DBA-MySql面试问题及答案-上_mysql dba 面试题-程序员宅基地
文章目录
-
-
- 1.什么是数据库?
- 2.如何查看某个操作的语法?
- 3.MySql的存储引擎有哪些?
- 4.常用的2种存储引擎?
- 6.可以针对表设置引擎吗?如何设置?
- 6.选择合适的存储引擎?
- 7.选择合适的数据类型
- 8.char & varchar
- 9.Mysql字符集
- 10.如何选择字符集?
- 11.什么是索引?
- 12.索引设计原则?
- 13.MySql有哪些索引?
- 14.Hash索引和B+树索引的底层实现原理:
- 15. 非聚簇索引一定会回表查询吗?
- 16.如何查询最后一行记录?
- 17.MySQL自增id不连续问题?
- 18.sql注入问题?
- 19.什么是3NF(范式)?
- 20. NULL和空串判断?
- 21.什么是事务?
- 22.事务4个特性?
- 23.事务隔离级别分别是?
- 24.InnoDB默认事务隔离级别?如何查看当前隔离级别
- 25.什么是锁?
- 26.死锁?
- 27.如何处理死锁?
- 28.如何创建用户?授权?
- 29.如何查看表结构?
- 30.Mysql删除表的几种方式?区别?
- 31.like走索引吗?
- 32.什么是回表?
- 33.如何避免回表?
- 34.索引覆盖是什么?
- 35.视图的优缺点?
- 36.主键和唯一索引区别?
- 37.如何随机获取一条记录?
- 38.Mysql中的数值类型?
- 39.查看当前表有哪些索引?
- 40.索引不生效的情况?
- 41.MVVC?
- 42.sql语句的执行流程?
- 43.如何获取select 语句执行计划?
- 44.explain列有哪些?含义?
- 45.MySql最多创建多少列索引?
- 46.为什么最好建立一个主键?
- 47.**字段为什么要求建议为not null?**
- 48.**varchar(10)和int(10)代表什么含义**
- 49.视图是什么?对比普通表优势?
- 50.count(*)在不同引擎的实现方式?
-
1.什么是数据库?
数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
2.如何查看某个操作的语法?
比如看建表的语法:
mysql> ? create table
Name: 'CREATE TABLE'
Description:
Syntax:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,…)
[table_options]
[partition_options]
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
[(create_definition,…)]
[table_options]
[partition_options]
[IGNORE | REPLACE]
[AS] query_expression
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
3.MySql的存储引擎有哪些?
MyISAM、 InnoDB、BDB、MEMORY、MERGE、EXAMPLE、NDB Cluster、 ARCHIVE、CSV、BLACKHOLE、FEDERATED。
Tips:InnoDB和BDB提供事务安全表,其他存储引擎都是非事务安全表。
4.常用的2种存储引擎?
1.Myisam是Mysql的默认存储引擎,当create创建新表时,未指定新表的存储引擎时,默认使用Myisam。
每个MyISAM 在磁盘上存储成三个文件。文件名都和表名相同,扩展名分别是 .frm (存储表定义) 、.MYD (MYData,存储数据)、.MYI (MYIndex,存储索引)。
数据文件和索引文件可以放置在不同的目录,平均分布io,获得更快的速度。
2.InnoDB 存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比 Myisam 的存储引擎,InnoDB 写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
6.可以针对表设置引擎吗?如何设置?
可以, ENGINE=xxx 设置引擎。
代码示例:
create table person(
id int primary key auto_increment,
username varchar(32)
) ENGINE=InnoDB
6.选择合适的存储引擎?
