8连接路径_path("keys")-程序员宅基地
技术标签: p优深
文章目录
- 动态规划推进到join_ search_one_ level
- 遗传算法推进到merge clump
- 物理优化的部分从这两个函数开始就进入到建立连接路径的阶段
-
连接路径指的是物理连接路径,也就是通过这种路径来实现逻辑连接操作
-
建立连接路径的过程就是不断地尝试生成这3种路径的过程。
- 相同的两个基表(Reloptlnfo)建立连接关系
- 它们采用的物理路径不同,对应的路径的代价也就不同
- 因此在建立连接路径的过程中,需不断尝试对路径筛选
- 尽早地淘汰掉一些差路径
8.1检查
- 动规中需将N-1层的每个Reloptlnfo和第1层的每个 Reloptlnfo尝试连接,产生的新的Reloptlnfo保存到第N层
- 但在两个Reloptlnfo做连接时,有些是明显不适合做连接的,
- 可 通过检查的方式避开在这些Reloptlnfo间做连接,
- 可通过增加剪枝函数来避免无效搜索
- SQL中会通过逻辑连接操作符和约束条件来指定两个表之间的逻辑连接关系,约束条件能过滤连接结果,
- 因此如果两个表上有约束条件,那就可尝试优先对这两个表先做连接,就能保证有约束条件的表在查询计划的下层,能尽早过滤数据,减少査询计划上层节点的计算量
- 两个表可能会有连接顺序的限制
- SQL中指定Lateral语义就能导致两个表的连接有先有后,
- 建立物理连接路径的时候也必须考虑这种先后
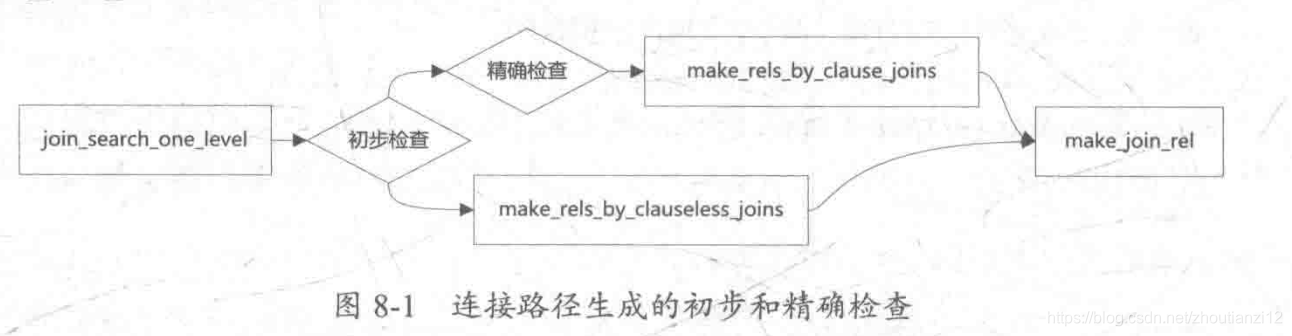
8.1.1初步检查
- join_search_one_level中,对第N-1层的(也就是join_search_one_leve中的level-1层)每个Reloptlnfo初步分析,如果满足之一
- Reloptlnfo->joininfo不NULL
- Reloptlnfo->has_eclass_joins是true
- 在等价类的记录中有当前Reloptinfo和其他Reloptlnfo可能存在等值连接条件
- has_join_restriction是true
- 当前Reloptlnfo和其他Reloptlnf有连接顺序限制
- 那这个Reloptlnfo和第1层的Reloptlnfo做连接时就进入 make rels_by clause_joins,否则_make rels_by causeless_joins
- 基于连接条件来建立连接路径的
- 是在没有连接条件的情况下生成基于卡氏积的连接路径
- has_join_restriction
- 第N-1层的这个Rel是否和其他Rel有连接顺序限制

- 初步检查只基于单个Rel的判断
- 是一种“可能性”的判断
- 基于当前的Rel判断它是否和其他Rel有连接条件或者连接顺序限制,有了这种可能性时,就进入精确检查
8.1.2精确检查
- 这个Rel和其他Rel无连接条件或顺序限制
- make_rels_by_causeless_joins
- 将当前Rel和第1层所有Rel连接
- 当前Rel和其他Rel有“可能”有连接条件或顺序限制
- make_rels_by_clause_joins
- 第1层所有Rel中筛选出真正和当前Rel有连接条件或顺序限制的Rel
/*
* have_relevant_joinclause
* Detect whether there is a joinclause that involves
* the two given relations.
*
* Note: the joinclause does not have to be evaluable with only these two
* relations. This is intentional. For example consider
* SELECT * FROM a, b, c WHERE a.x = (b.y + c.z)
* If a is much larger than the other tables, it may be worthwhile to
* cross-join b and c and then use an inner indexscan on a.x. Therefore
* we should consider this joinclause as reason to join b to c, even though
* it can't be applied at that join step.
*/
bool
have_relevant_joinclause(PlannerInfo *root,
RelOptInfo *rel1, RelOptInfo *rel2)
{
bool result = false;
List *joininfo;
Relids other_relids;
ListCell *l;
/*
* We could scan either relation's joininfo list; may as well use the
* shorter one.
*/
if (list_length(rel1->joininfo) <= list_length(rel2->joininfo))
{
joininfo = rel1->joininfo;
other_relids = rel2->relids;
}
else
{
joininfo = rel2->joininfo;
other_relids = rel1->relids;
}
foreach(l, joininfo)
{
RestrictInfo *rinfo = (RestrictInfo *) lfirst(l);
if (bms_overlap(other_relids, rinfo->required_relids))
{
result = true;
break;
}
}
/*
* We also need to check the EquivalenceClass data structure, which might
* contain relationships not emitted into the joininfo lists.
*/
if (!result && rel1->has_eclass_joins && rel2->has_eclass_joins)
result = have_relevant_eclass_joinclause(root, rel1, rel2);
return result;
}
- have_relevant_joinclause筛选有连接条件的Reloptlnfo
- have_join_order_restriction判断两个Rel是否有连接顺序限制,判断两个Rel间真实关系
- 这两个,就从初步筛选的“对一个Rel初判断”过渡到
- “对两个Rel精确判断”
-
have_relevant_joinclause判断依据
-
Reloptlnfo->joininfo记录一部分连接条件(a>b)
- 如果一个Reloptlnfo->joininfo中的连接条件也引用另一个Rel,这两个Reloptlnfo有连接条件
-
等价类中记录SQL中显式指定的等值约束
- 基于等价类中的等价成员推理获得新的等值连接条件
- 两个Rel的relids在同一个等价类
- have_join_order_restriction总和have_relevant joinclause成对出现,在进入have_join_order_restriction时候隐含一个条件,那就是在两表之间可能没有相关的连接条件,
- have_relevant_joinclause是falseオ进入have_join order_restriction
- have_join_order_restriction和has_join_restriction相似,都从三方面来判断是否有连接顺序限制
- 两个Rel间是否存在 Lateral顺序的限制
- 两个Rel是否包含 Placeholder Var变量。
- Specialjoininfo中的 min lefthand和 min righthand是否对两个 Reloptlnfo(也就是relids)有连接顺序限制。
- 对have_join_order_restriction分析如下:


- 两个Rel无论是有连接条件或是连接顺序限制,还是没有连接条件,它们最终都要调make_join_rel来生成连接路径
8.1.3“合法”连接
- make_join_rel生成它们的上一层的父Rel,
- 并将物理连接路径保存在父Rel中成员变量
- 在确定level-1层的表和第1层的所有表都无约束条件时
- 只能让 level-1层的表和第1层的表依次生成笛卡儿积,
- 如果level-1层的表和第1层的某个表有连接条件
- 排除和第1层没有连接条件的表
- 能裁减掉很多不必要的连接路径
- 两个待选的Rel,这两个Rel可能Inner、 Left、 Semi,
- 或这两个Rel间就没有合法的逻辑连接,这时就要确定它们的逻辑连接,做连接关系合法性的检查,分两步
- 步骤1:对Plannerlnfo->join_info_list中的 Specialjoininfo遍历,是否能找到一个“合法”的 Specialjoininfo,因为除Inner外的其他逻辑连接关系都会对应生成一个Specialjoinlnfo,且Specialjoininfo中还记录了合法的连接顺序
- 步骤2:对Rel中的Lateral排查,查看Specialjoinlnfo是否符合Lateral语义指定的连接顺序要求
- 如果Plannerlnfo->join_info_list中找到合法的 Specialjoinlnfo,这个Specialjoinlnfo也符合Lateral的要求,就可将这个Specialjoinlnfo作为两个Rel连接操作的依据,为其生成父连接路径,
- 内连接不记录在join_info_list,
- 在判断连接合法性的时候要考虑到内连接
8.1.3.1合法的连接关系
- 步骤1的实现
- join info list中目前有4种连接
- Left、 Full、 Semi和 Anti,
- 步骤1通过Specialjoininfo中的最小集合( min lefthand和 min righthand)判断两个Rel间关系


- 对Semijoin的Specialjoinlnfo,尝试对其进行唯一化处理
- 在RHS中找到一个符合连接条件的数据即可,不需要把RHS中符合连接条件的数据全部都找出来,
- 因此可以将RHS中的数据“去重”,这样也不影响执行结果
8.3虚表
- 准备好Reloptlnfo和合法的Specialjoininfo,就可向准备好的 Reloptlnfo中增加物理连接路径,路径的生成在populate_joinrel_with_paths中实现,它根Specialjoininfo中指定的逻辑连接类型调用 add paths to joinrel I函数来添加物理连接路径。
- 添加路径前,判断一下在两个Rel中是否有执行结果一定为空的表,
- 一个Rel的约束条件为常量false,
- 它最终的执行结果一定是空集,
- 称这种类型的 Rel为“虚表”,
- 对不同的连接类型,虚表和其他Rel的连接结果可能还是一个虚表

- restriction_is_constant_false的2参only_pushed_down代表针对哪些约束条件检査
- 外连接下, true:只针对能下推的过滤条件(参考4章约束条件下推的内容)做检查,因为即使在连接条件是常量false,连接结果可能并不是一个虚表,
- 外连接中,对不满足连接条件的Nonnullable-side的元组仍然会被显示,且在Nullable-side中补充NUL值,
- 如果要判断两个 Rel连接的结果是虚表,
- 则要对可以下推的约束条件也就是过滤条件判断

