scrapy基础_p.3.cn 连接timeout-程序员宅基地
技术标签: python
Scrapy介绍
参考文档
• 什么是Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取
Scrapy使用了Twisted异步网络框架,可以加快我们的下载速度
http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
异步和非阻塞的区别
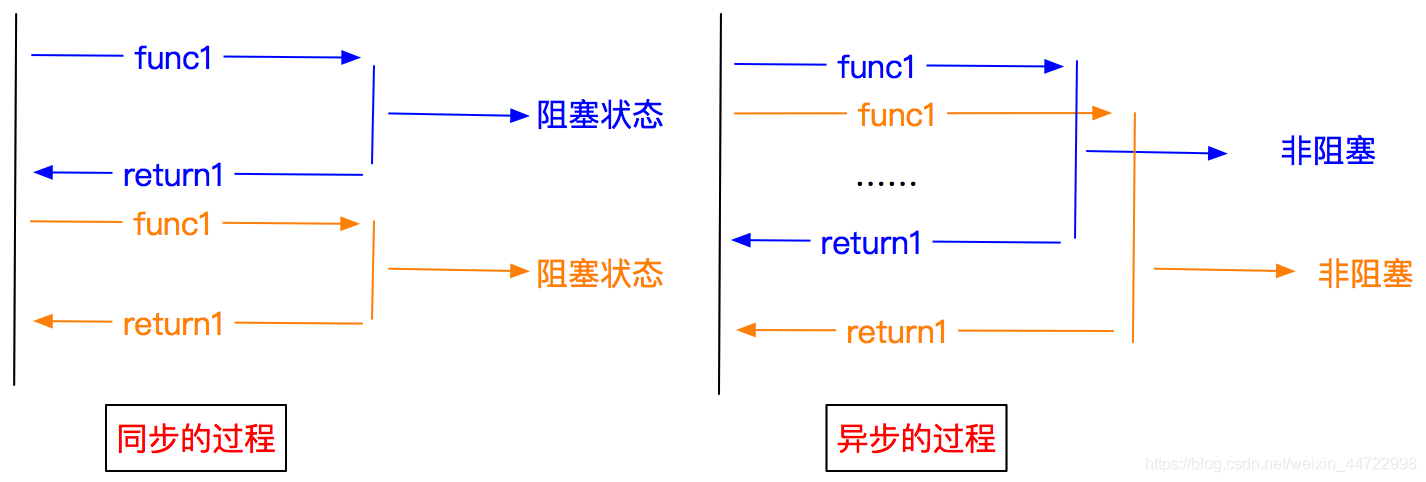
异步:调用在发出之后,这个调用就直接返回,不管有无结果
非阻塞:关注的是程序在等待调用结果时的状态,指在不能立刻得到结果之前,该调用不会阻塞当前线程
Scrapy工作流程
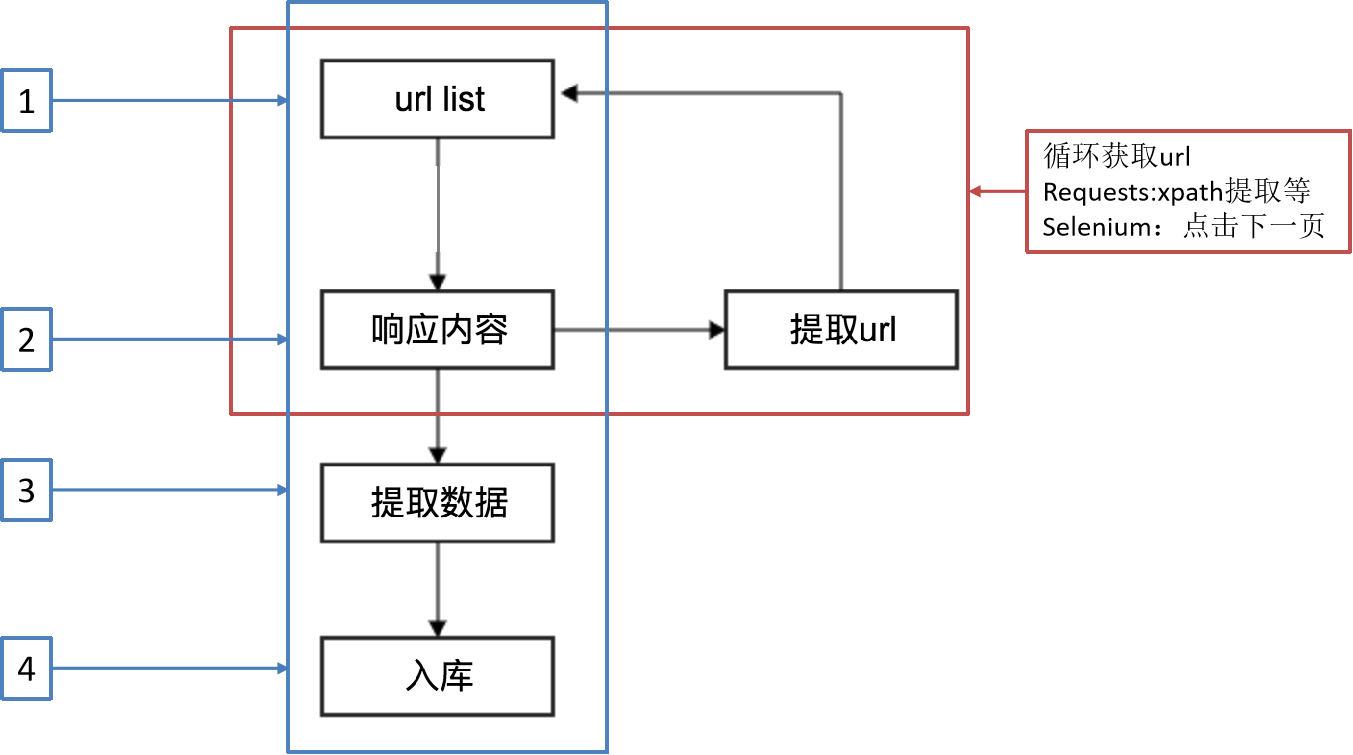
另一种爬虫方式
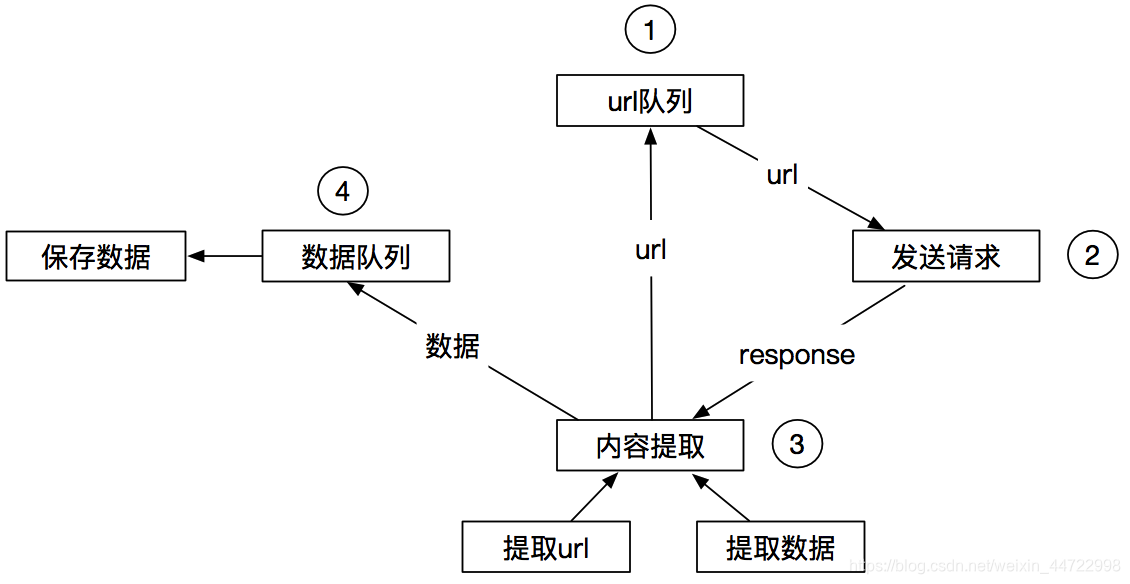
Scrapy工作流程图示
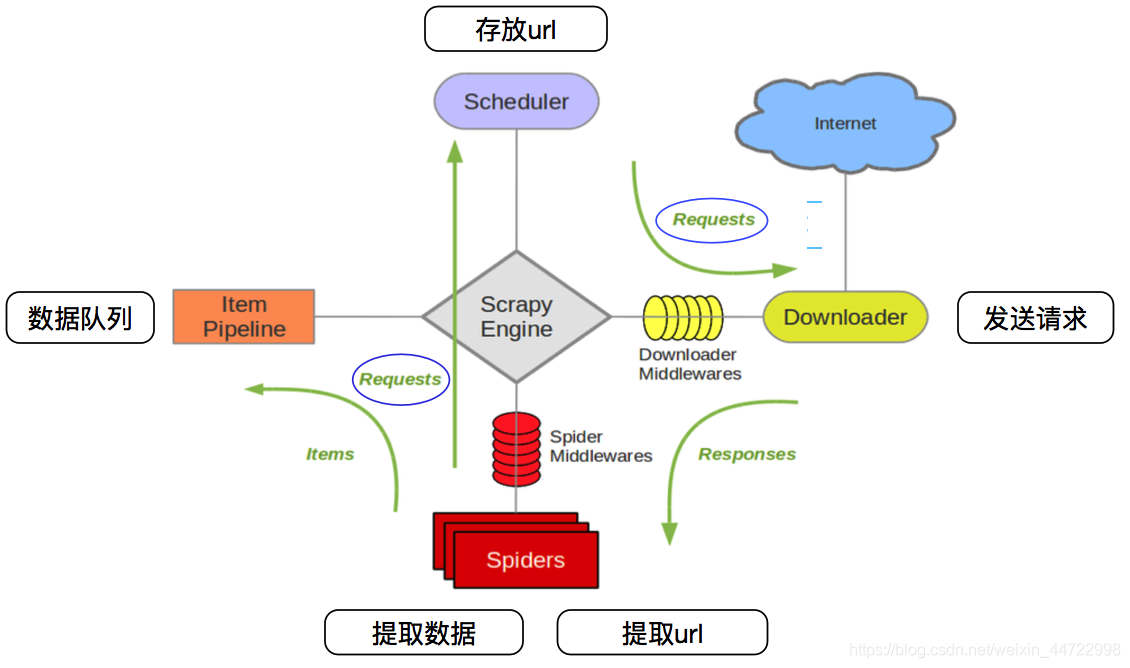
| Scrapy engine(引擎) | 总指挥:负责数据和信号的在不同模块间的传递 | scrapy已经实现 |
|---|---|---|
| Scheduler(调度器) | 一个队列,存放引擎发过来的request请求 | scrapy已经实现 |
| Downloader(下载器) | 下载把引擎发过来的requests请求,并返回给引擎 | scrapy已经实现 |
| Spider(爬虫) | 处理引擎发来的response,提取数据,提取url,并交给引擎 | 需要手写 |
