2023年!自然语言处理(NLP)10 大预训练模型_nlp最新模型-程序员宅基地
来源: AINLPer 公众号(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2022-10-23
引言
语言模型是构建NLP应用程序的关键。现在人们普遍相信基于预训练模型来构建NLP语言模型是切实有效的方法。随着疫情阴霾的散去,相信NLP技术会继续渗透到众多行业中。在此过程中,肯定有很多同学会用到NLP预训练模型,为此作者整理了目前2023年NLP的十大预训练模型及论文。
BERT模型

BERT模型(Bidirectional Encoder Representations from Transformers)是由谷歌在2018年研究发布的一款NLP预训练模型,一经发布在当年的火热程度不亚于目前ChatGPT。
它采用独特的神经网络架构Transformer(现在看来已经不新鲜了)进行语言理解。该模型适用于语音识别(ASR)、文本到语音(TTS)以及序列到序列(Sequence To Sequence)的任何任务。利用BERT模型它可以有效的应对11个NLP任务,其中Google搜索就是采用BERT模型的最好例子,Google的其它应用案例,例如Google文档、Google邮件辅助编写等都应用了BERT模型的文本预测能力。
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
https://arxiv.org/pdf/1810.04805.pdf
GPT-2模型

GPT-2模型(Generative Pre-trained Transformer ,即生成式预训练Transformer)是OpenAI于2019年2月发布的开源模型,并于同年年11月发布了GPT-2语言模型的完整版本(有15亿个参数)。
GPT-2在文本翻译、QA问答、文章总结、文本生成等NLP任务上可以达到人类的水平。但是但在生成长文章时,会变得重复或无意义。GPT-2是一个通用模型,针对上述任务,它并且没有接受过专门的训练,这得益于它独特的泛化延申能力,即可以在任意序列中准确合成下一项。GPT-2是OpenAI 2018年GPT模型的“直接放大”,其参数计数和训练数据集的大小都增加了10倍。GPT的模型也是基于Transformer建立的,它使用Attention来取代之前RNN和CNN的架构,进而让模型有选择地关注它预测的最相关的输入文本片段。
论文:Language Models are Unsupervised Multitask Learners
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
GPT-3模型

GPT-3模型(Generative Pre-trained Transformer ,即生成式预训练Transformer)是一个自回归语言模型,它由OpenAI于2020年发布,它使用深度学习来生成类似人类的文本。即给定一个作为提示的初始文本,它会继续生成后面的文本。GPT-3生成的文本质量非常高,以至于很难确定它是否是由人类编写的,这既有好处也有风险。(目前爆火的chatGPT就是基于GPT-3.5训练得到的)
GPT-3架构只存在解码器的Transformer网络,具有2048个Token长的上下文以及1750亿个参数,需要存储800GB。采用生成性预训练对模型进行训练;经过训练,它可以根据前一个Token预测下一个Token是什么。该模型在零样本和小样本学习任务上表现出了强大的学习能力。
论文:GPT3
https://arxiv.org/pdf/2005.14165.pdf
RoBERTa

RoBERTa模型(Robustly Optimized BERT Pretraining Approach)是由Meta AI在2019年7月份发布的,它基于BERT模型优化得到的。该模型通过学习和预测故意掩膜的文本部分,在BERT的语言掩蔽策略上建立它的语言模型,并使用更大的小批量和学习率进行训练。与BERT相比,这使得RoBERTa可以改进掩码语言建模目标,并产生更好的下游任务性能。
RoBERTa是一个预训练模型,它在GLUE或通用语言理解评估上表现出色。
论文:RoBERTa: A Robustly Optimized BERT Pretraining Approach
https://arxiv.org/pdf/1907.11692.pdf
ALBERT
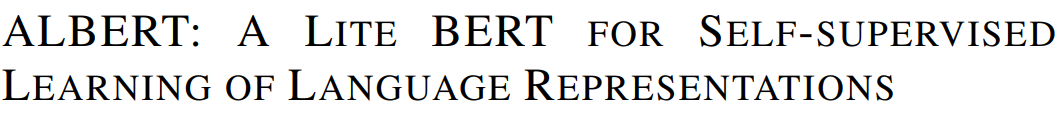
ALBERT模型(A Little Bert)是BERT模型的精简版本,由谷歌在2020年初发布。该模型主要用于解决模型规模增加导致训练时间变慢的问题。该语言模型采用了因子嵌入和跨层参数共享两种参数简化方法,即在Factorized embedding中,隐藏层和词汇嵌入是分开测量的。然而,跨层参数共享可防止参数数量随着网络的增长而增加。
ALBERT的成功证明了识别模型的各个方面的重要性,这些方面会产生强大的上下文表示。通过将改进工作集中在模型架构的这些方面,可以大大提高模型在各种NLP任务上的效率和性能。
论文:ALBERT
https://arxiv.org/pdf/1909.11942.pdf
XLNet

