【深度学习】李宏毅2021/2022春深度学习课程笔记 - 机器学习的可解释性_李宏毅2021机器学习笔记-程序员宅基地
技术标签: 机器学习的可解释性 笔记 机器学习 深度学习 人工智能 # 深度学习
文章目录
一、为什么我们需要可解释性的机器学习
- 一个AI就算能回答出正确的答案也不代表它很聪明
下面举个例子,从前有一匹神马,“会计算数学题”,比方说,你问他根号9等于多少,它就会跺3下马蹄。但是人们后来发现,神马只有在很多人围观的时候才能算出数学题,当没有很多人围观的时候,它就会乱跺马蹄。所以,其实神马也许并不是真的会解数学题,它只是学会了在很多人围观的时候察言观色,根据人们的反应推断出什么时候该停下跺马蹄,这样它才就会有胡萝卜吃。

- 当机器学习用于决定银行是否要给一个人贷款的时候,根据法律,它必须给出一个理由
- 当机器学习用在医疗诊断上时,人命关天,AI必须给出一个诊断的理由,而不能仅仅是一个黑箱
- 当一个AI驱动的无人驾驶车进行急刹车后导致了后面的车追尾,那么这个无人驾驶车是否要负责任也要取决于它紧急刹车的理由。如果是因为前面有老太太在过马路,那么它急刹车就算对的;如果是无缘无故地急刹车,那这个AI就有问题了
- 更重要地是,如果机器学习是具有可解释性的,那我们就可以根据这个解释的结果去修正改进AI模型
二、可解释性的 vs 强大的(Powerful)
- 一些模型是具有较强的可解释性的,例如线性模型,但是它不是 Powerful 的
- Deep 的 Model 很难被解释,但是它比线性模型更加 Powerful
决策树模型不仅具有较强的 Powerful ,而且还具有较强的可解释性
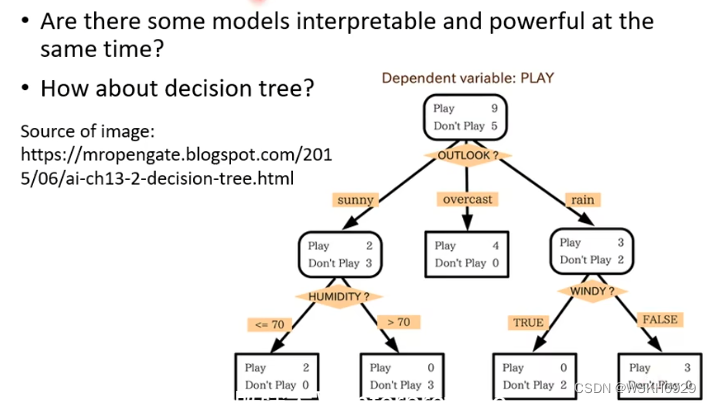
但是,决策树模型也可能会很复杂(如下图左所示),此时也不太好解释
另外,我们通常不会使用一颗决策树去进行预测,而是使用一个森林(多个决策树),此时,森林又变成不好解释的了

三、可解释性机器学习的目标
可以给出让人感觉到舒服的解释(不一定要准确)
如下图所示,哈佛大学的一项研究表明,当人们在排队打印东西时:
- 如果一个人说“打扰一下,我有5张纸,可以让我先印吗”,此时接受率是60%
