Redis——集群搭建_虚拟机搭建redis集群-程序员宅基地
一、开启redis
我们日常不使用docker来部署redis集群,基本上都是直接使用redis启动,是在redis的文件里面进行
![]()
但是,如果像在任意位置能执行redis-server的话,需要配置环境变量。

回归正题,我们需要搭建一个集群,我们先在虚拟机上面进行。
这个前提里面我们已经把redis.conf复制了三份数据分别放在7001,7002,7003里面去.

首先我们在虚拟机上三个redis的开启。分别对应的端口号为7001,7002,7003。

其次,我们需要在redis.conf文件里面添加replica-announce-ip参数.作用其实就是为了确保在这些redis从节点能在集群里面进行发布自己的ip地址.

直接添加第一行数据。

此时这里已经对redis的集群基本配置已经配置完毕,我们来尝试一下连接!

发现连接不上!
第一种情况:虚拟机的防火墙没有关闭。
第二种情况:bind没有进行注释掉,并且还没有关闭保护模式。(原来是因为配置文件中的bind没有进行注释。其实bind指向127.0.0.1其实也就是只允许虚拟机本机通过回环地址来连接redis。我们来进行修改。)


然后就可以正常连接上了。
二、主从关系部署
添加:
第一种:配置文件
在配置文件里面添加一行配置 slaveof <masterip><masterport>.在这样就去确定当前redis的主是那一个。这里填上ip地址,以及端口。

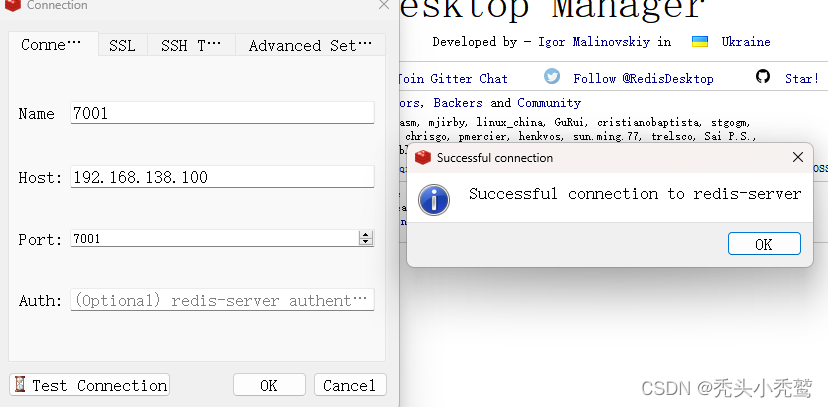
第二种:redis服务上
在redis服务里面执行 slaveof <masterip><masterport>.命令。
判断:
验证是否已经建立好主从关系。直接在主的服务里面执行info replication来查看

读写分离:
而主从关系我们看这样图:
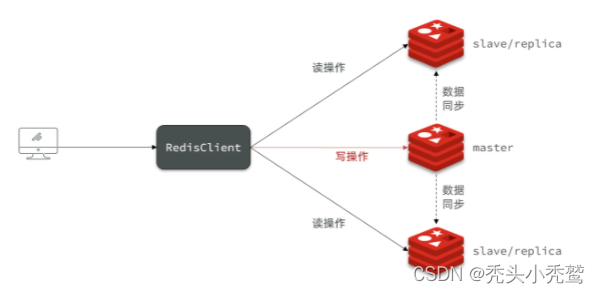
我们可以清晰的了解到,redis集群默认是主节点读写都可以的操作,从节点只做读的操作。

那主从数据如何进行同步的咧?
分两种情况:
(1)全量同步(基于RDB文件来进行):
主要发生在第一次连接的时候,执行全量同步把master的所有数据拷贝给slave节点。