| Item Pipline(管道) | 处理引擎传过来的数据,比如存储 | 需要手写 |
| Downloader Middlewares(下载中间件 | 可以自定义的下载扩展,比如设置代理 | 一般不用手写 |
| Spider Middlewares(中间件) | 可以自定义requests请求和进行response过滤 | 一般不用手写 |
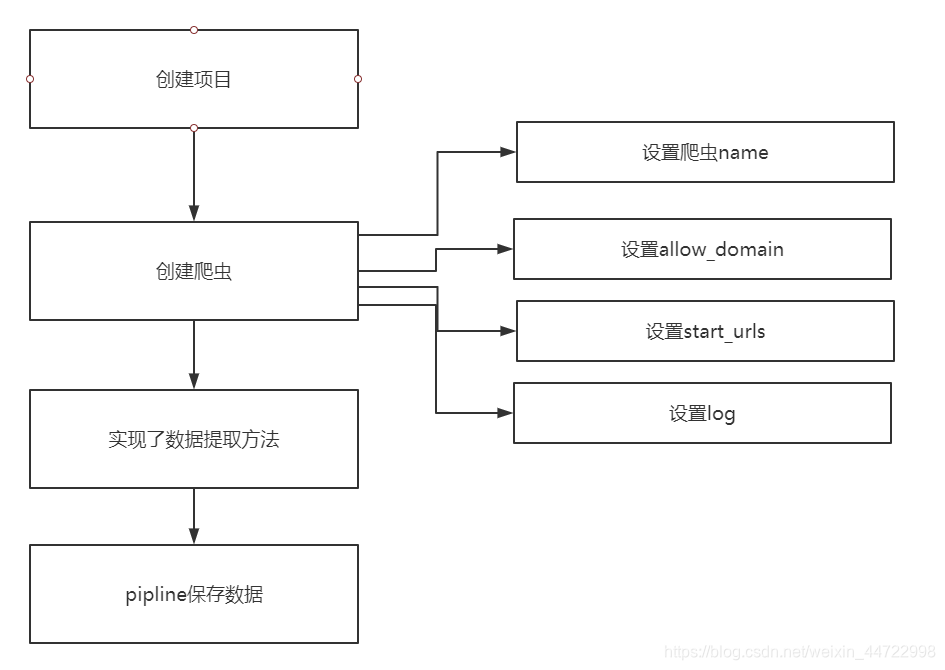
Scrapy入门
1 创建一个scrapy项目
scrapy startproject mySpider
2 生成一个爬虫
scrapy genspider demo "demo.cn"
3 提取数据
- extract_first()
- extract()
完善spider 使用xpath等
4 保存数据
pipeline中保存数据
在命令中运行爬虫
scrapy crawl qb # qb爬虫的名字
在pycharm中运行爬虫
from scrapy import cmdline
cmdline.execute("scrapy crawl qb".split())
pipline使用
从pipeline的字典形可以看出来,pipeline可以有多个,而且确实pipeline能够定义多个
为什么需要多个pipeline:
1 可能会有多个spider,不同的pipeline处理不同的item的内容
2 一个spider的内容可以要做不同的操作,比如存入不同的数据库中
注意:
1 pipeline的权重越小优先级越高
2 pipeline中process_item方法名不能修改为其他的名称
logging模块的使用
import scrapy
