Python毕业设计|课程设计|基于Python+Djingo实现个人博客系统_python个人博客系统设计与实现-程序员宅基地
技术标签: python项目实战 个人博客系统 python个人博客 博客管理系统 课程设计
作者简介:全栈开发工程,从事Java、Python、前端、小程序方面的开发和研究,对大数据应用与开发比较感兴趣,
主要内容:Java项目、前端项目、Python项目、小程序开发、大数据项目、单片机
收藏点赞不迷路 关注作者有好处
文末获取源码
感谢您的关注,请收藏以免忘记,点赞以示鼓励,评论给以建议,爱你哟
项目编号:BS-Python-007
一,环境介绍
语言环境:Python3.8 Django4.2.1
数据库:Mysql: mysql5.7
开发工具:IDEA
前端技术:HTML+CSS+JS
二,项目简介
主要功能:
- 文章,页面,分类目录,标签的添加,删除,编辑等。文章、评论及页面支持`Markdown`,支持代码高亮。
- 支持文章全文搜索。
- 完整的评论功能,包括发表回复评论,以及评论的邮件提醒,支持`Markdown`。
- 侧边栏功能,最新文章,最多阅读,标签云等。
- 支持Oauth登陆,现已有Google,GitHub,facebook,微博,QQ登录。
- 支持`Redis`缓存,支持缓存自动刷新。
- 简单的SEO功能,新建文章等会自动通知Google和百度。
- 集成了简单的图床功能。
- 集成`django-compressor`,自动压缩`css`,`js`。
- 网站异常邮件提醒,若有未捕捉到的异常会自动发送提醒邮件。
- 集成了微信公众号功能,现在可以使用微信公众号来管理你的vps了。
系统的用户可以分为两类,前端用户和后台管理用户,用户的权限可以在后台由管理员进行管理设定。系统功能相对比较完整,包含了用户管理、博文分类管理、博文管理、标签管理、评论管理、友情连接管理、侧边栏管理、第三方授权登录管理等等
三,系统展示
系统首页
前端用户登录
博客详情
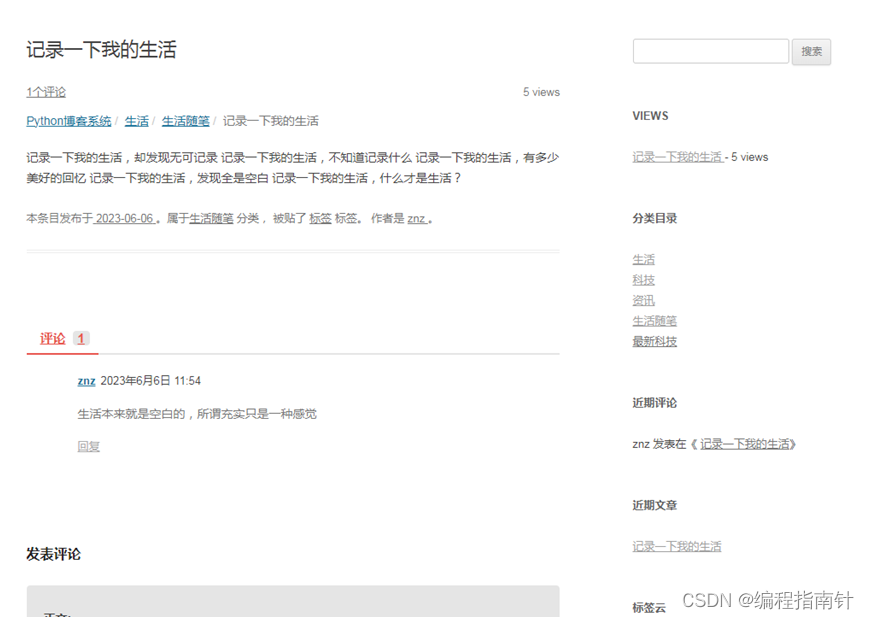
文档归类
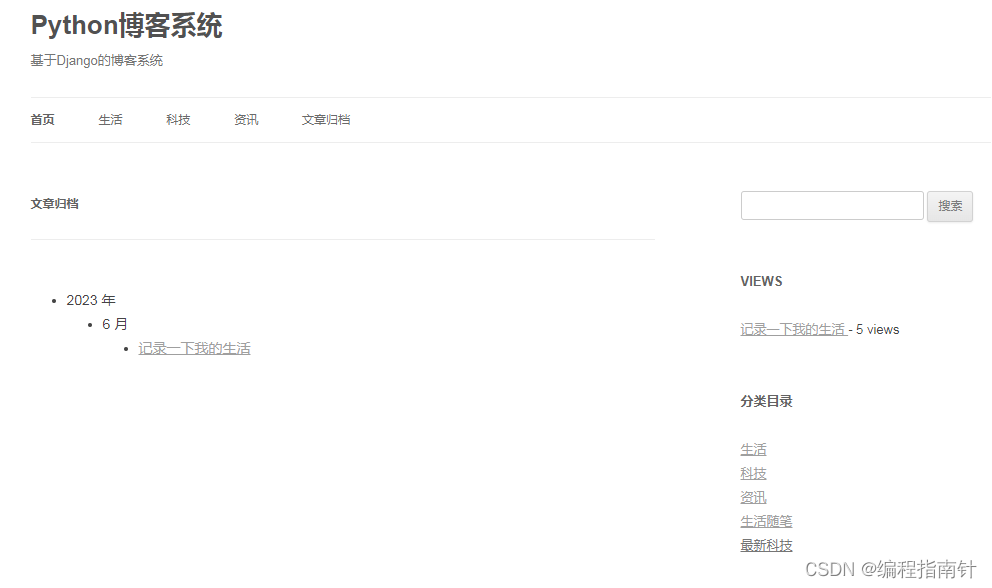
后台管理
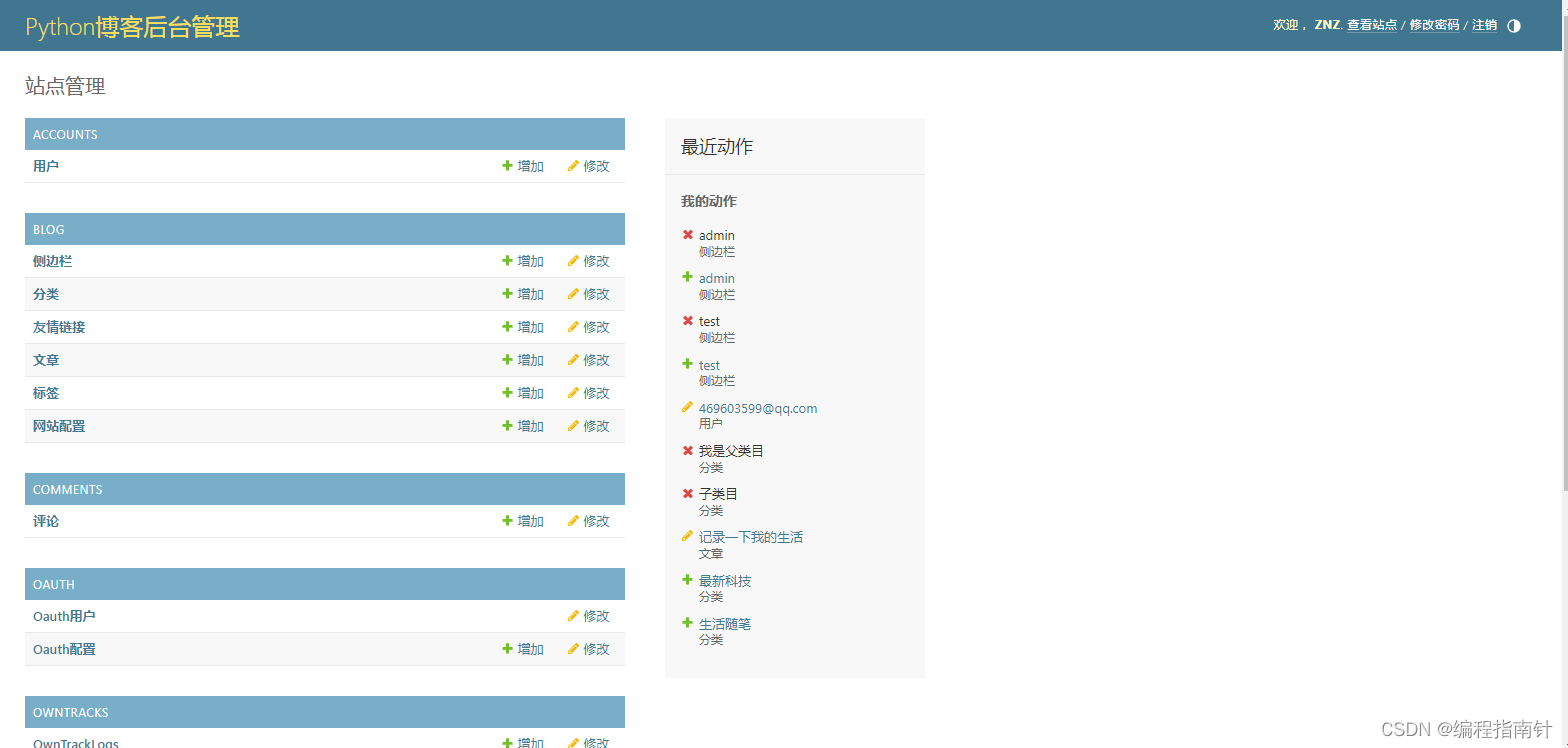
用户管理
分类管理
文章管理

标签管理
网站配置
评论管理
四,核心代码展示
from django.contrib.admin import AdminSite
from django.contrib.admin.models import LogEntry
from django.contrib.sites.admin import SiteAdmin
from django.contrib.sites.models import Site
from accounts.admin import *
from blog.admin import *
from blog.models import *
from comments.admin import *
from comments.models import *
from djangoblog.logentryadmin import LogEntryAdmin
from oauth.admin import *
from oauth.models import *
from owntracks.admin import *
from owntracks.models import *
from servermanager.admin import *
from servermanager.models import *
class DjangoBlogAdminSite(AdminSite):
site_header = 'Python博客后台管理'
site_title = '后台管理'
def __init__(self, name='admin'):
super().__init__(name)
def has_permission(self, request):
return request.user.is_superuser
# def get_urls(self):
# urls = super().get_urls()
# from django.urls import path
# from blog.views import refresh_memcache
#
# my_urls = [
# path('refresh/', self.admin_view(refresh_memcache), name="refresh"),
# ]
# return urls + my_urls
admin_site = DjangoBlogAdminSite(name='admin')
admin_site.register(Article, ArticlelAdmin)
admin_site.register(Category, CategoryAdmin)
admin_site.register(Tag, TagAdmin)
admin_site.register(Links, LinksAdmin)
admin_site.register(SideBar, SideBarAdmin)
admin_site.register(BlogSettings, BlogSettingsAdmin)
admin_site.register(commands, CommandsAdmin)
admin_site.register(EmailSendLog, EmailSendLogAdmin)
admin_site.register(BlogUser, BlogUserAdmin)
admin_site.register(Comment, CommentAdmin)