判断是否第一次同步:
通过Replication ID:
简称:replid,数据集的标记,每一个master都有一个唯一的replid(并且slave本质上也是一个master,也会有自己的replid),当slave连接上后,master会发现slave的replid与其不相同,所以就判断为是第一次同步,就会做全量同步。之后slave就会继承master的id值。
(1)增量同步(通过repl_backlog):
通过replid我们可以判断得出是否进行全量同步,那增量同步就通过repl_backlog来进行的。

offset :
偏移量,随着记录命令日志增多而逐渐增大。其实我可以理解为就是做数据的记录备份。
repl_backlog:
偏移固定大少的环型数组,也就是角标达到数组末尾,这个数据就会进行数据覆盖。
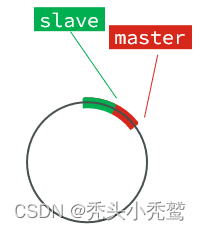


这个环里面记录的数据有命令日志数据,以及对应的偏移量。
当出项slave出现了网络阻塞时,master的命令日志数据以及偏移量远远超过slave时。
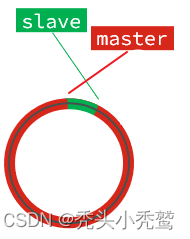
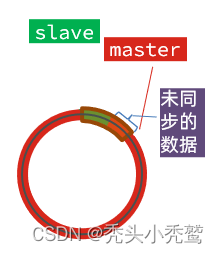
此时被框选的部分的slave未同步的偏移量就会被更新掉,然后slave就会发现自己的offset没有了。无法完成增量同步,就到最后只能进行全量同步了。
三、哨兵(sentinel)机制

哨兵作用:
监控:sentinel会不断的检查redis的主从节点是否正常运作。
自动故障恢复:也就是当redis的主节点故障之后,会迅速安排一个从节点接上。
通知:也就是告诉redis从节点,主节点故障了。
监控的原理:类似微服务一样,基于心跳机制来进行监控,sentinel每一秒会对所有节点进行一个ping命令来确保节点是否存货
(1)主观下线:也就是某个sentinel在1s里面发送的ping没有在规定时间内响应,就为主观下线。
(2)客观下线:主要用于集群,也就是集群里面当quorum个sentinel都认为该主节点没有响应,就为客观下线。
其实也就是结合微服务里面的sentinel来对redis进行一个集群管控操作。首先sentinel我们都知道使用来做微服务保护的。来对微服务进行限流访问以及熔断机制的。
但是我们回想一个点,假设单节点的sentinel挂掉之后,对一个的sentinel对微服务的保护机制就没有了。所以我们要搭建sentinel的时候需要进行集群搭建。当然单节点的sentinel也可以,但是不安全!
并且!!!redis里面是有sentinel的!也就是内置了sentinel!所以我们是不需要在外置开启sentinel的。只需要使用redis-sentinel命令就可调用redis里面的sentinel!
注意的是:redis集群一定要一直开着。这个redis-sentinel是用来监控redis的。
我们只需要写好sentinel配置文件即可:

