Elasticsearch介绍及如何使用_elasticsearch match_phrase_prefix-程序员宅基地
技术标签: elasticsearch
是什么
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念:
- 节点(Node):
一个节点是一个单一的服务器,是你的集群的一部分,存储数据,并且参与集群的索引和搜索功能。
一个节点可以通过配置特定的集群名称来加入特定的集群。默认情况下,每个节点被设定加入一个名称为 “elasticsearch” 的集群,这意味着如果你在你的网络中启动了一些节点,并且假设它们能相互发现,它们将会自动组织并加入一个名称是 “elasticsearch” 的集群。 - 索引(Index):
可以近似的理解SQL中的数据库,虽然官方文档上说这是不好的。可以包涵表和数据。 - 类型(Type):(警告!Type在6.0.0版本中已经不赞成使用):
可以近似的理解成是SQL中的表,里面会包涵许多数据 - 文档(Document):
可以近似的理解是SQL中的表里的每一条数据。
去哪下:
官网下载传送
官网下载window版(我的是6.6.1版本)。
双击运行bin目录下的 elasticsearch.bat
怎么玩:
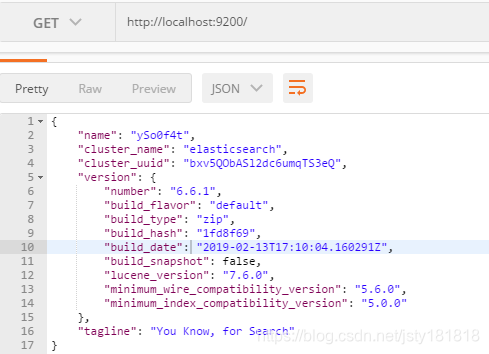
看到这个结果,说明安装,启动成功。
- 列出所有的索引:(GET)
http://localhost:9200/_cat/indices?v
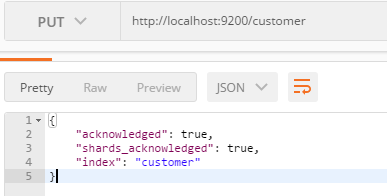
- 创建一个索引:(PUT)
http://localhost:9200/customer
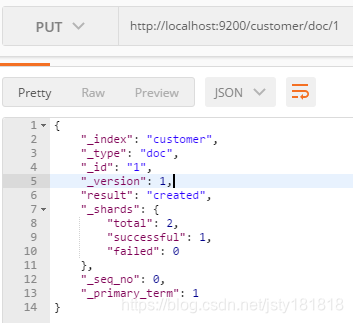
- 向索引中添加文档(PUT)
http://localhost:9200/customer/doc/1
//其中doc是类型。
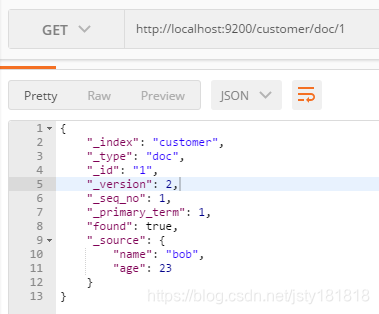
- 获取刚刚加入索引的文档:(GET)
http://localhost:9200/customer/doc/1
- 删除一个索引:(DELETE)
http://localhost:9200/customer
- 更新文档(POST)
除了能够新增和替换文档,我们也可以更新文档。注意虽然 Elasticsearch 在底层并没有真正更新文档,而是当我们更新文档时,Elasticsearch 首先去删除旧的文档,然后加入新的文档。
http://localhost:9200/customer/doc/1/_update?pretty
{
"doc": { "name": "Jane Doe" }
}
更新操作也可以使用简单的脚本来执行。如下的示例使用一个脚本将age增加了5:
http://localhost:9200/customer/doc/1/_update?pretty
{
"script" : "ctx._source.age += 5"
}
- 删除文档(DELETE):
http://localhost:9200/customer/doc/2?pretty
推荐使用Kibana进行数据查询
