OpenAI的人工智能语音识别模型Whisper详解及使用_ai虚拟老师语音识别-程序员宅基地
技术标签: 音视频处理 深度学习 pytorch whisper AI数字人技术 语音识别
1 whisper介绍
拥有ChatGPT语言模型的OpenAI公司,开源了 Whisper 自动语音识别系统,OpenAI 强调 Whisper 的语音识别能力已达到人类水准。
Whisper是一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练,能够在英语语音识别上达到接近人类水平的鲁棒性和准确性。Whisper还可以进行多语言语音识别、语音翻译和语言识别等任务。Whisper的架构是一个简单的端到端方法,采用了编码器-解码器的Transformer模型,将输入的音频转换为对应的文本序列,并根据特殊的标记来指定不同的任务。
Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。OpenAI 开放模型和推理代码,希望开发者可以将 Whisper 作为建立有用的应用程序和进一步研究语音处理技术的基础。
代码地址:代码地址
2 whisper模型
2.1 使用数据集
Whisper模型是在68万小时标记音频数据的数据集上训练的,其中包括11.7万小时96种不同语言的演讲和12.5万小时从”任意语言“到英语的翻译数据。该模型利用了互联网生成的文本,这些文本是由其他自动语音识别系统(ASR)生成而不是人类创建的。该数据集还包括一个在VoxLingua107上训练的语言检测器,这是从YouTube视频中提取的短语音片段的集合,并根据视频标题和描述的语言进行标记,并带有额外的步骤来去除误报。
2.2 模型
主要采用的结构是编码器-解码器结构。
重采样:16000 Hz
特征提取方法:使用25毫秒的窗口和10毫秒的步幅计算80通道的log Mel谱图表示。
特征归一化:输入在全局内缩放到-1到1之间,并且在预训练数据集上具有近似为零的平均值。
编码器/解码器:该模型的编码器和解码器采用Transformers。
- 编码器的过程
编码器首先使用一个包含两个卷积层(滤波器宽度为3)的词干处理输入表示,使用GELU激活函数。
第二个卷积层的步幅为 2。
然后将正弦位置嵌入添加到词干的输出中,然后应用编码器 Transformer 块。
Transformers使用预激活残差块,编码器的输出使用归一化层进行归一化。
- 模型结构
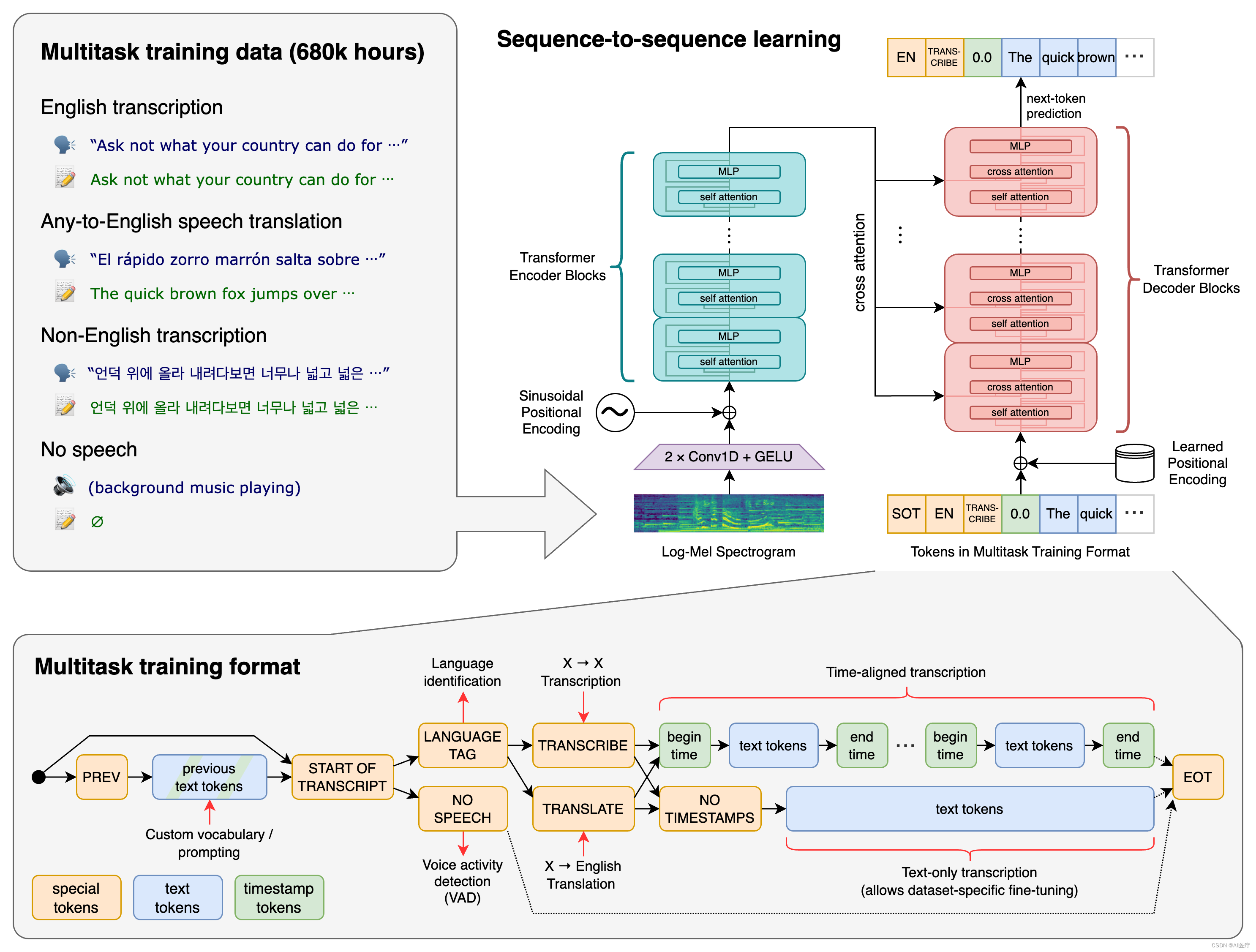
- 解码的过程
在解码器中,使用了学习位置嵌入和绑定输入输出标记表示。
编码器和解码器具有相同的宽度和数量的Transformers块。
2.3 训练
输入的音频被分割成 30 秒的小段、转换为 log-Mel 频谱图,然后传递到编码器。解码器经过训练以预测相应的文字说明,并与特殊的标记进行混合,这些标记指导单一模型执行诸如语言识别、短语级别的时间戳、多语言语音转录和语音翻译等任务。
相比目前市面上的其他现有方法,它们通常使用较小的、更紧密配对的「音频 - 文本」训练数据集,或使用广泛但无监督的音频预训练集。因为 Whisper 是在一个大型和多样化的数据集上训练的,而没有针对任何特定的数据集进行微调,虽然它没有击败专攻 LibriSpeech 性能的模型(著名的语音识别基准测试),然而在许多不同的数据集上测量 Whisper 的 Zero-shot(不需要对新数据集重新训练,就能得到很好的结果)性能时,研究人员发现它比那些模型要稳健得多,犯的错误要少 50%。
为了改进模型的缩放属性,它在不同的输入大小上进行了训练。
- 通过 FP16、动态损失缩放,并采用数据并行来训练模型。
- 使用AdamW和梯度范数裁剪,在对前 2048 次更新进行预热后,线性学习率衰减为零。
- 使用 256 个批大小,并训练模型进行 220次更新,这相当于对数据集进行两到三次前向传递。
由于模型只训练了几个轮次,过拟合不是一个重要问题,并且没有使用数据增强或正则化技术。这反而可以依靠大型数据集内的多样性来促进泛化和鲁棒性。
Whisper 在之前使用过的数据集上展示了良好的准确性,并且已经针对其他最先进的模型进行了测试。
2.4 优点
-