XLNet是一个类似BERT的模型,而不是完全不同的模型。总之,XLNet是一种通用的自回归预训练方法。它是CMU和Google Brain团队在2019年6月份发布的模型,XLNet在20个任务上超过了BERT的表现,并在18个任务上取得了当前最佳效果(state-of-the-art),包括机器问答、自然语言推断、情感分析和文档排序。
BERT模型基于去噪自编码器的预训练模型可以很好地建模双向语境信息,性能优于基于自回归语言模型的预训练方法。然而,由于需要mask一部分输入,BERT忽略了被mask位置之间的依赖关系,因此出现预训练和微调效果的差异(pretrain-finetune discrepancy),基于以上问题,一种泛化的自回归预训练模型XLNet应运而生。
论文:XLNet
https://arxiv.org/pdf/1906.08237.pdf
T5

T5模型(Transfer Text-to-Text Transformer,即文本到文本传输转换)是Google在2020年7月份发布的一款强大的统一模型,它将所有NLP任务都转化成文本到文本任务,由此可以方便地评估在阅读理解、摘要生成、文本分类等一系列NLP任务上,不同的模型结构,预训练目标函数,无标签数据集等的影响。
谷歌提出了一种统一的NLP迁移学习方法,开创了该领域的新局面。该模型使用网络抓取数据进行训练,在几个NLP任务上得到了最先进的结果。
论文:T5
https://arxiv.org/pdf/1910.10683.pdf
ELECTRA

$emsp;ELECTRA模型(Efficiently Learning an Encoder that Classifies Token Replacements Accurately),该模型以1/4的算力就达到了RoBERTa的效果。该模型借鉴了对抗网络的思想,共训练两个神经网络模型,其中生成器Generator,随机屏蔽原始文本中的单词,进行预测学习;判别器Discriminator判定单词是否与原始文本一致,如果一致则为真,如果不同则为假。采用联合训练的方法,但与对抗网络不同的时,参数不在生成器和判别器中反向传播,只共享embedding。embedding大小和判别器的隐层一致。
论文:ELECTRA
https://openreview.net/pdf?id=r1xMH1BtvB
DeBERTa

DeBERTa模型(Decoding-enhanced BERT with Disentangled Attention),是微软在2021年初发布。目前该模型其实已经迭代了三个版本。DeBERTa 模型使用了两种新技术(注意力解耦机制、增强的掩码解码器)改进了 BERT和RoBERTa模型,同时还引入了一种新的微调方法(虚拟对抗训练方法)以提高模型的泛化能力。结果表明以上技术和方法,提高了模型预训练的效率以及自然语言理解(NLU)和自然语言生成(NLG)下游任务的性能。
论文:DeBERTa
https://arxiv.org/pdf/2006.03654.pdf
StructBERT