搜索:
- _mget(批量获取文档)
类似sql中的 id in(1,2,3)这样。
GET _mget
{
"docs":[
{
"_index": "bank",
"_type": "account",
"_id": "1",
"_source": ["balance", "city"]
},
{
"_index": "bank",
"_type": "account",
"_id": "5",
"_source": "firstname"
}
]
}
也可以简写:
GET /bank/account/_mget
{
"ids": ["1", "2", "4"]
}
-
_bulk(批量操作)
1.格式:
{action:{metadata}}
{requestbody}
其中action(行为)可以取值:
1.create:文档不存在时创建
2.update:更新文档
3.index:创建新文档或覆盖已有文档
4.delete:删除一个文档
create和index的区别:如果数据存在,使用create操作失败,会提示文档以存在,使用index可以成功执行。
如果使用create创建多个,其中有存在的,那么存在的返回失败,不存在的添加成功
其中metadata可以取值:
_index,_type,_id示例:
1.create:POST /bank/account/_bulk { "create":{ "_id":"999"}} { "account_number":999, "balance": 999} { "create":{ "_id":"1000"}} { "account_number":1000, "balance": 1000} { "create":{ "_id":"1001"}} { "account_number":1001, "balance": 1001}2.delete:
POST bank/account/_bulk { "delete":{ "_index":"bank", "_type":"account", "_id":"1000"}}3.update:
POST /bank/account/_bulk { "update":{ "_id":"1001"}} { "doc":{ "balance":"0"}} -
term:
用于查询指定字段包含某个词项的文档。这个查询不知道分词器的存在,所以搜索的值不会进行分词。只会拿搜索的值去倒排索引中找。
GET /bank/account/_search
{
"query":{
"term":{
"address":{
"value":"heath"
}
}
}
}
- match:
知道分词器的存在,所以搜索的值会被分词在去查询。
GET /bank/account/_search
{
"query":{
"match":{
"address":"511 Heath Place"
}
}
}
- multi_match:
可以指定多个字段,意思是:查找fields字段值的字段中包含query字段中对应的值
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
}
}
- match_phrase:
短语搜索,就是搜索含有指定的短语的数据。意思是搜索的值经过分词之后和es中分词保存的一致,顺序也一致,两头的可以少,中间的不可以少
GET /bank/account/_search
{
"query":{
"match_phrase":{
"address":"511 Heath Place"
}
}
}
- _source:
用来指定返回的字段:
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": ["firstname", "age"]
}
_可以写个数组来指定,也可以在 "source" 字段中加"includes"和"excludes"
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": {
"includes": ["age", "balance", "gen*"],
"excludes": ["gender"]
}
}
- sort:
用来排序,和关系型数据库的排序类似
GET /bank/account/_search
{
"query":{
"match_all":{
}
},
"sort":[
{
"balance":{
"order":"desc"
}
},
{
"age":{
"order":"asc"
}
}
]
}
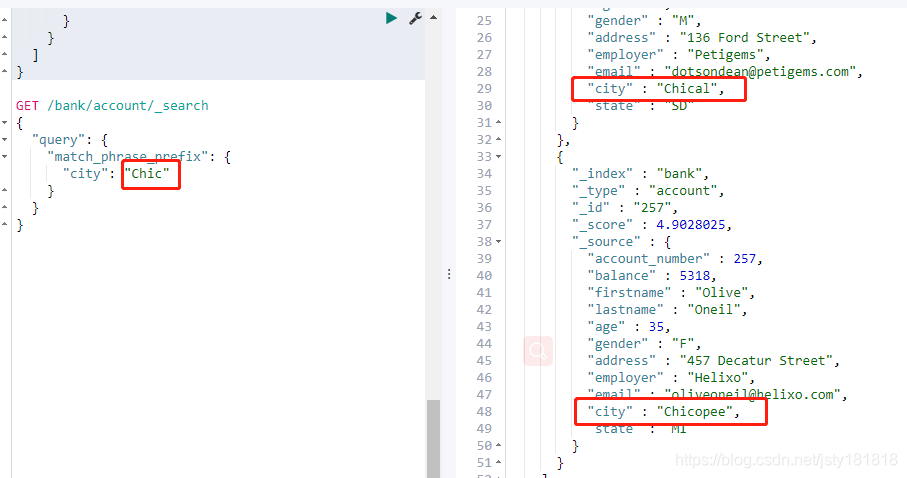
- match_phrase_prefix:
前缀匹配(查询的值不会分词,但是忽略大小写)
- range:
范围查询:
GET /bank/account/_search
{
"query":{
"range":{
"age":{
"gte": 20,
"lt": 30
}
}
}
}
- wildcard:
通配符匹配:
通配符:
* 代表任意多字符
? 代表一个字符
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
}
}
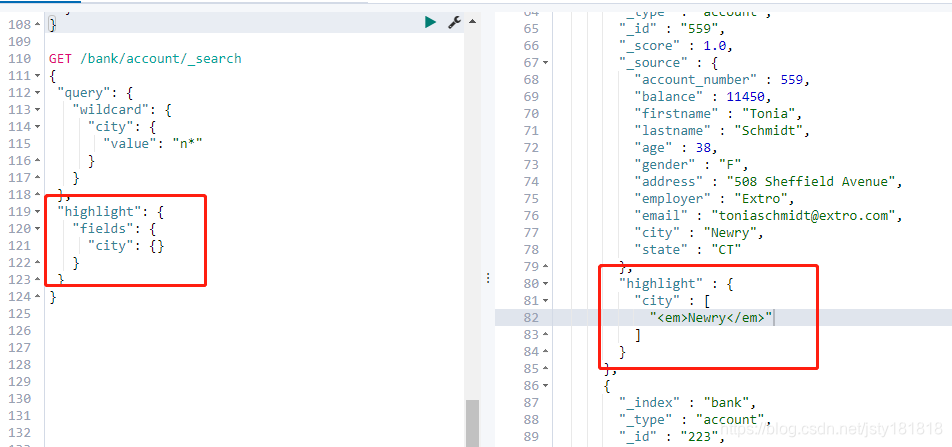
- highlight:
高亮显示:
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
},
"highlight":{
"fields":{
"city":{
}
}
}
}
- fuzzy:
模糊匹配,这个可不是mysql中的like,是可以错误的输入一些字 来进行匹配
GET /bank/account/_search
{
"query":{
"fuzzy":{
"city": "Nicho1so"
}
}
}
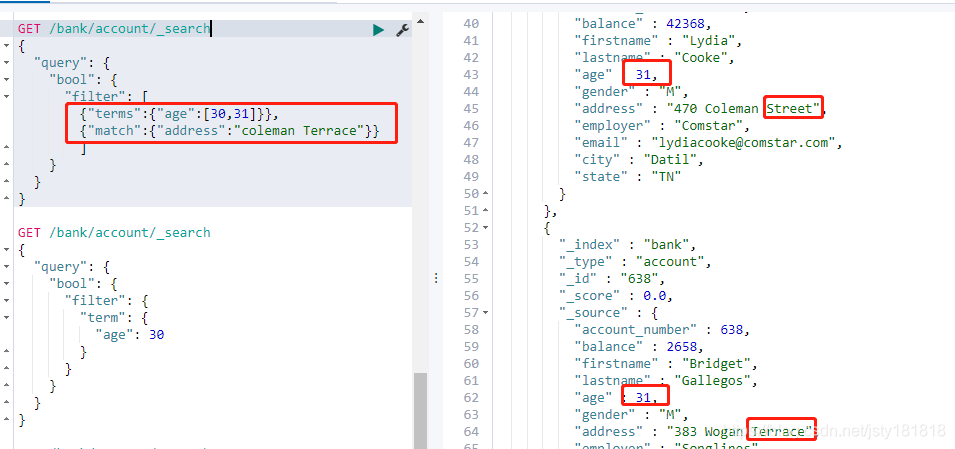
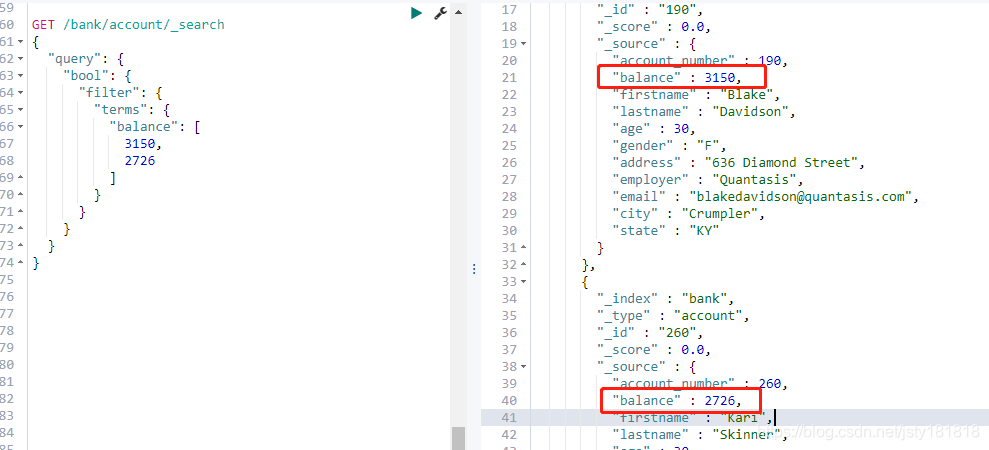
- filter查询:
过滤查询:
- must,should,must_not:
GET /bank/account/_search
{
"query":{
"bool":{
"must": [
{
"term":{
"age":{
"value" :20
}
}
}
]
}
}
}
- exists:
查询某个字段不为空
GET /bank/account/_search
{
"query":{