- 连接条件没对 TEST_A LEFT JOIN TEST_B起作用
- 但对Nullable-side的 TEST B起到作用,
- 对TEST B表的扫描变成了虚表(虚表路径在生成执行计划时会建立基于One-Time Filter的Result节点)
- 从外连接看出,在ON FALSE时,也就是Nonnullable-side没有和 Nullable-side匹配的元组,这和Nullable-side是虚表的效果是一样
- 无论是过滤还是连接条件,只要有常量false约束,外连接 Nullable–side的表就可修正为虚表,这里的Nullable-side的判断使用了 Specialjoininfo-> syn righthand而不是 Specialjoininfo-> min righthand,因为我们记录min righthand的目的是保证连接顺序的正确性,而syn righthand的目的是记录语句中原始的逻辑连接关系,只要有约束条件是常量 false,那对一个连接操作而言,它会作用到整个连接上,而不一定是连接的“最小集( min righthand)”上
- add_paths_to_joinrel中,
- Inner 、 Left 、 Ful 尝试交换两个Rel位置来尝试更多的可能路径
- 逻辑优化阶段做外连接消除时,
- 将所有的 Right通过交换连接表位置的方式都转换成了 Left ,因此在之后很长时间内我们只处理 Left ,
- 但到了 populate_ joinrel with paths之后,
- Right Join又“回来了”。
8.4 Semi Join和唯一化路径
- join_is_legal中
- 将SemiJoin内表唯一化
- 唯一化的过程会增加查询代价
- 好处Semijoin可被消除掉
- SemiJoin的内表如果是唯一化的
- 那它和内连接等价
- 路径的唯一化实际上是做一个收支的考量
- 是由唯一化而増加的代价多
- 还是由于转换成为内连接而带来的好处多
- join_is_legal和populate_ joinrel_with_paths中都对 Semi的内表做检查(在join_is_legal检查时产生的唯一化路径会被保存起来, populate_joinrel_with_paths可能会直接利用而不是自己再去重复创建),
- 如果Semi的内表满足以下条件
- 那它已隐含唯一性,可直接认为它就是唯一化路径
- SemiJoin的内表是普通表,且表上有Unique素引
- 约束条件能和索引匹配,那它本身就是唯一化路径
- relation_has_unique_index_for判断约束条件是否能和Unique素引匹配
- 必须是唯一索引(判断Unique标记)。
- 保证Indexoptlnfo->immediate==tue,
- 如果=false,就代表这个唯一性约東是可延退的,这种情况可能产生暂时的不唯一
- 如果是有谓词的局部索引,谓词必须符合约束条件的要求(这是索引在这个查询中能够被利用的最低要求)
- 索引的键要么和约束条件(restrictlist)匹配,
- 要么和Semi的内表的相关的表达式( Special Joininfo-> semi_rhs_exprs)匹配
- SemiJoin的内表是子査询,子査询中有“唯一”性质的子句,
- 且该子句和内表的约束条件能匹配,就唯一化路径
- 子查询有distinctClause,那它的结果有唯一性
- 如果子查询有group Clause子句(不含Grouping sets子句),那进行分组的属性有唯一性
- 如果査询中有Grouping sets,对其进行唯一化分析复杂
- 因此Pg处理Grouping Sets为空且只有1个,这情况下子查询只会产生一条结果,可认为是“唯一化”的
- 如果在查询中没有分组子句(没group Clause和 Grouping sets),那普通的聚集函数和Having子句保证最终结果只有一行,可认为是“唯一化”
- UNON, INTERSECT, EXCEPT如果不带“ALL”,那它的结果有唯一性
- 如果 Semi内表不具有隐式唯一化,那可显式地给它构建唯一化路径
- 通常有两种方法:Sort和Hash
- 要构建显式的唯一化路径,要满足
- jinfo->semi_can_btree==tue
- sjinfo->semi_can_hash==true,
- 尝试用Sor去重,
- 尝试用Hash去重
- 都会增加代价,需注意对这部分代价估算
- add_paths_to_joinrel I中
- 如果发现Semi的内表是唯一化
- Semi在内表“找到一个符合连接条件即可”的这个特性就必然
- 这时就可将Semi变为Inner