然后通过使用命令来根据每个配置文件来以哨兵模式来启动。

假设我们把7001的redis给宕机了,看一下27001也就是sentinel的日志信息。
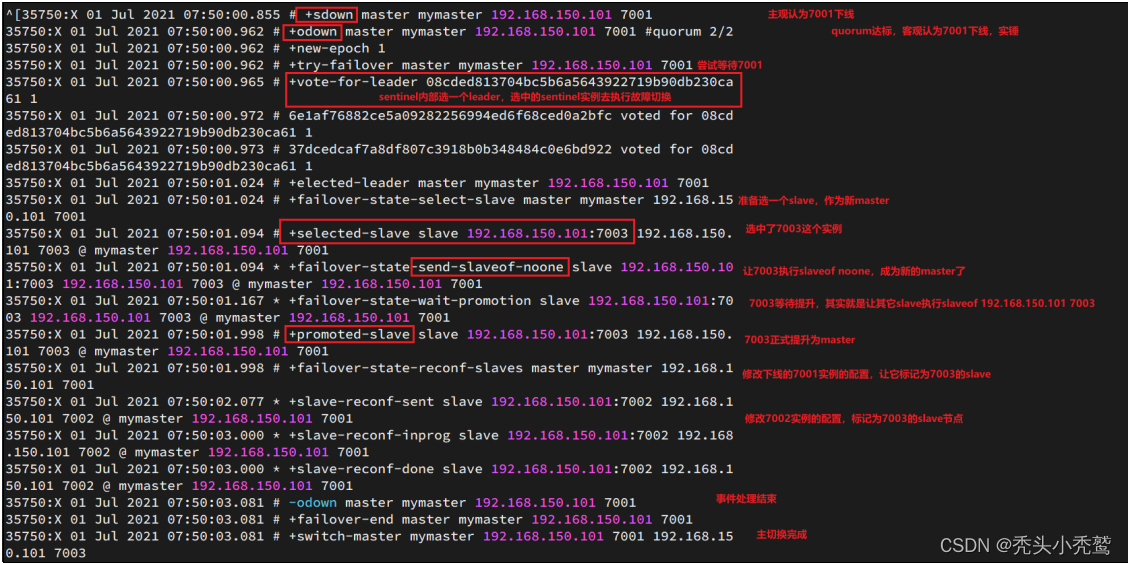
此时对应的7003与7002也有有日子信息的导入。
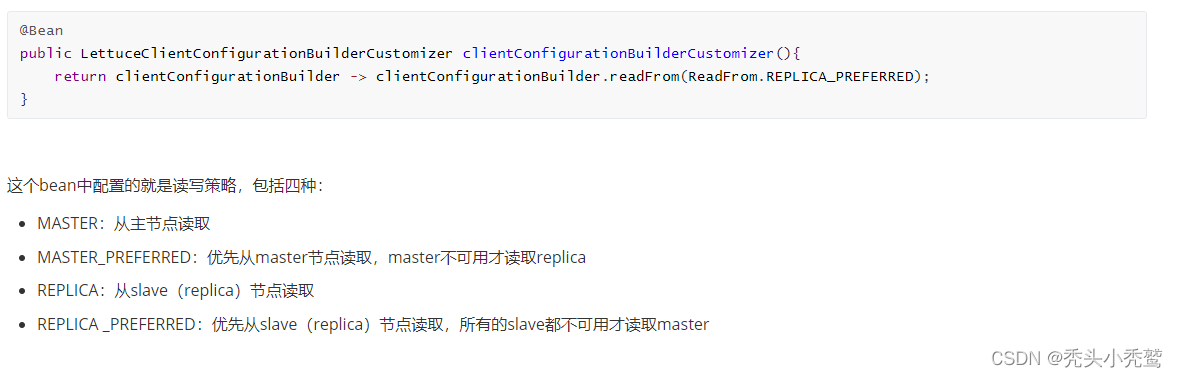
在spring中如何配置根据哨兵机制来进行读写分离咧?
我们都知道spring-redis提供了一个redisTemplate的封装类。我们只需要调整application.yml文件里面redis的连接端口就可以使用redisTemplate来发送数据到redis里面去。如果要做读写分离的话,我们此时在application.yml文件里面配置上这样:
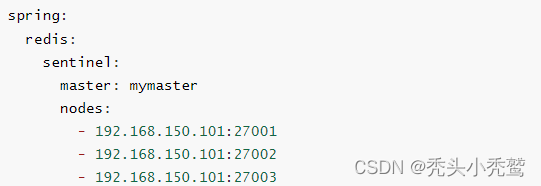
而RedisTemplate的底层是利用lettuce实现了节点的感知和自动切换。
此时如果我们需要对其进行读写分离的话,就需要重写lettuce类,并且把其放入到spring容器里面去。
四、分片集群(redis-cli --cluster)
主从结构是为了进行读写分离,而哨兵机制,是为了在主从结构的基础上预防主节点丢失的一个保护机制。而这两个围绕着都是一个主节点(master),多个从节点(slave)
那如果当有大量的数据要进行写入,单个master是无法支持得到,所以对数据进行一个分类!把不同的数据分到不同的master上面进行管理,此时就需要使用到分片集群。
(通俗易懂来说,就是要有多个主节点,实现数据分区。)