- 如果一个人说“打扰一下,我有5张纸,可以让我先印吗,因为我有急事”,此时接受率暴涨到了94%
- 如果一个人说“打扰一下,我有5张纸,可以让我先印吗,因为我需要先印”,此时接受率也高达93%
从上面的例子可以发现,有时候,不一定需要一个准确的理由才可以让人们接受,往往理由只需要能让人们感到舒服就可以了
所以,可解释性机器学习的目标就是可以给出让人们舒服的解释

四、可解释性的机器学习
可解释性的机器学习可分为两个解释方向,一个是局部的解释,另一个是全局的解释。
如下图所示:
- 局部的解释(对决策的原因进行解释):告诉我们为什么它认为图片上的是一只猫
- 全局的解释(总结决策的规律):告诉我们猫应该是什么样子的
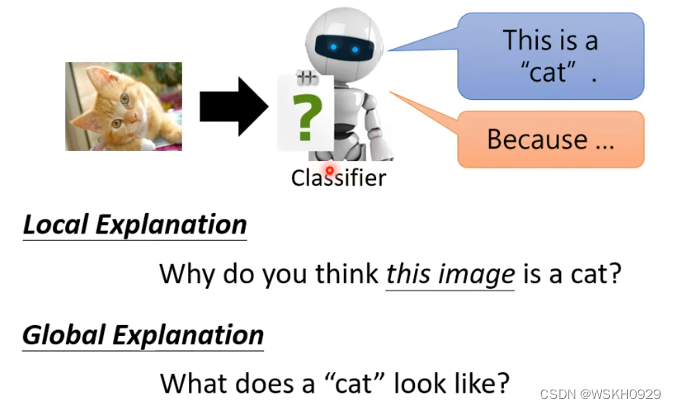
4.1 Local Explanation 局部的解释
4.1.1 特征重要性
当你想知道模型决策的原因时,可以尝试找出输入特征中对模型决策影响最大的特征,然后进行分析
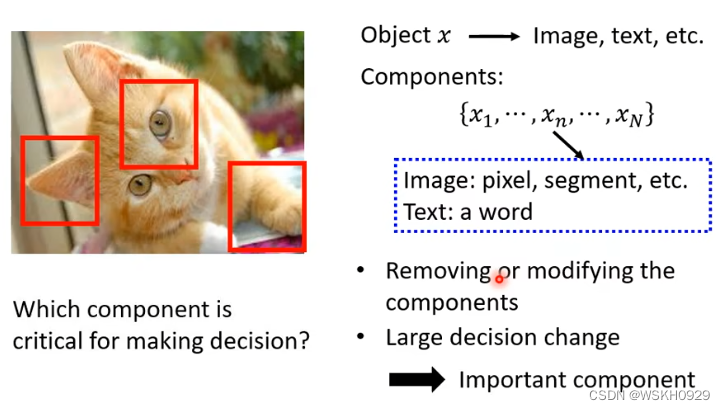
如下图所示,我们可以用一个灰色的方框作为干扰,在图片中进行滑动遍历,看看当灰色方框移动到什么位置的时候,模型识别出正确答案的概率比较低,哪里就是模型做出决策的主要依据。
比如下面的第一张图,灰色方框位于狗狗的脸处时,模型识别出狗狗的概率最低,位于其他位置时,模型仍然可以大概率识别出狗狗,所以模型是根据狗狗的脸去判断的,而不是看到了地板或、墙壁或者玩具球才觉得图片中的是狗,这就成为了一个解释!
还有一个办法,以图像为例,我们可以对某一个像素点做微小调整 a a a,设模型的输出变化为 b b b,那么这个像素的重要程度可以用 ∣ a b ∣ |\frac{a}{b}| ∣ba∣ 表示,如下图所示,表明模型是真的看到了狗、猴、牛才做出的判断。
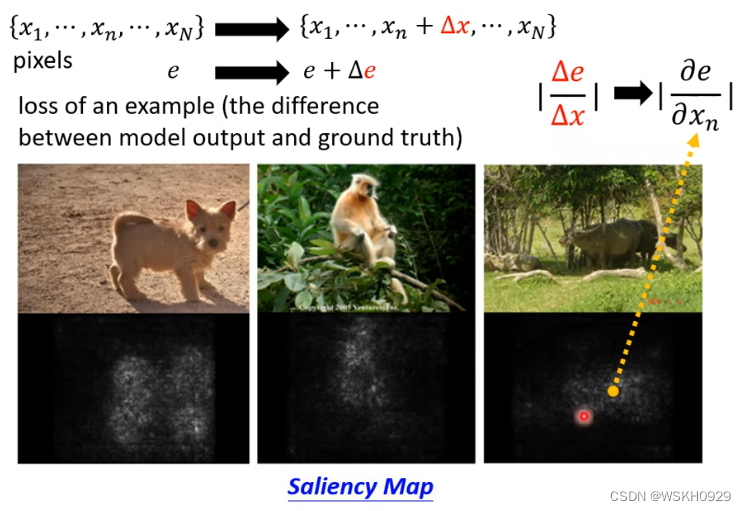
下面看一个实际例子:数码宝贝和宝可梦的识别(二元分类)

大家可以试一下,根据下图的6个训练资料,能不能认出Testing Image是属于宝可梦还是数码宝贝(答案是很难识别出来!)

