深度学习(9)之 easyOCR使用详解-程序员宅基地
技术标签: python 计算机视觉 深度学习 人工智能 # 深度学习 OCR
easyOCR使用详解
- 本文在 OCR-easyocr初识 基础上进行修改
- EasyOCR 是一个python版的文字识别工具。目前支持80中语言的识别。其对应的 github 地址:EasyOCR
- 可以在网站版测试 demo 测试效果:https://www.jaided.ai/easyocr/
- 其在字符识别上的效果如下:

一、介绍
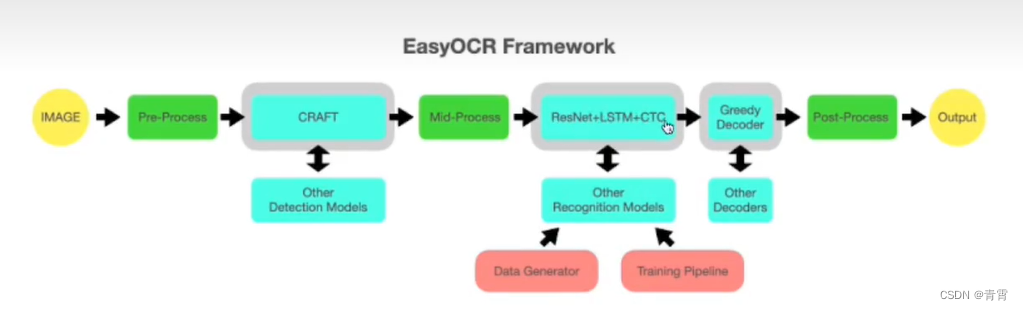
二、安装
- Install using pip
For the latest stable release:
pip install easyocr
For the latest development release:
pip install git+https://github.com/JaidedAI/EasyOCR.git
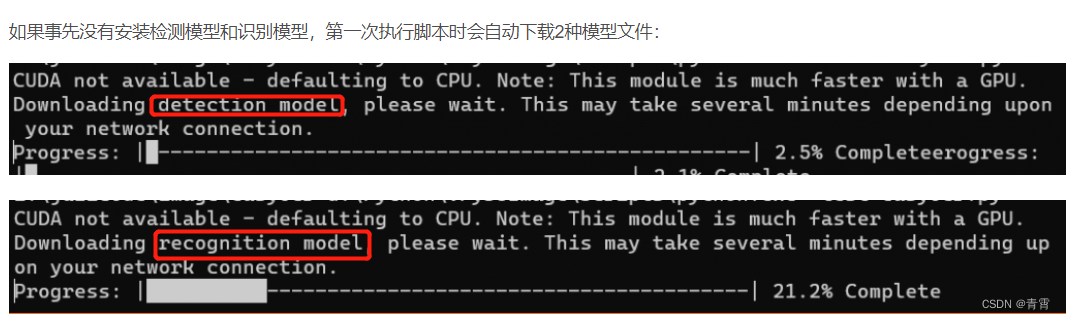
- 模型储存路径:
windows: C:\Users\username\.EasyOCR\linux:/root/.EasyOCR/

三、API文档
3.1、easyocr.Reader class:
-
lang_list (list) - 识别的语言代码列表,例如 ['ch_sim','en']
-
gpu (bool, string, default = True) - 启用 GPU
-
model_storage_directory (string, default = None) - 模型数据目录的路径。如果未指定,将从环境变量 EASYOCR_MODULE_PATH(首选)、MODULE_PATH(如果已定义)或 ~/.EasyOCR/ 定义的目录中读取模型。
-
download_enabled (bool, default = True) - 如果 EasyOCR 无法找到模型文件,则启用下载;
-
user_network_directory (bool, default = None) - 用户模型存储的路径。如果未指定,将从 MODULE_PATH + '/user_network' (~/.EasyOCR/user_network) 读取模型;
-
recog_network (string, default = 'standard') - 用户模型、模块和配置文件的名称;
-
detector (bool, default = True) - 将检测模型加载到内存中
-
recognizer (bool, default = True) - 将识别模型加载到内存中
-
lang_char - 显示当前模型中的所有可用字符
3.2、reader.readtext()
-
image (string, numpy array, byte) - 输入图像;
-
decoder (string, default = 'greedy')- 选项有 'greedy'、'beamsearch' 和 'wordbeamsearch';
-
beamWidth (int, default = 5) - 当解码器 = 'beamsearch' 或 'wordbeamsearch' 时要保留多少光束;
-
batch_size (int, default = 1) - batch_size>1 将使 EasyOCR 更快但使用更多内存;
-
worker (int, default = 0) - 数据加载器中使用的编号线程;
-
allowlist (string) - 强制 EasyOCR 只识别字符的子集。对特定问题有用(例如车牌等);
-
blocklist (string) - 字符的块子集。如果给定了允许列表,则此参数将被忽略。
-
detail (int, default = 1) - 将此设置为 0 以进行简单输出;
-
paragraph (bool, default = False) - 将结果合并到段落中;
-