首先,开启集群的前提那肯定是开启redis,而开启集群的话,只需要在redis的配置文件上,添加开启集群功能,以及进群的心跳检查。
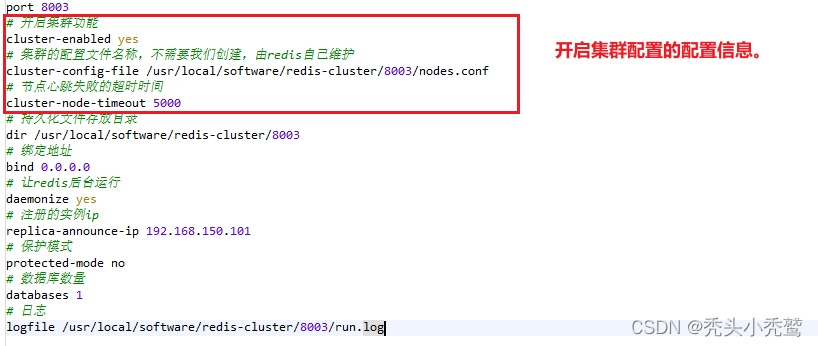
用对应的配置文件进行开启。因为daemonize为yes,也就是后台运行,此时我们想知道redis是否全部开启。使用查看进程命令。
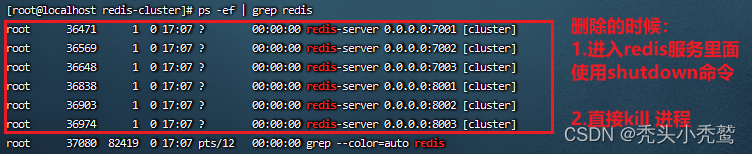
注意:现在只是开启了redis服务,并没有形成分片集群,要形成分片集群,就需要进行一下操作。
我们使用的redis是6.2.6版本的redis,对应redis5.0之后,集群管理已经集成到了redis-cli命令里面去了。
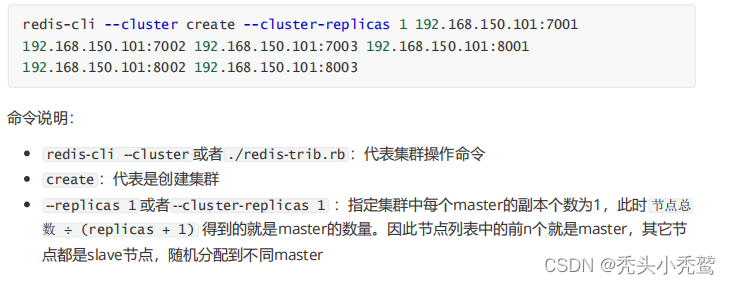
--cluster:代表使用集群操作命令。
create:创建集群。
--replicas 1:也就是设置replicas=1提供的端口的节点总数的基础上/(replicas+1),此时有6的接口,除以2对应就是有3个主节点。
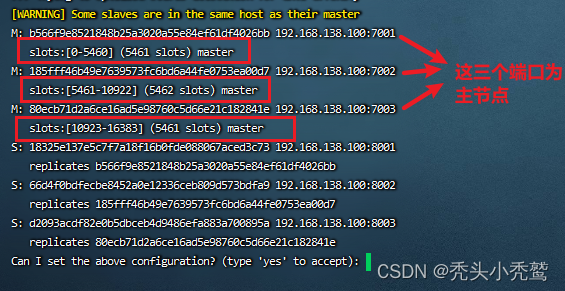
我们可以通过这个图,可以看到slots就是redis把主节点分配的插槽位置。
查看集群状态:
redis-cli -p 集群任意端口 cluster nodes