import logging
logger = logging.getLogger(__name__)
class QbSpider(scrapy.Spider):
name = 'qb'
allowed_domains = ['qiushibaike.com']
start_urls = ['http://qiushibaike.com/']
def parse(self, response):
for i in range(10):
item = {
}
item['content'] = "haha"
# logging.warning(item)
logger.warning(item)
yield item
pipeline文件
import logging
logger = logging.getLogger(__name__)
class MyspiderPipeline(object):
def process_item(self, item, spider):
# print(item)
logger.warning(item)
item['hello'] = 'world'
return item
保存到本地,在setting文件中LOG_FILE = ‘./log.log’
basicConfig样式设置
https://www.cnblogs.com/felixzh/p/6072417.html
回顾
如何翻页

腾讯爬虫案例
通过爬取腾讯招聘的页面的招聘信息,学习如何实现翻页请求
http://hr.tencent.com/position.php
创建项目
scrapy startproject tencent
创建爬虫
scrapy genspider hr tencent.com
scrapy.Request知识点
scrapy.Request(url, callback=None, method='GET', headers=None, body=None,cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None)
常用参数为:
callback:指定传入的URL交给那个解析函数去处理
meta:实现不同的解析函数中传递数据,meta默认会携带部分信息,比如下载延迟,请求深度
dont_filter:让scrapy的去重不会过滤当前URL,scrapy默认有URL去重功能,对需要重复请求的URL有重要用途
item的介绍和使用
items.py
import scrapy
class TencentItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
position = scrapy.Field()
date = scrapy.Field()
Scrapy log信息的认知

Scrapy settings说明和配置
为什么需要配置文件:
配置文件存放一些公共的变量(比如数据库的地址,账号密码等)
方便自己和别人修改
一般用全大写字母命名变量名 SQL_HOST = '192.168.0.1'
settings文件详细信息:https://www.cnblogs.com/cnkai/p/7399573.html
Scrapy CrawlSpider说明
之前的代码中,我们有很大一部分时间在寻找下一页的URL地址或者内容的URL地址上面,这个过程能更简单一些吗?
