NNLM Word2Vec FastText LSA Glove 总结_word2vec 和 nnlm 对比有什么区别?-程序员宅基地
NNLM(Neural Network Language Model)
顾名思义,就是神经网络语言模型,本质就是语言模型。word2vec也可以看成一种语言模型,但是为了计算的效率,把神经softmax给拿掉了,下面稍详细写写word2vec
Word2Vec
Word2Vec的结构如下图,假设输入词库的大小是V,每个词都用one-hot来表示,那么每个词的维度就是V。Input layer到Hidden layer之间用一个全连接网络相连,如果Hidden layer有N层,那么参数就是VN。而Output layer最终也是V维,因此从Hidden layer到Output layer之间的参数是VN。
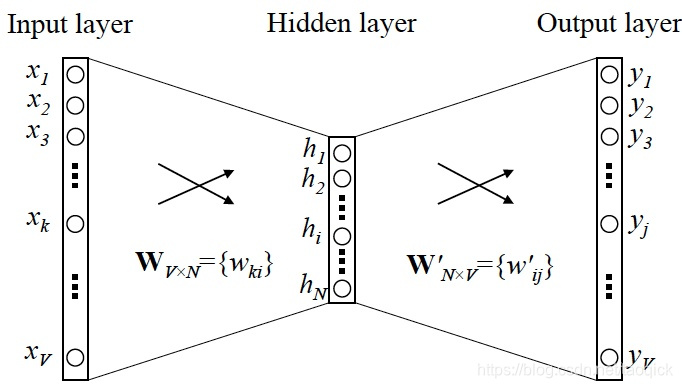
有了这个结构,Word2Vec有两个目标: ∑ w ∈ C l o g ( w ∣ c o n t e x t ) \sum_{w\in C}log(w|context) ∑w∈Clog(w∣context) (Continous bag-of-word)和 ∑ w ∈ C l o g ( c o n t e x t ∣ w ) \sum_{w\in C}log(context|w) ∑w∈Clog(context∣w) (Skip-gram)。当然输出层是一个向量,想把这个向量映射到某个词的概率得用softmax函数 P ( y = x n ∣ x ) = e x n ∑ i = 1 V e x i P(y=x_n|x)=\frac{e^{x_n}}{\sum_{i=1}^Ve^{x_i}} P(y=xn∣x)=∑i=1Vexiexn,其中x为最终输出层输出的向量, x n x_n xn表示x中和单词 w n w_n wn对应的维度的值。
有了这个结构以后,开始用back propagation来求解,但是由于Softmax激活函数中存在归一化项的缘故,推导出来的迭代公式需要对词汇表中的所有单词进行遍历,使得每次迭代过程非常缓慢。这部分推导可以参考word2vec Parameter Learning Explained by Xin Rong,里面非常详细。
为了优化back propagation,word2vec里用了hierarchy softmax,本质是把 N 分类问题变成 log(N)次二分类,但是这种方法还是训练慢。干脆更直接一点用了Negative Sample,实质上对每一个样本中每一个词都进行负例采样。
训练好以后,我们实际上是把隐藏层(Hidden layer也叫projection layer)里的权重拿出来,这样原始的V维one-hot就可以映射成一个N维的向量(N一般在50-300之间)。这个N维的向量有些很好的性质,例如叠加,再比如巴黎-法国=柏林-德国等等。我们在应用中直接load这个word2vec的词表就可以。
FastText
fastText简而言之,就是把文档中所有词通过lookup table变成向量,取平均后直接用线性分类器得到分类结果。
但是比如对下面的三个例子来说:The movie is not very good , but i still like it . [2]The movie is very good , but i still do not like it .I do not like it , but the movie is still very good .其中第1、3句整体极性是positive,但第2句整体极性就是negative。如果只是通过简单的取平均来作为sentence representation进行分类的话,可能就会很难学出词序对句子语义的影响。
这部分转自知乎
作者:董力
链接:https://www.zhihu.com/question/48345431/answer/111513229
LSA
潜在语义分析(Latent Semantic Analysis)可以基于co-occurance matrix构建词向量,实质上是基于全局语料采用SVD进行矩阵分解,然而SVD计算复杂度高,所以潜在语义分析是基于频率的
Glove
GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,说白了就是给共现矩阵降维,但是又不像LSA那么heavy,而是利用目标函数上的技巧来优化计算。
Glove的目标函数是
J = ∑ i , j N f ( X i , j ) ( v i T v j + b i + b j − l o g ( X i , j ) ) 2 J=\sum_{i,j}^Nf(X_{i,j})(v_i^Tv_j+b_i+b_j-log(X_{i,j}))^2 J=i,j∑Nf(Xi,j)(viTvj+bi+bj−log(Xi,j))2
其中f(x)是权重
f ( x ) = ( x / x m a x ) 0.75 , 当 x < x m a x f ( x ) = 1 , 当 x > = x m a x f(x)=(x/xmax)^{0.75}, 当x<xmax\\ f(x)=1, 当x>=xmax f(x)=(x/xmax)0.75,当x<xmaxf(x)=1,当x>=xmax
训练采用了AdaGrad的梯度下降算法,对矩阵X中的所有非零元素进行随机采样,学习曲率(learning rate)设为0.05,在vector size小于300的情况下迭代了50次,其他大小的vectors上迭代了100次,直至收敛。
这个目标函数的脑洞是这样的,两个词向量的乘积 v i T v j v_i^Tv_j viTvj是和 P i , j P_{i,j} Pi,j正相关的,其中 P i , j P_{i,j} Pi,j表示两个词共现的概率。那么
P i , j = X i , j X i = X i , j X i P_{i,j} = \frac{X_{i,j}}{X_i}=\frac{X_{i,j}}{X_i} Pi,j=XiXi,j=XiXi,j
同时希望满足以下除法的关系,因此需要加一下Log: P i , j = X i , k X j , k P_{i,j} = \frac{X_{i,k}}{X_{j,k}} Pi,j=Xj,kXi,k
那么的可以得到
l o g ( P i , j ) = v i T v j l o g ( X i , j ) − l o g ( X i ) = v i T v j l o g ( X i , j ) = v i T v j + b i + b j J = ∑ i , j N f ( X i , j ) ( v i T v j + b i + b j − l o g ( X i , j ) ) 2 log(P_{i,j})=v_i^Tv_j \\ log(X_{i,j})-log(X_{i})=v_i^Tv_j \\ log(X_{i,j}) =v_i^Tv_j+b_i+b_j \\ J=\sum_{i,j}^Nf(X_{i,j})(v_i^Tv_j+b_i+b_j-log(X_{i,j}))^2 log(Pi,j)=viTvjlog(Xi,j)−log(Xi)=viTvjlog(Xi,j)=viTvj+bi+bjJ=i,j∑Nf(Xi,j)(viTvj+bi+bj−log(Xi,j))2
详细目标函数的脑洞和推导可以参考:https://blog.csdn.net/coderTC/article/details/73864097和http://www.fanyeong.com/2018/02/19/glove-in-detail/
各种比较
以下转自知乎:https://zhuanlan.zhihu.com/p/57153934
1、word2vec和tf-idf 相似度计算时的区别?
word2vec 1、稠密的 低维度的 2、表达出相似度; 3、表达能力强;4、泛化能力强;
2、word2vec和NNLM对比有什么区别?(word2vec vs NNLM)
1)其本质都可以看作是语言模型;
2)词向量只不过NNLM一个产物,word2vec虽然其本质也是语言模型,但是其专注于词向量本身,因此做了许多优化来提高计算效率:
与NNLM相比,词向量直接sum,不再拼接,并舍弃隐层;
考虑到sofmax归一化需要遍历整个词汇表,采用hierarchical softmax 和negative sampling进行优化,hierarchical softmax 实质上生成一颗带权路径最小的哈夫曼树,让高频词搜索路劲变小;negative sampling更为直接,实质上对每一个样本中每一个词都进行负例采样;
3、 word2vec负采样有什么作用?
负采样这个点引入word2vec非常巧妙,两个作用,1.加速了模型计算,2.保证了模型训练的效果,一个是模型每次只需要更新采样的词的权重,不用更新所有的权重,那样会很慢,第二,中心词其实只跟它周围的词有关系,位置离着很远的词没有关系,也没必要同时训练更新,作者这点非常聪明。
4、word2vec和fastText对比有什么区别?(word2vec vs fastText)
1)都可以无监督学习词向量, fastText训练词向量时会考虑subword;
2)fastText还可以进行有监督学习进行文本分类,其主要特点:
结构与CBOW类似,但学习目标是人工标注的分类结果;
采用hierarchical softmax对输出的分类标签建立哈夫曼树,样本中标签多的类别被分配短的搜寻路径;
引入N-gram,考虑词序特征;
引入subword来处理长词,处理未登陆词问题;
5、glove和word2vec、 LSA对比有什么区别?(word2vec vs glove vs LSA)
1)glove vs LSA
LSA(Latent Semantic Analysis)可以基于co-occurance matrix构建词向量,实质上是基于全局语料采用SVD进行矩阵分解,然而SVD计算复杂度高;
glove可看作是对LSA一种优化的高效矩阵分解算法,采用Adagrad对最小平方损失进行优化;
2)word2vec vs LSA
主题模型和词嵌入两类方法最大的不同在于模型本身。
主题模型是一种基于概率图模型的生成式模型。其似然函数可以写为若干条件概率连乘的形式,其中包含需要推测的隐含变量(即主题)
词嵌入模型一般表示为神经网络的形式,似然函数定义在网络的输出之上。需要学习网络的权重来得到单词的稠密向量表示。
3)word2vec vs glove
word2vec是局部语料库训练的,其特征提取是基于滑窗的;而glove的滑窗是为了构建co-occurance matrix,是基于全局语料的,可见glove需要事先统计共现概率;因此,word2vec可以进行在线学习,glove则需要统计固定语料信息。
word2vec是无监督学习,同样由于不需要人工标注;glove通常被认为是无监督学习,但实际上glove还是有label的,即共现次数[公式]。
word2vec损失函数实质上是带权重的交叉熵,权重固定;glove的损失函数是最小平方损失函数,权重可以做映射变换。
总体来看,glove可以被看作是更换了目标函数和权重函数的全局word2vec。
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线