min_size (int, default = 10) - 过滤文本框小于最小值(以像素为单位);
-
rotation_info (list, default = None) - 允许 EasyOCR 旋转每个文本框并返回具有最佳置信度分数的文本框。符合条件的值为 90、180 和 270。例如,对所有可能的文本方向尝试 [90, 180 ,270]。
-
contrast_ths (float, default = 0.1) - 对比度低于此值的文本框将被传入模型 2 次。首先是原始图像,其次是对比度调整为“adjust_contrast”值。结果将返回具有更高置信度的那个;
-
adjust_contrast (float, default = 0.5) - 低对比度文本框的目标对比度级别。
-
text_threshold (float, default = 0.7) - 文本置信度阈值
-
low_text (float, default = 0.4) - 文本下限分数
-
link_threshold (float, default = 0.4) - 链接置信度阈值
-
canvas_size (int, default = 2560) - 最大图像尺寸。大于此值的图像将被缩小。
-
mag_ratio (float, default = 1) - 图像放大率
-
slope_ths (float, default = 0.1) - 考虑合并的最大斜率 (delta y/delta x)。低值意味着不会合并平铺框。
-
ycenter_ths (float, default = 0.5) - y 方向的最大偏移。不应该合并不同级别的框。
-
height_ths (float, default = 0.5) - 盒子高度的最大差异。不应合并文本大小非常不同的框。
-
width_ths (float, default = 0.5) - 合并框的最大水平距离。
-
add_margin (float, default = 0.1) - 将边界框向所有方向扩展某个值。这对于具有复杂脚本的语言(例如泰语)很重要。
-
x_ths (float, default = 1.0) - 当段落=True 时合并文本框的最大水平距离。
-
y_ths (float, default = 0.5) - 当段落 = True 时合并文本框的最大垂直距离。
四、识别模型
 https://github.com/JaidedAI/EasyOCR/blob/master/custom_model.md
https://github.com/JaidedAI/EasyOCR/blob/master/custom_model.md4.1、训练识别模型
4.2、使用自定义的识别模型
五、使用
5.1、基本使用1
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True
5.2、基本使用2

代码实现如下:
import easyocr
reader = easyocr.Reader(
lang_list=['ch_sim', 'en'], # 需要导入的语言识别模型,可以传入多个语言模型,其中英语模型en可以与其他语言共同使用
gpu=False, # 默认为True
download_enabled=True # 默认为True,如果 EasyOCR 无法找到模型文件,则启用下载
)
result = reader.readtext('id_card.jpg', detail=1 ) # 图片可以传入图片路径、也可以传入图片链接。但推荐传入图片路径,会提高识别速度。包含中文会出错。设置detail=0可以简化输出结果,默认为1
print(result)
readtext 返回的列表中,每个元素都是一个元组,内含三个信息:位置、文字、置信度:
[
([[27, 37], [341, 37], [341, 79], [27, 79]], '姓 名 爱新觉罗 。玄烨', 0.6958897643232619),
([[29, 99], [157, 99], [157, 135], [29, 135]], '性 别 男', 0.914532774041559),