"bool":{
"filter": {
"exists":{
"field": "age"
}
}
}
}
}
- 聚合查询:
1.sum

智能推荐
Linux 文件压缩与解压相关-程序员宅基地
文章浏览阅读85次。tar [-cxtzjvfpPN] 文件与目录 ....参数:-c :建立一个压缩文件的参数指令-x :解开一个压缩文件的参数指令-t :查看压缩文件里面的文件特别注意: c/x/t 同时只能存在一个,原因是我们不可能同时压缩与解压缩。-z :是否同时具有 gzip 的属性?亦即是否需要用 gzip 压缩-j :是否同时具有 bzip2 的属性?亦即是否需要用 bzi...
memcpy 函数详解-程序员宅基地
文章浏览阅读9.1k次。原型:extern void *memcpy(void *dest, void *src, unsigned int count);用法:#include 功能:由src所指内存区域复制count个字节到dest所指内存区域。说明:src和dest所指内存区域不能重叠,函数返回指向dest的指针。举例: // memcpy._memcpy
微型计算机电路基础第四版逻辑门,数字逻辑的电路基础——逻辑门.PDF-程序员宅基地
文章浏览阅读219次。数字逻辑的电路基础——逻辑门课程代码第三讲数字逻辑的电路基础——逻辑门佟冬Microprocessor R&D Centertongdong@/courses/digital/2010fall 1课程回顾 布尔代数 6个公设 10个定理 用于开关函数的化简 开关函数(3种表示方法) 直值表 布尔表达式(SOP, POS) 最小范..._微型计算机电路基础(第4版)教案
SimpleAdmin手摸手教学之:请求代理-程序员宅基地
文章浏览阅读56次。在之前使用其他admin的时候,经常会有人再部署的时候会遇到这么一个问题:明明在生产环境中配置了后端的api地址,但是通过nginx部署之后,请求的确是本地的地址。这是因为在项目中配置了代理,部署之后所有的请求都走了代理导致配置文件地址失效,关于vite代理说明,请自行百度,针对这种情况,本系统通过开关的方式让开发者自行选择是否走代理。
BZOJ 4245: [ONTAK2015]OR-XOR-程序员宅基地
文章浏览阅读81次。要求or的值最大,从高位到低位贪心,高位尽量为0,所以要求优先满足高位每段的xor和都相等转化为前缀和就是选出0的个数能否>=m#include<cstdio>using namespace std;int vis[1000005];long long a[1000005],Sum[1000005];int main(){ int n,m; s..._[ontak2015] or-xor
蜂群算法与多目标优化的结合:实践经验与效果-程序员宅基地
文章浏览阅读864次,点赞21次,收藏21次。1.背景介绍蜂群算法(Particle Swarm Optimization, PSO)是一种基于自然界蜂群行为的优化算法,由阿德利·迪亚斯(Adelia Diana)和伊瑟尔·阿迪亚德(Eckhardt Adia)于2001年提出。蜂群算法是一种简单、高效的全局优化算法,主要应用于解决连续优化问题。然而,随着现实世界中的优化问题变得越来越复杂,单目标优化算法已经无法满足需求。多目标优化问题是..._多蜂群优化算法
