迁移学习——数据不够的情况下训练深度学习模型_迁移学习数量-程序员宅基地
深度学习大牛吴恩达曾经说过:做 AI 研究就像造宇宙飞船,除了充足的燃料之外,强劲的引擎也是必不可少的。假如燃料不足,则飞船就无法进入预定轨道。而引擎不够强劲,飞船甚至不能升空。类比于 AI,深度学习模型就好像引擎,海量的训练数据就好像燃料,这两者对于 AI 而言同样缺一不可。
随着深度学习技术在机器翻译、策略游戏和自动驾驶等领域的广泛应用和流行,阻碍该技术进一步推广的一个普遍性难题也日渐凸显:训练模型所必须的海量数据难以获取。
以下是一些当前比较流行的机器学习模型和其所需的数据量,可以看到,随着模型复杂度的提高,其参数个数和所需的数据量也是惊人的。

基于这一现状,本文将从深度学习的层状结构入手,介绍模型训练所需的数据量和模型规模的关系,然后通过一个具体实例介绍迁移学习在减少数据量方面起到的重要作用,最后推荐一个可以简化迁移学习实现步骤的云工具:NanoNets。
层状结构的深度学习模型
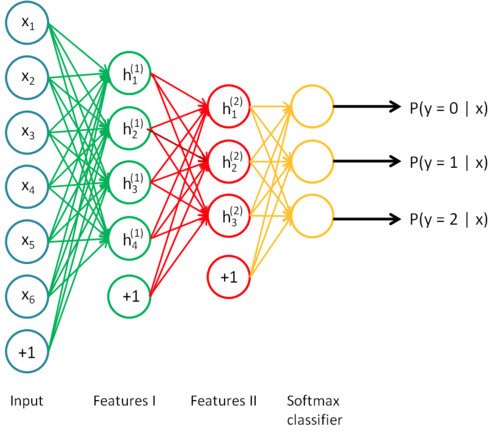
深度学习是一个大型的神经网络,同时也可以被视为一个流程图,数据从其中的一端输入,训练结果从另一端输出。正因为是层状的结构,所以你也可以打破神经网络,将其按层次分开,并以任意一个层次的输出作为其他系统的输入重新展开训练。
数据量、模型规模和问题复杂度
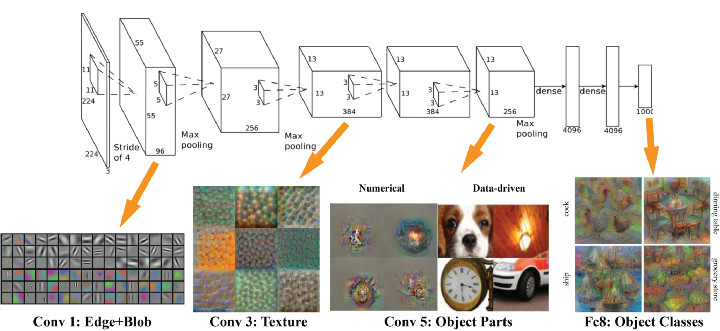
模型需要的训练数据量和模型规模之间存在一个有趣的线性正相关关系。其中的一个基本原理是,模型的规模应该足够大,这样才能充分捕捉数据间不同部分的联系(例如图像中的纹理和形状,文本中的语法和语音中的音素)和待解决问题的细节信息(例如分类的数量)。模型前端的层次通常用来捕获输入数据的高级联系(例如图像边缘和主体等)。模型后端的层次通常用来捕获有助于做出最终决定的信息(通常是用来区分目标输出的细节信息)。因此,待解决的问题的复杂度越高(如图像分类等),则参数的个数和所需的训练数据量也越大。
引入迁移学习
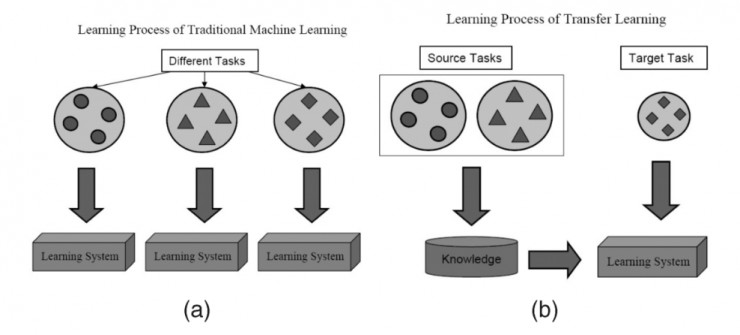
在大多数情况下,面对某一领域的某一特定问题,你都不可能找到足够充分的训练数据,这是业内一个普遍存在的事实。但是,得益于一种技术的帮助,从其他数据源训练得到的模型,经过一定的修改和完善,就可以在类似的领域得到复用,这一点大大缓解了数据源不足引起的问题,而这一关键技术就是迁移学习。
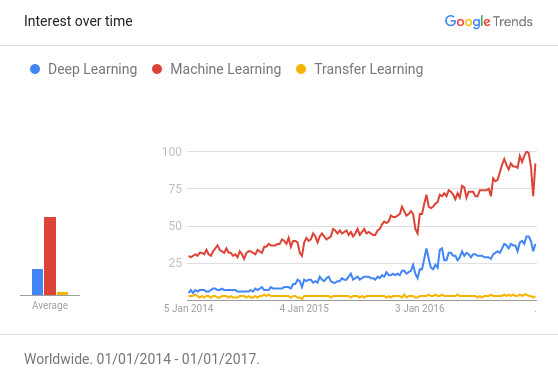
根据 Github 上公布的“引用次数最多的深度学习论文”榜单,深度学习领域中有超过 50% 的高质量论文都以某种方式使用了迁移学习技术或者预训练(Pretraining)。迁移学习已经逐渐成为了资源不足(数据或者运算力的不足)的 AI 项目的首选技术。但现实情况是,仍然存在大量的适用于迁移学习技术的 AI 项目,并不知道迁移学习的存在。如下图所示,迁移学习的热度远不及机器学习和深度学习。
迁移学习的基本思路是利用预训练模型,即已经通过现成的数据集训练好的模型(这里预训练的数据集可以对应完全不同的待解问题,例如具有相同的输入,不同的输出)。开发者需要在预训练模型中找到能够输出可复用特征(feature)的层次(layer),然后利用该层次的输出作为输入特征来训练那些需要参数较少的规模更小的神经网络。由于预训练模型此前已经习得了数据的组织模式(patterns),因此这个较小规模的网络只需要学习数据中针对特定问题的特定联系就可以了。此前流行的一款名为 Prisma 的修图 App 就是一个很好的例子,它已经预先习得了梵高的作画风格,并可以将之成功应用于任意一张用户上传的图片中。
值得一提的是,迁移学习带来的优点并不局限于减少训练数据的规模,还可以有效避免过度拟合(overfit),即建模数据超出了待解问题的基本范畴,一旦用训练数据之外的样例对系统进行测试,就很可能出现无法预料的错误。但由于迁移学习允许模型针对不同类型的数据展开学习,因此其在捕捉待解问题的内在联系方面的表现也就更优秀。如下图所示,使用了迁移学习技术的模型总体上性能更优秀。
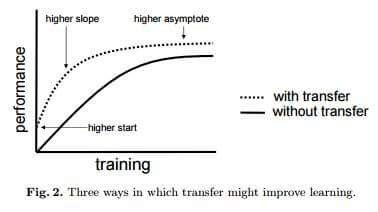
迁移学习到底能消减多少训练数据?

这里以此前网上流行的一个连衣裙图片为例。如图所示,如果你想通过深度学习判断这条裙子到底是蓝黑条纹还是白金条纹,那就必须收集大量的包含蓝黑条纹或者白金条纹的裙子的图像数据。参考上文提到的问题规模和参数规模之间的对应关系,建立这样一个精准的图像识别模型至少需要 140M 个参数,1.2M 张相关的图像训练数据,这几乎是一个不可能完成的任务。
现在引入迁移学习,用如下公式可以得到在迁移学习中这个模型所需的参数个数:
No. of parameters = [Size (inputs) + 1] * [Size (outputs) + 1] = [2048+1]*[1+1]~ 4098 parameters
可以看到,通过迁移学习的引入,针对同一个问题的参数个数从 140M 减少到了 4098,减少了 10 的 5 次方个数量级!这样的对参数和训练数据的消减程度是惊人的。
一个迁移学习的具体实现样例
在本例中,我们需要用深度学习技术对电影短评进行文本倾向性分析,例如“It was great,loved it.”表示积极正面的评论,“It was really stupid.”表示消极负面的评论。
假设现在可以得到的数据规模只有 72 条,其中 62 条没有经过预先的倾向性标记,用来预训练。8 条经过了预先的倾向性标记,用来训练模型。2 条也经过了预先的倾向性标记,用来测试模型。
由于我们只有 8 条经过预先标记的训练数据,如果直接以这样的数据量对模型展开训练,无疑最终的测试准确率将非常低。(因为判断结果只有正面和负面两种,因此可以预见最终的测试准确率可能只有 50%)
为了解决这个难题,我们引入迁移学习。即首先用 62 条未经标记的数据对模型展开通用的情感判断,然后在这一预训练的基础上对本例的特定问题展开分析,复用预训练模型中的部分层次,就可以将最终的测试准确率提升到 100%。下面将从 3 个步骤展开分析。
步骤1
创建预训练模型来分析词与词之间的关系。这里我们通过分析未标记语句中的某一词汇,尝试预测出现在同一句子中的其他词汇。
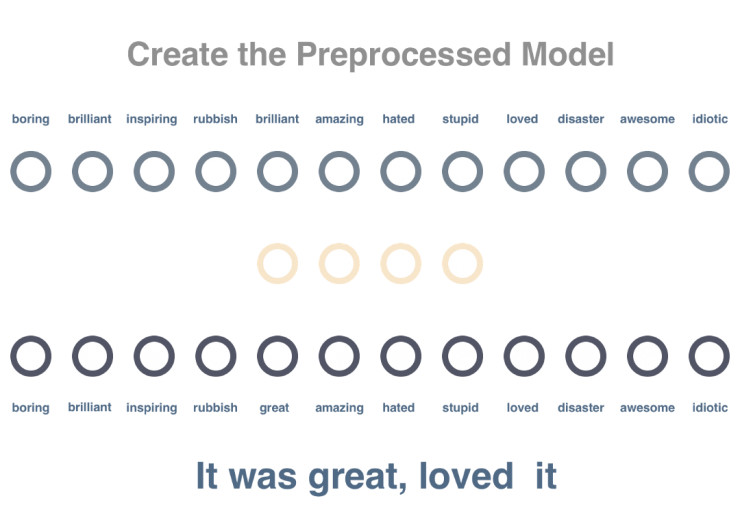
步骤2
对模型展开训练,使得出现在类似上下文中的词汇获得类似的向量表示。在这一步骤中,62 条待处理语句首先会被删除停用词,并被标记解释。之后,针对每个词汇,系统会尝试减小其向量表示与相关词汇的差别,并增加其与不相关词汇的差别。
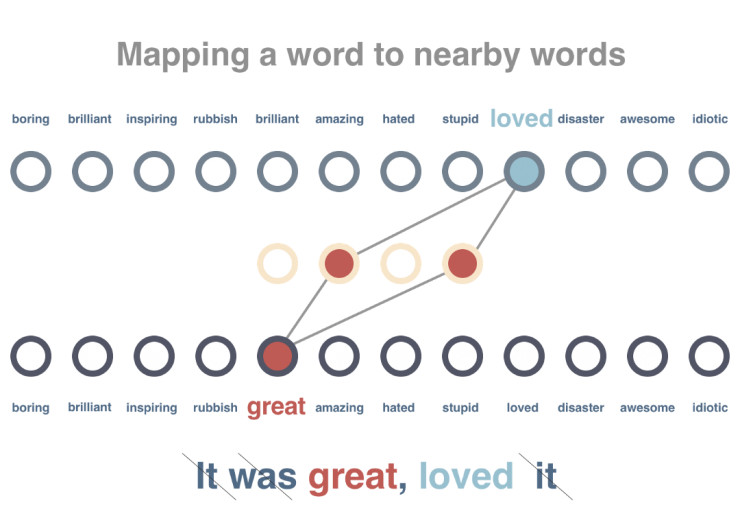
步骤3
预测一个句子的文本倾向性。由于在此前的预训练模型中我们已经得到了针对所有词汇的向量表示,并且这些向量具有用数字表征的每个词汇的上下文属性,这将使得文本的倾向性分析变得更易于实现。
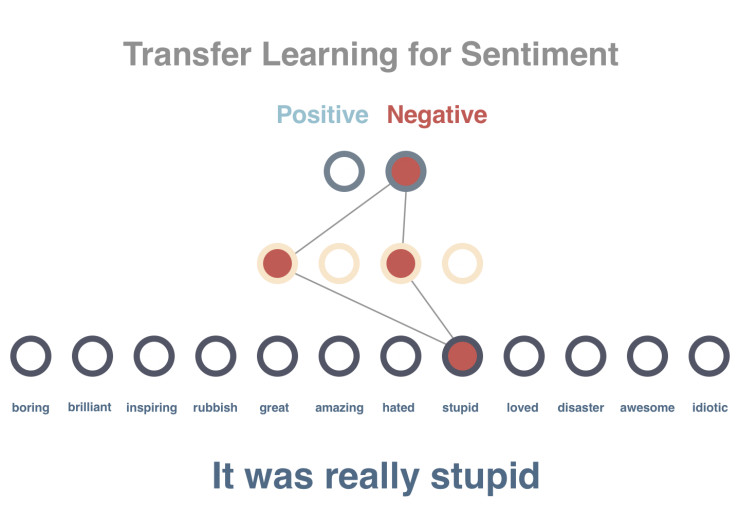
需要注意的是,这里并非直接使用 10 个已经被预先标记的句子,而是先将句子的向量设置为其所有词汇的平均值(在实际任务中,我们将使用类似时间递归神经网络 LSTM 的相关原理)。这样,经过平均化处理的句子向量将作为输入数据导入模型,而句子的正面或负面判定将作为结果输出。需要特别强调的是,这里我们在预训练模型和 10 个被预先标记的句子之间加入了一个隐藏层(hidden layer),用来适配文本倾向性分析这一特定场景。正如你所看到的,这里只用 10 个标记量就实现了 100% 的预测准确率。
当然,必须指出的是,这里展示的只是一个非常简单的模型示意,而且测试用例只有 2 条。但不可否认的一点是,由于迁移学习的引入,确实使得本例中的文本倾向性预测准确率从 50% 提升到了 100%。
本例的完整代码详见如下链接:https://gist.github.com/prats226/9fffe8ba08e378e3d027610921c51a78
迁移学习的实现难点
虽然迁移学习的引入可以显著减少模型对训练数据量的要求,但同时也意味着更多的专业调教。从上面的例子就能看出,只是考虑这些海量的必须硬编码实现的参数数量,以及围绕这些参数进行的繁杂的调试过程,就足够让人望而生畏了。而这也是迁移学习在实际应用中难以进一步推广的重要阻碍之一。这里我们总结了 8 条常见的迁移学习的实现难点。
1. 获取一个相对大规模的预训练数据
2. 选择一个合适的预训练模型
3. 难以排查哪个模型没有发挥作用
4. 不知道需要多少额外数据来训练模型
5. 难以判断应该在什么情况下停止预训练
6. 决定预训练模型的层次和参数个数
7. 代理和服务于组合模型
8. 当获得更多数据或者更好的算法时,预训练模型难以更新
NanoNets 工具
NanoNets 是一个简单方便的基于云端实现的迁移学习工具,其内部包含了一组已经实现好的预训练模型,每个模型有数百万个训练好的参数。用户可以自己上传或通过网络搜索得到数据,NanoNets 将自动根据待解问题选择最佳的预训练模型,并根据该模型建立一个 NanoNets(纳米网络),并将之适配到用户的数据。NanoNets 和预训练模型之间的关系结构如下所示。
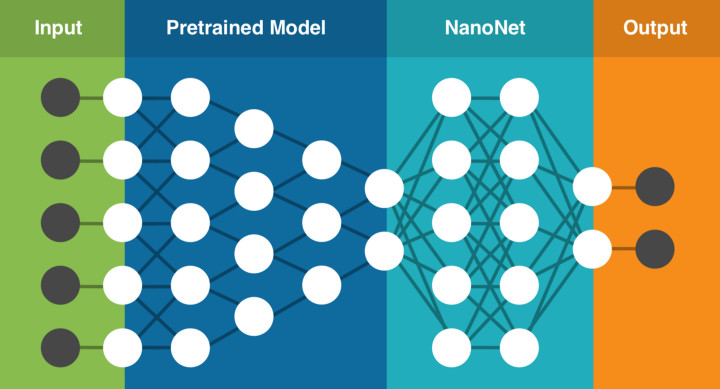
以上文提到的蓝黑条纹还是白金条纹的连衣裙为例,用户只需要选择待分类的名称,然后自己上传或者网络搜索训练数据,之后 NanoNets 就会自动适配预训练模型,并生成用于测试的 web 页面和用于进一步开发的 API 接口。如下所示,图中为系统根据一张连衣裙图片给出的分析结果。

具体使用方法详见 NanoNets 官网:http://nanonets.ai/ 。值得一提的是,由于处于推广期,NanoNets 的 API 接口在 3 月 1 日之前都会免费开放,感兴趣的小伙伴不妨试一试吧。
来源:medium
智能推荐
【新手科研指南5】深度学习代码怎么读-小白阶段性思路(以手写数字识别应用为例)_深度学习程序怎么读-程序员宅基地
文章浏览阅读6.2k次,点赞6次,收藏26次。我是一个深度学习代码小白,请你用中文写上注释,能让我能轻松理解下面这段代码。注意包含所有函数、调用和参数的注释。以同样的python代码块样式返回你写的代码给我。代码看累了,就看《动手学深度学习》文档:基于PyTorch框架,从底层函数实现基础功能,再到框架的高级功能。努力上路的小白一枚,麻烦路过的大佬指导一二,同时希望能和大家交流学习~争取更新学习这个文档的专栏,记录学习过程。量身定做了一套话术hhh,亲身测试还不错。这个感觉更浅一点儿,之后复习看吧。20天吃掉那只Pytorch。_深度学习程序怎么读
Java学习路线图,看这一篇就够了!-程序员宅基地
文章浏览阅读2.7w次,点赞126次,收藏1.2k次。耗废1024根秀发,Java学习路线图来了,整合了自己所学的所有技术整理出来的2022最新版Java学习路线图,适合于初、中级别的Java程序员。_java学习路线
PCL_Tutorial2-1.7-点云保存PNG_pcl::io:savepng-程序员宅基地
文章浏览阅读4.4k次。1.7-savingPNG介绍代码详情函数详解savePNGFile()源码savePNGFile()源码提示savePNGFile()推荐用法处理结果代码链接介绍PCL提供了将点云的值保存到PNG图像文件的可能性。这只能用有有序的云来完成,因为结果图像的行和列将与云中的行和列完全对应。例如,如果您从类似Kinect或Xtion的传感器中获取了点云,则可以使用它来检索与该云匹配的640x480 RGB图像。代码详情#include <pcl / io / pcd_io.h>#incl_pcl::io:savepng
知乎问答:程序员在咖啡店编程,喝什么咖啡容易吸引妹纸?-程序员宅基地
文章浏览阅读936次。吸引妹子的关键点不在于喝什么咖啡,主要在于竖立哪种男性人设。能把人设在几分钟内快速固定下来,也就不愁吸引对口的妹子了。我有几个备选方案,仅供参考。1. 运动型男生左手单手俯卧撑,右手在键盘上敲代码。你雄壮的腰腹肌肉群活灵活现,简直就是移动的春药。2.幽默男生花 20 块找一个托(最好是老同学 or 同事)坐你对面。每当你侃侃而谈,他便满面涨红、放声大笑、不能自已。他笑的越弱_咖啡厅写代码
【笔试面试】腾讯WXG 面委会面复盘总结 --一次深刻的教训_腾讯面委会面试是什么-程序员宅基地
文章浏览阅读1.2w次,点赞5次,收藏5次。今天 (应该是昨天了,昨晚太晚了没发出去)下午参加了腾讯WXG的面委会面试。前面在牛客上搜索了面委会相关的面经普遍反映面委会较难,因为都是微信的核心大佬,问的问题也会比较深。昨晚还蛮紧张的,晚上都没睡好。面试使用的是腾讯会议,时间到了面试官准时进入会议。照例是简单的自我介绍,然后是几个常见的基础问题:例如数据库索引,什么时候索引会失效、设计模式等。这部分比较普通,问的也不是很多,不再赘述。现在回想下,大部分还是简历上写的技能点。接下来面试官让打开项目的代码,对着代码讲解思路。我笔记本上没有这部分代码,所_腾讯面委会面试是什么
AI绘画自动生成器:艺术创作的新浪潮-程序员宅基地
文章浏览阅读382次,点赞3次,收藏4次。AI绘画自动生成器是一种利用人工智能技术,特别是深度学习算法,来自动创建视觉艺术作品的软件工具。这些工具通常基于神经网络模型,如生成对抗网络(GANs),通过学习大量的图像数据来生成新的图像。AI绘画自动生成器作为艺术与科技结合的产物,正在开启艺术创作的新篇章。它们不仅为艺术家和设计师提供了新的工具,也为普通用户提供了探索艺术的机会。随着技术的不断进步,我们可以预见,AI绘画自动生成器将在未来的创意产业中发挥越来越重要的作用。
随便推点
Flutter ListView ListView.build ListView.separated_flutter listview.separated和listview.builder-程序员宅基地
文章浏览阅读1.7k次。理解为ListView 的三种形式吧ListView 默认构造但是这种方式创建的列表存在一个问题:对于那些长列表或者需要较昂贵渲染开销的子组件,即使还没有出现在屏幕中但仍然会被ListView所创建,这将是一项较大的开销,使用不当可能引起性能问题甚至卡顿直接返回的是每一行的Widget,相当于ios的row。行高按Widget(cell)高设置ListView.build 就和io..._flutter listview.separated和listview.builder