思路:
1.从response中提取所有的标签对应的URL地址
2.自动的构造自己resquests请求,发送给引擎
目标:通过爬虫了解crawlspider的使用
生成crawlspider的命令:scrapy genspider -t crawl 爬虫名字 域名
LinkExtractors链接提取器
使用LinkExtractors可以不用程序员自己提取想要的url,然后发送请求。这些工作都可以交给LinkExtractors,他会在所有爬的页面中找到满足规则的url,实现自动的爬取。
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains = (),
deny_domains = (),
deny_extensions = None,
restrict_xpaths = (),
tags = ('a','area'),
attrs = ('href'),
canonicalize = True,
unique = True,
process_value = None
)
主要参数讲解:
• allow:允许的url。所有满足这个正则表达式的url都会被提取。
• deny:禁止的url。所有满足这个正则表达式的url都不会被提取。
• allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取。
• deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。
• restrict_xpaths:严格的xpath。和allow共同过滤链接。
Rule规则类
定义爬虫的规则类。
class scrapy.spiders.Rule(
link_extractor,
callback = None,
cb_kwargs = None,
follow = None,
process_links = None,
process_request = None
)
主要参数讲解:
• link_extractor:一个LinkExtractor对象,用于定义爬取规则。
• callback:满足这个规则的url,应该要执行哪个回调函数。因为CrawlSpider使用了parse作为回调函数,因此不要覆盖parse作为回调函数自己的回调函数。
• follow:指定根据该规则从response中提取的链接是否需要跟进。
• process_links:从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class YgSpider(CrawlSpider):
name = 'yg'
allowed_domains = ['sun0769.com']
start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4&page=0']
rules = (
Rule(LinkExtractor(allow=r'wz.sun0769.com/html/question/201811/\d+\.shtml'), callback='parse_item'),
Rule(LinkExtractor(allow=r'http:\/\/wz.sun0769.com/index.php/question/questionType\?type=4&page=\d+'), follow=True),
)
def parse_item(self, response):
item = {
}
item['content'] = response.xpath('//div[@class="c1 text14_2"]//text()').extract()
print(item)
案例演示 爬取小程序社区
http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1
Scrapy 模拟登录
那么对于scrapy来说,也是有两个方法模拟登录:
• 1 直接携带cookie
• 2 找到发送post请求的URL地址,带上信息,发送请求
Scrapy模拟登录人人网
• 携带cookie
在spider文件中
# 重写start_requests()方法
def start_requests(self):
headers = {
'ua':'xxx',
'cookie':'xxxxx'
}
# 发送请求
yield scrapy.Request(
url=self.start_urls[0],
headers=headers
#此结果没有获取到数据
)
改写
# 重写start_requests()方法
def start_requests(self):
# 携带cookie
cookies = 'anonymid=kc1mze9joexboe; _r01_=1; taihe_bi_sdk_uid=c5ab893b13e43548f001c993d2154595; id=974676254; xnsid=d022a847; jebecookies=75dbf0fd-5be4-4d9e-bb02-b10e891a7a43|||||; ver=7.0'
# 解决cookie格式的问题 str --> dict 字典推导式
cookies = {
i.split('=')[0]:i.split('=')[1] for i in cookies.split('; ')}
# 发送请求
yield scrapy.Request(
url=self.start_urls[0],
# 处理请求的结果
callback=self.parse,
# 携带cookie
cookies=cookies
)
Scrapy模拟登录github
• 发送post请求
Scrapy自动登录
class GithubSpider(scrapy.Spider):
name = 'github'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response):
commit = 'Sign in'
#可以在网页中可以获取到加密的数据所以就简单了
authenticity_token = response.xpath("//input[@name='authenticity_token']/@value").extract_first()
# ga_id = response.xpath("//input[@name='ga_id']/@value").extract_first()
login = 'LogicJerry'
password = '12122121zxl'
timestamp = response.xpath("//input[@name='timestamp']/@value").extract_first()
timestamp_secret = response.xpath("//input[@name='timestamp_secret']/@value").extract_first()
# 定义一个字典提交数据
data = {
'commit': commit,
'authenticity_token': authenticity_token,
# 'ga_id': ga_id,
'login': login,
'password': password,