人类都很难识别,那么机器的识别结果如何呢,有人做了实验,实验结果是非常不可思议的,模型在测试集上的识别率居然高达98%!

所以,我们迫不及待地想知道,机器是如何识别的。
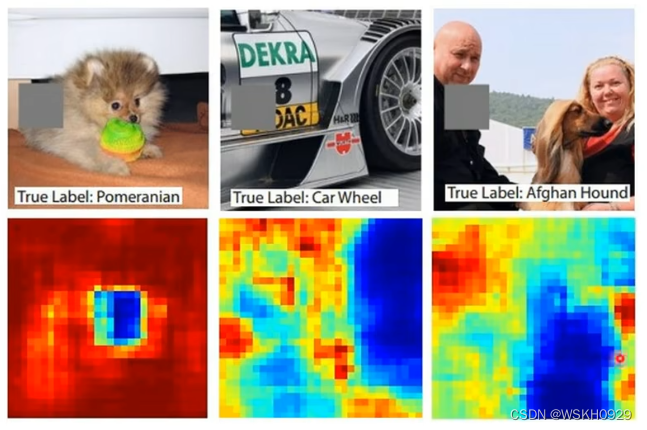
根据前面介绍的,我们可以绘制出每个测试图像的 Saliency Map ,看看机器是根据什么特征识别出宝可梦和数码宝贝的,结果很奇怪,机器认为重要的特征都完美地避开了宝可梦和数码宝贝的本体,也就是说,机器靠看背景就能很高正确率地识别出来。

这是为啥?原来是因为宝可梦数据集(PNG)和数码宝贝数据集(JPEG)的图片格式不一样,PNG图像的背景是黑色的。和JPEG有很大差别,所以机器靠着识别背景,就能得到很高的正确率

再举一个真实的例子,有一个识别马很准确的模型,当绘制出 Saliency Map 之后,才发现模型是根据左下角的一个网站标识认出的马(因为训练所用的数据集大部分有马的图片都是在该网站上找的)

当然,有时候绘制出来的 Saliency Map 可能会带有很多杂讯,如下图中间所示。我们可以为原始图像添加噪声然后用加了噪声后的图计算 Saliency Map;进行N次这样的操作就得到了 N 个 Saliency Map,最后再将他们求平均,得到最终的平滑后的 Saliency Map!

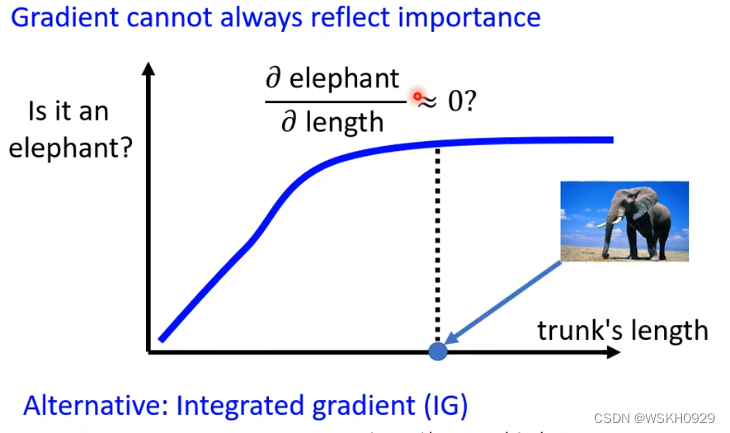
我们知道,鼻子长度是判断是否为大象的重要特征,在一定范围内时,鼻子越长,越有可能时大象,但当鼻子长度超出这个范围,那么它是大象的概率也不会增大了。在超出一定范围时,鼻子长度可能会被认为是不重要的特征,这是不符合常理的。
所以,光看一个特征的偏微分,也许不能判断它是否重要
一个解决的方案就是 Integrated Gradient(IG)
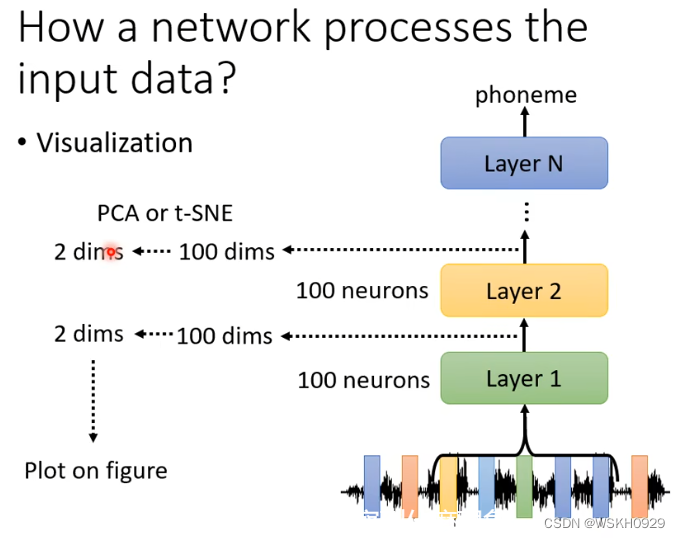
4.1.2 模型怎么处理数据的?