选择标准: 根据应用特点选择合适的存储引擎,对于复杂的应用系统可以根据实际情况选择 多种存储引擎进行组合. 下面是常用存储引擎的适用环境:
- MyISAM: 默认的 MySQL 插件式存储引擎, 它是在 Web、 数据仓储和其他应用环境下最常使用的存储引擎之一。
- InnoDB:用于事务处理应用程序,具有众多特性,包括 ACID 事务支持。
- Memory: 将 所有数据保存在RAM 中, 在 需要快速查找引用和其他类似数据的环境下,可 提供极快的访问。
- Merge:允许 MySQL DBA 或开发人员将一系列等同的 MyISAM 表以逻辑方式组合在一起,并作为 1 个对象引用它们。对于诸如数据仓储等 VLDB 环境十分适合。
7.选择合适的数据类型
前提: 使用适合存储引擎。
选择原则: 根据选定的存储引擎,确定如何选择合适的数据类型下面的选择方法按存储引擎分类 :
-
MyISAM 数据存储引擎和数据列
MyISAM数据表,最好使用固定长度的数据列代替可变长度的数据列。
-
MEMORY存储引擎和数据列
MEMORY数据表目前都使用固定长度的数据行存储,因此无论使用CHAR或VARCHAR列都没有关系。两者都是作为CHAR类型处理的。
-
InnoDB 存储引擎和数据列
建议使用 VARCHAR类型
对于InnoDB数据表,内部的行存储格式没有区分固定长度和可变长度列(所有数据行 都使用指向数据列值的头指针) ,因此在本质上,使用固定长度的CHAR列不一定比使 用可变长度VARCHAR列简单。 因而, 主要的性能因素是数据行使用的存储总量。 由于 CHAR 平均占用的空间多于VARCHAR,因此使用VARCHAR来最小化需要处理的数据行的存储总 量和磁盘I/O是比较好的。
8.char & varchar
保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
9.Mysql字符集
mysql服务器可以支持多种字符集 (可以用show character set命令查看所有mysql支持 的字符集) ,在同一台服务器、同一个数据库、甚至同一个表的不同字段都可以指定使用不 同的字符集。
mysql的字符集包括字符集(CHARACTER)和校对规则(COLLATION)两个概念。
10.如何选择字符集?
建议在能够完全满足应用的前提下,尽量使用小的字符集。因为更小的字符集意味着能够节省空间、 减少网络传输字节数,同时由于存储空间的较小间接的提高了系统的性能。
有很多字符集可以保存汉字,比如 utf8、gb2312、gbk、latin1 等等,但是常用的是 gb2312 和 gbk。因为 gb2312 字库比 gbk 字库小,有些偏僻字(例如:洺)不能保存,因此 在选择字符集的时候一定要权衡这些偏僻字在应用出现的几率以及造成的影响, 不能做出肯 定答复的话最好选用 gbk。
11.什么是索引?
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
12.索引设计原则?
-
搜索的索引列,不 一定是所要选择的列。最适合索引的列是出现在WHERE子句中的列,或连接子句中指定的列,而不是出现在SELECT 关键字后的选择列表中的列。
-
使用惟一索引。考虑某列中值的分布。 对于惟一值的列,索引的效果最好,而具有多个 重复值的列,其索引效果最差。
-
使用短索引。如果对串列进行索引,应该指定一个前缀长度,只要有可能就应该这做样。 例如,如果有一个 CHAR(200) 列,如果在前 10 个或 20 个字符内,多数值是惟一的, 那么就不要对整个列进行索引。
-
利用最左前缀。在创建 一个 n 列的索引时,实际是创建了 MySQL 可利用的 n 个索引。 多列索引可起几个索引的作用,因为可利用索引中最左边的列集来匹配行。 这样的列集 称为最左前缀。 (这与索引一个列的前缀不同,索引一个列的前缀是利用该的n前个字 符作为索引值 )
-
不要过度索引。每个额外的索引都要占用额外的磁盘空间,并降低写操作的性能,这一点我们前面已经介绍 过。在修改表的内容时,索引必须进行更新,有时可能需要重构, 因此, 索引越多,所花的时间越长。
如果有一个索引很少利用或从不使用,那么会不必要地减缓表的修改速度。 此外,MySQL 在生成一个执行计划时,要考虑各个索引,这也要费时间。
创建多余的索引给查询优化带来了更多的工作。索引太多,也可能会使 MySQL选择不到所要使用的 最好索引。 只保持所需的索引有利于查询优化。 如果想给已索引的表增加索引, 应 该考虑所要增加的索引是否是现有多列索引的最左索引。
-
考虑在列上进行的比较类型。 索引可用于“ <”、“ < = ”、“ = ”、“ > =”、“ > ”和 BETWEEN 运算。在模式具有一个直接量前缀时,索引也用于 LIKE 运算。如果只将某个列用于其他类型的运算时(如 STRCMP( )) ,对其进行索引没有价值。
13.MySql有哪些索引?