随便推点
遍历,toArray()_哪些数据结构可以使用toarray()-程序员宅基地
文章浏览阅读269次。任何数据结构,能够遍历,就能放到一个数组里,即toArray()。放在数组里,有利于操作,可以同时读取前面或后面的数据,而在其他数据结构里,则不是那么容易的,例如树_哪些数据结构可以使用toarray()
手机usb计算机连接不能选择,USB调试 是灰色按钮,无法点击,现在手机无法与电脑连接。...-程序员宅基地
文章浏览阅读9.6k次。USB调试 是灰色按钮,无法点击,现在手机无法与电脑连接。以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!USB调试 是灰色按钮,无法点击,现在手机无法与电脑连接。你好!首先你要先打开开发者选项(最上面)才可以再打开USB调试三星手机WLAN连接按钮是灰色,无法点击手机重启试试。如果依旧不能点击打开,就把手机恢复出厂设置..._usb计算机连接无法选择
我所理解的Android模块化(一)——模块化概念和路由_安卓模块那个是子模块和父模块-程序员宅基地
文章浏览阅读1.2w次,点赞13次,收藏84次。笔者在公司的项目中使用模块化的方式开发APP已经快一年的时间,其中经历过以模块化的方式来重构项目中一些相对来说业务比较独立的模块。遇到了一些问题,也积累了一些经验,所以想谈一谈我对Android模块化的理解,也希望能帮助到大家。_安卓模块那个是子模块和父模块
深度学习实战14(进阶版)-手写文字OCR识别,手写笔记也可以识别了_ocr.recognize_text-程序员宅基地
文章浏览阅读3.2k次,点赞2次,收藏20次。大家好,我是微学AI,今天给大家带来手写OCR识别的项目。手写的文稿在日常生活中较为常见,比如笔记、会议记录,合同签名、手写书信等,手写体的文字到处都有,所以针对手写体识别也是有较大的需求。_ocr.recognize_text
存储器的层次结构-程序员宅基地
文章浏览阅读1.5w次,点赞5次,收藏66次。文章目录存储器的层次结构1.存储器的多层结构2.多层结构的存储器系统3.程序的装入和链接(1) 程序的装入(2)程序的链接存储器的层次结构1.存储器的多层结构对于通用计算机而言,存储层次至少应具有三级:最高层为CPU寄存器,中间为主存,最底层是辅存。在较高档的计算机中,还可以根据具体的功能细分为寄存器、高速缓存、主存储器、磁盘缓存、固定磁盘、可移动存储介质等6层。如下图所示。2.多层结构..._存储器的层次结构
AJAX请求 状态pending_http请求 pending-程序员宅基地
文章浏览阅读4.3k次。一、pending 是什么意思?定义:信号产生和传递之间的时间间隔内,称此信号是未决的;简单的说就是:一个已经产生的信号,但是还没有传递给任何进程,此时该信号的状态就称为未决状态。二、HTTP Status pending 相关状态还包括哪些?1、待定状态;2、未决状态;3、等待状态;4、检验状态三、出现“pending”如何解决?通过上面讲了“pending 是什么意思?”你应该能明白一个大概的意思了吧,也有了一个大概的解决思路了吧。绝大多数情况都是因为..._http请求 pending