Lucene介绍与使用-程序员宅基地
目录
1、了解搜索技术
1.1 什么是搜索
简单的说,搜索就是搜寻、查找,在IT行业中就是指用户输入关键字,通过相应的算法,查询并返回用户所需要的信息。
1.2 普通的数据库搜索
类似:select * from 表名 where 字段名 like ‘%关键字%’
例如:select * from article where content like ’%here%’
结果: where here shere
1.3 新的业务需求
比如,用户在百度文本框中输入,“吃饭睡觉写程序”,会出现的以下结果:
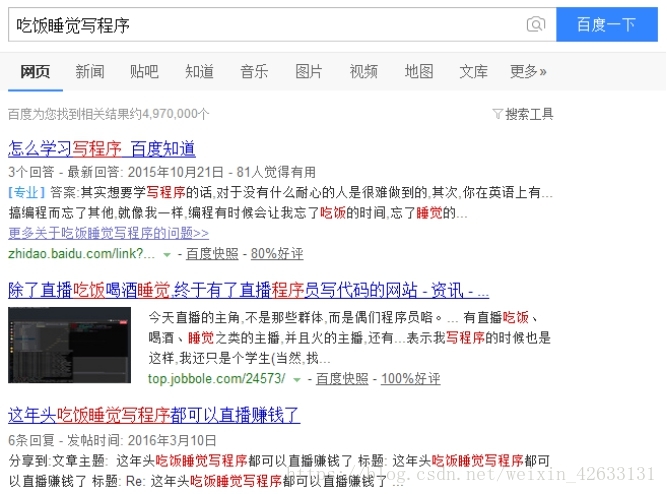
从结果可以看出,百度搜索具备以下明显特点:
1、即使在相关结果数量接近500万时,也能快速得出结果。
2、搜索的结果不仅仅局限于完整的“吃饭睡觉写程序”这一短语,而是将此短语拆分成,“写程序”,“吃饭”,“睡觉”,“程序”等关键字。
3、对拆分后的搜索关键字进行标红显示。
4、…
问题:上述功能,使用大家以前学过的数据库搜索能够方便实现吗?
1.4 普通的数据库搜索的缺陷
类似:select * from 表名 where 字段名 like ‘%关键字%’
例如:select * from article where content like ’%here%’
结果: where here shere
1、因为没有通过高效的索引方式,所以查询的速度在大量数据的情况下是很慢。
2、搜索效果比较差,只能对用户输入的完整关键字首尾位进行模糊匹配。用户搜索的结果误多输入一个字符,可能就导致查询出的结果远离用户的预期。
2、 搜索技术
2.1 搜索引擎的种类
搜索引擎按照功能通常分为垂直搜索和综合搜索。
1、垂直搜索是指专门针对某一类信息进行搜索。例如:会搜网 主要做商务搜索的,并且提供商务信息。除此之外还有爱看图标网、职友集等。
2、综合搜索是指对众多信息进行综合性的搜索。例如:百度、谷歌、搜狗、360搜索等。
2.2 倒排索引
倒排索引又叫反向索引(右下图)以字或词为文档中出现的位置情况。

在实际的运用中,我们可以对数据库中原始的数据结构(左图),在业务空闲时事先根据左图内容,创建新的倒排索引结构的数据区域(右图)。
用户有查询需求时,先访问倒排索引数据区域(右图),得出文档id后,通过文档id即可快速,准确的通过左图找到具体的文档内容。
这一过程,可以通过我们自己写程序来实现,也可以借用已经抽象出来的通用开源技术来实现。
4 Lucene概述
4.1 什么是Lucene
LOGO:

-
Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供
-
Lucene提供了一个简单却强大的应用程序接口(API),能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具
-
Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品
4.2 什么是全文检索?