- BTREE
- HASH
- FULLTEXT
- R-Tree
- 物理存储角度
1、聚集索引(clustered index)
2、非聚集索引(non-clustered index)
- 从逻辑角度
- 普通索引:仅加速查询
- 唯一索引:加速查询 + 列值唯一(可以有null)
- 主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
- 组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
- 全文索引:对文本的内容进行分词,进行搜索
14.Hash索引和B+树索引的底层实现原理:
hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据.B+树底层实现是多路平衡查找树.对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然后根据查询判断是否需要回表查询数据.
那么可以看出他们有以下的不同:
- hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询.
因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询.而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),天然支持范围.
- hash索引不支持使用索引进行排序,原理同上.
- hash索引不支持模糊查询以及多列索引的最左前缀匹配.原理也是因为hash函数的不可预测.AAAA和AAAAB的索引没有相关性.
- hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询.
- hash索引虽然在等值查询上较快,但是不稳定.性能不可预测,当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差.而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低.
因此,在大多数情况下,直接选择B+树索引可以获得稳定且较好的查询速度.而不需要使用hash索引.
15. 非聚簇索引一定会回表查询吗?
不一定,这涉及到查询语句所要求的字段是否全部命中了索引,如果全部命中了索引,那么就不必再进行回表查询.
举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行select age from employee where age < 20的查询时,在索引的叶子节点上,已经包含了age信息,不会再次进行回表查询.
16.如何查询最后一行记录?
select * from table_name order by id desc limit 1;
17.MySQL自增id不连续问题?
- 唯一键冲突
- 事务回滚
- 批量申请自增id的策略
18.sql注入问题?
原因:用户传入的参数中注入符合sql的语法,从而破坏原有sql结构语意,达到攻击效果。
19.什么是3NF(范式)?
- 1NF 指的是数据库表中的任何属性都具有原子性的,不可再分解
- 2NF 是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性
- 3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余
20. NULL和空串判断?
NULL值是没有值,,它不是空串。如果指定’'(两个单引号,其间没有字符),这在NOT NULL列中是允许的。空串是一个有效的值,它不是无值。
判断NULL需要用 IS NULL 或者 IS NOT NULL。
21.什么是事务?
可以用来维护数据库的完整性,它保证成批的MySQL操作要么完全执行,要么完全不执行。
22.事务4个特性?
事务是必须满足4个条件(ACID):
- 原子性 Atomicity: 一个事务中的所有操作,要么全部完成,要么全部不完成,最小的执行单位。
- 一致性 Consistency: 事务执行前后,都处于一致性状态。
- 隔离性 Isolation: 数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
- 持久性 Durability: 事务执行完成后,对数据的修改就是永久的,即便系统故障也不会丢失。
23.事务隔离级别分别是?
- READ_UNCOMMITTED 这是事务最低的隔离级别,它充许另外一个事务可以看到这个事务未提交的数据。解决第一类丢失更新的问题,但是会出现脏读、不可重复读、第二类丢失更新的问题,幻读 。
- READ_COMMITTED 保证一个事务修改的数据提交后才能被另外一个事务读取,即另外一个事务不能读取该事务未提交的数据。解决第一类丢失更新和脏读的问题,但会出现不可重复读、第二类丢失更新的问题,幻读问题
- REPEATABLE_READ 保证一个事务相同条件下前后两次获取的数据是一致的 (注意是 一个事务,可以理解为事务间的数据互不影响)解决第一类丢失更新,脏读、不可重复读、第二类丢失更新的问题,但会出幻读。
- SERIALIZABLE 事务串行执行,解决了脏读、不可重复读、幻读。但效率很差,所以实际中一般不用。
24.InnoDB默认事务隔离级别?如何查看当前隔离级别
可重复读(REPEATABLE-READ)
查看:
mysql> select @@global.tx_isolation;
+———————————+
| @@global.tx_isolation |
+———————————+
| REPEATABLE-READ |
+———————————+
1 row in set, 1 warning (0.01 sec)
25.什么是锁?
数据库的锁是为了支持对共享资源进行并发访问,提供数据的完整性和一致性,这样才能保证在高并发的情况下,访问数据库的时候,数据不会出现问题。
26.死锁?
是指两个或两个以上进程执行过程中,因竞争共享资源造成的相互等待现象。
27.如何处理死锁?