4.1.2.1 可视化
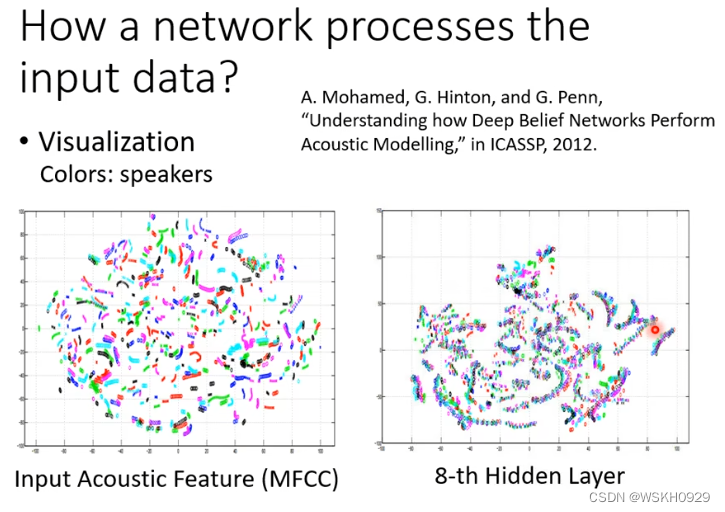
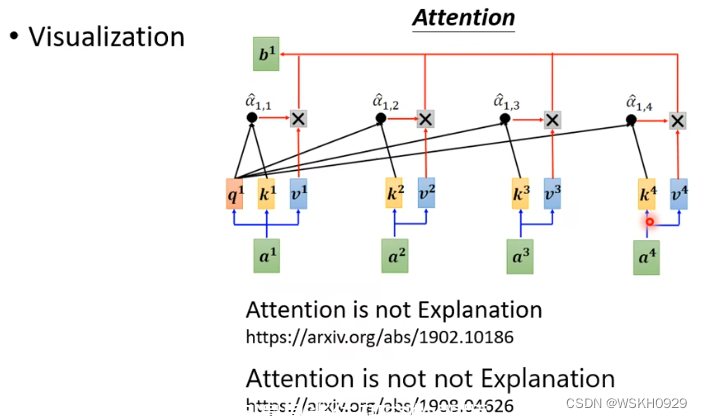
如下图所示,在语音辨识的例子里,在神经网络的每一层可能有100维的向量,维度太高不好可视化,我们可以将其降维(PCA或者其他方法),降到2维就好可视化了
从下面的例子中我们可以看出,经过了8层的网络之后,不同人说的相同内容的句子,模型可以把他们识别出来并聚在一起
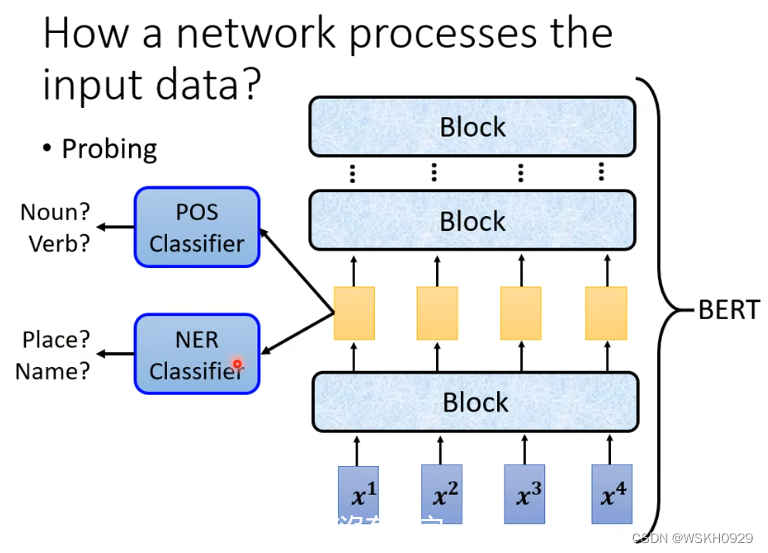
4.1.2.2 Probing 探针
可视化观察模型学到了什么的方法很有局限性,因为我们在降维的过程中就已经损失掉了一些精度,并且肉眼观察也很难看出什么猫腻。
所以,就有了Probing 探针技术
我们可以创建一个独立的分类器,把网络某一层的输出作为它的训练资料,如果用该层的输出训练出来的分类器正确率很高,则说明该层具有很多有用的资讯
当然,有时候也要注意分类器的强度,正确率不高也可能是分类器太弱或者学习率没有调好等等原因导致的
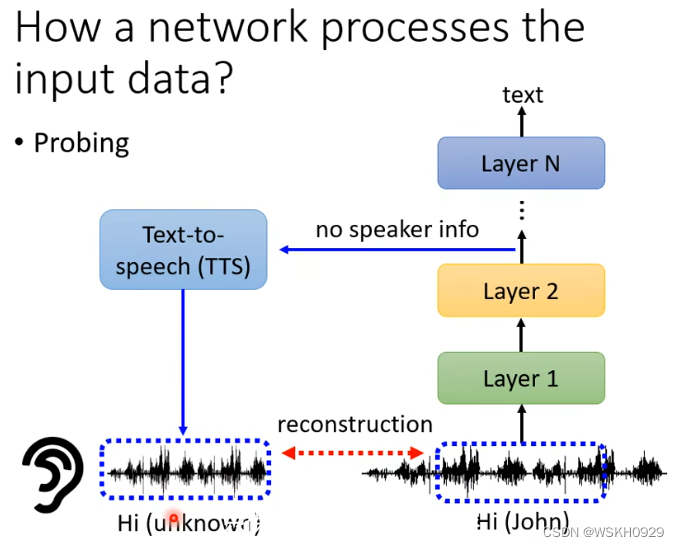
