Anaconda安装(过程详细)_anaconda安装教程-程序员宅基地
技术标签: python anaconda 机器学习基础配置
在本文开始之前,祝大家新年快乐,心想事成,事事顺利!
一、前言
Anaconda是一个开源的Python发行版本,用来管理Python相关的包,安装Anaconda可以很方便的切换不同的环境,使用不同的深度学习框架开发项目,本文将详细介绍Anaconda的安装。
二、实验环境
Windows 10
三、Anaconda安装
注:在Anaconda安装的过程中,比较容易出错的环节是环境变量的配置,所以大家在配置环境变量的时候,要细心一些。
步骤一:输入链接“https://www.anaconda.com/”登录Anaconda官网。
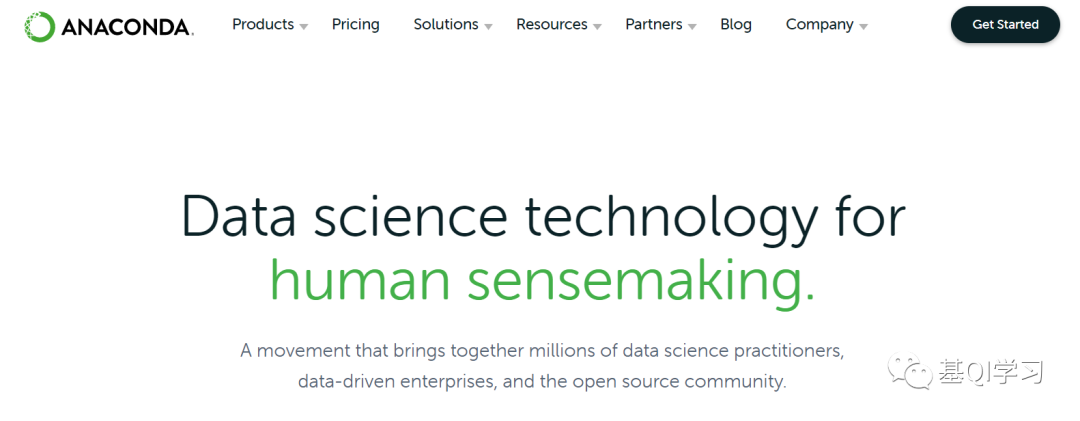
步骤二:鼠标选中“Products”,点击“Indiviaual Edition”选项(Individual Edition是免费版的)。
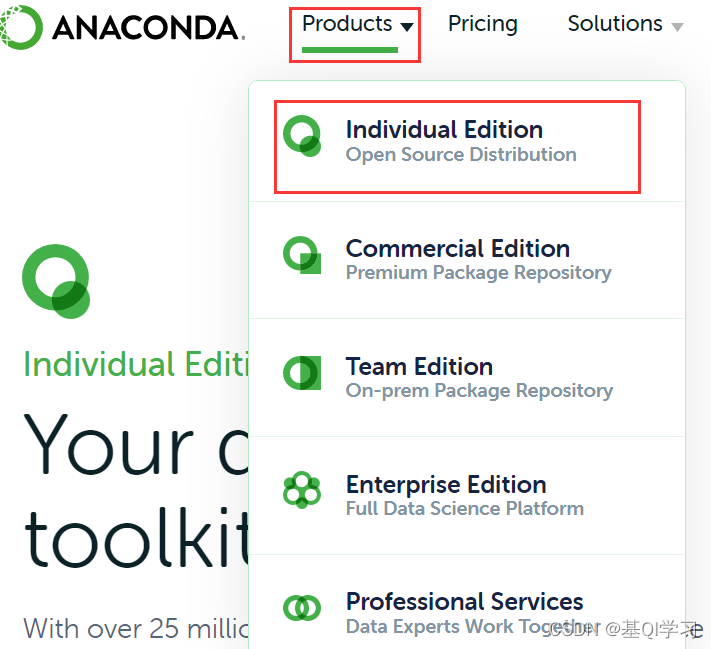
步骤三:选择Windows版本“64-Bit Graphical Installer
(510 MB)”进行安装。
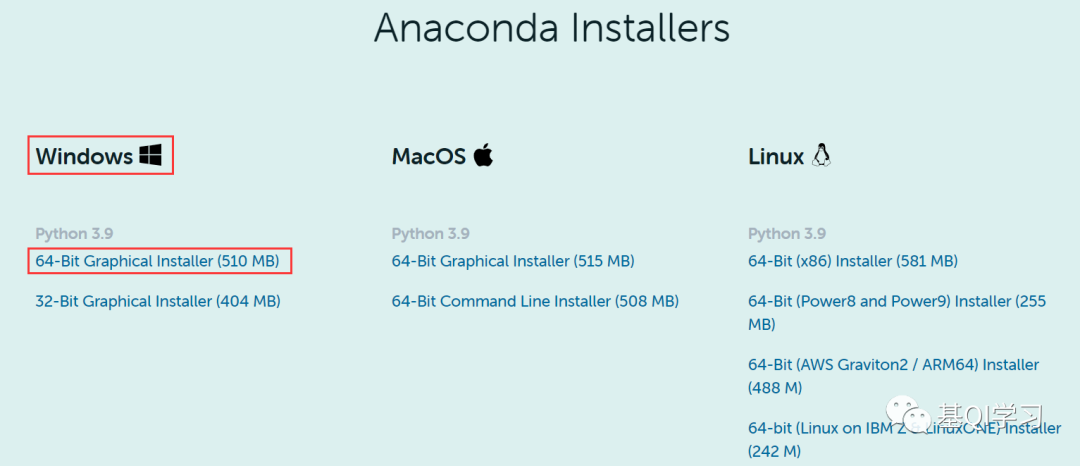
步骤四:双击“Anaconda3-2021.11-Windows-x86_64.
exe”,进行安装。

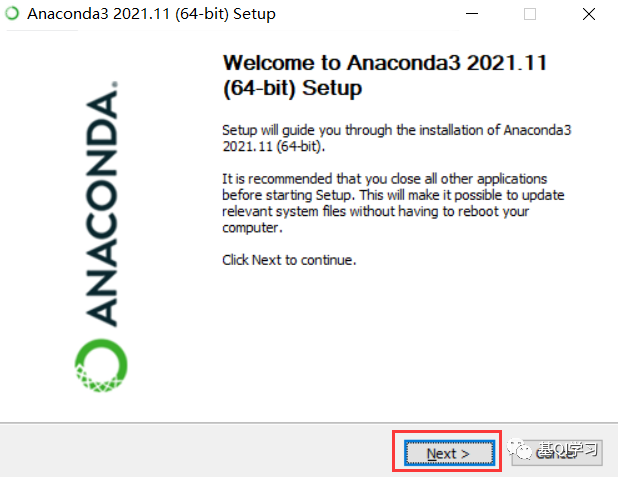
步骤五:点击“Next”。
步骤六:点击“I Agree”。
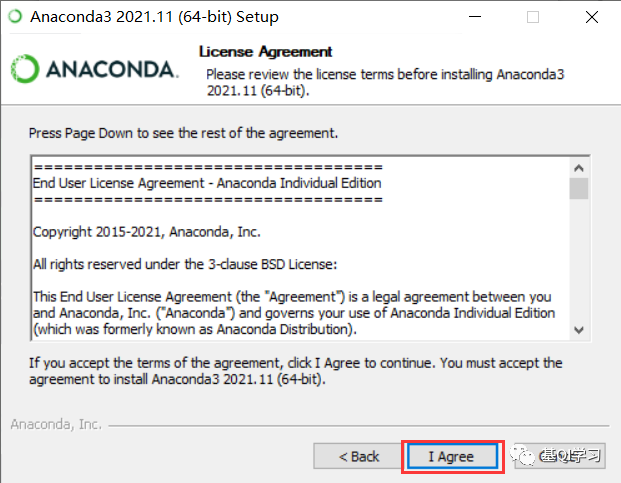
步骤七:选择“Just Me”,点击“Next”。(若电脑有多个用户,则选择“All Users”)
![]()
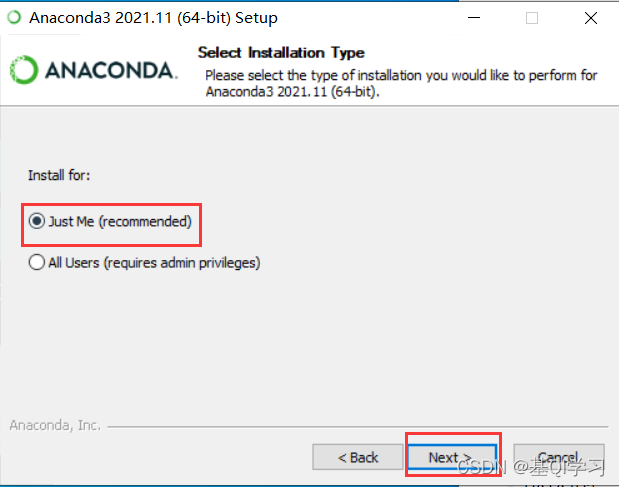
步骤八:设置Anaconda的安装路径,路径名称最好为全英文,随后点击“Next”。