- 设置超时时间。超时后自动释放。
- 发起死锁检测,主动回滚其中一条事务,让其他事务继续执行。
28.如何创建用户?授权?
创建用户:
CREATE USER 'username'@'host' IDENTIFIED BY 'password';
授权:
GRANT privileges ON databasename.tablename TO 'username'@'host';
- username:用户名
- host:可以登陆的主机地址。本地用户用localhost表示,任意远程主机用通配符%。
- password:登陆密码,密码可以为空表示不需要密码登陆服务器
- databasename: 数据库名称。
- tablename:表名称,*代表所有表。
29.如何查看表结构?
desc table_name;
mysql> desc zipkin_spans;
+———————+———————+———+——+————+———+
| Field | Type | Null | Key | Default | Extra |
+———————+———————+———+——+————+———+
| trace_id_high | bigint(20) | NO | PRI | 0 | |
| trace_id | bigint(20) | NO | PRI | NULL | |
| id | bigint(20) | NO | PRI | NULL | |
| name | varchar(255) | NO | MUL | NULL | |
| parent_id | bigint(20) | YES | | NULL | |
| debug | bit(1) | YES | | NULL | |
| start_ts | bigint(20) | YES | MUL | NULL | |
| duration | bigint(20) | YES | | NULL | |
+———————+———————+———+——+————+———+
8 rows in set (0.01 sec)
30.Mysql删除表的几种方式?区别?
1.delete : 仅删除表数据,支持条件过滤,支持回滚。记录日志。因此比较慢。
delete from table_name;
2.truncate: 仅删除所有数据,不支持条件过滤,不支持回滚。不记录日志,效率高于delete。
truncate table table_name;
3.drop:删除表数据同时删除表结构。将表所占的空间都释放掉。删除效率最高。
drop table table_name;