4.3 Lucene下载及版本问题
官网:
- 目前最新的版本是7.x系列,但是在企业中还是用4.x比较多,所以我们学习4.x的版本
老版本下载地址:
http://archive.apache.org/dist/lucene/java/
4.4 Lucene、Solr、Elasticsearch关系
Lucene:底层的API,工具包
Solr:基于Lucene开发的企业级的搜索引擎产品
Elasticsearch:基于Lucene开发的企业级的搜索引擎产品
5 Lucene的基本使用
使用Lucene的API来实现对索引的增(创建索引)、删(删除索引)、改(修改索引)、查(搜索数据)。
5.1 创建索引
5.1.1 创建索引的流程
文档Document:数据库中一条具体的记录
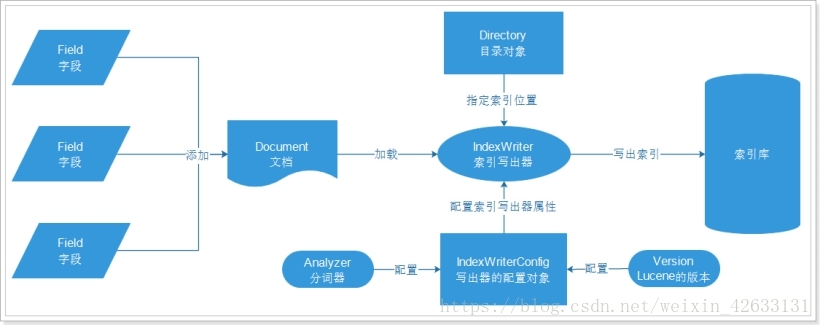
字段Field:数据库中的每个字段
目录对象Directory:物理存储位置
写出器的配置对象:需要分词器和lucene的版本
5.1.2 添加依赖