当然,探针不一定要是分类器,如下图所示,探针是一个语音合成模型,它尝试吃被探测网络某一层的输出,目标是尽可能还原被探测网络最原始的输出。
显然,如果还原率越高,说明该层保留的咨询就越多。
有时候可能合成出来的语音准确的复现了源语音的内容,但是音色已经听不出来是谁了,说明被探测网络主要是通过提出语音内容的手段进行预测,这就为模型提供了一种解释
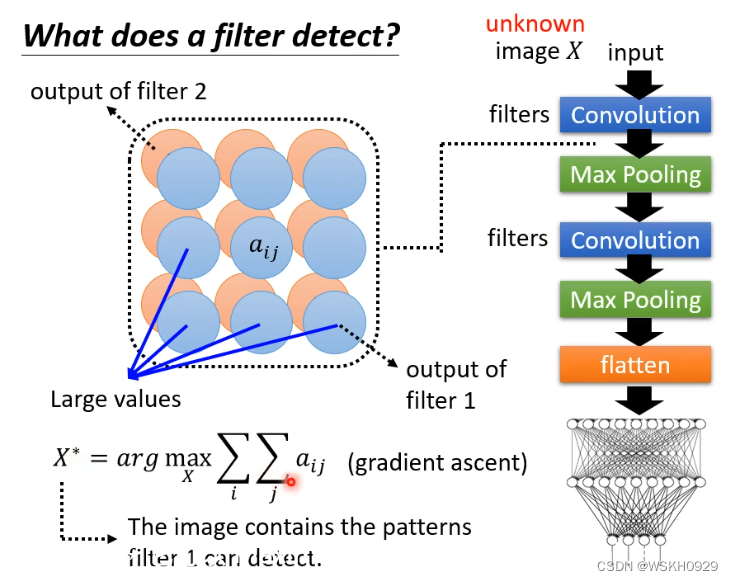
4.2 Global Explanation 全局的解释
如下图所示,假设已经有一个训练好的网络模型CNN
如果我们想知道这个CNN模型是怎么判断一张未知图片是否为猫的,那么可以找到它的任意一个卷积层(你想解释哪一层就找哪一层)
然后对于该卷积层的每一个 filter,都尝试找到一张图片 X,使得 X 经过 filter 之后得到的矩阵综合最大(可以用梯度上升法找这个X)
假设已经有了一个手写数字识别模型,用上面介绍的方法,我们可以得到下图所示的 X 集合,从中我们可以推测,如果将手写数字看为一些笔画的组合,那么模型卷积层的一些 filter 负责识别垂直的笔画,一些 filter 负责识别斜的笔画