admin_site.register(OAuthUser, OAuthUserAdmin)
admin_site.register(OAuthConfig, OAuthConfigAdmin)
admin_site.register(OwnTrackLog, OwnTrackLogsAdmin)
admin_site.register(Site, SiteAdmin)
admin_site.register(LogEntry, LogEntryAdmin)
from django.contrib import admin
from django.contrib.admin.models import LogEntry, ADDITION, CHANGE, DELETION
from django.contrib.contenttypes.models import ContentType
from django.urls import reverse, NoReverseMatch
from django.utils.encoding import force_str
from django.utils.html import escape
from django.utils.safestring import mark_safe
from django.utils.translation import pgettext_lazy, gettext_lazy as _
action_names = {
ADDITION: pgettext_lazy('logentry_admin:action_type', 'Addition'),
DELETION: pgettext_lazy('logentry_admin:action_type', 'Deletion'),
CHANGE: pgettext_lazy('logentry_admin:action_type', 'Change'),
}
class LogEntryAdmin(admin.ModelAdmin):
date_hierarchy = 'action_time'
readonly_fields = ([f.name for f in LogEntry._meta.fields] +
['object_link', 'action_description', 'user_link',
'get_change_message'])
fieldsets = (
(_('Metadata'), {
'fields': (
'action_time',
'user_link',
'action_description',
'object_link',
)
}),
(_('Details'), {
'fields': (
'get_change_message',
'content_type',
'object_id',
'object_repr',
)
}),
)
list_filter = [
'content_type'
]
search_fields = [
'object_repr',
'change_message'
]
list_display_links = [
'action_time',
'get_change_message',
]
list_display = [
'action_time',
'user_link',
'content_type',
'object_link',
'action_description',
'get_change_message',
]
def has_add_permission(self, request):
return False
def has_change_permission(self, request, obj=None):
return (
request.user.is_superuser or
request.user.has_perm('admin.change_logentry')
) and request.method != 'POST'
def has_delete_permission(self, request, obj=None):
return False
def object_link(self, obj):
object_link = escape(obj.object_repr)
content_type = obj.content_type
if obj.action_flag != DELETION and content_type is not None:
# try returning an actual link instead of object repr string
try:
url = reverse(
'admin:{}_{}_change'.format(content_type.app_label,
content_type.model),
args=[obj.object_id]
)
object_link = '<a href="{}">{}</a>'.format(url, object_link)
except NoReverseMatch:
pass
return mark_safe(object_link)
object_link.admin_order_field = 'object_repr'
object_link.short_description = _('object')
def user_link(self, obj):
content_type = ContentType.objects.get_for_model(type(obj.user))
user_link = escape(force_str(obj.user))
