在线轻量级RESTful API 仅数KB,适合敏捷开发,移动APP等场景。服务器算力有限,匿名用户重新替代 使用方式 安装 go get -u github....
(3)基于语义的统计语言实现关键词抽取 1.2 短语抽取的算法模型 (1)基于互信息和左右信息熵算法实现短语抽取 (2)LDA (3)TextRank 1.3 自动摘要抽取算法模型 (1)决策树算法 (2)逻辑回归算法 (3)贝叶斯...
推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地