2021 最新前端面试题及答案-程序员宅基地
文章浏览阅读1.4k次,点赞4次,收藏14次。废话不多说直接上干货1.js运行机制JavaScript单线程,任务需要排队执行同步任务进入主线程排队,异步任务进入事件队列排队等待被推入主线程执行定时器的延迟时间为0并不是立刻执行,只是代表相比于其他定时器更早的被执行以宏任务和微任务进一步理解js执行机制整段代码作为宏任务开始执行,执行过程中宏任务和微任务进入相应的队列中整段代码执行结束,看微任务队列中是否有任务等待执行,如果有则执行所有的微任务,直到微任务队列中的任务执行完毕,如果没有则继续执行新的宏任务执行新的宏任务,凡是在..._前端面试
linux基本概述-程序员宅基地
文章浏览阅读1k次。(3)若没有查到,则将请求发给根域DNS服务器,并依序从根域查找顶级域,由顶级查找二级域,二级域查找三级,直至找到要解析的地址或名字,即向客户机所在网络的DNS服务器发出应答信息,DNS服务器收到应答后现在缓存中存储,然后,将解析结果发给客户机。(3)若没有查到,则将请求发给根域DNS服务器,并依序从根域查找顶级域,由顶级查找二级域,二级域查找三级,直至找到要解析的地址或名字,即向客户机所在网络的DNS服务器发出应答信息,DNS服务器收到应答后现在缓存中存储,然后,将解析结果发给客户机。_linux
JavaScript学习手册十三:HTML DOM——文档元素的操作(一)_javascript学习手册十三:html dom——文档元素的操作(一)-程序员宅基地
文章浏览阅读7.9k次,点赞26次,收藏66次。HTML DOM——文档元素的操作1、通过id获取文档元素任务描述相关知识什么是DOM文档元素节点树通过id获取文档元素代码文件2、通过类名获取文档元素任务描述相关知识通过类名获取文档元素代码文件3、通过标签名获取文档元素任务描述相关知识通过标签名获取文档元素获取标签内部的子元素代码文件4、html5中获取元素的方法一任务描述相关知识css选择器querySelector的用法代码文件5、html5中获取元素的方法二任务描述相关知识querySelectorAll的用法代码文件6、节点树上的操作任务描述相关_javascript学习手册十三:html dom——文档元素的操作(一)
《LeetCode刷题》172. 阶乘后的零(java篇)_java 给定一个整数n,返回n!结果尾数中零的数量-程序员宅基地
文章浏览阅读132次。《LeetCode学习》172. 阶乘后的零(java篇)_java 给定一个整数n,返回n!结果尾数中零的数量
php 公众号消息提醒,如何开启公众号消息提醒功能-程序员宅基地
文章浏览阅读426次。请注意,本文将要给大家分享的并不是开启公众号的安全操作风险提醒,而是当公众号粉丝给公众号发消息的时候,公众号的管理员和运营者如何能在手机上立即收到消息通知,以及在手机上回复粉丝消息。第一步:授权1、在微信中点击右上角+,然后选择“添加朋友”,然后选择“公众号”,然后输入“微小助”并关注该公众号。2、进入微小助公众号,然后点击底部菜单【新增授权】,如下图所示:3、然后会打开一个温馨提示页面。请一定要..._php微信公众号服务提示