'webauthn-support': 'supported',
'webauthn-iuvpaa-support': 'unsupported',
'timestamp': timestamp,
'timestamp_secret': timestamp_secret,
}
# 提交数据发送请求
yield scrapy.FormRequest(
# 提交的地址
url='https://github.com/session',
# 提交数据
formdata=data,
# 响应方法
callback=self.after_login
)
def after_login(self,response):
# print(response)
# 保存文件
with open('github3.html','w',encoding='utf-8') as f:
f.write(response.body.decode())
快速登录:
def parse(self, response):
yield scrapy.FormRequest.from_response(
# 请求响应结果
response=response,
# 提交数据
formdata={
'login_field':'LogicJerry','password':'12122121zxl'},
# 回调函数
callback=self.after_login
)
def after_login(self,response):
# print(response)
# 保存文件
with open('github4.html','w',encoding='utf-8') as f:
f.write(response.body.decode())
Scrapy下载图片
载图片案例 爬取汽车之家图片
scrapy为下载item中包含的文件提供了一个可重用的item pipelines,这些pipeline有些共同的方法和结构,一般来说你会使用Files Pipline或者Images Pipeline
爬取汽车家
https://www.autohome.com.cn/65/#levelsource=000000000_0&pvareaid=101594
选择使用scrapy内置的下载文件的方法
• 1:避免重新下载最近已经下载过的数据
• 2:可以方便的指定文件存储的路径
• 3:可以将下载的图片转换成通用的格式。如:png,jpg
• 4:可以方便的生成缩略图
• 5:可以方便的检测图片的宽和高,确保他们满足最小限制
• 6:异步下载,效率非常高
Pipeline
下载文件的 Files Pipeline
使用Files Pipeline下载文件,按照以下步骤完成:
• 定义好一个Item,然后在这个item中定义两个属性,分别为file_urls以及files。files_urls是用来存储需要下载的文件的url链接,需要给一个列表
• 当文件下载完成后,会把文件下载的相关信息存储到item的files属性中。如下载路径、下载的url和文件校验码等
• 在配置文件settings.py中配置FILES_STORE,这个配置用来设置文件下载路径
• 启动pipeline:在ITEM_PIPELINES中设置scrapy.piplines.files.FilesPipeline:1
下载图片的 Images Pipeline
使用images pipeline下载文件步骤:
• 定义好一个Item,然后在这个item中定义两个属性,分别为image_urls以及images。image_urls是用来存储需要下载的文件的url链接,需要给一个列表
• 当文件下载完成后,会把文件下载的相关信息存储到item的images属性中。如下载路径、下载的url和图片校验码等
• 在配置文件settings.py中配置IMAGES_STORE,这个配置用来设置文件下载路径
• 启动pipeline:在ITEM_PIPELINES中设置scrapy.pipelines.images.ImagesPipeline:1
一:
不配置pipeline:默认框架图片管道
方法一:
1,设置setting,
a:ROBOTSTXT_OBEY = False,关闭机器人协议
b:设置ua19行附近
USER_AGENT = {
'Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50'}
c,开启图片管道,大概在67行,
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,###注意写法
}
d:IMAGES_STORE="image"#储存图片的位置,此时为当前位置
3:spider设置·
在spider中把图片连接标签改为image_urls,注意返回的src必须是列表list类型,并用yield方法推送出去:yield{
"image_urls":image_urls},注(使用系统默认图片管道,因为框架方法中默认的是image_urls,换个变量框架识别不出来)
方法二:
1,设置setting,
a,ROBOTSTXT_OBEY = False,关闭机器人协议
b:设置ua19行附近
USER_AGENT = 'Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50'
c,开启图片管道,大概在67行,
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline':
IMAGES_URLS_FIELD="src"#存储图片的链接方法
IMAGES_STORE="image"#储存图片的位置,此时为当前位置
2:item设置
src=scrapy.Field(),
3:spider设置·导入item包,并推送item:yield item
总结:
此方法不能给图片命,如果callback函数不起作用注意allowed_domains()是否定义出问题
注意callback函数用法,yield scrapy.Request(url=url,callback=self.parse)注意,首先明确的是self只有在类的方法中才会有且必须,在调用时不必传入相应的参数。
独立的函数或方法是不必带有self的。self指向当前对象自身。此时Request()中url必须是字符串,不可以是列表
当返回的src标签不全时可以:1:直接和原网址请求网址相加,2:用yield scrapy.Request(url=response.urljoin(next_url),callback=self.get_info)注意在下一个函数名字前加self,不要括号
def get_info(self,response):注意response
知识点总结,
知识点总结,
yield scrapy.Request(url=url, meta={
'item': item}, callback=self.parse_detail, dont_filter=False)
去重机制:Request的参数dont_filter默认是False(去重),每yield一个Request,就将url参数与调度器内已有的url进行比较,如果存在相同url则默认不入队列,如果没有相同的url则入队列,每一个url入队列前都要与现有的url进行比较。如果想要实现不去重效果,则将dont_filter改为True