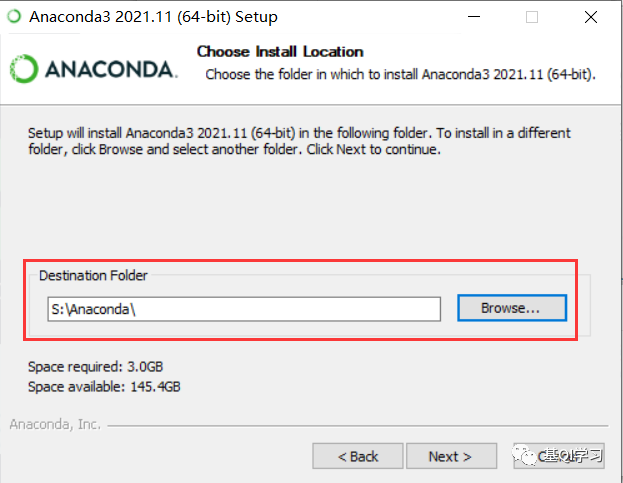
步骤九:点击“Install”。这里就不选择自动将Anaconda添加到系统路径了(因为我之前安装Anaconda的时候都是手动添加路径,使用的时候没有出现过问题,所以本次安装我仍然手动配置路径,我没有试过自动添加路径,所以不知道会出什么问题,大家感兴趣可以尝试。)
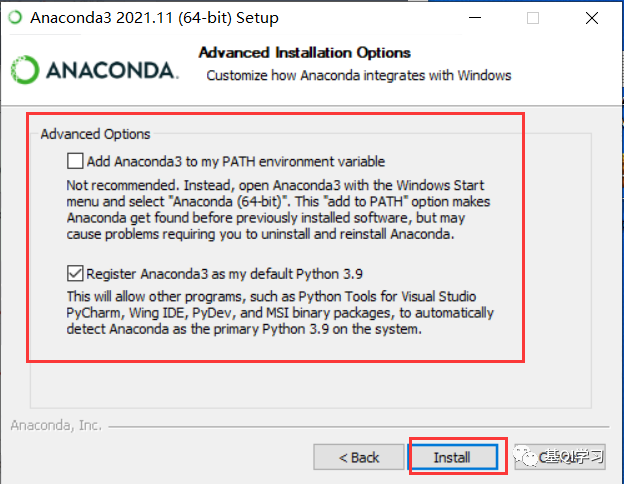
步骤十:点击“Next”。
步骤十一:点击“Next”。

步骤十二:点击“Finish”。
步骤十三:接下来就是手动配置环境变量了(比较关键)。
由于每台电脑打开环境变量的操作可能不同,所以本文仅以本电脑打开环境变量的步骤进行讲解。
打开环境变量:双击桌面“此电脑”,右键选择“属性”,随后在打开的页面点击“高级系统设置”,点击环境变量。
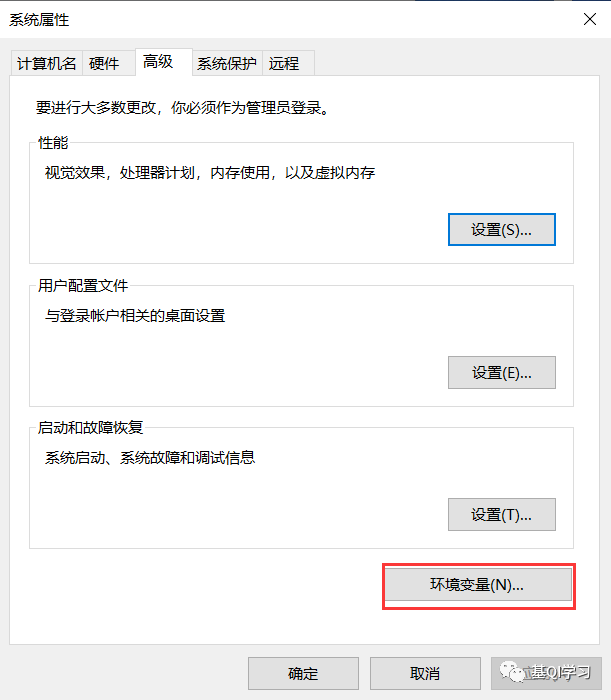
在系统变量(一定要看清,是系统变量,不是用户变量)一栏中,找到“Path”(这个Path不同电脑的书写可能不一样,所以根据自己电脑上的来,我这里是Path,但其它的电脑可能在大小写上有区别)。
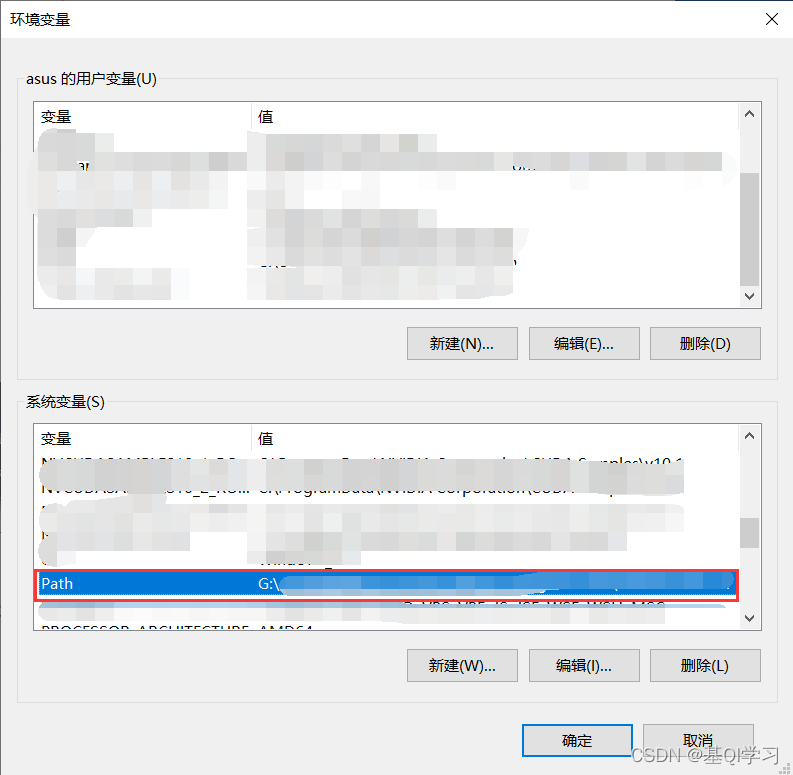
双击“Path”,并点击新建。
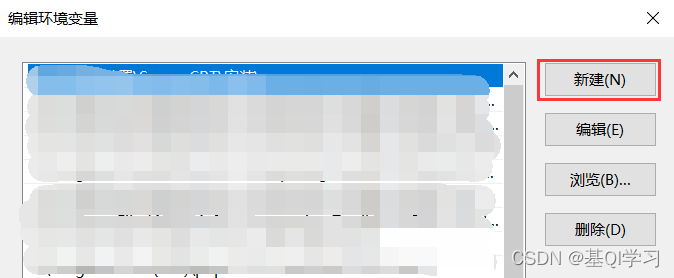
输入以下信息(Anaconda安装路径要根据自己当时安装Anaconda的路径来):
Anaconda安装路径
Anaconda安装路径\Scripts
Anaconda安装路径\Library\bin
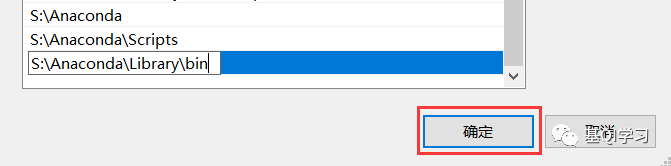
(上图中的内容仅是个人安装路径的配置,大家配置的时候,只需要更改“Anaconda安装路径”,改成自己的路径),输入完三条变量后,点击确定。
检验Anaconda环境变量是否配置成功:
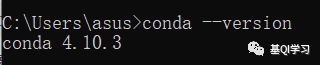
(1)打开cmd。
(2)输入“conda --version”。
