Hive引擎替换为Spark(Hive on Spark)1、背景2、Hive引擎选择3、三种引擎如何切换引擎?4、hive on spark配置集群模式5、hive on spark参数调优6、结束语 1、背景 Hive on Spark是由Cloudera发起,由Intel、MapR等...
”Hive“ 的搜索结果
Hive CLI和Beeline的区别-Hive vs Beeline Beeline主要是开发来与新服务器进行交互。Hive CLI是基于 Apache Thrift的客户端,而Beeline是基于SQLLine CLI的JDBC客户端。在本文中,我们将详细阐述Hive CLI和...
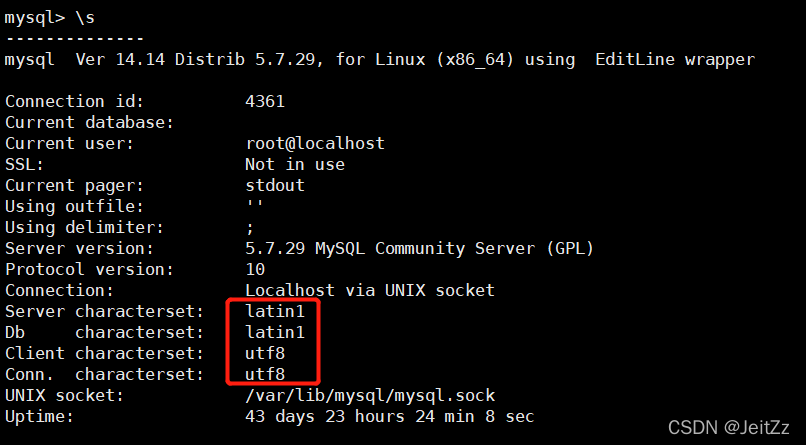
内置的HASH()函数使用哪种哈希算法? 我理想地是在寻找SHA512/SHA256哈希...HASH函数(从Hive 0.11开始)使用类似于java.util.List#hashCode的算法。 其代码如下所示: int hashCode = 0; // Hive HASH uses 0 as the s...
hive 的存储格式
标签: hive
hive的存储格式
HBase与Hive的整合 hive与我们的HBase各有千秋,各自有着不同的功能, 但是归根接地,hive与hbase的数据最终都是存储在hdfs上面的, 一般的我们为了存储磁盘的空间,不会将一份数据存储到多个地方, 导致磁盘...
Hive 多数组合并 使用CONCAT_WS和split 完成多个数组合成一个数组
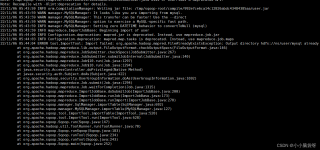
执行完报错了:FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.StatsTask。需要注意的是,之前的insert语句虽然报错了,但是已经向表里插入数据了,有可能会造成重复的数据。执行这个...


Hive的[MSCK REPAIR TABLE] 命令全量修复分区,目的就是将分区信息更新到元数据库中。该命令通常用于分区表的分区修复。 官方解释:(翻译版) Hive将每个表的分区信息保存在metastore中,如果通过hadoop fs -put...
本文总结了Spark与Hive的集成方式,包括Spark with Hive和Hive on Spark。前者通过访问Hive Metastore实现数据加载和处理,提高了数据处理的灵活性和效率;后者则将Spark作为其后端的分布式执行引擎,实现了Hive与...
hive 查看库名 表名
Hive采用了类SQL的查询语言HQL,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处。 数据库可以用在OLTP的应用中,但是Hive是为数据仓库而设计的,清楚这一点...
sql exists

hive添加字段到指定位置 先添加字段到最后位置再移动到指定位置
hive中如何新增字段
标签: hive
1、方法1 alter table 表名 add columns (列名 string COMMENT '新添加的列') CASCADE; 与alter table 表名 add columns (列名 string COMMENT '新添加的列'); CASCADE会刷历史分区字段 ...2、方法2 (适用于外部...

pom文件 <dependency> <...org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>2.1.1</version> <exclusions> <exc
写在前面的话,学《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive的那些事在《Hive内置数据类型...
hive> select space(10) from dual; hive> select length(space(10)) from dual; 10 2、space函数与split函数结合,得到数组; space函数与split函数结合,可以得到空格字符串数组 举例: hive>select ...
hive取整和取余
hive.map.aggr=true; 在map中会做部分聚集操作,效率更高但需要更多的内存。 hive.groupby.skewindata=true: 数据倾斜时负载均衡,当选项设定为true,生成的查询计划会有两个MRJob。第一个MRJob 中, Map的输出...


当在hive上提交mapreduce任务时,常见的管理引擎有yarn与local,默认使用集群模式yarn进行执行。当执行任务计算的文件大小与文件数相对较小时,可以开启本地模式进行执行,效率相对集群模式会更高。 查看当前hive的...
推荐文章
- 什么是.NET Core ?它和.NET Framework 有什么不同?_.net core和.net framework的区别-程序员宅基地
- nfc java_NFC 开发-程序员宅基地
- Oracle数据学习笔记六——Oracle数据库的sql优化_创建plustrace角色-程序员宅基地
- Typora配置阿里云图床——云笔记_笔记图床-程序员宅基地
- [OpenGL] OpenGL各个头文件的意义_opengl代码头文件是什么意思-程序员宅基地
- 2023软件设计师上半年真题解析(上午+下午)_软件设计师编程题-程序员宅基地
- springboot用mybatis-generator自动生成mapper和model的配置文件:generatorConfig.xml_5. 模型层使用springboot集成mybitis generator技术,实现了mapper的-程序员宅基地
- 推荐系统- NCF(Neural Collaborative Filtering)的推荐模型与python实现_neuralcf推荐系统-程序员宅基地
- shell脚本实现批量拷贝_shell脚本批量复制文件-程序员宅基地
- oracle数据库查存储过程中包含,Oracle存储过程包含三部分-程序员宅基地