try:
# try returning an actual link instead of object repr string
url = reverse(
'admin:{}_{}_change'.format(content_type.app_label,
content_type.model),
args=[obj.user.pk]
)
user_link = '<a href="{}">{}</a>'.format(url, user_link)
except NoReverseMatch:
pass
return mark_safe(user_link)
user_link.admin_order_field = 'user'
user_link.short_description = _('user')
def get_queryset(self, request):
queryset = super(LogEntryAdmin, self).get_queryset(request)
return queryset.prefetch_related('content_type')
def get_actions(self, request):
actions = super(LogEntryAdmin, self).get_actions(request)
if 'delete_selected' in actions:
del actions['delete_selected']
return actions
def action_description(self, obj):
return action_names[obj.action_flag]
action_description.short_description = _('action')
def get_change_message(self, obj):
return obj.get_change_message()
get_change_message.short_description = _('change message')
# encoding: utf-8
from __future__ import absolute_import, division, print_function, unicode_literals
import json
import os
import re
import shutil
import threading
import warnings
import six
from django.conf import settings
from django.core.exceptions import ImproperlyConfigured
from django.utils.datetime_safe import datetime
from django.utils.encoding import force_str
from haystack.backends import BaseEngine, BaseSearchBackend, BaseSearchQuery, EmptyResults, log_query
from haystack.constants import DJANGO_CT, DJANGO_ID, ID
from haystack.exceptions import MissingDependency, SearchBackendError, SkipDocument
from haystack.inputs import Clean, Exact, PythonData, Raw
from haystack.models import SearchResult
from haystack.utils import get_identifier, get_model_ct
from haystack.utils import log as logging
from haystack.utils.app_loading import haystack_get_model
from jieba.analyse import ChineseAnalyzer
from whoosh import index
from whoosh.analysis import StemmingAnalyzer
from whoosh.fields import BOOLEAN, DATETIME, IDLIST, KEYWORD, NGRAM, NGRAMWORDS, NUMERIC, Schema, TEXT
from whoosh.fields import ID as WHOOSH_ID
from whoosh.filedb.filestore import FileStorage, RamStorage
from whoosh.highlight import ContextFragmenter, HtmlFormatter
from whoosh.highlight import highlight as whoosh_highlight
from whoosh.qparser import QueryParser
from whoosh.searching import ResultsPage
from whoosh.writing import AsyncWriter
try:
import whoosh
except ImportError:
raise MissingDependency(
"The 'whoosh' backend requires the installation of 'Whoosh'. Please refer to the documentation.")