31.like走索引吗?
Xxx% 走索引, %xxx不走索引。
32.什么是回表?
在普通索引查到主键索引后,再去主键索引定位记录。等于说非主键索引需要多走一个索引树。
33.如何避免回表?
索引覆盖被查询的字段。
34.索引覆盖是什么?
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引’。
35.视图的优缺点?
优点
简单化,数据所见即所得
安全性,用户只能查询或修改他们所能见到得到的数据
逻辑独立性,可以屏蔽真实表结构变化带来的影响
缺点
性能相对较差,简单的查询也会变得稍显复杂
修改不方便,特变是复杂的聚合视图基本无法修改
36.主键和唯一索引区别?
本质区别,主键是一种约束,唯一索引是一种索引。
主键不能有空值(非空+唯一),唯一索引可以为空。
主键可以是其他表的外键,唯一索引不可以。
一个表只能有一个主键,唯一索引 可以多个。
都可以建立联合主键或联合唯一索引。
主键-》聚簇索引,唯一索引->非聚簇索引。
37.如何随机获取一条记录?
SELECT * FROM table_name ORDER BY rand() LIMIT 1;
38.Mysql中的数值类型?
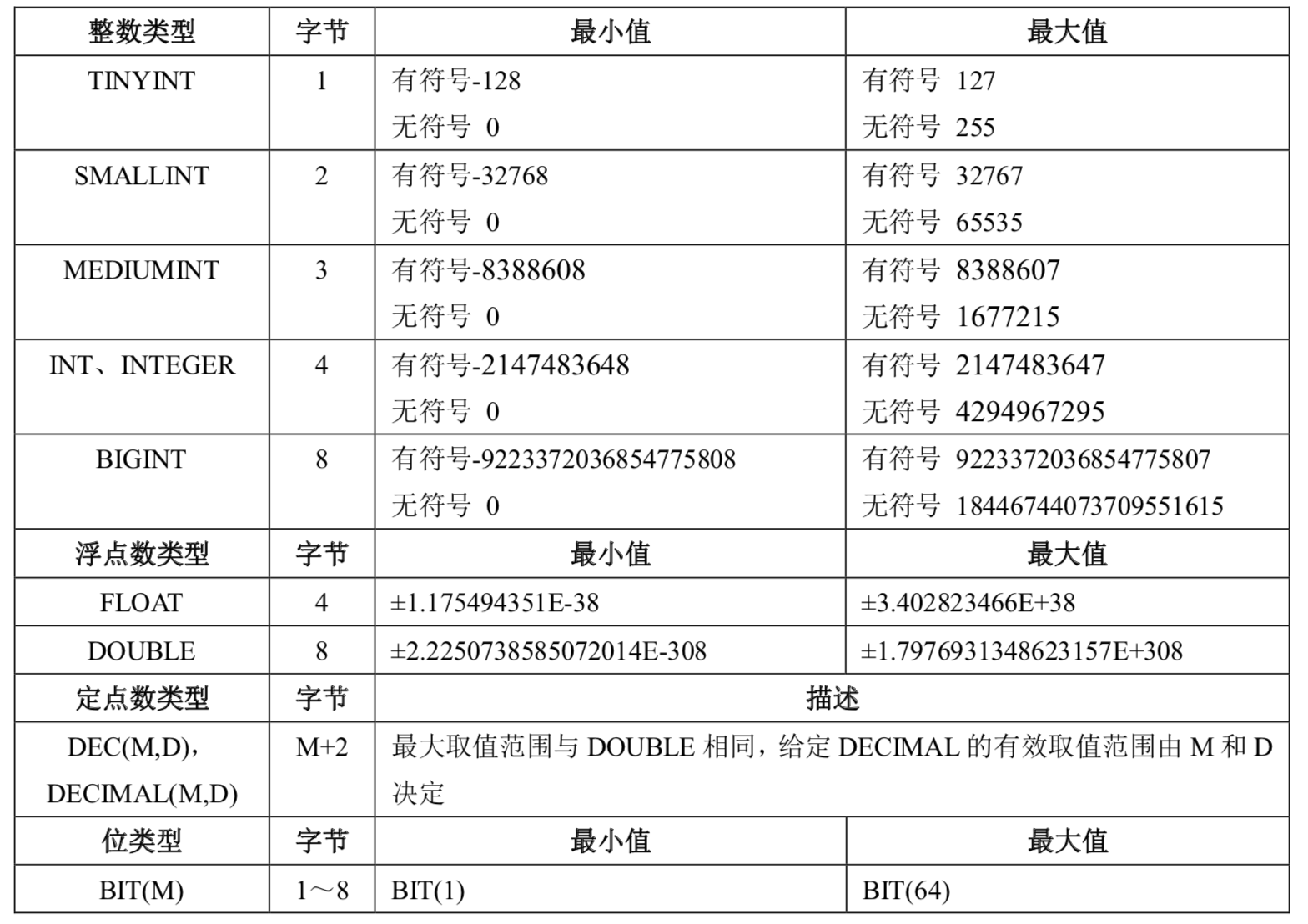
39.查看当前表有哪些索引?
show index from table_name;
40.索引不生效的情况?
- 使用不等于查询
- NULL值
- 列参与了数学运算或者函数
- 在字符串like时左边是通配符.比如 %xxx
- 当mysql分析全表扫描比使用索引快的时候不使用索引.
- 当使用联合索引,前面一个条件为范围查询,后面的即使符合最左前缀原则,也无法使用索引.
41.MVVC?
MVCC 全称是多版本并发控制系统,InnoDB 的 MVCC 是通过在每行记录后面保存两个隐藏的列来实现,这两个列一个保存了行的创建时间,一个保存行的过期时间(删除时间)。当然存储的并不是真实的时间而是系统版本号(system version number)。每开始一个新的事务,系统版本号都会自动新增,事务开始时刻的系统版本号会作为事务的版本号,用来查询到每行记录的版本号进行比较。
42.sql语句的执行流程?
客户端连接数据库,验证身份。
获取当前用户权限。
当你查询时,会先去缓存看看,如果有返回。
如果没有,分析器对sql做词法分析。
优化器对sql进行“它认为比较好的优化”。
执行器负责具体执行sql语句。
最后把数据返回给客户端。
43.如何获取select 语句执行计划?
explain sql;
44.explain列有哪些?含义?