注意要把item实例放到for循环中,最后再用yield方法:
yield scrapy.Request(url=url, meta={
'item': item}, callback=self.parse_detail, dont_filter=False)
接受item用item = response.meta['item']
1:setting:
ITEM_PIPELINES = {
# 'scrapy.pipelines.images.ImagesPipeline': 1,
"meinvtupian.pipelines.MeinvtupianPipeline":1,}
IMAGES_URLS_FIELD="src"#存储图片的链接
IMAGES_STORE="e:/img"
2:item:
src = scrapy.Field()
name = scrapy.Field()
3:pipelines设置:
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class MeinvtupianPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for src in item["src"]:#实现循环
yield scrapy.Request(url=src, meta={
'item': item})#注意·meta方法
def file_path(self, request, response=None, info=None):
item = request.meta['item']#注意
name = item['name']
for name in name:#注意缩进
#path = name + ".jpg"#结尾是jpg方式.此方法只能获取一个图片
image_guid = request.url.split('/')[-1]
path = name+image_guid
return path #必须返回path
多级页面的抓取:
注意要把item实例放到for循环中,最后再用yield方法传输数据:
yield scrapy.Request(url=url,meta={
'item':item},callback=self.parse_detail,follow=False)
接受item用:item = response.meta['item']
for made in made:
item["made"]=made
yield scrapy.deepcopy(item)#注意yied放在循环之外
Scrapy 下载中间件
下载中间件是scrapy提供用于用于在爬虫过程中可修改Request和Response,用于扩展scrapy的功能
使用方法:
• 编写一个Download Middlewares和我们编写一个pipeline一样,定义一个类,然后再settings中开启
Download Middlewares默认方法:
处理请求,处理响应,对应两个方法
process_request(self,request,spider):
当每个request通过下载中间件时,该方法被调用
process_response(self,request,response,spider):
当下载器完成http请求,传递响应给引擎的时候调用
process_request(request,spider)
当每个Request对象经过下载中间件时会被调用,优先级越高的中间件,越先调用;该方法应该返回以下对象:None/Response对象/Request对象/抛出IgnoreRequest异常
• 返回None:scrapy会继续执行其他中间件相应的方法;
• 返回Response对象:scrapy不会再调用其他中间件的process_request方法,也不会去发起下载,而是直接返回该Response对象
• 返回Request对象:scrapy不会再调用其他中间件的process_request()方法,而是将其放置调度器待调度下载
• 如果这个方法抛出异常,则会调用process_exception方法
process_response(request,response,spider)
当每个Response经过下载中间件会被调用,优先级越高的中间件,越晚被调用,与process_request()相反;该方法返回以下对象:Response对象/Request对象/抛出IgnoreRequest异常。
• 返回Response对象:scrapy会继续调用其他中间件的process_response方法;
• 返回Request对象:停止中间器调用,将其放置到调度器待调度下载;
• 抛出IgnoreRequest异常:Request.errback会被调用来处理函数,如果没有处理,它将会被忽略且不会写进日志。
设置随机请求头
爬虫在频繁访问一个页面的时候,这个请求如果一直保持一致。那么很容易被服务器发现,从而禁止掉这个请求头的访问。因此我们要在访问这个页面之前随机的更改请求头,这样才可以避免爬虫被抓。随机更改请求头,可以在下载中间件实现。在请求发送给服务器之前,随机的选择一个请求头。这样就可以避免总使用一个请求头
测试请求头网址: http://httpbin.org/user-agent
在middlewares.py文件中
注意方法:
spider.settings[‘USER_AGENTS’]
- 方法1
class RandomUserAgent(object):
def process_request(self,request,spider):
useragent = random.choice(spider.settings['USER_AGENTS'])
request.headers['User-Agent'] = useragent
class CheckUserAgent(object):
def process_response(self,request,response,spider):
print(request.headers['User-Agent'])
return response
- 方法2
class Middlewareua():
def process_request(self, request, spider):
ua = UserAgent().chrome
request.headers['User-Agent'] = ua
print(ua)
请求头网址:http://www.useragentstring.com/pages/useragentstring.php?typ=Browser
添加代理
- 方法1
class Proxy_Middleware():
def process_request(self, request, spider):
try:
xdaili_url = spider.settings.get('XDAILI_URL')#从设置中获取代理池
r = requests.get(xdaili_url)
proxy_ip_port = r.text
request.meta['proxy'] = 'https://' + proxy_ip_port
except requests.exceptions.RequestException:
print('获取讯代理ip失败!')
spider.logger.error('获取讯代理ip失败!')