但是,有些时候,按照这种方法提取出来的 X 很可能是人类看不出规律的,如下图所示
这不是令人惊讶的,因为我们学过恶意攻击就知道,给图片加上一点人类看不到的杂讯,就足以使得模型输出完全不同的结果,所以深层模型看到的东西往往是抽象、人类难以理解的

但是我想看到比较像数字的结果应该怎么办呢?一个简单粗暴的办法就是,对 X 施加一些限制,如下图所示,我们在最大化 sum(y) 的同时,也要最小化 X 中的像素总和,也就是用尽可能少的白点描述图像,这样有利于提高 X 的可解释性

当然,如果你想得到非常想数字的 X ,可以参考下面的论文,他调了很多参数,做了很多限制,才得到了下图的 X,可以明显看出丹顶鹤的轮廓
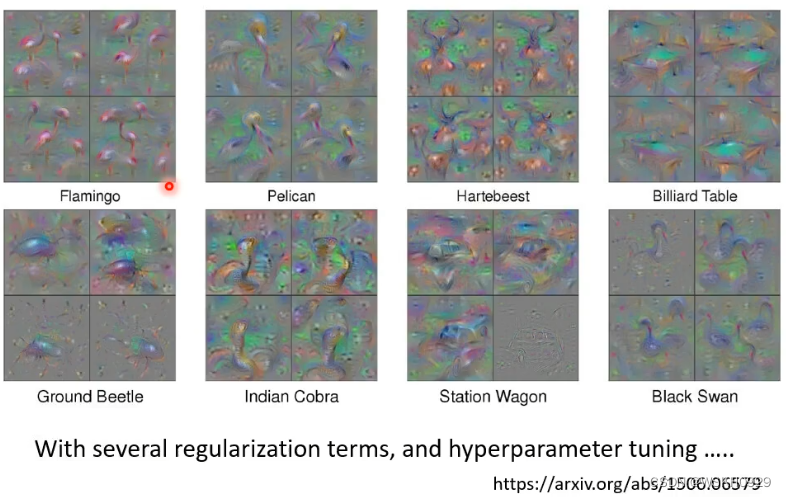
我们也可以借助生成式网络来生成 X
如下图所示,假设有一个生成式网络G,我们可以给一组可训练的参数z,传入G得到X,然后再将X传入图像分类器CNN模型,目标是图像分类器给出的置信分数越高越好,此时最优的z称为z*,对应的X可以通过G(z)得到。
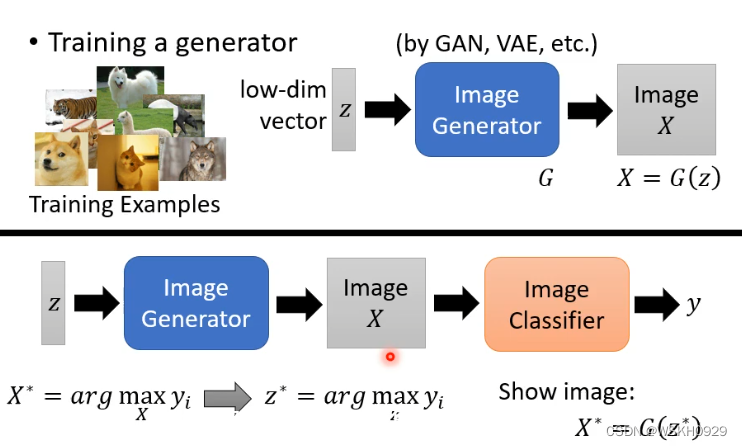
下面是通过生成式网络生成的X的示意图,都非常形象逼真!