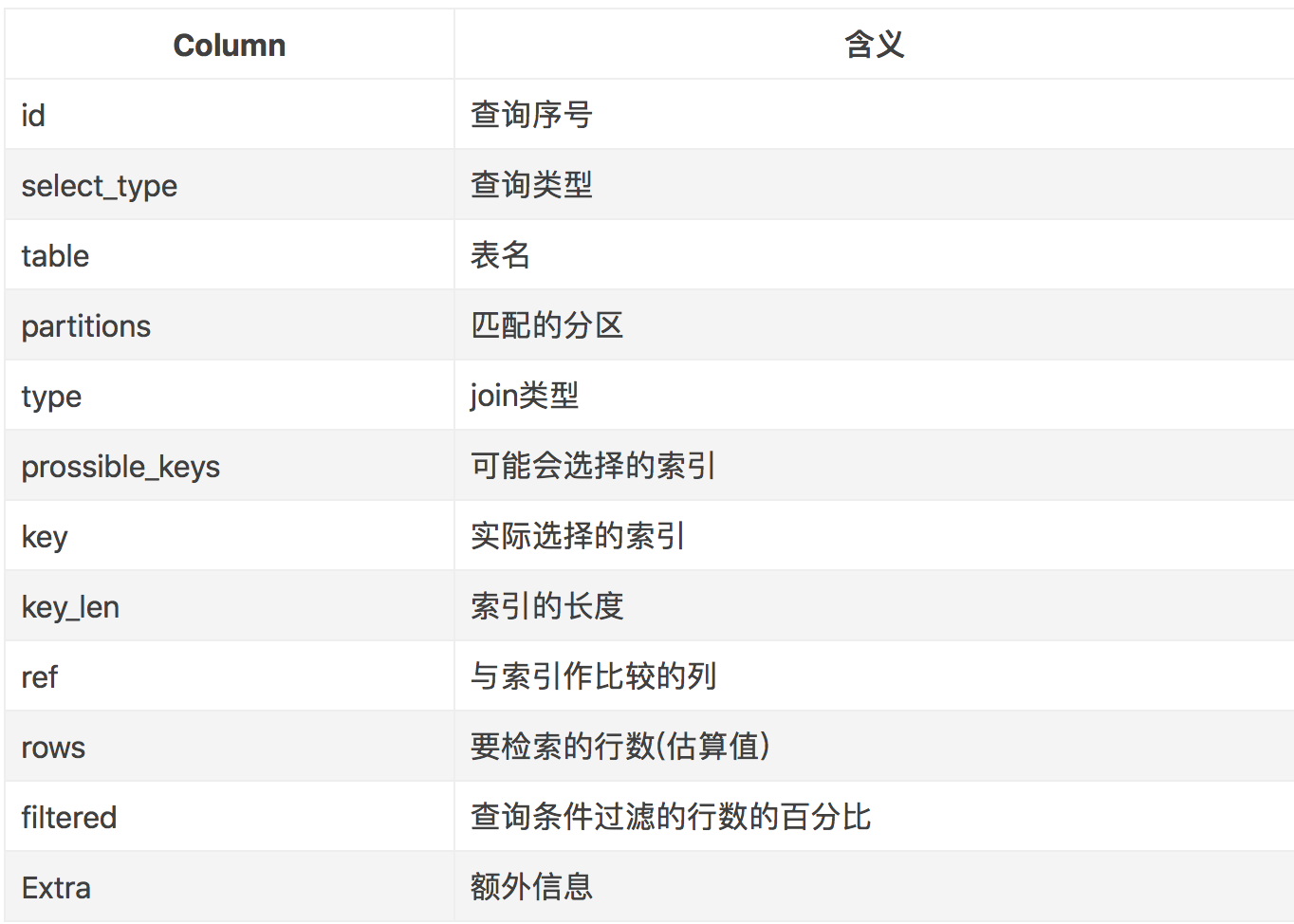
一、 id
SQL查询中的序列号。
id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行。
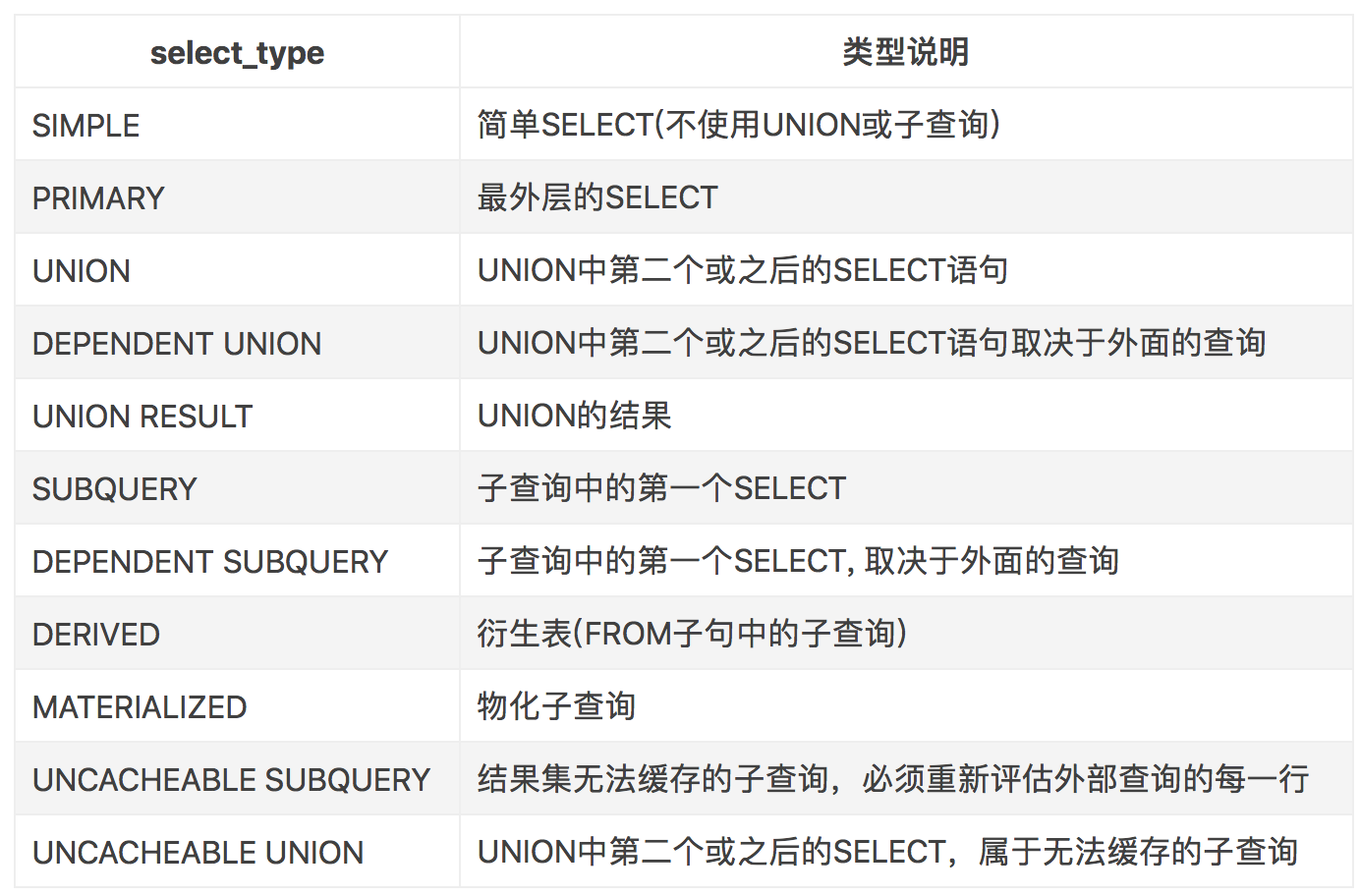
二、select_type
三、table
显示这一行的数据是关于哪张表的。不一定是实际存在的表名。 可以为如下的值:
- <unionM,N>: 引用id为M和N UNION后的结果。
- : 引用id为N的结果派生出的表。派生表可以是一个结果集,例如派生自FROM中子查询的结果。
- : 引用id为N的子查询结果物化得到的表。即生成一个临时表保存子查询的结果。
四、type
这是最重要的字段之一,显示查询使用了何种类型。从最好到最差的连接类型依次为:
system,const,eq_ref,ref,fulltext,ref_or_null,index_merge,unique_subquery,index_subquery,range,index,ALL
1、system
表中只有一行数据或者是空表,这是const类型的一个特例。且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index
2、const
最多只有一行记录匹配。当联合主键或唯一索引的所有字段跟常量值比较时,join类型为const。其他数据库也叫做唯一索引扫描
3、eq_ref
多表join时,对于来自前面表的每一行,在当前表中只能找到一行。这可能是除了system和const之外最好的类型。当主键或唯一非NULL索引的所有字段都被用作join联接时会使用此类型。
eq_ref可用于使用’='操作符作比较的索引列。比较的值可以是常量,也可以是使用在此表之前读取的表的列的表达式。
相对于下面的ref区别就是它使用的唯一索引,即主键或唯一索引,而ref使用的是非唯一索引或者普通索引。 eq_ref只能找到一行,而ref能找到多行。
4、ref
对于来自前面表的每一行,在此表的索引中可以匹配到多行。若联接只用到索引的最左前缀或索引不是主键或唯一索引时,使用ref类型(也就是说,此联接能够匹配多行记录)。
ref可用于使用’=‘或’<=>'操作符作比较的索引列。
5、 fulltext
使用全文索引的时候是这个类型。要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
6、ref_or_null
跟ref类型类似,只是增加了null值的比较。实际用的不多。
7、index_merge
表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取多个索引,性能可能大部分时间都不如range
