数据结构和算法——Huffman树和Huffman编码详解_huffman树,huffman编码-程序员宅基地
技术标签: algorithm
Huffman树是一种特殊结构的二叉树,由Huffman树设计的二进制前缀编码,也称为Huffman编码在通信领域有着广泛的应用。在word2vec模型中,在构建层次Softmax的过程中,也使用到了Huffman树的知识。
在通信中,需要将传输的文字转换成二进制的字符串,假设传输的报文为:“AFTERDATAEARAREARTAREA”,现在需要对该报文进行编码。
一、Huffman树的基本概念
在二叉树中有一些基本的概念,对于如下所示的二叉树:
- 路径
路径是指在一棵树中,从一个节点到另一个节点之间的分支构成的通路,如从节点8到节点1的路径如下图所示:
- 路径长度
路径长度指的是路径上分支的数目,在上图中,路径长度为2。
- 节点的权
节点的权指的是为树中的每一个节点赋予的一个非负的值,如上图中每一个节点中的值。
- 节点的带权路径长度
节点的带权路径长度指的是从根节点到该节点之间的路径长度与该节点权的乘积:如对于1节点的带权路径长度为:2。
- 树的带权路径长度
树的带权路径长度指的是所有叶子节点的带权路径长度之和。
有了如上的概念,对于Huffman树,其定义为:
给定nn个叶子节点,构造一棵二叉树,若这棵二叉树的带权路径长度达到最小,则称这样的二叉树为最优二叉树,也称为Huffman树。
由以上的定义可以知道,Huffman树是带权路径长度最小的二叉树,对于上面的二叉树,其构造完成的Huffman树为:
二、Huffman树的构建
由上述的Huffman树可知:节点的权越小,其离树的根节点越远。那么应该如何构建Huffman树呢?以上述报文为例,首先需要统计出每个字符出现的次数作为节点的权:
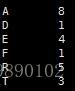
接下来构建Huffman树:
- 重复以下的步骤:
- 按照权值对每一个节点排序:D-F-T-E-R-A
- 选择权值最小的两个节点,此处为D和F生成新的节点,节点的权重为这两个节点的权重之和,为2
- 直到只剩最后的根节点
按照上述的步骤,该报文的Huffman树的生成过程为:
对于树中节点的结构为:
#define LEN 512
struct huffman_node{
char c;
int weight;
char huffman_code[LEN];
huffman_node * left;
huffman_node * right;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
对于Huffman树的构建过程为:
int huffman_tree_create(huffman_node *&root, map<char, int> &word){
char line[MAX_LINE];
vector<huffman_node *> huffman_tree_node;
map<char, int>::iterator it_t;
for (it_t = word.begin(); it_t != word.end(); it_t++){
// 为每一个节点申请空间
huffman_node *node = (huffman_node *)malloc(sizeof(huffman_node));
node->c = it_t->first;
node->weight = it_t->second;
node->left = NULL;
node->right = NULL;
huffman_tree_node.push_back(node);
}
// 开始从叶节点开始构建Huffman树
while (huffman_tree_node.size() > 0){
// 按照weight升序排序
sort(huffman_tree_node.begin(), huffman_tree_node.end(), sort_by_weight);
// 取出前两个节点
if (huffman_tree_node.size() == 1){
// 只有一个根结点
root = huffman_tree_node[0];
huffman_tree_node.erase(huffman_tree_node.begin());
}else{
// 取出前两个
huffman_node *node_1 = huffman_tree_node[0];
huffman_node *node_2 = huffman_tree_node[1];
// 删除
huffman_tree_node.erase(huffman_tree_node.begin());
huffman_tree_node.erase(huffman_tree_node.begin());
// 生成新的节点
huffman_node *node = (huffman_node *)malloc(sizeof(huffman_node));
node->weight = node_1->weight + node_2->weight;
(node_1->weight < node_2->weight)?(node->left=node_1,node->right=node_2):(node->left=node_2,node->right=node_1);
huffman_tree_node.push_back(node);
}
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
其中,map结构的word为每一个字符出现的频率,是从文件中解析出来的,解析的代码为:
int read_file(FILE *fn, map<char, int> &word){
if (fn == NULL) return 1;
char line[MAX_LINE];
while (fgets(line, 1024, fn)){
fprintf(stderr, "%s\n", line);
//解析,统计词频
char *p = line;
while (*p != '\0' && *p != '\n'){
map<char, int>::iterator it = word.find(*p);
if (it == word.end()){
// 不存在,插入
word.insert(make_pair(*p, 1));
}else{
it->second ++;
}
p ++;
}
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
当构建好Huffman树后,我们分别利用先序遍历和中序遍历去遍历Huffman树,先序遍历的代码为:
void print_huffman_pre(huffman_node *node){
if (node != NULL){
fprintf(stderr, "%c\t%d\n", node->c, node->weight);
print_huffman_pre(node->left);
print_huffman_pre(node->right);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
中序遍历的代码为:
void print_huffman_in(huffman_node *node){
if (node != NULL){
print_huffman_in(node->left);
fprintf(stderr, "%c\t%d\n", node->c, node->weight);