- 执行计划中没有Semi
- 内表做基于Hash聚集的唯一化处理,实际上在逻辑优化通过reduce unique semijoins 做过类似的处理
- 第4章中 Semi Join消除部分
8.5建立连接路径
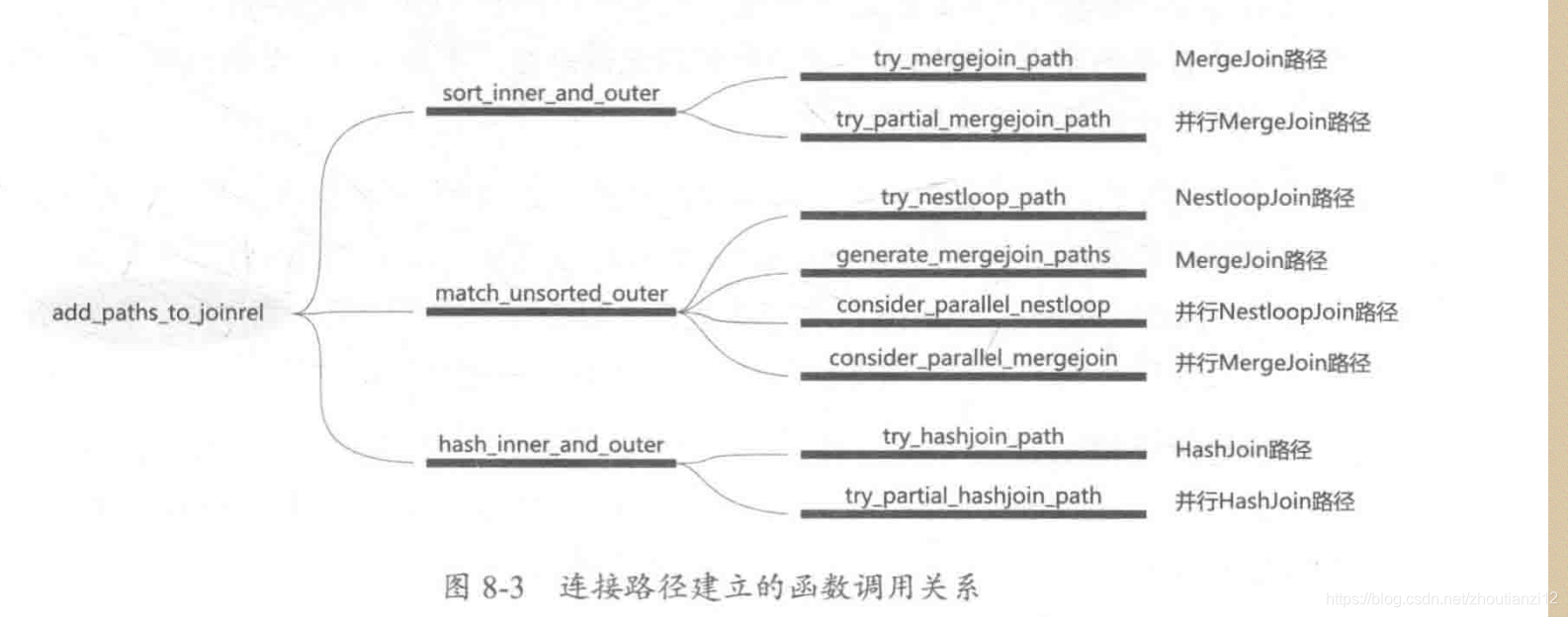
- add_paths_to_joinrel建立物理连接路径
- 虽然物理连接路径只有3种
- 但要同时考虑并行路径、参数化路径
- 创建扫描路径时,每个Rel中可能有多个扫描路径,
- 并行路径、参数化路径及普通的扫描路径
- 选哪个路径来生成新的父Rel路径?
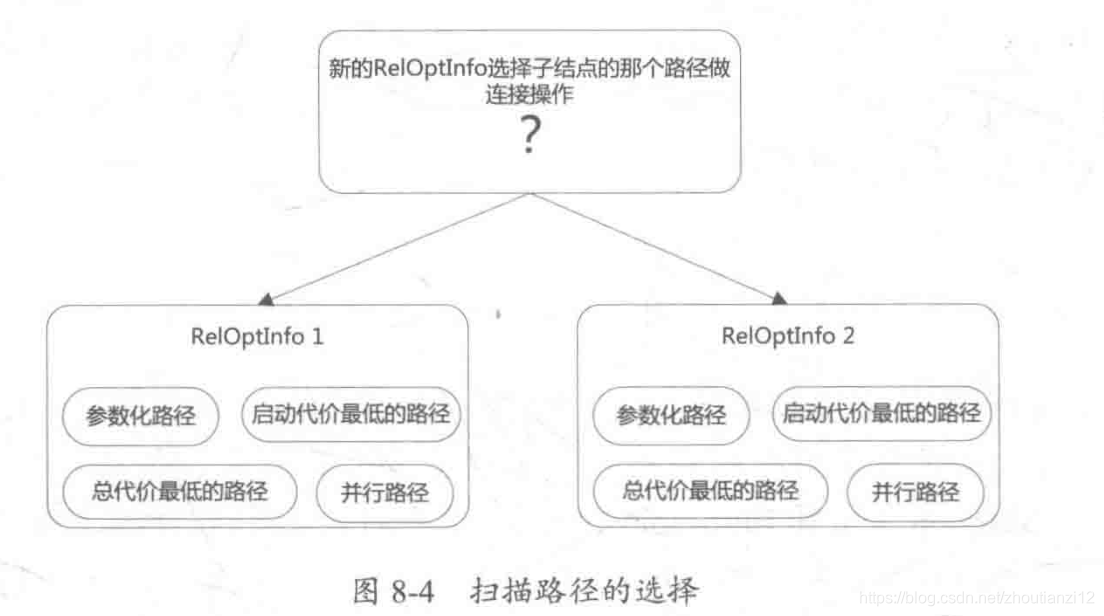
- sort_inner_and_outer主要生成Mergejoin
- 必须显式对子Rel排序
- 只需选子Rel中的总代价最低
- (Reloptlnfo->cheapest_total_path)
- match_unsorted_outer也生成Mergejoin,
- 它只显式对内表排序
- 只有外表的Pathkeys能匹配连接条件
- 只需对内表排序就能获得MergeJoin路径
- 这时内表路径就不一定是总代价最低路径
- 内表的路径是B树索引扫描,且它的Pathkeys满足当前连接条件
- 即使B树的索引扫描不是总代价最低,但它可节省排序时间
- 或许用它来产生连接路径的总代价反而最低
- 还要考虑参数化路径的生成
- 参数化路径是参数的使用者,
- 要保证参数的产生者还没参与到连接路径的建立中,
- 因此要保存一个参数的产生者的表的集合(param source rels),
- 建立连接路径过程中要检査,
- 只有参数的产生者还没参与到连接路径中时,当前连接才有效
- 为方便创建Mergejoin
- 先对约束条件处理
- 把适用于Mergejoin的约束条件从中筛选(select_mergejoin_clauses),
- 这样在sort_inner_and_outer和match_unsorted_outer中都可利用这个Mergejoinable连接条件

8.5.1 sort_inner_and_outer
- 并行的Mergejoin的生成依赖
- LHS的Reloptlnfo中是否有并行路径
- 选择的是子Rel中代价最低的并行路径

- Mergejoin含排序
- 连接结果的顺序和外表顺序一致(排除Right和Full)


- add_paths_to_joinrel通过select_mergejoin_clauses获得适用于Mergejoin的约束条件,结合Mergejoin产生的Pathkeys,约束条件的应用顺序就变得重要
- 两个子约束条件A和B是Mergejoinable的约東
- 生成路径中可用{A,B}来生成一条Mergejoin
- 也可用{B,A}生成一条Mergejoin
- 这两个路径的估计代价相同
- 但这两条路径产生的连接结果的排序方式不同
- 也就是说两条路径产生的Pathkeys不同的
- 不同的Pathkeys对外层的操作产生不同影响