8、unique_subquery
用于where中的in形式子查询,子查询返回不重复值唯一值,可以完全替换子查询,效率更高。 该类型替换了下面形式的IN子查询的ref: value IN (SELECT primary_key FROM single_table WHERE some_expr)
9、index_subquery
该联接类型类似于unique_subquery。适用于非唯一索引,可以返回重复值。
10、range
索引范围查询,常见于使用 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN()或者like等运算符的查询中。
11、index
索引全表扫描,把索引从头到尾扫一遍。这里包含两种情况: 一种是查询使用了覆盖索引,那么它只需要扫描索引就可以获得数据,这个效率要比全表扫描要快,因为索引通常比数据表小,而且还能避免二次查询。在extra中显示Using index,反之,如果在索引上进行全表扫描,没有Using index的提示。
12、all
全表扫描,性能最差。
五、possible_keys
查询可能使用到的索引都会在这里列出来。
六、Key
key列显示MySQL实际使用的键(索引)
要想强制MySQL使用或忽视possible_keys列中的索引,可以使用FORCE INDEX、USE INDEX或者IGNORE INDEX。
select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。
七、key_len
表示索引中使用的字节数。
key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
不损失精确性的情况下,长度越短越好 。
八、ref
表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值。
九、rows
rows 也是一个重要的字段。 这是mysql估算的需要扫描的行数(不是精确值)。
十、Extra
该列包含MySQL解决查询的详细信息,有以下几种情况:
- Using where:列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤。
- Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询。
- Using filesort:MySQL中无法利用索引完成的排序操作称为“文件排序”。
- Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
- Impossible where:这个值强调了where语句会导致没有符合条件的行。
- Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行。