print_huffman_in(node->right);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
得到的结构与上图中的结构一致。
三、由Huffman树生成Huffman编码
有了上述的Huffman树的结构,现在我们需要利用Huffman树对每一个字符编码,该编码又称为Huffman编码,Huffman编码是一种前缀编码,即一个字符的编码不是另一个字符编码的前缀。在这里约定:
- 将权值小的最为左节点,权值大的作为右节点
- 左孩子编码为0,右孩子编码为1
因此,上述的编码形式如下图所示:
从上图中,E节点的编码为:00,同理,D节点的编码为1001
Huffman编码的实现过程为:
int get_huffman_code(huffman_node *&node){
if (node == NULL) return 1;
// 利用层次遍历,构造每一个节点
huffman_node *p = node;
queue<huffman_node *> q;
q.push(p);
while(q.size() > 0){
p = q.front();
q.pop();
if (p->left != NULL){
q.push(p->left);
strcpy((p->left)->huffman_code, p->huffman_code);
char *ptr = (p->left)->huffman_code;
while (*ptr != '\0'){
ptr ++;
}
*ptr = '0';
}
if (p->right != NULL){
q.push(p->right);
strcpy((p->right)->huffman_code, p->huffman_code);
char *ptr = (p->right)->huffman_code;
while (*ptr != '\0'){
ptr ++;
}
*ptr = '1';
}
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
利用上述的代码,测试的主函数为:
int main(){
// 读文件
FILE *fn = fopen("huffman", "r");
huffman_node *root = NULL;
map<char, int> word;
read_file(fn, word);
huffman_tree_create(root, word);
fclose(fn);
fprintf(stderr, "pre-order:\n");
print_huffman_pre(root);
fprintf(stderr, "in-order:\n");
print_huffman_in(root);
get_huffman_code(root);
fprintf(stderr, "the final result:\n");
print_leaf(root);
destory_huffman_tree(root);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
print_leaf函数用于打印出每个叶节点的Huffman编码,其具体实现为:
void print_leaf(huffman_node *node){
if (node != NULL){
print_leaf(node->left);
if (node->left == NULL && node->right == NULL) fprintf(stderr, "%c\t%s\n", node->c, node->huffman_code);
print_leaf(node->right);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
destory_huffman_tree函数用于销毁Huffman树,其具体实现为:
void destory_huffman_tree(huffman_node *node){
if (node != NULL){
destory_huffman_tree(node->left);
destory_huffman_tree(node->right);
free(node);
node = NULL;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
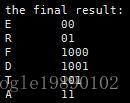
其最终的结果为:
参考文献
- 《大话数据结构》
- 《数据结构》(C语言版)
智能推荐
Windows下kafka生成消费者报错:Missing required argument “[zookeeper]“_missing required argument "[zookeeper]-程序员宅基地
文章浏览阅读4.3k次。.\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic kafka-test-topic --from-beginning上面的语句就是在Windos下 kafka生成消费者的命令行,这命令行是我从百度上找的,但一直是报错。仔细看报错是缺少一个参数–zookeeper,然后我W3Cshool关于kafka的教程上看到Linux系统下生成消费者的命令行。如下:bin/kafka-console-consumer.sh._missing required argument "[zookeeper]
Qt Creator中,include路径包含过程(或如何找到对应的头文件)_qt include路径-程序员宅基地
文章浏览阅读5.9w次,点赞11次,收藏29次。Qt Creator中,include路径包含过程(或如何找到对应的头文件)利用Qt Creator开发程序时,需要包含利用#include来添加头文件。大家都知道,#include 对于后者,路径比较直观,容易理解。如#include "lyc/daniel.h",路径在当前目录的lyc文件夹下。(文件包含是可以嵌套的。)下面重点追溯一下Qt的标准库头文件的路径包含情况。_qt include路径
Fortify代码扫描问题及修复_input validation and representation-程序员宅基地
文章浏览阅读1.6w次,点赞8次,收藏39次。静态代码扫描常见问题及修复风险类型原因Code Correctness: Erroneous String Compare字符串的对比使用错误方法Cross-Site ScriptingWeb浏览器发送非法数据,导致浏览器执行恶意代码Dead Code: Expression is Always true表达式的判断总是trueDead Code: Unused Method没有使用的方法HTTP Response Splitting含有未验证的数据_input validation and representation
探索Svelte SVG Patterns:创新SVG图案生成器-程序员宅基地
文章浏览阅读278次,点赞4次,收藏9次。探索Svelte SVG Patterns:创新SVG图案生成器项目地址:https://gitcode.com/catchspider2002/svelte-svg-patterns该项目[[链接]][1]是一个基于Svelte框架构建的SVG图案生成工具,由开发者catchspider2002维护。它允许用户通过简单的交互式界面创建独特且可自定义的SVG图案,这些图案可以用于网页背景、图标...