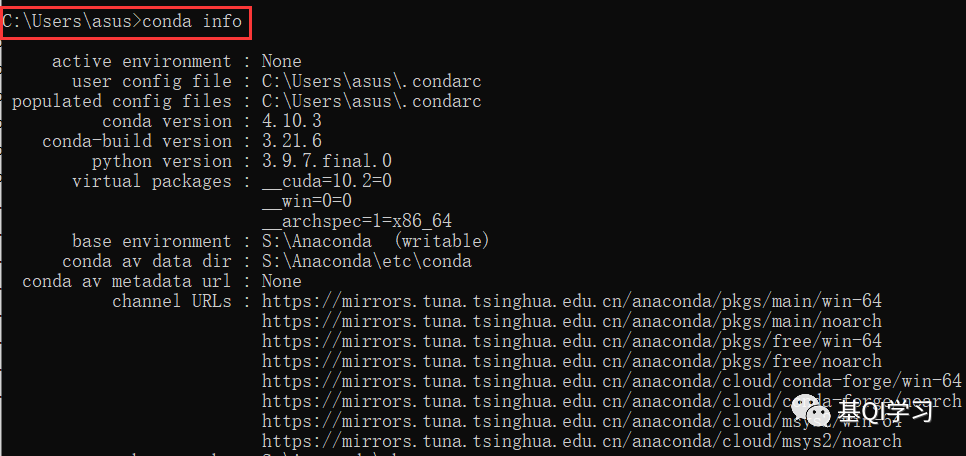
(3)输入“conda info”。
(4)输入“activate”,回车,之后再输入“python”。

若显示的内容均与上图相同或类似,这说明环境变量配置成功。
至此,Anaconda的安装就完成了。
四、结束语
我本来是想着用这一篇文章详细介绍Anaconda安装与深度学习框架(CPU版本和GPU版本)安装的,但是就在快写完的时候,发现其实可以自动化的安装CUDA和cuDNN,不需要手动安装(我之前都是手动安装),所以就准备下一篇文章详细讲解使用conda自动化安装CUDA和cuDNN,真不是我偷懒,是我发现了更省事的方法,所以下篇文章一定把深度学习框架的安装与配置讲明白了。
五、下一篇文章内容
下一篇文章详细讲解用Anaconda自动化安装CUDA和cuDNN,以及安装Tensorflow,PyTorch以及PaddlePaddle这三种深度学习框架,下篇一定!!!
智能推荐
linux嵌入式串口与zigbee,zigbee的串口与STM32通信-程序员宅基地
文章浏览阅读1.2k次。在TI 的CC2530中,使用的是协议栈Z-Stack2007,现在想通过串口与STM32通信,当STM32给zigbee发送数据时,zigbee接收,只是接收的这部分代码TI给封装起来了,只知道在配置里头是这样的:/* @ZL 串口初始化 */halUARTCfg_t uartConfig;/* UART Configuration */uartConfig.configured ..._linux zigbee stack
jieba 计算2个句子的文本相似度(Python实现)_jieba判断语义重复-程序员宅基地
文章浏览阅读6.1k次,点赞7次,收藏33次。余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。github 参考链接:https://github.com/ZhanPwBibiBibi/CHlikelihood# -*- coding: utf-8 -*-import jiebaimport numpy as npimport redef get_word_vector(s1,s2): """ :pa.._jieba判断语义重复