Whisper 已经在真实数据以及其他模型上使用的数据以及弱监督下进行了训练。
-
模型的准确性针对人类听众进行了测试并评估其性能。
-
它能够检测清音区域并应用 NLP 技术在转录本中正确进行标点符号的输入。
-
模型是可扩展的,允许从音频信号中提取转录本,而无需将视频分成块或批次,从而降低了漏音的风险。
-
模型在各种数据集上取得了更高的准确率。
Whisper在不同数据集上的对比结果,相比wav2vec取得了目前最低的词错误率
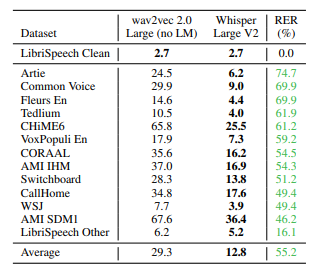
模型没有在timit数据集上进行测试,所以为了检查它的单词错误率,我们将在这里演示如何使用Whisper来自行验证timit数据集,也就是说使用Whisper来搭建我们自己的语音识别应用。
2.5 whisper的多种尺寸模型
whisper有五种模型尺寸,提供速度和准确性的平衡,其中English-only模型提供了四种选择。下面是可用模型的名称、大致内存需求和相对速度。

模型的官方下载地址:
"tiny.en": "https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt",
"tiny": "https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt",
"base.en": "https://openaipublic.azureedge.net/main/whisper/models/25a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead/base.en.pt",
"base": "https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt",
"small.en": "https://openaipublic.azureedge.net/main/whisper/models/f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872/small.en.pt",
"small": "https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt",
"medium.en": "https://openaipublic.azureedge.net/main/whisper/models/d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f/medium.en.pt",
"medium": "https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt",
"large-v1": "https://openaipublic.azureedge.net/main/whisper/models/e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a/large-v1.pt",
"large-v2": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",
"large": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",3 whisper环境构建及运行
3.1 conda环境安装
参见:annoconda安装
3.2 whisper环境构建
conda create -n whisper python==3.9
conda activate whisper
pip install openai-whisper
conda install ffmpeg
pip install setuptools-rust3.3 whisper命令行使用
whisper /opt/000001.wav --model base输出内容如下:
[00:00.000 --> 00:02.560] 人工智能识别系统。执行命令时,会自动进行模型下载,自动下载模型存储的路径如下:
~/.cache/whisper也可以通过命令行制定本地模型运行:
Whisper /opt/000001.wav --model base --model_dir /opt/models --language Chinese支持的文件格式:m4a、mp3、mp4、mpeg、mpga、wav、webm
3.4 whisper在代码中使用
import whisper
model = whisper.load_model("base")
result = model.transcribe("/opt/000001.wav")
print(result["text"])智能推荐
机器学习模型评分总结(sklearn)_model.score-程序员宅基地
文章浏览阅读1.5w次,点赞10次,收藏129次。文章目录目录模型评估评价指标1.分类评价指标acc、recall、F1、混淆矩阵、分类综合报告1.准确率方式一:accuracy_score方式二:metrics2.召回率3.F1分数4.混淆矩阵5.分类报告6.kappa scoreROC1.ROC计算2.ROC曲线3.具体实例2.回归评价指标3.聚类评价指标1.Adjusted Rand index 调整兰德系数2.Mutual Informa..._model.score
Apache虚拟主机配置mod_jk_apache mod_jk 虚拟-程序员宅基地
文章浏览阅读344次。因工作需要,在Apache上使用,重新学习配置mod_jk1. 分别安装Apache和Tomcat:2. 编辑httpd-vhosts.conf: LoadModule jk_module modules/mod_jk.so #加载mod_jk模块 JkWorkersFile conf/workers.properties #添加worker信息 JkLogFil_apache mod_jk 虚拟
Android ConstraintLayout2.0 过度动画MotionLayout MotionScene3_android onoffsetchanged-程序员宅基地
文章浏览阅读335次。待老夫kotlin大成,扩展:MotionLayout 与 CoordinatorLayout,DrawerLayout,ViewPager 的 交互众所周知,MotionLayout 的 动画是有完成度的 即Progress ,他在0-1之间变化,一.CoordinatorLayout 与AppBarLayout 交互时,其实就是监听 offsetliner 这个 偏移量的变化 同样..._android onoffsetchanged
【转】多核处理器的工作原理及优缺点_多核处理器怎么工作-程序员宅基地
文章浏览阅读8.3k次,点赞3次,收藏19次。【转】多核处理器的工作原理及优缺点《处理器关于多核概念与区别 多核处理器工作原理及优缺点》原文传送门 摘要:目前关于处理器的单核、双核和多核已经得到了普遍的运用,今天我们主要说说关于多核处理器的一些相关概念,它的工作与那里以及优缺点而展开的分析。1、多核处理器 多核处理器是指在一枚处理器中集成两个或多个完整的计算引擎(内核),此时处理器能支持系统总线上的多个处理器,由总..._多核处理器怎么工作
个人小结---eclipse/myeclipse配置lombok_eclispe每次运行个新项目都需要重新配置lombok吗-程序员宅基地
文章浏览阅读306次。1. eclipse配置lombok 拷贝lombok.jar到eclipse.ini同级文件夹下,编辑eclipse.ini文件,添加: -javaagent:lombok.jar2. myeclipse配置lombok myeclipse像eclipse配置后,定义对象后,直接访问方法,可能会出现飘红的报错。 如果出现报错,可按照以下方式解决。 ..._eclispe每次运行个新项目都需要重新配置lombok吗
【最新实用版】Python批量将pdf文本提取并存储到txt文件中_python批量读取文字并批量保存-程序员宅基地