光场深度估计(Light Field Depth Estimation)-程序员宅基地
文章浏览阅读1.8w次,点赞23次,收藏94次。本文将介绍光场领域进行深度估计的相关研究。In this post, I’ll introduce some depth estimation algorithms using Light field information. Here is some of the code.研究生阶段的研究方向是光场深度信息的恢复。再此做一些总结,以便于让大家了解光场数据处理的一般步骤以及深度估计的相关..._光场深度估计
CSS3 column 分栏-程序员宅基地
文章浏览阅读68次。column的布局形式还没有使用过,后续的bug和解决方案有待检验。columncolumn-count:number; 设置内容分为多少栏显示column-width:长度单位;设置每一栏的宽度而不设定元素的宽度column-gap:长度单位;设置多栏之间的间隔距离column-rule:宽度,颜色;在栏与栏之间增加一条间隔线。类似border.column-spa..._h5 column-span
随便推点
VM虚拟机安装Windows XP Service Pack 3 (x86)_windows_xp_professional_with_service_pack_3_x86-程序员宅基地
文章浏览阅读2.9k次,点赞2次,收藏3次。Windows版本 Windows XP发行于2001年10月25日,于2014年4月8日停止支持,XP取自Experience。Windows 7发行于2009年10月22日。 Windows XP Service Pack 3 (x86):SP(service pack)是指服务补丁包,01年发布的XP不带补丁,第一次补丁版本叫SP2,14年最后一个补丁版本叫SP3。下载ISO 操作系统站:https://msdn.itellyou.cn/。值得一提,MSDN是原装系统,跟ghost系统_windows_xp_professional_with_service_pack_3_x86
vue-cli指定版本安装_vue-cli-service 选哪个版本-程序员宅基地
文章浏览阅读1.2w次,点赞16次,收藏32次。安装新的版本前,需要先把之前安装的版本卸载掉。vue卸载:npm uninstall vue-cli -g(3.0以下版本卸载)npm uninstall -g @vue/cli(3.0以上版本卸载)vue安装:npm install -g @vue/cli (安装的是最新版)npm install [email protected] (指定版本安装【指定版本为3.0以下版本】,其中2.9.6为版本号)npm install -g @vue/[email protected](指定版本安装【指定版本为3.0以上版本】,_vue-cli-service 选哪个版本
Verilog SPI-Flash读写总线控制模块_qspi flash verilog-程序员宅基地
文章浏览阅读3.6k次,点赞2次,收藏59次。`timescale 1ns / 1ps//////////////////////////////////////////////////////////////////////////////////// Company: // Engineer: // // Create Date: 2019/11/26 11:55:56// Design Name: // Module Name: spi_driver// Project Name: // Target Devices: //._qspi flash verilog
Python实例1:题目:有1、2、3、4个数字,能组成多少个互不相同且无重复数字的三位数?都是多少?_pycharm有1、2、3、4个数字,能组成多少个互不相同且无重复数字的三位数?都是多少?-程序员宅基地
文章浏览阅读1w次,点赞6次,收藏29次。这是一个相对比较简单的数学题,首先我们先对题目进行分析分析:三位数,个位、十位、百位分别都可以是1、2、3、4这四个数字,但要求互不相同且无重复,就要求个位不等于十位,个位不等于百位,十位不等于百位分析完毕后,我们可以就可以开始编写代码了!方法1:首先是相对比较基础的,利用for循环嵌套附加if判断筛选实现i = 0for x in range(1, 5): for y in range(1, 5): for z in range(1, 5): _pycharm有1、2、3、4个数字,能组成多少个互不相同且无重复数字的三位数?都是多少?
Android 中常用的跨进程通信和跨线程通信方法总结_android 跨线程消息-程序员宅基地
文章浏览阅读708次。优点:简化了线程间通信:EventBus提供了一种简单的方式来进行线程间通信,开发人员无需手动处理线程切换和消息传递的细节。松耦合的组件通信:通过EventBus,组件之间可以进行松耦合的通信,发送者和接收者之间没有直接的依赖关系。线程切换方便:EventBus允许在发布事件时指定事件的接收线程,从而方便地在不同线程之间切换。1.优点:网络通信能力:Socket通信可以在网络层面上进行进程间通信,适用于跨网络的通信需求。有多个进程和线程就会涉及到跨进程通信或跨线程通信,用户状态同步,UI刷新等。_android 跨线程消息
vue2(vue-cli3x[vue.config.js])使用cesium配置过程_vue2中使用cesium,vue.config.js-程序员宅基地
文章浏览阅读1.7k次。vue-cli3x中vue.config.js配置cesium环境_vue2中使用cesium,vue.config.js