Openmesh函数库设计及与CGAL的对比_openmesh和cgal-程序员宅基地
文章浏览阅读4.7k次。Openmesh函数库设计及与CGAL的对比在前面写了CGAL模板类设计的一些思路,这里尝试写一点openmesh库的设计思路以及和CGAL的对比.虽然OPENMESH代码量小,不过还是只看懂皮毛,很大部分算是翻译帮助文档吧,主要用作笔记,方便以后继续分析。相对CGAL的功能强大和庞大(包含大量计算几何算法的实现),Openmesh显得更加小巧轻量化,它更专_openmesh和cgal
常用验证函数-程序员宅基地
文章浏览阅读1.1k次。//函数名:chksafe//功能介绍:检查是否含有"",//,"/"//参数说明:要检查的字符串//返回值:0:是 1:不是function chksafe(a){ return 1;/* fibdn = new Array ("" ,"//", "、", ",", ";", "/"); i=fibdn.length; j=a.length; for (ii=0;ii { for (
关于C语言编译的可执行文件 exe 发给好友解决办法 Visual Studio 2013 版本_将c语言可执行程序发给别人-程序员宅基地
文章浏览阅读3.2k次,点赞2次,收藏14次。下面展示一些 内联代码片。前提是用的 Visual Studio 工具你是不是把 exe 可执行文件发给好友之后,好友打开是这种情况?下面展示一些 内联代码片。就解决办法:然后_将c语言可执行程序发给别人
mysql运行报错64bit_关于MySQL5.6.25在Win7 64bit下重装后无法启动的解决方法-程序员宅基地