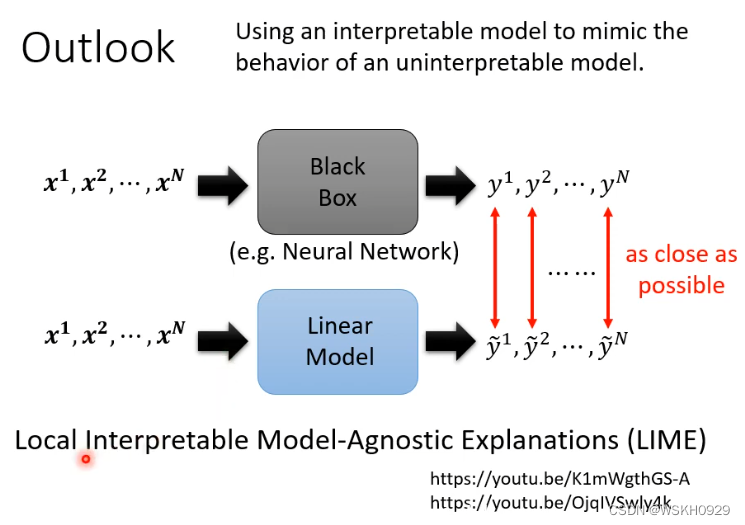
还有另外的方法如下图所示,我们可以用一个简单的容易解释的线性模型去模仿难以解释的深度模型,例如,我们给定同样的输入,目标是线性模型的输出和深度模型的输出越接近越好,以此训练出来的线性模型就会模仿深度模型,进而我们可以通过分析线性模型达到解释深度模型的效果
但是直接用线性模型模仿整个深度模型肯定是很难的,所以一般我们只用线性模型模仿深度模型的一部分,比如只对CNN的前两层进行模仿,这样就比较容易模仿,也容易解释
智能推荐
解决win10/win8/8.1 64位操作系统MT65xx preloader线刷驱动无法安装_mt65驱动-程序员宅基地
文章浏览阅读1.3w次。转载自 http://www.miui.com/thread-2003672-1-1.html 当手机在刷错包或者误修改删除系统文件后会出现无法开机或者是移动定制(联通合约机)版想刷标准版,这时就会用到线刷,首先就是安装线刷驱动。 在XP和win7上线刷是比较方便的,用那个驱动自动安装版,直接就可以安装好,完成线刷。不过现在也有好多机友换成了win8/8.1系统,再使用这个_mt65驱动
SonarQube简介及客户端集成_sonar的客户端区别-程序员宅基地
文章浏览阅读1k次。SonarQube是一个代码质量管理平台,可以扫描监测代码并给出质量评价及修改建议,通过插件机制支持25+中开发语言,可以很容易与gradle\maven\jenkins等工具进行集成,是非常流行的代码质量管控平台。通CheckStyle、findbugs等工具定位不同,SonarQube定位于平台,有完善的管理机制及强大的管理页面,并通过插件支持checkstyle及findbugs等既有的流..._sonar的客户端区别
元学习系列(六):神经图灵机详细分析_神经图灵机方法改进-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏27次。神经图灵机是LSTM、GRU的改进版本,本质上依然包含一个外部记忆结构、可对记忆进行读写操作,主要针对读写操作进行了改进,或者说提出了一种新的读写操作思路。神经图灵机之所以叫这个名字是因为它通过深度学习模型模拟了图灵机,但是我觉得如果先去介绍图灵机的概念,就会搞得很混乱,所以这里主要从神经图灵机改进了LSTM的哪些方面入手进行讲解,同时,由于模型的结构比较复杂,为了让思路更清晰,这次也会分开几..._神经图灵机方法改进
【机器学习】机器学习模型迭代方法(Python)-程序员宅基地
文章浏览阅读2.8k次。一、模型迭代方法机器学习模型在实际应用的场景,通常要根据新增的数据下进行模型的迭代,常见的模型迭代方法有以下几种:1、全量数据重新训练一个模型,直接合并历史训练数据与新增的数据,模型直接离线学习全量数据,学习得到一个全新的模型。优缺点:这也是实际最为常见的模型迭代方式,通常模型效果也是最好的,但这样模型迭代比较耗时,资源耗费比较多,实时性较差,特别是在大数据场景更为困难;2、模型融合的方法,将旧模..._模型迭代
base64图片打成Zip包上传,以及服务端解压的简单实现_base64可以装换zip吗-程序员宅基地
文章浏览阅读2.3k次。1、前言上传图片一般采用异步上传的方式,但是异步上传带来不好的地方,就如果图片有改变或者删除,图片服务器端就会造成浪费。所以有时候就会和参数同步提交。笔者喜欢base64图片一起上传,但是图片过多时就会出现数据丢失等异常。因为tomcat的post请求默认是2M的长度限制。2、解决办法有两种:① 修改tomcat的servel.xml的配置文件,设置 maxPostSize=..._base64可以装换zip吗