# Handle minimum requirement.
if not hasattr(whoosh, '__version__') or whoosh.__version__ < (2, 5, 0):
raise MissingDependency(
"The 'whoosh' backend requires version 2.5.0 or greater.")
# Bubble up the correct error.
DATETIME_REGEX = re.compile(
'^(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})T(?P<hour>\d{2}):(?P<minute>\d{2}):(?P<second>\d{2})(\.\d{3,6}Z?)?$')
LOCALS = threading.local()
LOCALS.RAM_STORE = None
class WhooshHtmlFormatter(HtmlFormatter):
"""
This is a HtmlFormatter simpler than the whoosh.HtmlFormatter.
We use it to have consistent results across backends. Specifically,
Solr, Xapian and Elasticsearch are using this formatting.
"""
template = '<%(tag)s>%(t)s</%(tag)s>'
class WhooshSearchBackend(BaseSearchBackend):
# Word reserved by Whoosh for special use.
RESERVED_WORDS = (
'AND',
'NOT',
'OR',
'TO',
)
# Characters reserved by Whoosh for special use.
# The '\\' must come first, so as not to overwrite the other slash
# replacements.
RESERVED_CHARACTERS = (
'\\', '+', '-', '&&', '||', '!', '(', ')', '{', '}',
'[', ']', '^', '"', '~', '*', '?', ':', '.',
)
def __init__(self, connection_alias, **connection_options):
super(
WhooshSearchBackend,
self).__init__(
connection_alias,
**connection_options)
self.setup_complete = False
self.use_file_storage = True
self.post_limit = getattr(
connection_options,
'POST_LIMIT',
128 * 1024 * 1024)
self.path = connection_options.get('PATH')
if connection_options.get('STORAGE', 'file') != 'file':
self.use_file_storage = False
if self.use_file_storage and not self.path:
raise ImproperlyConfigured(
"You must specify a 'PATH' in your settings for connection '%s'." %
connection_alias)
self.log = logging.getLogger('haystack')
def setup(self):
"""
Defers loading until needed.
"""
from haystack import connections
new_index = False
# Make sure the index is there.
if self.use_file_storage and not os.path.exists(self.path):
os.makedirs(self.path)
new_index = True
if self.use_file_storage and not os.access(self.path, os.W_OK):
raise IOError(
"The path to your Whoosh index '%s' is not writable for the current user/group." %
self.path)
if self.use_file_storage:
self.storage = FileStorage(self.path)
else:
global LOCALS
if getattr(LOCALS, 'RAM_STORE', None) is None:
LOCALS.RAM_STORE = RamStorage()
self.storage = LOCALS.RAM_STORE
self.content_field_name, self.schema = self.build_schema(
connections[self.connection_alias].get_unified_index().all_searchfields())
self.parser = QueryParser(self.content_field_name, schema=self.schema)
if new_index is True:
self.index = self.storage.create_index(self.schema)
else:
try:
self.index = self.storage.open_index(schema=self.schema)
except index.EmptyIndexError:
self.index = self.storage.create_index(self.schema)
self.setup_complete = True
def build_schema(self, fields):
schema_fields = {
ID: WHOOSH_ID(stored=True, unique=True),
DJANGO_CT: WHOOSH_ID(stored=True),
DJANGO_ID: WHOOSH_ID(stored=True),
}
# Grab the number of keys that are hard-coded into Haystack.
# We'll use this to (possibly) fail slightly more gracefully later.
initial_key_count = len(schema_fields)
content_field_name = ''
for field_name, field_class in fields.items():
if field_class.is_multivalued:
if field_class.indexed is False:
schema_fields[field_class.index_fieldname] = IDLIST(
stored=True, field_boost=field_class.boost)
else:
schema_fields[field_class.index_fieldname] = KEYWORD(
stored=True, commas=True, scorable=True, field_boost=field_class.boost)
elif field_class.field_type in ['date', 'datetime']:
schema_fields[field_class.index_fieldname] = DATETIME(
stored=field_class.stored, sortable=True)
elif field_class.field_type == 'integer':
schema_fields[field_class.index_fieldname] = NUMERIC(
stored=field_class.stored, numtype=int, field_boost=field_class.boost)
elif field_class.field_type == 'float':
schema_fields[field_class.index_fieldname] = NUMERIC(
stored=field_class.stored, numtype=float, field_boost=field_class.boost)
elif field_class.field_type == 'boolean':