- TEST_A LEFT JOIN TEST_B ON TEST_A.a= TEST_B.a
- AND
- TEST_A.b=TEST_B.b
- 这部分如果要生成Mergejoin
- 外表排序顺序可{TEST A.a, TEST A.b}和{TEST A.b, TEST A.a}两种Pathkeys
- 还要和TEST_C Fulljoin
- 约束条件含TEST A.b
- 选{TEST A.b, TEST A.a}作Mergejoin的Pathkeys
- Mergejoin的连接结果的第一排序键就是TEST A.b,
- 和上层TEST_C做Mergejoin的时就省略对TEST_A.b排序
8.5.1.1外表的初始 Pathkeys
- 根据Mergejoinable连接条件能生成不同顺序Pathkeys
- 连接结果的顺序和外表顺序一致,可将Mergejoinable连接条件中外表的等价类提取出(Restrictlnfo记录外表和内表的等价类),形成一个初始的 Pathkeys,然后用这个初始的Pathkeys衍生出其他顺序Pathkeys,再用衍生出的Pathkeys对Merge Joinable的约束条件排序,最后根据排序后的MergeJoinable约束条件生成内表的Pathkeys
- 用Pathkeys来衍生出不同顺序的约束条件,而不是直接使用约束条件自身来衍生的原因:
- Pathkeys更易和上层的Plannerlnfo->query_pathkeys比较
- 这时的等价类都是“最终”等价类,形成的Pathkeys都是“规范”的Pathkeys
- 约束条件中的有些排序结果冗余
- A.a=B. b AND A.a=B. C AND A.a=C. d AND A.b=
D.e这样的约束
- A.a=B. b AND A.a=B. C AND A.a=C. d AND A.b=
- 它的外表的Pathkeys只可能{A.a,A.b}或{A.b,A.a},
- 但通过约束条件排序可能得到很多种冗余的路径
- 由MergeJoinable连接条件向Pathkeys转换的过程
- 在select_outer_pathkeys_for_merge中实现,
- 这个函数主要分3步
here
8.5.1.3 Mergejoin路径及代价
- 构建Mergejoin较简单,就是向Mergepath结构体填充已有数据
- Pathkeys的不同会产生不同的Mergejoin,
- 创建物理路径带来的消耗也要考虑
- 创路径前预检,对较差的路径在创建前就将其淘汰
- Mergejoin的代价计算分两
- 1:计算初步的代价,筛选掉一些明显的代价较高路径,
- 这能节省查询优化的执行时间
- 2:计算最终的代价,如果已决定要创建Mergejoin,
- 这时就根据Mergejoin在查询执行器中的执行方法
- 来计算各个步骤代价
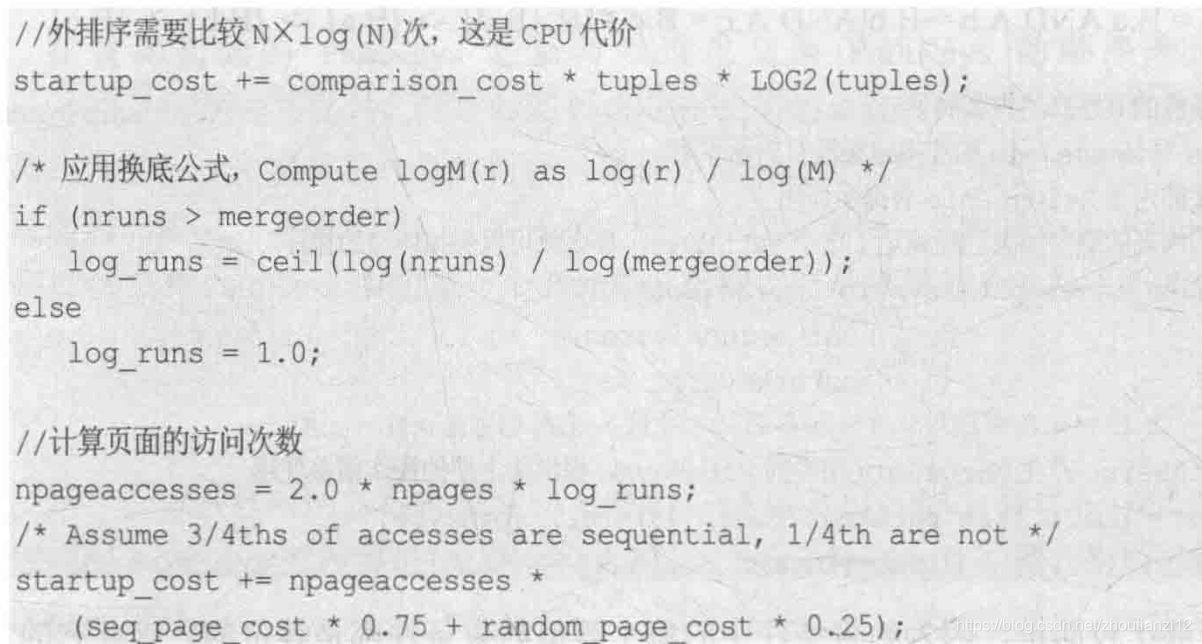
- 初步代价最重要的排序带来的代价(cost_sort)
- 根据待排序元组的输入字节、输出字节及可用的排序内存大小
- 排序分3种
- output_bytes>sort_mem_bytes,
- 说排序的结果会有一部分保存到外存,这时计算代价考虑使用外排序+多路归并
- input_bytes>sort_mem_bytes
- output_bytes< sort_mem_bytes(LIMIT也会产生这种)
- 只需要获得排序后的前K个元组
- 前K个元组是可以放到内存的,堆排
- 内存中保持TOP-K个元组,时间复杂度是N×log(K)
- 代价曲线连续性,计算代价时使N×log(2K)
- 如果待排序的元组完全能加载内存
- 考虑用快排,N×log(N)
- 初级代价计算第一个匹配上连接条件的元组之前的元组所占的比例( outerstartsel和 innerstartsel)和最后一个匹配连接条件元组之前的元组所占的比例(outerendsel和innerendsel)
- 这里本来需要使用所有的Mergejoinable的连接条件来估算这些值,但考虑到这个操作是低效的
- 因此只用第一个连接条件来估算这些值
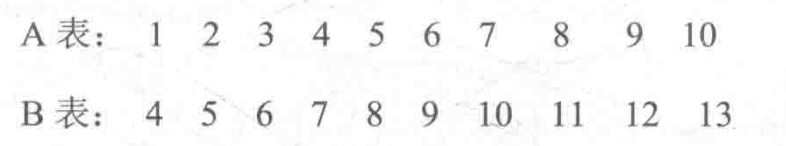
- A表作为外表到第4条记录的时候才能匹配到B表的第1条记录,
- A表的outerstartsel是0.3(共10条数据,前面3条都没有匹配上),B表作为内表第一条记录就能和A中的记录匹配上,因此B表的 innerstartsel是0。
- A表的最后是10,它能和B表的10匹配上,也就是说在 Mergejoin过程中,A表能扫描到结尾,因此A表的outerendsel的是1,而B表只需要扫描到10就结束,因为Mergejoin过程中有一方的数据结東了,另一方也就可以结束,因此B表的innerendsel的值是0.7。
- outerstartsel和 innerstartsel中至少有一个是0,同样, outerendsel和 innerendsel中至少有一个是1。
- 通过 outerstartsel或 innerstartsel能够计算 Mergejoin的启动代价,通过outerendsel或者 innerendsel可以计算 Mergejoin的执行代价。
- 初始代价是在路径建立前估计的,这样在获得初始代价之后,就可以决定是否建立这个路径,如果需要建立这个路径,就开始创建 Mergejoin路径,需要注意的是并行Mergejoin
路径的并行度取决于外表的并行度
- 创建 Mergejoin后还要精确计算Mergejoin的最终代价,这个过程复用了初始代价的计算结果,然后继续计算路径中的表达式代价、物化代价等。