StructBERT模型是一个预训练的语言模型,由阿里巴巴达摩院2019年提出的NLP预训练模型。它是基于BERT模型的改进,与其最大区别在于:StructBERT增加了两个预训练任务和目标,可以最大限度地利用单词和句子的顺序,分别在单词和句子级别利用语言结构。因此,新模型适用于下游任务所需的不同水平的语言理解。
论文:StructBERT
https://arxiv.org/pdf/1908.04577.pdf
推荐阅读
[1] EMNLP2022 | 带有实体内存(Entity Memory)的统一编解码框架 (美国圣母大学)
[2] NeurIPS2022 | 训练缺少数据?你还有“零样本学习(zero-shot Learning)”(香槟分校)
智能推荐
适合入门的8个趣味机器学习项目-程序员宅基地
文章浏览阅读86次。首发地址:https://yq.aliyun.com/articles/221708谈到机器学习,相信很多除学者都是通过斯坦福大学吴恩达老师的公开课《Machine Learning》开始具体的接触机器学习这个领域,但是学完之后又不知道自己的掌握情况,缺少一些实际的项目操作。对于机器学习的相关竞赛挑战,有些项目的门槛有些高,参加后难以具体的实现,因此造..._scrath五子棋下载
oracle 12c avg,Oracle 12c新特性系列专题-安徽Oracle授权认证中心-程序员宅基地
文章浏览阅读83次。原标题:Oracle 12c新特性系列专题-安徽Oracle授权认证中心 随着Oracle database 12c的普及,数据库管理员 (DBA) 的角色也随之发生了转变。 Oracle 12c数据库对 DBA 而言是下一代数据管理。它让 DBA 可以摆脱单调的日常管理任务,能够专注于如何从数据中获取更多价值。未来我们会推出基于Oracle12c的技术文章,帮助DBA尽快掌握新一代数据库的新特性..._ilm add policy row store compress advanced row after
第七周项目三(负数把正数赶出队列)-程序员宅基地
文章浏览阅读150次。问题及代码:*Copyright(c)2016,烟台大学计算机与控制工程学院 *All right reserved. *文件名称:负数把正数赶出队列.cpp *作者:张冰 *完成日期;2016年10月09日 *版本号;v1.0 * *问题描述: 设从键盘输入一整数序列a1,a2,…an,试编程实现: 当ai>0时,ai进队,当ai<0时,将队首元素出队,当ai
贪心+构造,LeetCode 1702. 修改后的最大二进制字符串-程序员宅基地
文章浏览阅读376次。贪心+构造
Linux命名空间学习教程(二) IPC-程序员宅基地
文章浏览阅读150次。本文讲的是Linux命名空间学习教程(二) IPC,【编者的话】Docker核心解决的问题是利用LXC来实现类似VM的功能,从而利用更加节省的硬件资源提供给用户更多的计算资源。而 LXC所实现的隔离性主要是来自内核的命名空间, 其中pid、net、ipc、mnt、uts 等命名空间将容器的进程、网络、消息、文件系统和hostname 隔离开。本文是Li..._主机的 ipc 命名空间
adb强制安装apk_adb绕过安装程序强制安装app-程序员宅基地
文章浏览阅读2w次,点赞5次,收藏7次。在设备上强制安装apk。在app已有的情况下使用-r参数在app版本低于现有版本使用-d参数命令adb install -r -d xxx.apk_adb绕过安装程序强制安装app
随便推点
STM32F407 越界问题定位_stm32flash地址越界怎么解决-程序员宅基地
文章浏览阅读290次。如果是越界进入硬件错误中断,MSP 或者 PSP 保存错误地址,跳转前会保存上一次执行的地址,lr 寄存器会保存子函数的地址,所以如果在 HardFault_CallBack 中直接调用 C 语言函数接口会间接修改了 lr,为了解决这个问题,直接绕过 lr 的 C 语言代码,用汇编语言提取 lr 寄存器再决定后面的操作。由于 STM32 加入了 FreeRTOS 操作系统,可能导致无法准确定位,仅供参考(日常编程需要考虑程序的健壮性,特别是对数组的访问,非常容易出现越界的情况)。_stm32flash地址越界怎么解决
利用SQL注入上传木马拿webshell-程序员宅基地
文章浏览阅读1.8k次。学到了一种操作,说实话,我从来没想过还能这样正常情况下,为了管理方便,许多管理员都会开放MySQL数据库的secure_file_priv,这时就可以导入或者导出数据当我如图输入时,就会在D盘创建一个名为123456.php,内容为<?php phpinfo();?>的文件我们可以利用这一点运用到SQL注入中,从拿下数据库到拿下目标的服务器比如我们在使用联合查询注入,正常是这样的语句http://xxx?id=-1 union select 1,'你想知道的字段的内容或查询语句',
Html CSS的三种链接方式_html链接css代码-程序员宅基地
文章浏览阅读2.9w次,点赞12次,收藏63次。感谢原文:https://blog.csdn.net/abc5382334/article/details/24260817感谢原文:https://blog.csdn.net/jiaqingge/article/details/52564348Html CSS的三种链接方式css文本的链接方式有三种:分别是内联定义、链入内部css、和链入外部css1.代码为:<html>..._html链接css代码
玩游戏哪款蓝牙耳机好?2021十大高音质游戏蓝牙耳机排名_适合游戏与运动的高音质蓝牙耳机-程序员宅基地
文章浏览阅读625次。近几年,蓝牙耳机市场发展迅速,越来越多的消费者希望抛弃线缆,更自由地听音乐,对于运动人士来说,蓝牙耳机的便携性显得尤为重要。但目前市面上的大多数蓝牙耳机实际上都是“有线”的,运动过程中产生的听诊器效应会严重影响听歌的感受。而在“真无线”耳机领域,除了苹果的AirPods外,可供选择的产品并不多,而AirPods又不是为运动场景打造的,防水能力非常差。那么对于喜欢运动又想要“自由”的朋友来说,有没有一款产品能够满足他们的需求呢?下面这十款小编专门为大家搜罗的蓝牙耳机或许就能找到适合的!网红击音F1_适合游戏与运动的高音质蓝牙耳机
iOS 17 测试版中 SwiftUI 视图首次显示时状态的改变导致动画“副作用”的解决方法-程序员宅基地
文章浏览阅读1k次,点赞6次,收藏7次。在本篇博文中,我们在 iOS 17 beta 4(SwiftUI 5.0)测试版中发现了 SwiftUI 视图首次显示时状态的改变会导致动画“副作用”的问题,并提出多种解决方案。
Flutter 自定义 轮播图的实现_flutter pageview轮播图 site:csdn.net-程序员宅基地
文章浏览阅读1.9k次。 在 上篇文章–Flutter 实现支持上拉加载和下拉刷新的 ListView 中,我们最终实现的效果是在 listView 上面留下了一段空白,本意是用来加载轮播图的,于是今天就开发了一下,希望能给各位灵感。一 、效果如下说一下大体思路 其实图片展示是用的 PageView ,然后,下面的指示器 是用的 TabPageSelector ,当然整体是用 Stack 包裹起来的。1、..._flutter pageview轮播图 site:csdn.net