- 方法2
class Proxy_Middleware():
def process_request(self, request, spider):
#可被选用的代理IP
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
]
# 使用代理池进行请求代理ip的设置
print('this is process_exception!')
if request.url.split(':')[0] == 'http':
request.meta['proxy'] = random.choice(self.PROXY_http)
else:
request.meta['proxy'] = random.choice(self.PROXY_https)
USER_AGENTS = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" ]
添加selenum获取动态网页
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver import ChromeOptions
import time
from fake_useragent import UserAgent
from scrapy.http import HtmlResponse
class TianmaoSpiderMiddleware(object):
# def process_request(self):
def process_request(self,request,spider):
#设置无头浏览器
option = webdriver.ChromeOptions()
option.add_argument('--headless')
#设置浏览器
driver = webdriver.Chrome(chrome_options=option)
# driver=webdriver.Chrome()
#请求网页
driver.get(url=request.url)
#模拟向下滑动页面
length = 1000
for i in range(0, 3):
js = "var q=document.body.scrollTop=" + str(length)
driver.execute_script(js)
time.sleep(1)
length += length
#获取动态网页代码
page_text = driver.page_source
# 篡改响应对象
print("中间件被执行了")
return HtmlResponse(url=driver.current_url, body=page_text, encoding='utf-8', request=request)
Scrapy导出数据:cvs, json,xml格式
scrapy crawl 爬虫名 - o 文件名.json
scrapy crawl 爬虫名 - o 文件名.csv
scrapy crawl 爬虫名 - o 文件名.xml
保存数据为文本格式:
class JsonPipeline(object):
def process_item(self,item,spider):
base_dir = os.getcwd()#获取当前工作路径
file_name = base_dir + '/test.txt'
# 以追加的方式打开并写入文件
with open (file_name,"a") as f:
f.write(item + '\n') # \n代表换行符
return item
保存数据为json格式
2.保存数据为json格式(需要导入json,os模块)
class JsonPipeline(self,item,spider):
base_dir = os.getcwd()
file_name = base_dir + '/test.json'
# 把字典类型的数据转换成json格式,并写入
with open(file_name,"a") as f:
line = json.dumps(dict(item),ensure_ascii=False,indent=4)
f.write(line)
f.write("\n")
return item
这里需要解释下json.dumps()里面的几个参数:
- item:提取的数据,数据要转换为json格式
- ensure_ascii:要设置为false,不然数据会直接以utf-8的方式存入
- indent:格式化输出,增加可阅读性
以 excel表格的形式存储
import csv
def process_item(self, item, spider):
with open('data1.csv','w')as f:
# fieldnames = ['aa', 'cc']
# writer = csv.DictWriter(f,fieldnames=fieldnames)#添加表头,但是代码没有运行,这步暂时不用的,不##太理解
writer = csv.writer(f)
writer.writerow(['名字', '评分'])#添加表头第一行
for title, pingfen in zip(item['title'], item['pingfen']):
writer.writerow([title, pingfen])
注意:
os.getcwd() 该函数不需要传递参数,它返回当前的目录。需要说明的是,当前目录并不是指脚本所在的目录,而是所运行脚本的目录。>>>import os>>>print os.getcwd()D:\Program Files\Python27这里的目录即是python的安装目录。若把上面的两行语句保存为getcwd.py,保存于E:\python\盘,运行后显示是E:\pythonscrapy导入模块item,可以简化,设置爬虫为根目录,不必从头开始导入模块,,比如,frome taobao.item import TaobaoIteam
对于多个爬虫的scrapy,有三种方法,1,在spider中item中定义一个名字比如ieem["name"]="taobao",,,这时候可以在下载中间件和item中判断数据
if ieem["name"]=="taobao"
else:
2:判断item是不是主爬虫的一个实例,
isinstance(test, Father)
3,查找spider的名字,进行判断
shell
命令:scrapy shell url
Scrapy练习爬取苏宁图书
• 创建项目
• 创建爬虫
• 首页大分类
• 首页大分类下的小分类
• 小分类下的图书
https://book.suning.com/?safp=d488778a.homepage1.99345513004.47&safpn=10001
•
智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf