用limma包的voom方法来做RNA-seq 差异分析_limma voom-程序员宅基地
用limma包的voom方法来做RNA-seq 差异分析
大家都知道,这十几年来最流行的差异分析软件就是R的limma包了,但是它以前只支持microarray的表达数据。
考虑到大家都熟悉了它,它又发了一个voom的方法,让它从此支持RNA-seq的count数据啦!
大家都知道芯片数据跟RNA-seq数据的本质就是value的分布不一样,所以各种针对RNA-seq的差异分析包也就是提出来一个新的normalization方法而已。
而我们limma本身就提出了一个voom的方法来对RNA-seq数据进行normalization
使用这个包也需要三个数据:
表达矩阵
分组矩阵
差异比较矩阵
用法与limma一模一样的,只是多了一个normalization而已。
读取自己的数据
一般我们会自己读取表达矩阵和分组信息,下面是一个例子:
options(warn=-1)
suppressMessages(library(DESeq2))
suppressMessages(library(limma))
suppressMessages(library(pasilla))
data(pasillaGenes)
exprSet=counts(pasillaGenes)
head(exprSet) ##表达矩阵如下
## treated1fb treated2fb treated3fb untreated1fb untreated2fb
## FBgn0000003 0 0 1 0 0
## FBgn0000008 78 46 43 47 89
## FBgn0000014 2 0 0 0 0
## FBgn0000015 1 0 1 0 1
## FBgn0000017 3187 1672 1859 2445 4615
## FBgn0000018 369 150 176 288 383
## untreated3fb untreated4fb
## FBgn0000003 0 0
## FBgn0000008 53 27
## FBgn0000014 1 0
## FBgn0000015 1 2
## FBgn0000017 2063 1711
## FBgn0000018 135 174
(group_list=pasillaGenes$condition)
## [1] treated treated treated untreated untreated untreated untreated
## Levels: treated untreated
##这是分组信息,7个样本,3个处理的,4个未处理的对照!
另外一个例子是从airway里面得到表达矩阵和分组信息
library(airway)
data(airway)
exprSet=assays(airway)$counts ## 表达矩阵
group_list=colData(airway)$dex ## 分组信息
第一步:构建分组矩阵
suppressMessages(library(limma))
design <- model.matrix(~factor(group_list))
colnames(design)=levels(factor(group_list))
rownames(design)=colnames(exprSet)
design
## treated untreated
## treated1fb 1 0
## treated2fb 1 0
## treated3fb 1 0
## untreated1fb 1 1
## untreated2fb 1 1
## untreated3fb 1 1
## untreated4fb 1 1
## attr(,"assign")
## [1] 0 1
## attr(,"contrasts")
## attr(,"contrasts")$`factor(group_list)`
## [1] "contr.treatment"
第二步:根据分组信息和表达矩阵进行normalization
这里构建了一个对象 An object of class “EList”
v <- voom(exprSet,design,normalize="quantile")
## 下面的代码如果你不感兴趣不需要运行,免得误导你
## 就是看看normalization前面的数据分布差异
#png("RAWvsNORM.png")
exprSet_new=v$E
par(cex = 0.7)
n.sample=ncol(exprSet)
if(n.sample>40) par(cex = 0.5)
cols <- rainbow(n.sample*1.2)
par(mfrow=c(2,2))
boxplot(exprSet, col = cols,main="expression value",las=2)
boxplot(exprSet_new, col = cols,main="expression value",las=2)
hist(exprSet)
hist(exprSet_new)
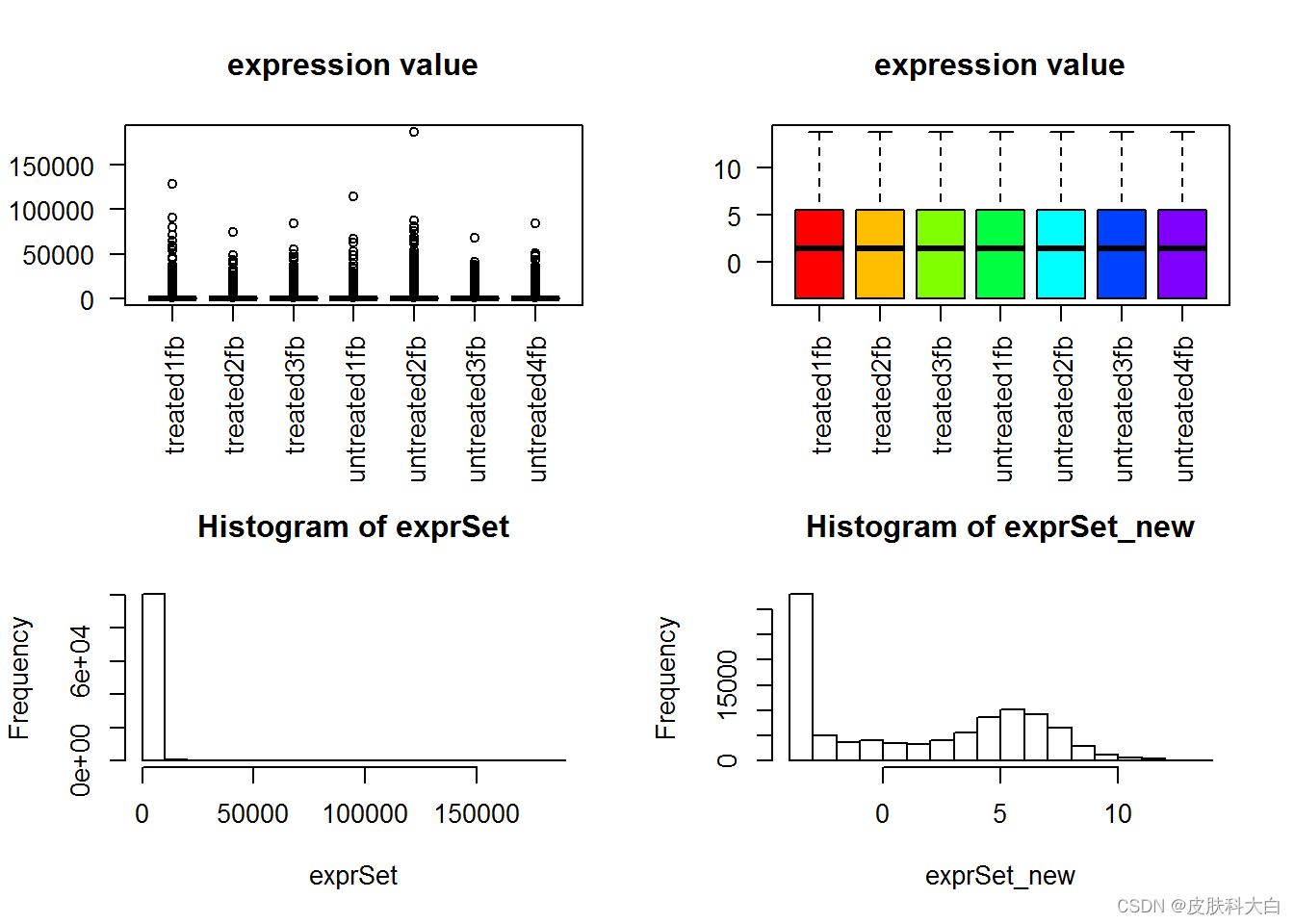
#dev.off()
可以很明显看到normalization前后数据分布差异非常大!
第三步:做差异分析,提取差异分析结果 这里不需要差异比较矩阵了,因为我的分组矩阵表明样本就分成两组,直接提取coef=2的数据即可
fit <- lmFit(v,design)
fit2 <- eBayes(fit)
tempOutput = topTable(fit2, coef=2, n=Inf)
DEG_voom = na.omit(tempOutput)
head(DEG_voom)
## logFC AveExpr t P.Value adj.P.Val
## FBgn0029167 2.1608689 7.880589 41.19142 5.195806e-08 0.0007518331
## FBgn0003137 -0.9560776 8.421903 -29.97211 2.920473e-07 0.0021129620
## FBgn0003748 -1.0385933 6.395990 -23.78787 1.020682e-06 0.0049230892
## FBgn0035085 2.5190255 5.221183 21.01339 1.993995e-06 0.0058809216
## FBgn0050185 -0.4886279 5.487547 -19.95422 2.635106e-06 0.0058809216
## FBgn0015568 -1.1040979 3.922438 -19.96954 2.624231e-06 0.0058809216
## B
## FBgn0029167 9.065020
## FBgn0003137 7.800063
## FBgn0003748 6.652695
## FBgn0035085 5.870585
## FBgn0050185 5.734162
## FBgn0015568 5.557560
差异分析结果就不解释啦!
智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范