文章浏览阅读340次。在重装MySQL5.6.25安装到进行配置的时候,一直在等待服务的启动。如果手动在系统服务启动会提示1067错误,这个错误在网上很常见,然而我试过了很多方法均无法解决。于是看ProgramData\MySQL Server 5.6\data下的 ***.err 错误日志,看出错的部分:2015-06-04 13:08:19 5200 [Warning] InnoDB: Doublewrite do..._windows [error] innodb: header page consists of zero bytes in datafile: .\ib
随便推点
计算机usb接口禁用,台式机usb接口禁用了怎么办-程序员宅基地
文章浏览阅读7.2k次。我们的台式机接口有时候用不了,可能是被禁用了,那要怎么样解决呢?下面由学习啦小编给你做出详细的台式机usb接口禁用了解决方法介绍!希望对你有帮助!台式机usb接口禁用了解决方法一:一、检查是否禁用主板usb设备。进入bios屏蔽掉usb,进入bios选择 Devices - USB Setup- Front USB Ports- 将该项改为 Enable; 按F10保存并退出。二、在控制面板里检查..._主机的usb接口封了怎么用
IDEA连接Mysql失败:下载驱动失败,Failed todownload Cannot download Read timed out_idea com.mysql:mysql-connector下载卡住-程序员宅基地
文章浏览阅读482次,点赞7次,收藏8次。解决:1. 手动加入jar包2.选择自己maven仓库中存在mysql-connector3. 选择完毕后,确定使用:4. 进行测试连接_idea com.mysql:mysql-connector下载卡住
Java连接Redis存取数据(详细)_redis导入导出数据java-程序员宅基地
文章浏览阅读6.5k次,点赞4次,收藏30次。Java连接Redis存取数据一.相关工具二.准备工作1.启动redis2.外部连接测试3.新建连接。4.连接成功三.新建jedis项目1.新建项目2.命名项目3.引入相关jar包4.引入 junit5.新建包com.redis.test四.编写代码1.redis.properties : redis连接配置文件2.RedisPoolUtil : 连接池配置工具3.SerializeUtil : ..._redis导入导出数据java