([[180, 95], [284, 95], [284, 131], [180, 131]], '民蔟满', 0.4622474180193509),
([[30, 152], [94, 152], [94, 182], [30, 182]], '出 生', 0.6015505790710449),
([[110, 152], [344, 152], [344, 184], [110, 184]], '1654 年54日', 0.42167866223467815),
([[29, 205], [421, 205], [421, 243], [29, 243]], '住 址 北京市东城区景山前街4号', 0.6362530289101117),
([[105, 251], [267, 251], [267, 287], [105, 287]], '紫禁城乾清宫', 0.8425745057905053),
([[32, 346], [200, 346], [200, 378], [32, 378]], '公民身份证号码', 0.22538012770296922),
([[218, 348], [566, 348], [566, 376], [218, 376]], '000003165405049842', 0.902066405195785)
]
detail=0,从而只返回文字内容:
['姓 名 爱新觉罗 。玄烨', '性 别 男', '民蔟满', '出 生', '1654 年54日', '住 址 北京市东城区景山前街4号', '紫禁城 乾清宫', '公民身份证号码', '000003165405049842']
5.3、基本使用3


智能推荐
(算法)稳定婚姻匹配-程序员宅基地
文章浏览阅读71次。题目:婚介所登记了N位男孩和N位女孩,每个男孩都对N个女孩的喜欢程度做了排序,每个女孩都对N个男孩的喜欢程度做了排序,你作为月老,能否给出稳定的牵手方案?稳定的定义:如果男孩i和女孩a牵手,但男孩i对女孩b更喜欢,而女孩b的男朋友j拼不过男孩i,则没有力量阻碍男孩i和女孩b的私奔,这即是不稳定的。思路: 1962 年,美国数学家 David Gale 和 Lloyd Shapl..._wm[i][woman[i][j]]=j
python基础教程数据分析_Python基础教程之Python数据分析工具总结-程序员宅基地
文章浏览阅读112次。Python主要是依靠众多的第三方库来增强它的数据处理能力的。常用的是Numpy库,Scipy库、Matplotlib库、Pandas库、Scikit-Learn库等。常规版本的python需要在安装完成后另外下载相应的第三方库来安装库文件。而若安装的是Anaconda版本的Python,则不需要一个一个安装第三方库,可能已经同时安装了这些库。Anaconda是专门应用于科学计算的Python版本..._python处理piv教程
CS224n研究热点1 一个简单但很难超越的Sentence Embedding基线方法-程序员宅基地
文章浏览阅读149次。为什么80%的码农都做不了架构师?>>> ..._计算padded的sentence的embedding
苹果id无法登陆_苹果手机无法连接到app store怎么办-程序员宅基地
文章浏览阅读3.6k次。 苹果手机提供了App Store作为官方的软件下载渠道,如果有时候遇到苹果手机无法连接到app store怎么办,下面就为大家介绍一下解决的方法。苹果手机无法连接到app store怎么办 无法连接到App Store一般都是由于网络问题导致的,下面就为大家介绍一下几种解决的方法: 1、首先可以重启一遍手机看一下能否解决; 2、您可以将当前的WiFi断开使用移动网络能否正常打开; 3、..._苹果手机无法连接到app store
数形结合彻底解决2个球100层楼摔坏的问题_两个小球从高空抛下移到100层楼-程序员宅基地
文章浏览阅读1.3w次,点赞5次,收藏20次。题目:有一栋100层高楼,从某一层开始扔下的玻璃球刚好摔坏,现有两个玻璃球,试用最简便的方法确定这个恰好摔坏玻璃球的那层. 这是一道著名的面试题目,仅写出我的思路和解法. 首先从题目得出基本思路1.第一个球应该低到高试,但不是每层必试.2.不能有侥幸心理,第二个球在第一个球的区间里每层必试. 上图是简化为10层楼解法。 数字代表楼层,球从原点先右后上的路_两个小球从高空抛下移到100层楼
读取HG-S1010测量值 RS485通信 modbus协议 FP7_hg s1010接线-程序员宅基地
文章浏览阅读210次。HG-S1010配有模拟量输出(电压、电流),NPN/PNP输出,也可通过外接通讯模块进行输出。通信模块包括SC-HG1-485模块(RS485接口协议)、SC-HG1-ETC模块(EtherCAT总线)、SC-HG1-C模块(CCLink协议)等。本文介绍连接松下FP7与HG-S1010配RS485通信模块进行通信,通过modbus协议读取HG-S1010当前测量值。主控制器测量值位置在地址H64处,占两个字节。将SC-HG1-485模块与控制器HG-SC101连接,在端子台+、-插入通信用线。_hg s1010接线
随便推点
LeetCode刷题总结 - 面试经典 150 题 -持续更新-程序员宅基地
文章浏览阅读5.7k次,点赞4次,收藏22次。LeetCode刷题总结 - 面试经典 150 题 - 持续更新其他系列数组 / 字符串88. 合并两个有序数组27. 移除元素26. 删除有序数组中的重复项80. 删除有序数组中的重复项 II169. 多数元素189. 轮转数组121. 买卖股票的最佳时机122. 买卖股票的最佳时机 II55. 跳跃游戏274. H 指数380. O(1) 时间插入、删除和获取随机元素238. 除自身以外数组的乘积739. 每日温度42. 接雨水双指针125. 验证回文串392. 判断子序列167. 两数之和 II - _leetcode刷题
PTA 7-248 递归函数返回两个整数的最大公约数_编写函数,函数的形式参数为两个正整数a和b,函数返回a与b的最大公约数,要求用递归-程序员宅基地
文章浏览阅读1.3k次。PTA 7-248 递归函数返回两个整数的最大公约数_编写函数,函数的形式参数为两个正整数a和b,函数返回a与b的最大公约数,要求用递归
使用parted分区并用GPT方式分区_mengpt使用-程序员宅基地
文章浏览阅读4.4k次。使用parted分区,删除所有分区,并重新使用parted分区分区方式使用gpt_mengpt使用
Oauth2 访问oauth/authorize/**出现 403_oauth2 client_credentials 403-程序员宅基地
文章浏览阅读4.1k次,点赞3次,收藏3次。Oauth2 访问oauth/authorize/**出现 403_oauth2 client_credentials 403
STM32-串口通信发送+接收信息(标准库+代码)_stm32串口传输代码-程序员宅基地
文章浏览阅读586次,点赞12次,收藏8次。通用异步收发器UART(Universal Asynchronous Receiver/Transmitter),是一种串行、异步、全双工的通信协议。通过发送线(TX)、接收线(RX)、GND就可以进行全双工通信。需要确定好通信双方的波特率(bps指每秒传输的码元数量)串口通信是一位一位地传输,每传输一个字符总是以起始位开始,以停止位结束,字符之间没有固定的时间间隔要求。每一个字符的前面都有一位起始位(低电平),后面由7位数据位组成,接着是1位校验位,最后是1位停止位。_stm32串口传输代码
lliunx 系统 图片服务器fastdfs 安装和测试_linux测试fastdfs上传图片-程序员宅基地
文章浏览阅读465次。fastdfs 相关安装包下载:fastdfs_client_java_v1.10.tar.gz 下载链接:https://sourceforge.net/projects/fastdfs/fastdfs-nginx-module_v1.16.tar.gz 下载链接:https://sourceforge.net/projects/fastdfs/file_linux测试fastdfs上传图片