# Field boost isn't supported on BOOLEAN as of 1.8.2.
schema_fields[field_class.index_fieldname] = BOOLEAN(
stored=field_class.stored)
elif field_class.field_type == 'ngram':
schema_fields[field_class.index_fieldname] = NGRAM(
minsize=3, maxsize=15, stored=field_class.stored, field_boost=field_class.boost)
elif field_class.field_type == 'edge_ngram':
schema_fields[field_class.index_fieldname] = NGRAMWORDS(minsize=2, maxsize=15, at='start',
stored=field_class.stored,
field_boost=field_class.boost)
else:
# schema_fields[field_class.index_fieldname] = TEXT(stored=True, analyzer=StemmingAnalyzer(), field_boost=field_class.boost, sortable=True)
schema_fields[field_class.index_fieldname] = TEXT(
stored=True, analyzer=ChineseAnalyzer(), field_boost=field_class.boost, sortable=True)
if field_class.document is True:
content_field_name = field_class.index_fieldname
schema_fields[field_class.index_fieldname].spelling = True
# Fail more gracefully than relying on the backend to die if no fields
# are found.
if len(schema_fields) <= initial_key_count:
raise SearchBackendError(
"No fields were found in any search_indexes. Please correct this before attempting to search.")
return (content_field_name, Schema(**schema_fields))
def update(self, index, iterable, commit=True):
if not self.setup_complete:
self.setup()
self.index = self.index.refresh()
writer = AsyncWriter(self.index)
for obj in iterable:
try:
doc = index.full_prepare(obj)
except SkipDocument:
self.log.debug(u"Indexing for object `%s` skipped", obj)
else:
# Really make sure it's unicode, because Whoosh won't have it any
# other way.
for key in doc:
doc[key] = self._from_python(doc[key])
# Document boosts aren't supported in Whoosh 2.5.0+.
if 'boost' in doc:
del doc['boost']
try:
writer.update_document(**doc)
except Exception as e:
if not self.silently_fail:
raise
# We'll log the object identifier but won't include the actual object
# to avoid the possibility of that generating encoding errors while
# processing the log message:
self.log.error(
u"%s while preparing object for update" %
e.__class__.__name__,
exc_info=True,
extra={
"data": {
"index": index,
"object": get_identifier(obj)}})
if len(iterable) > 0:
# For now, commit no matter what, as we run into locking issues
# otherwise.
writer.commit()
def remove(self, obj_or_string, commit=True):
if not self.setup_complete:
self.setup()
self.index = self.index.refresh()
whoosh_id = get_identifier(obj_or_string)
try:
self.index.delete_by_query(
q=self.parser.parse(
u'%s:"%s"' %
(ID, whoosh_id)))
except Exception as e:
if not self.silently_fail:
raise
self.log.error(
"Failed to remove document '%s' from Whoosh: %s",
whoosh_id,
e,
exc_info=True)
def clear(self, models=None, commit=True):
if not self.setup_complete:
self.setup()
self.index = self.index.refresh()
if models is not None:
assert isinstance(models, (list, tuple))
try:
if models is None:
self.delete_index()
else:
models_to_delete = []
for model in models:
models_to_delete.append(
u"%s:%s" %
(DJANGO_CT, get_model_ct(model)))
self.index.delete_by_query(
q=self.parser.parse(
u" OR ".join(models_to_delete)))
except Exception as e:
if not self.silently_fail:
raise
if models is not None:
self.log.error(
"Failed to clear Whoosh index of models '%s': %s",
','.join(models_to_delete),
e,
exc_info=True)
else:
self.log.error(
"Failed to clear Whoosh index: %s", e, exc_info=True)
def delete_index(self):
# Per the Whoosh mailing list, if wiping out everything from the index,
# it's much more efficient to simply delete the index files.
if self.use_file_storage and os.path.exists(self.path):
shutil.rmtree(self.path)
elif not self.use_file_storage:
self.storage.clean()
# Recreate everything.
self.setup()
def optimize(self):
if not self.setup_complete:
self.setup()
self.index = self.index.refresh()
self.index.optimize()
def calculate_page(self, start_offset=0, end_offset=None):
# Prevent against Whoosh throwing an error. Requires an end_offset
# greater than 0.
if end_offset is not None and end_offset <= 0:
end_offset = 1
# Determine the page.
page_num = 0
if end_offset is None:
end_offset = 1000000
if start_offset is None:
start_offset = 0
page_length = end_offset - start_offset
if page_length and page_length > 0:
page_num = int(start_offset / page_length)
# Increment because Whoosh uses 1-based page numbers.
page_num += 1
return page_num, page_length
@log_query
def search(
self,
query_string,
sort_by=None,
start_offset=0,
end_offset=None,
fields='',
highlight=False,
facets=None,
date_facets=None,
query_facets=None,
narrow_queries=None,
spelling_query=None,
within=None,
dwithin=None,
distance_point=None,
models=None,
limit_to_registered_models=None,
result_class=None,
**kwargs):
if not self.setup_complete:
self.setup()
# A zero length query should return no results.
if len(query_string) == 0:
return {
'results': [],
'hits': 0,
}
query_string = force_str(query_string)
# A one-character query (non-wildcard) gets nabbed by a stopwords
# filter and should yield zero results.
if len(query_string) <= 1 and query_string != u'*':
return {
'results': [],
'hits': 0,
}
reverse = False
if sort_by is not None:
# Determine if we need to reverse the results and if Whoosh can
# handle what it's being asked to sort by. Reversing is an
# all-or-nothing action, unfortunately.
sort_by_list = []
reverse_counter = 0
for order_by in sort_by:
if order_by.startswith('-'):
reverse_counter += 1
if reverse_counter and reverse_counter != len(sort_by):
raise SearchBackendError("Whoosh requires all order_by fields"
" to use the same sort direction")
for order_by in sort_by:
if order_by.startswith('-'):
sort_by_list.append(order_by[1:])
if len(sort_by_list) == 1:
reverse = True
else:
sort_by_list.append(order_by)
if len(sort_by_list) == 1:
reverse = False
sort_by = sort_by_list[0]
if facets is not None:
warnings.warn(
"Whoosh does not handle faceting.",
Warning,
stacklevel=2)
if date_facets is not None:
warnings.warn(
"Whoosh does not handle date faceting.",
Warning,
stacklevel=2)
if query_facets is not None:
warnings.warn(
"Whoosh does not handle query faceting.",
Warning,
stacklevel=2)
narrowed_results = None
self.index = self.index.refresh()
if limit_to_registered_models is None:
limit_to_registered_models = getattr(
settings, 'HAYSTACK_LIMIT_TO_REGISTERED_MODELS', True)
if models and len(models):
model_choices = sorted(get_model_ct(model) for model in models)
elif limit_to_registered_models:
# Using narrow queries, limit the results to only models handled
# with the current routers.
model_choices = self.build_models_list()
else:
model_choices = []
if len(model_choices) > 0:
if narrow_queries is None:
narrow_queries = set()
narrow_queries.add(' OR '.join(
['%s:%s' % (DJANGO_CT, rm) for rm in model_choices]))
narrow_searcher = None
if narrow_queries is not None:
# Potentially expensive? I don't see another way to do it in
# Whoosh...
narrow_searcher = self.index.searcher()
for nq in narrow_queries:
recent_narrowed_results = narrow_searcher.search(
self.parser.parse(force_str(nq)), limit=None)
if len(recent_narrowed_results) <= 0:
return {
'results': [],
'hits': 0,
}
if narrowed_results:
narrowed_results.filter(recent_narrowed_results)
else:
narrowed_results = recent_narrowed_results
self.index = self.index.refresh()
if self.index.doc_count():
searcher = self.index.searcher()
parsed_query = self.parser.parse(query_string)
# In the event of an invalid/stopworded query, recover gracefully.
if parsed_query is None:
return {
'results': [],
'hits': 0,
}
page_num, page_length = self.calculate_page(
start_offset, end_offset)
search_kwargs = {
'pagelen': page_length,
'sortedby': sort_by,
'reverse': reverse,
}
# Handle the case where the results have been narrowed.
if narrowed_results is not None:
search_kwargs['filter'] = narrowed_results
try:
raw_page = searcher.search_page(
parsed_query,
page_num,
**search_kwargs
)
except ValueError:
if not self.silently_fail:
raise
return {
'results': [],
'hits': 0,
'spelling_suggestion': None,
}
# Because as of Whoosh 2.5.1, it will return the wrong page of
# results if you request something too high. :(
if raw_page.pagenum < page_num:
return {
'results': [],
'hits': 0,
'spelling_suggestion': None,
}
results = self._process_results(
raw_page,
highlight=highlight,
query_string=query_string,
spelling_query=spelling_query,
result_class=result_class)
searcher.close()
if hasattr(narrow_searcher, 'close'):
narrow_searcher.close()
return results
else:
if self.include_spelling:
if spelling_query:
spelling_suggestion = self.create_spelling_suggestion(
spelling_query)
else:
spelling_suggestion = self.create_spelling_suggestion(
query_string)
else:
spelling_suggestion = None
return {
'results': [],
'hits': 0,
'spelling_suggestion': spelling_suggestion,
}
def more_like_this(
self,
model_instance,
additional_query_string=None,
start_offset=0,
end_offset=None,
models=None,
limit_to_registered_models=None,
result_class=None,
**kwargs):
if not self.setup_complete:
self.setup()
# Deferred models will have a different class ("RealClass_Deferred_fieldname")
# which won't be in our registry:
model_klass = model_instance._meta.concrete_model
field_name = self.content_field_name
narrow_queries = set()
narrowed_results = None
self.index = self.index.refresh()
if limit_to_registered_models is None:
limit_to_registered_models = getattr(
settings, 'HAYSTACK_LIMIT_TO_REGISTERED_MODELS', True)
if models and len(models):
model_choices = sorted(get_model_ct(model) for model in models)
elif limit_to_registered_models:
# Using narrow queries, limit the results to only models handled
# with the current routers.
model_choices = self.build_models_list()
else:
model_choices = []
if len(model_choices) > 0:
if narrow_queries is None:
narrow_queries = set()
narrow_queries.add(' OR '.join(
['%s:%s' % (DJANGO_CT, rm) for rm in model_choices]))
if additional_query_string and additional_query_string != '*':
narrow_queries.add(additional_query_string)
narrow_searcher = None
if narrow_queries is not None:
# Potentially expensive? I don't see another way to do it in
# Whoosh...
narrow_searcher = self.index.searcher()
for nq in narrow_queries:
recent_narrowed_results = narrow_searcher.search(
self.parser.parse(force_str(nq)), limit=None)
if len(recent_narrowed_results) <= 0:
return {
'results': [],
'hits': 0,
}
if narrowed_results:
narrowed_results.filter(recent_narrowed_results)
else:
narrowed_results = recent_narrowed_results
page_num, page_length = self.calculate_page(start_offset, end_offset)
self.index = self.index.refresh()
raw_results = EmptyResults()
if self.index.doc_count():
query = "%s:%s" % (ID, get_identifier(model_instance))
searcher = self.index.searcher()
parsed_query = self.parser.parse(query)
results = searcher.search(parsed_query)
if len(results):
raw_results = results[0].more_like_this(
field_name, top=end_offset)
# Handle the case where the results have been narrowed.
if narrowed_results is not None and hasattr(raw_results, 'filter'):
raw_results.filter(narrowed_results)
try:
raw_page = ResultsPage(raw_results, page_num, page_length)
except ValueError:
if not self.silently_fail:
raise
return {
'results': [],
'hits': 0,
'spelling_suggestion': None,
}
# Because as of Whoosh 2.5.1, it will return the wrong page of
# results if you request something too high. :(
if raw_page.pagenum < page_num:
return {
'results': [],
'hits': 0,
'spelling_suggestion': None,
}
results = self._process_results(raw_page, result_class=result_class)
searcher.close()
if hasattr(narrow_searcher, 'close'):
narrow_searcher.close()
return results
def _process_results(
self,
raw_page,
highlight=False,
query_string='',
spelling_query=None,
result_class=None):
from haystack import connections
results = []
# It's important to grab the hits first before slicing. Otherwise, this
# can cause pagination failures.
hits = len(raw_page)
if result_class is None:
result_class = SearchResult
facets = {}
spelling_suggestion = None
unified_index = connections[self.connection_alias].get_unified_index()
indexed_models = unified_index.get_indexed_models()
for doc_offset, raw_result in enumerate(raw_page):
score = raw_page.score(doc_offset) or 0
app_label, model_name = raw_result[DJANGO_CT].split('.')
additional_fields = {}
model = haystack_get_model(app_label, model_name)
if model and model in indexed_models:
for key, value in raw_result.items():
index = unified_index.get_index(model)
string_key = str(key)
if string_key in index.fields and hasattr(
index.fields[string_key], 'convert'):
# Special-cased due to the nature of KEYWORD fields.
if index.fields[string_key].is_multivalued:
if value is None or len(value) == 0:
additional_fields[string_key] = []
else:
additional_fields[string_key] = value.split(
',')
else:
additional_fields[string_key] = index.fields[string_key].convert(
value)
else:
additional_fields[string_key] = self._to_python(value)
del (additional_fields[DJANGO_CT])
del (additional_fields[DJANGO_ID])
if highlight:
sa = StemmingAnalyzer()
formatter = WhooshHtmlFormatter('em')
terms = [token.text for token in sa(query_string)]
whoosh_result = whoosh_highlight(
additional_fields.get(self.content_field_name),
terms,
sa,
ContextFragmenter(),
formatter
)
additional_fields['highlighted'] = {
self.content_field_name: [whoosh_result],
}
result = result_class(
app_label,
model_name,
raw_result[DJANGO_ID],
score,
**additional_fields)
results.append(result)
else:
hits -= 1
if self.include_spelling:
if spelling_query:
spelling_suggestion = self.create_spelling_suggestion(
spelling_query)
else:
spelling_suggestion = self.create_spelling_suggestion(
query_string)
return {
'results': results,
'hits': hits,
'facets': facets,
'spelling_suggestion': spelling_suggestion,
}
def create_spelling_suggestion(self, query_string):
spelling_suggestion = None
reader = self.index.reader()
corrector = reader.corrector(self.content_field_name)
cleaned_query = force_str(query_string)
if not query_string:
return spelling_suggestion
# Clean the string.
for rev_word in self.RESERVED_WORDS:
cleaned_query = cleaned_query.replace(rev_word, '')
for rev_char in self.RESERVED_CHARACTERS:
cleaned_query = cleaned_query.replace(rev_char, '')
# Break it down.
query_words = cleaned_query.split()
suggested_words = []
for word in query_words:
suggestions = corrector.suggest(word, limit=1)
if len(suggestions) > 0:
suggested_words.append(suggestions[0])
spelling_suggestion = ' '.join(suggested_words)
return spelling_suggestion
def _from_python(self, value):
"""
Converts Python values to a string for Whoosh.
Code courtesy of pysolr.
"""
if hasattr(value, 'strftime'):
if not hasattr(value, 'hour'):
value = datetime(value.year, value.month, value.day, 0, 0, 0)
elif isinstance(value, bool):
if value:
value = 'true'
else:
value = 'false'
elif isinstance(value, (list, tuple)):
value = u','.join([force_str(v) for v in value])
elif isinstance(value, (six.integer_types, float)):
# Leave it alone.
pass
else:
value = force_str(value)
return value
def _to_python(self, value):
"""
Converts values from Whoosh to native Python values.
A port of the same method in pysolr, as they deal with data the same way.
"""
if value == 'true':
return True
elif value == 'false':
return False
if value and isinstance(value, six.string_types):
possible_datetime = DATETIME_REGEX.search(value)
if possible_datetime:
date_values = possible_datetime.groupdict()
for dk, dv in date_values.items():
date_values[dk] = int(dv)
return datetime(
date_values['year'],
date_values['month'],
date_values['day'],
date_values['hour'],
date_values['minute'],
date_values['second'])
try:
# Attempt to use json to load the values.
converted_value = json.loads(value)
# Try to handle most built-in types.
if isinstance(
converted_value,
(list,
tuple,
set,
dict,
six.integer_types,
float,
complex)):
return converted_value
except BaseException:
# If it fails (SyntaxError or its ilk) or we don't trust it,
# continue on.
pass
return value
class WhooshSearchQuery(BaseSearchQuery):
def _convert_datetime(self, date):
if hasattr(date, 'hour'):
return force_str(date.strftime('%Y%m%d%H%M%S'))
else:
return force_str(date.strftime('%Y%m%d000000'))
def clean(self, query_fragment):
"""
Provides a mechanism for sanitizing user input before presenting the
value to the backend.
Whoosh 1.X differs here in that you can no longer use a backslash
to escape reserved characters. Instead, the whole word should be
quoted.
"""
words = query_fragment.split()
cleaned_words = []
for word in words:
if word in self.backend.RESERVED_WORDS:
word = word.replace(word, word.lower())
for char in self.backend.RESERVED_CHARACTERS:
if char in word:
word = "'%s'" % word
break
cleaned_words.append(word)
return ' '.join(cleaned_words)
def build_query_fragment(self, field, filter_type, value):
from haystack import connections
query_frag = ''
is_datetime = False
if not hasattr(value, 'input_type_name'):
# Handle when we've got a ``ValuesListQuerySet``...
if hasattr(value, 'values_list'):
value = list(value)
if hasattr(value, 'strftime'):
is_datetime = True
if isinstance(value, six.string_types) and value != ' ':
# It's not an ``InputType``. Assume ``Clean``.
value = Clean(value)
else:
value = PythonData(value)
# Prepare the query using the InputType.
prepared_value = value.prepare(self)
if not isinstance(prepared_value, (set, list, tuple)):
# Then convert whatever we get back to what pysolr wants if needed.
prepared_value = self.backend._from_python(prepared_value)
# 'content' is a special reserved word, much like 'pk' in
# Django's ORM layer. It indicates 'no special field'.
if field == 'content':
index_fieldname = ''
else:
index_fieldname = u'%s:' % connections[self._using].get_unified_index(
).get_index_fieldname(field)
filter_types = {
'content': '%s',
'contains': '*%s*',
'endswith': "*%s",
'startswith': "%s*",
'exact': '%s',
'gt': "{%s to}",
'gte': "[%s to]",
'lt': "{to %s}",
'lte': "[to %s]",
'fuzzy': u'%s~',
}
if value.post_process is False:
query_frag = prepared_value
else:
if filter_type in [
'content',
'contains',
'startswith',
'endswith',
'fuzzy']:
if value.input_type_name == 'exact':
query_frag = prepared_value
else:
# Iterate over terms & incorportate the converted form of
# each into the query.
terms = []
if isinstance(prepared_value, six.string_types):
possible_values = prepared_value.split(' ')
else:
if is_datetime is True:
prepared_value = self._convert_datetime(
prepared_value)
possible_values = [prepared_value]
for possible_value in possible_values:
terms.append(
filter_types[filter_type] %
self.backend._from_python(possible_value))
if len(terms) == 1:
query_frag = terms[0]
else:
query_frag = u"(%s)" % " AND ".join(terms)
elif filter_type == 'in':
in_options = []
for possible_value in prepared_value:
is_datetime = False
if hasattr(possible_value, 'strftime'):
is_datetime = True
pv = self.backend._from_python(possible_value)
if is_datetime is True:
pv = self._convert_datetime(pv)
if isinstance(pv, six.string_types) and not is_datetime:
in_options.append('"%s"' % pv)
else:
in_options.append('%s' % pv)
query_frag = "(%s)" % " OR ".join(in_options)
elif filter_type == 'range':
start = self.backend._from_python(prepared_value[0])
end = self.backend._from_python(prepared_value[1])
if hasattr(prepared_value[0], 'strftime'):
start = self._convert_datetime(start)
if hasattr(prepared_value[1], 'strftime'):
end = self._convert_datetime(end)
query_frag = u"[%s to %s]" % (start, end)
elif filter_type == 'exact':
if value.input_type_name == 'exact':
query_frag = prepared_value
else:
prepared_value = Exact(prepared_value).prepare(self)
query_frag = filter_types[filter_type] % prepared_value
else:
if is_datetime is True:
prepared_value = self._convert_datetime(prepared_value)
query_frag = filter_types[filter_type] % prepared_value
if len(query_frag) and not isinstance(value, Raw):
if not query_frag.startswith('(') and not query_frag.endswith(')'):
query_frag = "(%s)" % query_frag
return u"%s%s" % (index_fieldname, query_frag)
# if not filter_type in ('in', 'range'):
# # 'in' is a bit of a special case, as we don't want to
# # convert a valid list/tuple to string. Defer handling it
# # until later...
# value = self.backend._from_python(value)
class WhooshEngine(BaseEngine):
backend = WhooshSearchBackend
query = WhooshSearchQuery
五,项目总结
对于博客系统来讲,用JAVA开发的较多,Python开发的相对较少,功能完整又比较全面的更是不多,这个系统做的整体功能完整,界面简洁大方,使用了较新的组件和技术框架,相对比较优秀。
智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数