Opencv自然场景文本识别系统(源码&教程)_opencv自然场景实时识别文字-程序员宅基地
文章浏览阅读1k次,点赞17次,收藏22次。Opencv自然场景文本识别系统(源码&教程)_opencv自然场景实时识别文字
随便推点
ESXi 快速复制虚拟机脚本_exsi6.7快速克隆centos-程序员宅基地
文章浏览阅读1.3k次。拷贝虚拟机文件时间比较长,因为虚拟机 flat 文件很大,所以要等。脚本完成后,以复制虚拟机文件夹。将以下脚本内容写入文件。_exsi6.7快速克隆centos
好友推荐—基于关系的java和spark代码实现_本关任务:使用 spark core 知识完成 " 好友推荐 " 的程序。-程序员宅基地
文章浏览阅读2k次。本文主要实现基于二度好友的推荐。数学公式参考于:http://blog.csdn.net/qq_14950717/article/details/52197565测试数据为自己随手画的关系图把图片整理成文本信息如下:a b c d e f yb c a f gc a b dd c a e h q re f h d af e a b gg h f bh e g i di j m n ..._本关任务:使用 spark core 知识完成 " 好友推荐 " 的程序。
南京大学-高级程序设计复习总结_南京大学高级程序设计-程序员宅基地
文章浏览阅读367次。南京大学高级程序设计期末复习总结,c++面向对象编程_南京大学高级程序设计
4.朴素贝叶斯分类器实现-matlab_朴素贝叶斯 matlab训练和测试输出-程序员宅基地
文章浏览阅读3.1k次,点赞2次,收藏12次。实现朴素贝叶斯分类器,并且根据李航《统计机器学习》第四章提供的数据训练与测试,结果与书中一致分别实现了朴素贝叶斯以及带有laplace平滑的朴素贝叶斯%书中例题实现朴素贝叶斯%特征1的取值集合A1=[1;2;3];%特征2的取值集合A2=[4;5;6];%S M LAValues={A1;A2};%Y的取值集合YValue=[-1;1];%数据集和T=[ 1,4,-1;..._朴素贝叶斯 matlab训练和测试输出
Markdown 文本换行_markdowntext 换行-程序员宅基地
文章浏览阅读1.6k次。Markdown 文本换行_markdowntext 换行
错误:0xC0000022 在运行 Microsoft Windows 非核心版本的计算机上,运行”slui.exe 0x2a 0xC0000022″以显示错误文本_错误: 0xc0000022 在运行 microsoft windows 非核心版本的计算机上,运行-程序员宅基地
文章浏览阅读6.7w次,点赞2次,收藏37次。win10 2016长期服务版激活错误解决方法:打开“注册表编辑器”;(Windows + R然后输入Regedit)修改SkipRearm的值为1:(在HKEY_LOCAL_MACHINE–》SOFTWARE–》Microsoft–》Windows NT–》CurrentVersion–》SoftwareProtectionPlatform里面,将SkipRearm的值修改为1)重..._错误: 0xc0000022 在运行 microsoft windows 非核心版本的计算机上,运行“slui.ex