android dialog自定义布局 圆角背景 点击空白处不关闭 设置dialog大小-程序员宅基地
文章浏览阅读748次。1.首先上布局文件<?xml version="1.0" encoding="utf-8"?><LinearLayout ="http://schemas.android.com/apk/res/android" android:orientation="vertical" android:layout_width="300d
【算法】从记忆化搜索到递推——动态规划入门_记忆化搜索和递推-程序员宅基地
文章浏览阅读311次。本文的题目其实都比较简单,但是为了学习记忆化搜索,还是要用记忆化搜索再做一遍,不要眼高手低。由于 dp 数组的无后效性,因此还可以将 dp 数组优化成两个变量。将大问题分解成子问题,即 dfs (i) 可以分解成 dfs (i - 1)对于简单的 dp 题,直接写 dp 还更简单一些,硬写记忆化搜索还有点难。因为——有些动态规划直接去想递推公式太难了,所以可以先写成记忆化搜索。由于记忆化搜索是从将大问题分解成子问题的角度去考虑的,所以会简单一些。如果读者觉得本文的题目太简单了,可以去尝试一下。_记忆化搜索和递推
2021-07-12嵌入式学习---交叉编译_交叉编译 prefix-程序员宅基地
文章浏览阅读336次。1、交叉编译交叉编译是在一个平台上生成另一个平台上的可执行代码。同一个体系结构可以运行不同的操作系统;同样,同一个操作系统也可以在不同的体系结构上运行。举例:我们在Ubuntu上面编写树莓派的代码,并编译成可执行代码,如a.out,是在树莓派上面运行的,不是在Ubuntu Linux上面运行。2、为什么要交叉编译1.有时是因为目的平台(C51)上不允许或不能够安装我们所需要的编译器,而我们又需要这个编译器的某些特征;2.有时是因为目的平台上的资源贫乏,无法运行我们所需要编译器;3.有时又是因为目的_交叉编译 prefix