此时如果要在redis里面存放数据的时候,之前是通过redis-cli -p 端口。然后直接把set放入进去。
当时因为现在是以集群形式。所以对应的数据会分区来进行输入。redis会通过存入的数据进行一个转化,转化为插槽对应的数值。
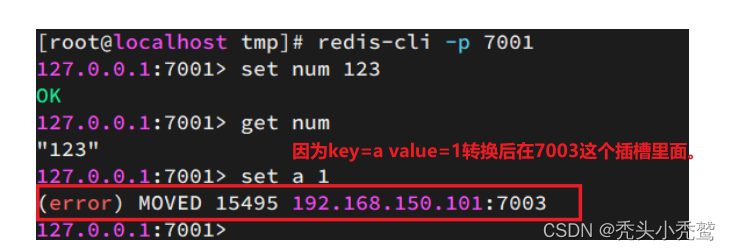
所以我们之后要通过redis-cli -p -c 端口,来进入redis服务。

redis分片集群是按什么来进行插槽注入的?
redis会根据key的CRC16算法得出一个哈希值,然后对16384进行取余,这样的话就会得到slot也就是插槽值。但是需要留意一个点。

也就是key={itcast}num的时候计算的就是{}里面的itcast的哈希值。
集群伸缩:
假设中途需要添加新的节点到集群里面:
一、加入节点
(1)先启动节点(根据集群部署的配置文件来进行部署)
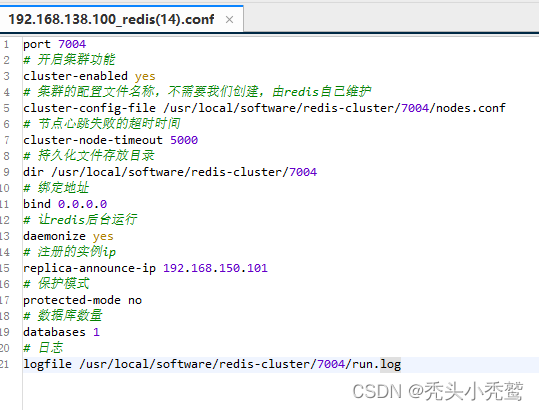
开启:
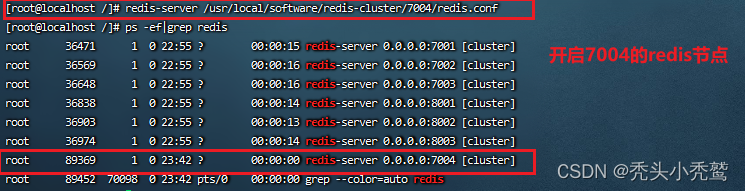
(2)使用redis-cli 里面的命令 --cluster 的添加节点的命令(add-node)

此时我们在查看一下对应集群里面的信息。cluster nodes

7004的插槽范围是为0!所以此时7004是无法用来存储信息的!
二、分配插槽:
(1).通过命令redis-cli的--cluster 里面的reshard 端口。这里的重点是找到当前端口对应的集群。而并不是对某个节点进行插槽拆分。reshard
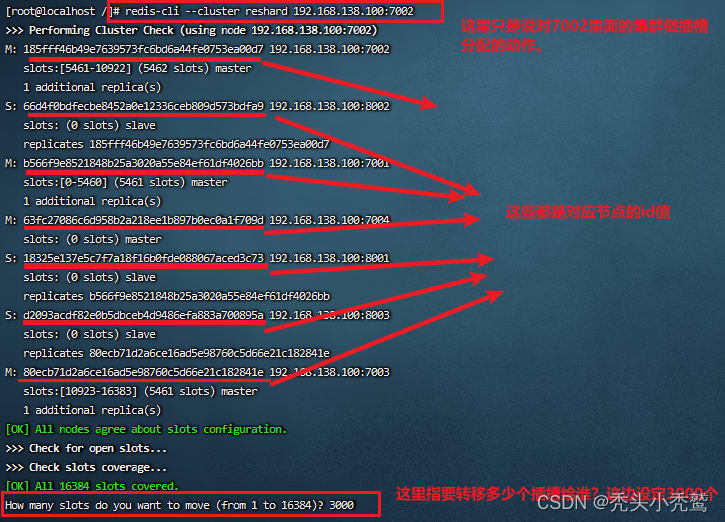 (2)确定这3000个插槽是给那个节点使用的。
(2)确定这3000个插槽是给那个节点使用的。
![]()
(3)决定用什么方式来抽取这3000个插槽出来:


我们现在来看一下转移后对应的插槽范围值:

我们用的方法是all,所以此时会发现,插槽分了三个部分。分别都是原本7001,7002,7003里面的插槽!
故障转移:
我们现在需要假设一个点:也就是我们之前都是通过哨兵机制来进行主节点故障之后,让从节点代替的,那分片集群式假设也出现这种情况的时候,那分片集群式如何解决的咧?
自动故障转移:
也就是分片集群会自动进行主节点的替换。当我们把7002的进程杀掉后,也就是让7002这个redis服务宕机!


手动故障转移:
假设,我现在7002的端口又重新启动的。但是我又想让其变会主节点。此时就需要进行手动调试。
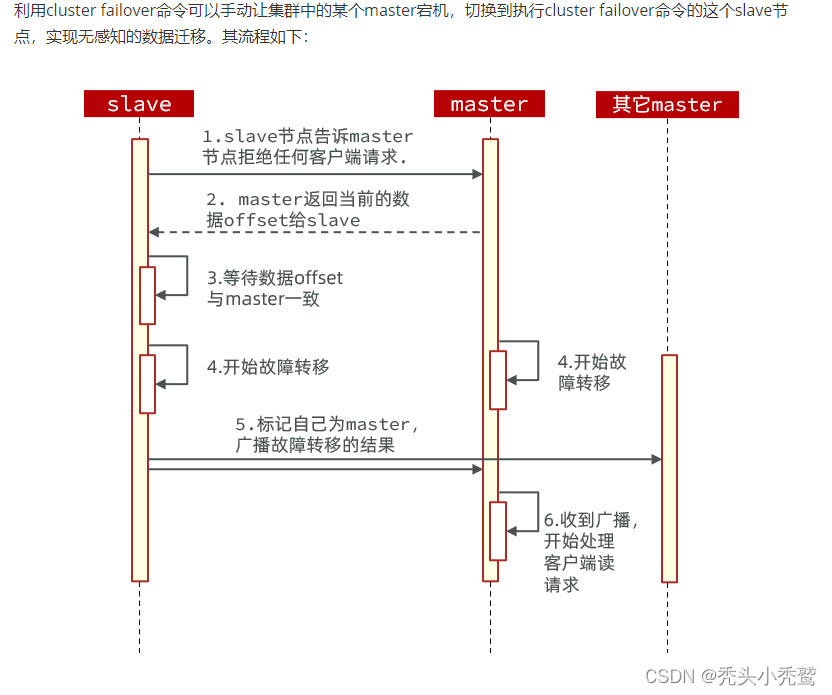
工作原理就是进入7002服务器里面,执行cluster failover(故障转移)命令。
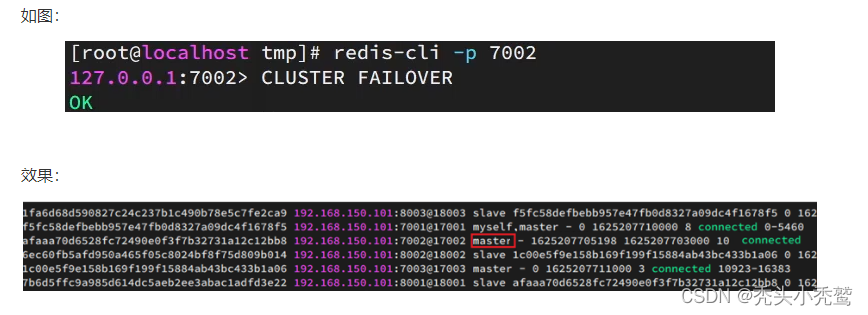
此时7002就恢复主节点,8002就恢复为从节点!
而spring-redis如何进行分片集群整合,与哨兵机制一样。
(1)注入spring-redis的依赖
(2)编写读写分离策略的bean!(一模一样的)
(3)application.yml文件的编写(差异点)
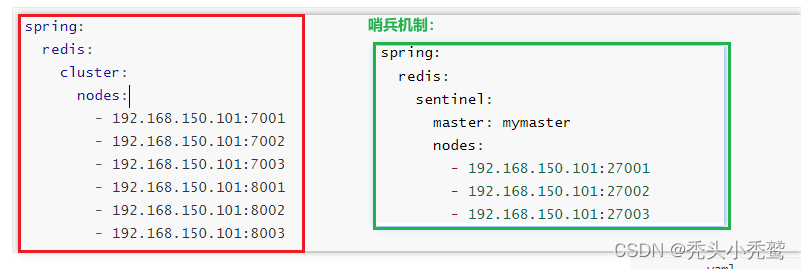
课外拓展:
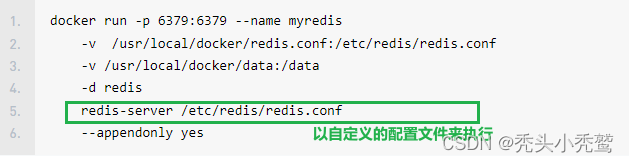
我们可以使用docker来部署redis,重点来了,如果我们没有给其设置配置文件,会按redis内部里面执行配置文件,以6379为端口,无法去修改,这个与mysql不同,mysql是可以去对默认的配置文件进行替换的。
智能推荐
python简易爬虫v1.0-程序员宅基地
文章浏览阅读1.8k次,点赞4次,收藏6次。python简易爬虫v1.0作者:William Ma (the_CoderWM)进阶python的首秀,大部分童鞋肯定是做个简单的爬虫吧,众所周知,爬虫需要各种各样的第三方库,例如scrapy, bs4, requests, urllib3等等。此处,我们先从最简单的爬虫开始。首先,我们需要安装两个第三方库:requests和bs4。在cmd中输入以下代码:pip install requestspip install bs4等安装成功后,就可以进入pycharm来写爬虫了。爬
安装flask后vim出现:error detected while processing /home/zww/.vim/ftplugin/python/pyflakes.vim:line 28_freetorn.vim-程序员宅基地
文章浏览阅读2.6k次。解决方法:解决方法可以去github重新下载一个pyflakes.vim。执行如下命令git clone --recursive git://github.com/kevinw/pyflakes-vim.git然后进入git克降目录,./pyflakes-vim/ftplugin,通过如下命令将python目录下的所有文件复制到~/.vim/ftplugin目录下即可。cp -R ...._freetorn.vim