8.5.2 match_unsorted_outer
- sort_inner_and_outer
- 显式排序,最低启动代价路径没用
- match_unsorted_outer考虑外表有序,对内表显式排序
- 如外表是B树索引扫描
- 早期还存在match_unsorted_inner,后被废
- add_paths_to_joinrel考虑过交换两个待连接的Reloptlnfo,
- 这样同一个Reloptlnfo在match_unsorted_outer中各有一次机会做外表和内表,
- 如果还match_unsorted_inner函数生成的路径,
- 就和match_unsorted_outer生成的路径重复
8.5.2.1路径生成流程
- 外表有序,无论Nestloopjoin还是Mergejoin
- 连接的结果也会和外表的顺序一致
- 所以match_unsorted_outer中,主要考虑生成Nestloopjoin和Mergejoin
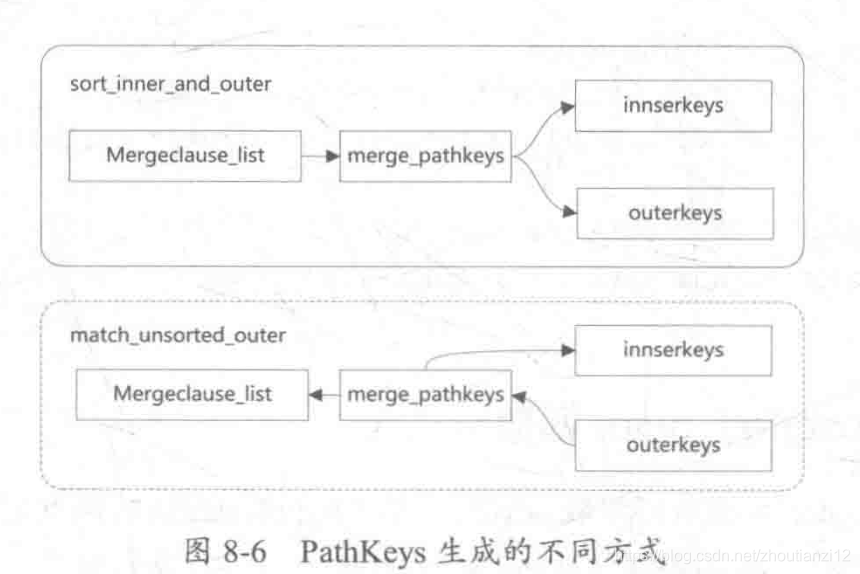
- sort_inner_and_outer通过MergeJoinable的连接条件来生成Pathkeys
- 然后不断调整Pathkeys中的Pathkey顺序来获得不同顺序的Pathkeys
- 然后根据不同顺序的Pathkeys来决定内表的innerkeys和外表的outerkeys
- match_unsorted_outer
- 假定外表路径有序
- 它按外表的Pathkeys反过来排序连接条件(外表的Pathkeys直接就可作为outerkeys用),
- 看连接条件中有哪些是和当前的Pathkeys匹配
- 把匹配的连接条件筛选出(用的是外表的Pathkeys,因此并不是所有的MergeJoinable约束条件都可用上),
- 然后再参照匹配出来的连接条件生成内表要显式排序的innerkeys
- 有Pathkeys和Mergejoinable连接条件后
- Mergejoin路径的建立和sort_inner_and_outer中类似
- 生成Nestloopjoin过程中,对外表的每一条路径,内表都要考虑
- 最低代价的路径
- 参数化路径
- 最低代价路径产生的物化路径。
- 还考虑产生于Nestloopjoin和Mergejoin的并行连接路径
- 并行NestloopJoin的内表看似只考虑参数化路径,
- 但最低代价的非参数化路径也在 innerrel->cheapestparameterized paths中保留一份,
- 所以实际上也考虑了最低代价的非参数化路径
8.5.2.2 Nestloopjoin代价计算
- Nestloopjoin的代价计算和Mergejoin类似
- 初级代价(initial_cost_nestloop)
- 和最终代价(final_cost_nestloop)
- 初级代价决定是否创建路径
- 最终路径筛选己创建路径
- 外表的每一条元组都扫描一次内表(内表路径类似于索引扫描,时间复杂度低些)
- 代价计算要考虑到对一个表连续多次扫描,第一次扫描的代价和之后扫描的代价不同
- 对一个排序路径,第一次执行时会有排序产生的启动代价
- 在第一次扫描之后排序已经完成且保留排序结果
- 第二次扫描时,可直接利用第一次扫描的排序结果
- 无须再排
- 第二次扫描不用计入排序带来的启动代价
- cost_rescan分析这种情況,计算第二次及之后的内表扫描的代价
- 第一次扫描时内表所有页面都在磁盘,扫描的过程中需要将所有的页面加载到内存
- 第二次时,不产生磁盘I/O(设页面进内存后都没被换出)cost_rescan没考虑这
- 初级代价的计算还考虑Semi、 Anti、 Uniquepath
- 针对这3种,初级代价中没计算它们的执行代价
- 它们的执行代价是在最终代价阶段计算