文章浏览阅读1.2w次,点赞31次,收藏126次。#注意:笔者在2021/11/11当天调试过这个代码是可用的,由于pdfminer版本的更新,网络上大多数的语法没有更新,我也是找了好久的文章才修正了我的代码,仅供学习参考。1、把pdf文件移动到本代码文件的同一个目录下,笔者是在pycharm里面运行的项目,下图中的x1文件夹存储了我需要转换成文本文件的所有pdf文件。然后要在此目录下创建一个存放转换后的txt文件的文件夹,如图中的txt文件夹。2、编写代码 (1)导入所需库# coding:utf-8import ..._python批量读取文字并批量保存
随便推点
Scala:访问修饰符、运算符和循环_scala ===运算符-程序员宅基地
文章浏览阅读1.4k次。http://blog.csdn.net/pipisorry/article/details/52902234Scala 访问修饰符Scala 访问修饰符基本和Java的一样,分别有:private,protected,public。如果没有指定访问修饰符符,默认情况下,Scala对象的访问级别都是 public。Scala 中的 private 限定符,比 Java 更严格,在嵌套类情况下,外层_scala ===运算符
MySQL导出ER图为图片或PDF_数据库怎么导出er图-程序员宅基地
文章浏览阅读2.6k次,点赞7次,收藏19次。ER图导出为PDF或图片格式_数据库怎么导出er图
oracle触发器修改同一张表,oracle触发器中对同一张表进行更新再查询时,需加自制事务...-程序员宅基地
文章浏览阅读655次。CREATE OR REPLACE TRIGGER Trg_ReimFactBEFORE UPDATEON BP_OrderFOR EACH ROWDECLAREPRAGMA AUTONOMOUS_TRANSACTION;--自制事务fc varchar2(255);BEGINIF ( :NEW.orderstate = 2AND :NEW.TransState = 1 ) THENBEG..._oracle触发器更新同一张表
debounce与throttle区别及其应用场景_throttle和debounce应用在哪些场景-程序员宅基地
文章浏览阅读513次。目录概念debouncethrottle实现debouncethrottle应用场景debouncethrottle场景举例debouncethrottle概念debounce字面理解是“防抖”,何谓“防抖”,就是连续操作结束后再执行,以网页滚动为例,debounce要等到用户停止滚动后才执行,将连续多次执行合并为一次执行。throttle字面理解是“节流”,何谓“节流”,就是确保一段时..._throttle和debounce应用在哪些场景
java操作mongdb【超详细】_java 操作mongodb-程序员宅基地
文章浏览阅读526次。regex() $regex 正则表达式用于模式匹配,基本上是用于文档中的发现字符串 (下面有例子)注意:若未加 @Field("名称") ,则识别mongdb集合中的key名为实体类属性名。也可以对数组进行索引,如果被索引的列是数组时,MongoDB会索引这个数组中的每一个元素。也可以对整个Document进行索引,排序是预定义的按插入BSON数据的先后升序排列。save: 若新增数据的主键已经存在,则会对当前已经存在的数据进行修改操作。_java 操作mongodb
github push 推送代码失败. 使用ssh rsa key. remote: Support for password authentication was removed._git push remote: support for password authenticati-程序员宅基地
文章浏览阅读1k次。今天push代码到github仓库时出现这个报错TACKCHEN-MB0:tc-image tackchen$ git pushremote: Support for password authentication was removed on August 13, 2021. Please use a personal access token instead.remote: Please see https://github.blog/2020-12-15-token-authentication_git push remote: support for password authentication was removed on august 1