HIT CSAPP大作业:程序人生—Hello‘s P2P-程序员宅基地
文章浏览阅读210次,点赞7次,收藏3次。本文简述了hello.c源程序的预处理、编译、汇编、链接和运行的主要过程,以及hello程序的进程管理、存储管理与I/O管理,通过hello.c这一程序周期的描述,对程序的编译、加载、运行有了初步的了解。_hit csapp
18个顶级人工智能平台-程序员宅基地
文章浏览阅读1w次,点赞2次,收藏27次。来源:机器人小妹 很多时候企业拥有重复,乏味且困难的工作流程,这些流程往往会减慢生产速度并增加运营成本。为了降低生产成本,企业别无选择,只能自动化某些功能以降低生产成本。 通过数字化..._人工智能平台
electron热加载_electron-reloader-程序员宅基地
文章浏览阅读2.2k次。热加载能够在每次保存修改的代码后自动刷新 electron 应用界面,而不必每次去手动操作重新运行,这极大的提升了开发效率。安装 electron 热加载插件热加载虽然很方便,但是不是每个 electron 项目必须的,所以想要舒服的开发 electron 就只能给 electron 项目单独的安装热加载插件[electron-reloader]:// 在项目的根目录下安装 electron-reloader,国内建议使用 cnpm 代替 npmnpm install electron-relo._electron-reloader
android 11.0 去掉recovery模式UI页面的选项_android recovery 删除 部分菜单-程序员宅基地
文章浏览阅读942次。在11.0 进行定制化开发,会根据需要去掉recovery模式的一些选项 就是在device.cpp去掉一些选项就可以了。_android recovery 删除 部分菜单
随便推点
echart省会流向图(物流运输、地图)_java+echart地图+物流跟踪-程序员宅基地
文章浏览阅读2.2k次,点赞2次,收藏6次。继续上次的echart博客,由于省会流向图是从echart画廊中直接取来的。所以直接上代码<!DOCTYPE html><html><head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width,initial-scale=1,minimum-scale=1,maximum-scale=1,user-scalable=no" /&_java+echart地图+物流跟踪
Ceph源码解析:读写流程_ceph 发送数据到其他副本的源码-程序员宅基地