- 最终代价计算中
- 连接关系产生的结果集的数量(没约束情况下),
- 对普通连接,数量是mXn
- 要计算路径中的表达式代价
- 在这基础上进行约束条件的表达式代价的计算、投影表达式代价的计算
- 如果内表是索引扫描,有两种情况
- 是把索引当作普通表对待,这样它的结果集仍是到mXn
- 内表是参数化路径,参数化的连接条件下降到素引扫描上
- final_cost_nestloopjoin中对这种情况的内表行数调整

- Semijoin、 Antijoin、 Uniquepath三种情况下,
- 这里要利用在compute_semi_anti_join_factors函数中已经计算好的两个变量来估计结果集的数量。
- outer_match_frac指外表中能与内表匹配上的元组数量占
外表总元组数量的比例, - match_count代表的是对于一条外表元组平均要扫描多少元组才能在内表中找到第一条匹配的元组,这样可以得到 Semijoin、 Antwoin、 Uniquepath三种情况下和匹配
项相关的连接的结果集的数量。
- 如果Semi、Anti、Uniquepath三种情况,外表中元组和内表没有匹配的元组
- 需怎么计算扫描的次数?
- 如果内表是索引扫描,有没有匹配项一査便知,因此这部分就不
再计算了; - 如果内表是其他扫描,则要扫描整个内表才能确定是否有匹配项,这部分必须计入结果集的数量中

- 最终代价中对Semijoin、 Antijoin、 Uniquepath的执行代价进行计算(初级代价的时候没计算)
- 由于内表路径类型不同,产生的结果集数量也不同,
- 计算代价的方式也不同