链接:https://www.jianshu.com/p/8fab76bbf448
45.MySql最多创建多少列索引?
16
46.为什么最好建立一个主键?
主键是数据库确保数据行在整张表唯一性的保障,即使业务上本张表没有主键,也建议添加一个自增长的ID列作为主键.设定了主键之后,在后续的删改查的时候可能更加快速以及确保操作数据范围安全.
47.字段为什么要求建议为not null?
MySQL官网这样介绍:
NULL columns require additional space in the rowto record whether their values are NULL. For MyISAM tables, each NULL columntakes one bit extra, rounded up to the nearest byte.
null值会占用更多的字节,且会在程序中造成很多与预期不符的情况.
48.varchar(10)和int(10)代表什么含义
varchar的10代表了申请的空间长度,也是可以存储的数据的最大长度,而int的10只是代表了展示的长度,不足10位以0填充.也就是说,int(1)和int(10)所能存储的数字大小以及占用的空间都是相同的,只是在展示时按照长度展示。
49.视图是什么?对比普通表优势?
视图(View)是一种虚拟存在的表,对于使用视图的用户来说基本上是透明的。视图并 不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时 动态生成的。
视图相对于普通的表的优势主要包括以下几项。
-
简单:使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件,
对用户来说已经是过滤好的复合条件的结果集。
-
安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权限管理并不能
限制到某个行某个列,但是通过视图就可以简单的实现。
-
数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加
列对视图没有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问 者的影响。
50.count(*)在不同引擎的实现方式?
MyISAM :把一个表的总行数存在了磁盘上,执行 count(*) 的时候会直接返回这个数,效率很高。
InnoDB : 比较麻烦,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
或许人生要有遗憾才算圆满
智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范