文章浏览阅读1.4k次。一、OSD模块简介1.1 消息封装:在OSD上发送和接收信息。cluster_messenger -与其它OSDs和monitors沟通client_messenger -与客户端沟通1.2 消息调度:Dispatcher类,主要负责消息分类1.3 工作队列:1.3.1 OpWQ: 处理ops(从客户端)和sub ops(从其他的OSD)。运行在op_tp线程池。1...._ceph 发送数据到其他副本的源码
进程调度(一)——FIFO算法_进程调度fifo算法代码-程序员宅基地
文章浏览阅读7.9k次,点赞3次,收藏22次。一 定义这是最早出现的置换算法。该算法总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面予以淘汰。该算法实现简单,只需把一个进程已调入内存的页面,按先后次序链接成一个队列,并设置一个指针,称为替换指针,使它总是指向最老的页面。但该算法与进程实际运行的规律不相适应,因为在进程中,有些页面经常被访问,比如,含有全局变量、常用函数、例程等的页面,FIFO 算法并不能保证这些页面不被淘汰。这里,我_进程调度fifo算法代码
mysql rownum写法_mysql应用之类似oracle rownum写法-程序员宅基地
文章浏览阅读133次。rownum是oracle才有的写法,rownum在oracle中可以用于取第一条数据,或者批量写数据时限定批量写的数量等mysql取第一条数据写法SELECT * FROM t order by id LIMIT 1;oracle取第一条数据写法SELECT * FROM t where rownum =1 order by id;ok,上面是mysql和oracle取第一条数据的写法对比,不过..._mysql 替换@rownum的写法
eclipse安装教程_ecjelm-程序员宅基地
文章浏览阅读790次,点赞3次,收藏4次。官网下载下载链接:http://www.eclipse.org/downloads/点击Download下载完成后双击运行我选择第2个,看自己需要(我选择企业级应用,如果只是单纯学习java选第一个就行)进入下一步后选择jre和安装路径修改jvm/jre的时候也可以选择本地的(点后面的文件夹进去),但是我们没有11版本的,所以还是用他的吧选择接受安装中安装过程中如果有其他界面弹出就点accept就行..._ecjelm
Linux常用网络命令_ifconfig 删除vlan-程序员宅基地
文章浏览阅读245次。原文链接:https://linux.cn/article-7801-1.htmlifconfigping <IP地址>:发送ICMP echo消息到某个主机traceroute <IP地址>:用于跟踪IP包的路由路由:netstat -r: 打印路由表route add :添加静态路由路径routed:控制动态路由的BSD守护程序。运行RIP路由协议gat..._ifconfig 删除vlan