8.5.3 hash inner and outer函数
8.6路径的筛选
- 连接路径代价计算看出
- 它的代价计算分两部分:
- 初级代价和最终代价
- 初级代价决定是否创建这个路径,是预筛选的过程
- 目前只针对连接路径有这样的预筛选
- 对基表来说,扫描路径种类有限,且这时还要尽可能考虑扫描路径,这样才能给上层的连接路径
- 扫描路径生成阶段没引入预筛选(位图扫描等扫描路径阶段引入并行路径的预筛选)
- 连接路径阶段的可能性多,且可能生成一些明显差路径,
- 这时预筛选能做一个检查,能节省生成执行计划的时间
- 如果生成执行计划时间太长,即使选出“很好”的执行计划,也不能接受
- 预筛选使用的是初级代价,这是一个不完整的代价,
- 最终代价的计算都是在初级代价的基础上增加新的代价,
- 如增加表达式代价等,
- 如果一个不完整的代价和已有路径的整体代价相比都没有任何优势,那这个连接路径被预筛掉
- 预筛选后,物理路径就会被创建且计算路径的最终代价,这个代价才是代价模型要计算的整体代价,add_path中,还要根据这个整体代价再做一次检查,和预筛选不同,预筛选只决定新路径创建不创建,add_path在新路径特别优秀的情况下,还
会淘汰一些老路径。
- Pg单独实现了关于并行路径筛选的接口,
- 用 add_partial_path_precheck做预筛选,
- add_partial_path做路径的最终筛选。
-
add_path将新路径和Reloptlnfo->pathlist比较,
-
add_partial_path将新路径和Reloptlnfo->partial pathlist比较
-
路径筛选依据取決于
-
路径的启动代价,可选项,
- 含LMIT子句时,启动代价才有用,
- 路径筛选过程中是否考虑启动代价的非常重要的因素就是tuple_fraction是否有值。
-
路径的总代价,路径的总代价是最重要的一个指标。
-
两路径的Pathkeys是不是具有可比性,
- 如果有,哪个 Pathkeys更好。
-
两个路径返回的行数哪个少,返回行数少说明它具有更好的过滤性,给上层的操作减少计算量
-
两个路径是否并行安全,安全的好于非安全的(在源代码中判断
parallel safe时需要注意比较的符号是还是>=,这里有细微的差别)。 -
如果是参数化路径,它们是否需要同样的“参数生产者”。
8.7小结
- 连接合法性判断的部分是难理解,
- 有些情况的判断Pg开发人员也没办法给出示例,
- 想要理解其中含义要仔细分析这部分的源码
- 本章介绍物理连接路径的生成,
- 实际上物理连接路径的种类单一,只有3种情况
- 不过结合不同类型的扫描路径
- 如并行扫描、参数化扫描、索引扫描,就会产生很多不同的可能性。
智能推荐
Bayesian statistics-程序员宅基地
文章浏览阅读152次。文件夹1Bayesian model selection贝叶斯模型选择1奥卡姆剃刀Occams razor原理2Computing the marginal likelihood evidence2-1 BIC approximation to log marginal ..._a.students.guide.to.bayesian.statistics
用kali Linux暴力破解Windows RDP(3389号端口)_kali 3389-程序员宅基地
文章浏览阅读1.6w次,点赞7次,收藏58次。RDP是Windows的远程桌面协议。我们要暴力破解3389号端口的前提是对方的3389号端口是开放的,不过大多数情况下电脑是默认关闭的,即使有远程协助的需要也不一定非得要用到3389号端口,开启不仅容易被对方破解,还容易成为肉鸡如果你发现你的端口是开放的,那么我建议你还是关上吧。用nmap查看目标端口是否开放。..._kali 3389
Android Studio 基础 之 截图,指定截图区域动态截图_android studio 截图-程序员宅基地
文章浏览阅读4.5k次,点赞5次,收藏33次。Android Studio 基础 之 截图,指定截图区域动态截图目录Android Studio 基础 之 截图,指定截图区域动态截图一、简单介绍二、实现原理三、注意事项四、预览效果五、实现步骤六、关键代码7、附录简版截图下面是简单的只要 x, y, width,heigth 输入进行屏幕截图的代码(也是从上面代码截取出来的,方便后期封装为工具类)一、简单介绍Android 开发中的一些基础操作,使用整理,便于后期使用。本节介绍,在Android中,_android studio 截图
android的底层驱动调试心得_cat /d/gpio-程序员宅基地
文章浏览阅读3.5k次,点赞3次,收藏23次。1、安卓模拟器使用sudo snap install scrcpy_302.snap --dangerousscrcpy抓取gpio的状态cat sys/kernel/debug/gpio2、调试背光ifconfig -a 查看wifi是否起来fdb111c89802e2bd78ebacaedac8e56ab12704ce lams0c7ba9436091827cc233b197c1432f4af8b0f1fe cq#sudo upgrade_tool di -b boot.img_cat /d/gpio
iOS 导航条 知识简析(返回按钮,标题,背景颜色 等)_返回按钮一般是什么颜色-程序员宅基地
文章浏览阅读2.4k次。一:导航条的返回按钮在讲导航条的返回按钮之前,先分享一个发现: 导航条自带 pop手势滑动功能,如果你没有自定义“返回”按钮,则可以直接手势滑动。栗子:页面A push到页面 B, B要pop回到A,在没有自定义返回按钮的情况下,可以直接点击导航条的Back按钮,也可以讲手指放在屏幕左边,向右滑动屏幕,即可pop回A。注:如果自定义了导航条的返回按钮,则滑动功能消失_返回按钮一般是什么颜色
技巧收集-程序员宅基地
文章浏览阅读762次。判断用户是否中止并离开了RESPONSE.ISCLIENTCONNECTED
随便推点
mnist手写数字分类的python实现_TensorFlow的MNIST手写数字分类问题 基础篇-程序员宅基地
文章浏览阅读348次。本章节的阅读对象是对机器学习和 TensorFlow 都不太了解的新手.就像我们学习编程的第一步往往是学习敲出 "Hello World" 一样,机器学习的入门就要知道 MNIST.MNIST 是一个入门级的计算机视觉数据集,它包含各种手写数字图片:它也包含每一张图片对应的标签,告诉我们这个是数字几;比如,上面这四张图片的标签分别是 5, 0, 4, 1。在此教程中,我们将训练一个机器学习模型用于..._python 自己拍摄手写数字的图片。根据前面训练得到的分类器,自行设计数据预处理流
wxpython窗口跳转_WxPython-用按钮打开一个新窗口-程序员宅基地
文章浏览阅读2k次。我正在创建一个界面,我需要打开一个新的窗口,点击一个按钮。所以我创建了主窗口,创建了所有按钮,并在一个类下创建了新窗口。我不完全确定是否需要,但我也会包括这一部分信息。对python来说是新的,如果它充满了错误,那么很抱歉。如果有人也能回答在打开另一个窗口时如何隐藏主菜单,那就太好了。干杯。import wxversionwxversion.select("2.8")import wxclass ..._wxpython点击按钮出现新窗口
操作系统精选习题——第四章_系统抖动现象的发生由什么引起的-程序员宅基地
文章浏览阅读3.4k次,点赞3次,收藏29次。一.单选题二.填空题三.判断题一.单选题静态链接是在( )进行的。A、编译某段程序时B、装入某段程序时C、紧凑时D、装入程序之前Pentium处理器(32位)最大可寻址的虚拟存储器地址空间为( )。A、由内存的容量而定B、4GC、2GD、1G分页系统中,主存分配的单位是( )。A、字节B、物理块C、作业D、段在段页式存储管理中,当执行一段程序时,至少访问()次内存。A、1B、2C、3D、4在分段管理中,( )。A、以段为单位分配,每._系统抖动现象的发生由什么引起的
UG NX 12零件工程图基础_ug-nx工程图-程序员宅基地
文章浏览阅读2.4k次。在实际的工作生产中,零件的加工制造一般都需要二维工程图来辅助设计。UG NX 的工程图主要是为了满足二维出图需要。在绘制工程图时,需要先确定所绘制图形要表达的内容,然后根据需要并按照视图的选择原则,绘制工程图的主视图、其他视图以及某些特殊视图,最后标注图形的尺寸、技术说明等信息,即可完成工程图的绘制。1.视图选择原则工程图合理的表达方案要综合运用各种表达方法,清晰完整地表达出零件的结构形状,并便于看图。确定工程图表达方案的一般步骤如下:口分析零件结构形状由于零件的结构形状以及加工位置或工作位置的不._ug-nx工程图
智能制造数字化工厂智慧供应链大数据解决方案(PPT)-程序员宅基地
文章浏览阅读920次,点赞29次,收藏18次。原文《智能制造数字化工厂智慧供应链大数据解决方案》PPT格式主要从智能制造数字化工厂智慧供应链大数据解决方案框架图、销量预测+S&OP大数据解决方案、计划统筹大数据解决方案、订单履约大数据解决方案、库存周转大数据解决方案、采购及供应商管理大数据模块、智慧工厂大数据解决方案、设备管理大数据解决方案、质量管理大数据解决方案、仓储物流与网络优化大数据解决方案、供应链决策分析大数据解决方案进行建设。适用于售前项目汇报、项目规划、领导汇报。
网络编程socket accept函数的理解_当在函数 'main' 中调用 'open_socket_accept'时.line: 8. con-程序员宅基地
文章浏览阅读2w次,点赞38次,收藏102次。在服务器端,socket()返回的套接字用于监听(listen)和接受(accept)客户端的连接请求。这个套接字不能用于与客户端之间发送和接收数据。 accept()接受一个客户端的连接请求,并返回一个新的套接字。所谓“新的”就是说这个套接字与socket()返回的用于监听和接受客户端的连接请求的套接字不是同一个套接字。与本次接受的客户端的通信是通过在这个新的套接字上发送和接收数_当在函数 'main' 中调用 'open_socket_accept'时.line: 8. connection request fa