<properties>
<lunece.version>4.10.2</lunece.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- lucene核心库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lunece.version}</version>
</dependency>
<!-- Lucene的查询解析器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lunece.version}</version>
</dependency>
<!-- lucene的默认分词器库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lunece.version}</version>
</dependency>
<!-- lucene的高亮显示 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>${lunece.version}</version>
</dependency>
</dependencies>
5.1.3 代码实现
步骤:
//1 创建文档对象
//2 创建存储目录
//3 创建分词器
//4 创建索引写入器的配置对象
//5 创建索引写入器对象
//6 将文档交给索引写入器
//7 提交
//8 关闭
// 创建索引
@Test
public void testCreate() throws Exception{
//1 创建文档对象
Document document = new Document();
// 创建并添加字段信息。参数:字段的名称、字段的值、是否存储,这里选Store.YES代表存储到文档列表。Store.NO代表不存储
document.add(new StringField("id", "1", Field.Store.YES));
// 这里我们title字段需要用TextField,即创建索引又会被分词。
document.add(new TextField("title", "谷歌地图之父跳槽facebook", Field.Store.YES));
//2 索引目录类,指定索引在硬盘中的位置
Directory directory = FSDirectory.open(new File("d:\\indexDir"));
//3 创建分词器对象
Analyzer analyzer = new StandardAnalyzer();
//4 索引写出工具的配置对象
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);
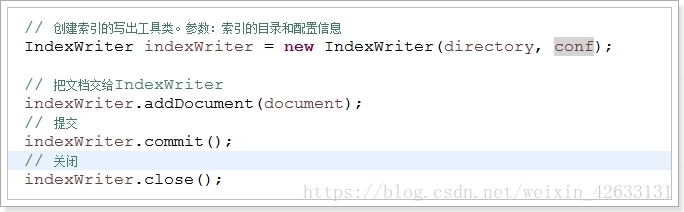
//5 创建索引的写出工具类。参数:索引的目录和配置信息
IndexWriter indexWriter = new IndexWriter(directory, conf);
//6 把文档交给IndexWriter
indexWriter.addDocument(document);
//7 提交
indexWriter.commit();
//8 关闭
indexWriter.close();
}
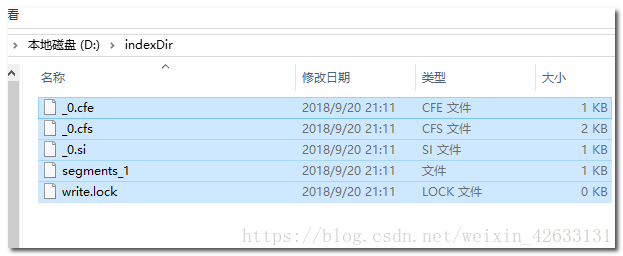
5.1.4 使用工具查看索引
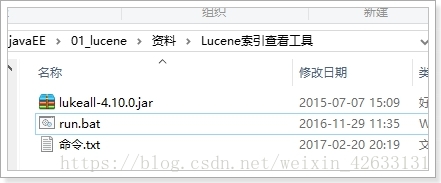
5.1.5 创建索引的API详解
5.1.5.1 Document(文档类)
Document:文档对象,是一条原始的数据
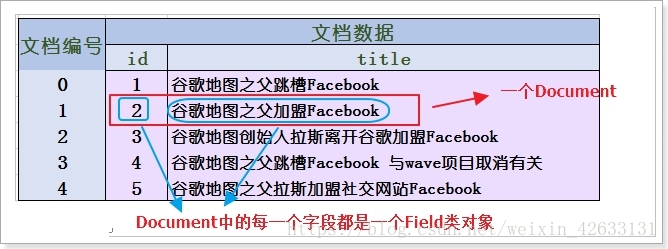
5.1.5.2 Field(字段类)
一个Document中可以有很多个不同的字段,每一个字段都是一个Field类的对象。
一个Document中的字段其类型是不确定的,因此Field类就提供了各种不同的子类,来对应这些不同类型的字段。
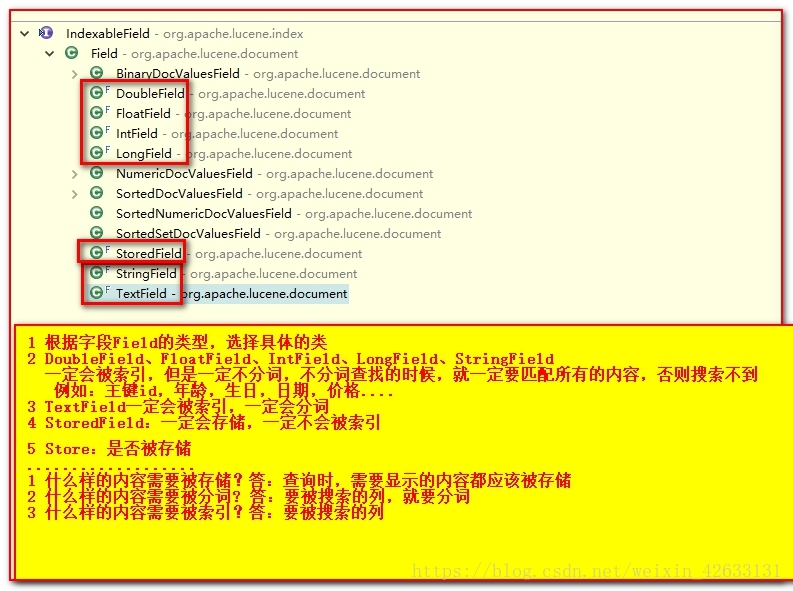
这些子类有一些不同的特性:
1)DoubleField、FloatField、IntField、LongField、StringField这些子类一定会被创建索引,但是不会被分词,而且不一定会被存储到文档列表。要通过构造函数中的参数Store来指定:如果Store.YES代表存储,Store.NO代表不存储

2)TextField即创建索引,又会被分词。StringField会创建索引,但是不会被分词。
如果不分词,会造成整个字段作为一个词条,除非用户完全匹配,否则搜索不到:
我们一般,需要搜索的字段,都会做分词:

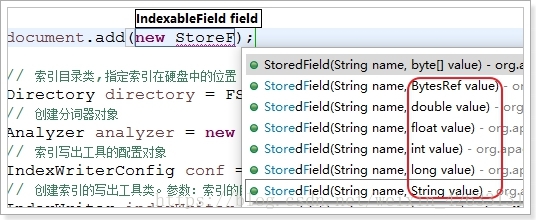
3)StoreField一定会被存储,但是一定不创建索引
StoredField可以创建各种数据类型的字段:

问题1:如何确定一个字段是否需要存储?
如果一个字段要显示到最终的结果中,那么一定要存储,否则就不存储
问题2:如何确定一个字段是否需要创建索引?
如果要根据这个字段进行搜索,那么这个字段就必须创建索引。
问题3:如何确定一个字段是否需要分词?
前提是这个字段首先要创建索引。然后如果这个字段的值是不可分割的,那么就不需要分词。例如:ID
5.1.5.3 Directory(目录类)
指定索引要存储的位置
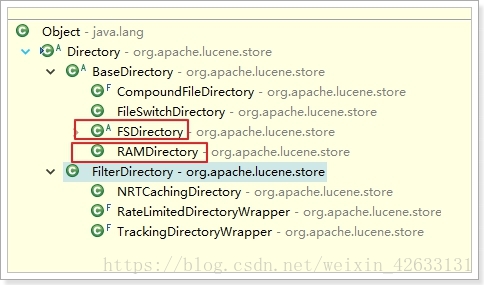
FSDirectory:文件系统目录,会把索引库指向本地磁盘。
特点:速度略慢,但是比较安全
RAMDirectory:内存目录,会把索引库保存在内存。
特点:速度快,但是不安全
5.1.5.4 Analyzer(分词器类)
• 提供分词算法,可以把文档中的数据按照算法分词
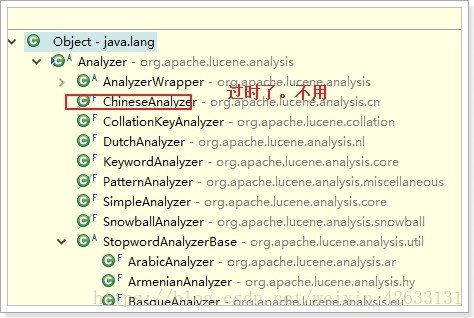
这些分词器,并没有合适的中文分词器,因此一般我们会用第三方提供的分词器:
一般我们用IK分词器。
5.1.5.5 IK分词器(重要)
- 概述
林良益
IK分词器官方版本是不支持Lucene4.X的,有人基于IK的源码做了改造,支持了Lucene4.X:
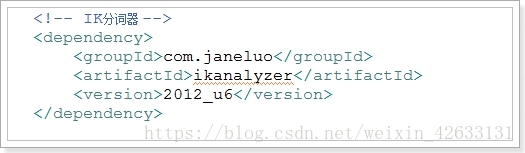
- 基本使用
引入IK分词器:
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>

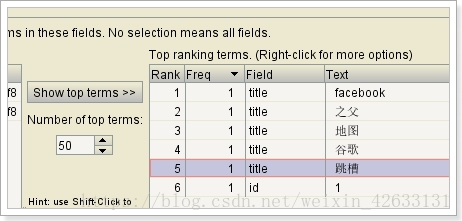
中文分词更专业:
- 扩展词典和停用词典
IK分词器的词库有限,新增加的词条可以通过配置文件添加到IK的词库中,也可以把一些不用的词条去除:
[外链图片转存失败(img-f41wpopO-1562576510318)(assets/wps18CD.tmp.jpg)]
扩展词典:用来引入一些自定义的新词
停止词典:用来停用一些不必要的词条

结果:分词中,加入了我们新的词,被停用的词语没有被分词:

5.1.5.6 IndexWriterConfig(索引写出器配置类)
1) 设置配置信息:Lucene的版本和分词器类型

2)设置是否清空索引库中的数据

5.1.5.7 IndexWriter(索引写出器类)
- 索引写出工具,作用就是 实现对索引的增(创建索引)、删(删除索引)、改(修改索引)
- 可以一次创建一个,也可以批量创建索引
// 批量创建索引
@Test
public void testCreate2() throws Exception{
// 创建文档的集合
Collection<Document> docs = new ArrayList<>();
// 创建文档对象
Document document1 = new Document();
document1.add(new StringField("id", "1", Field.Store.YES));
document1.add(new TextField("title", "谷歌地图之父跳槽facebook", Field.Store.YES));
docs.add(document1);
// 创建文档对象
Document document2 = new Document();
document2.add(new StringField("id", "2", Field.Store.YES));
document2.add(new TextField("title", "谷歌地图之父加盟FaceBook", Field.Store.YES));
docs.add(document2);
// 创建文档对象
Document document3 = new Document();
document3.add(new StringField("id", "3", Field.Store.YES));
document3.add(new TextField("title", "谷歌地图创始人拉斯离开谷歌加盟Facebook", Field.Store.YES));
docs.add(document3);
// 创建文档对象
Document document4 = new Document();
document4.add(new StringField("id", "4", Field.Store.YES));
document4.add(new TextField("title", "谷歌地图之父跳槽Facebook与Wave项目取消有关", Field.Store.YES));
docs.add(document4);
// 创建文档对象
Document document5 = new Document();
document5.add(new StringField("id", "5", Field.Store.YES));
document5.add(new TextField("title", "谷歌地图之父拉斯加盟社交网站Facebook", Field.Store.YES));
docs.add(document5);
// 索引目录类,指定索引在硬盘中的位置
Directory directory = FSDirectory.open(new File("d:\\indexDir"));
// 引入IK分词器
Analyzer analyzer = new IKAnalyzer();
// 索引写出工具的配置对象
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);
// 设置打开方式:OpenMode.APPEND 会在索引库的基础上追加新索引。OpenMode.CREATE会先清空原来数据,再提交新的索引
conf.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
// 创建索引的写出工具类。参数:索引的目录和配置信息
IndexWriter indexWriter = new IndexWriter(directory, conf);
// 把文档集合交给IndexWriter
indexWriter.addDocuments(docs);
// 提交
indexWriter.commit();
// 关闭
indexWriter.close();
}
5.2 查询索引数据
5.2.1 代码实现
实现步骤:
//1 创建读取目录对象
//2 创建索引读取工具
//3 创建索引搜索工具
//4 创建查询解析器
//5 创建查询对象
//6 搜索数据
//7 各种操作
@Test
public void testSearch() throws Exception {
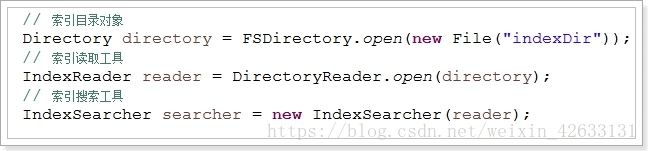
// 索引目录对象
Directory directory = FSDirectory.open(new File("d:\\indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
QueryParser parser = new QueryParser("title", new IKAnalyzer());
// 创建查询对象
Query query = parser.parse("谷歌");
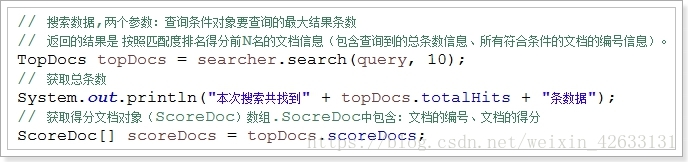
// 搜索数据,两个参数:查询条件对象要查询的最大结果条数
// 返回的结果是 按照匹配度排名得分前N名的文档信息(包含查询到的总条数信息、所有符合条件的文档的编号信息)。
TopDocs topDocs = searcher.search(query, 10);
// 获取总条数
System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据");
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
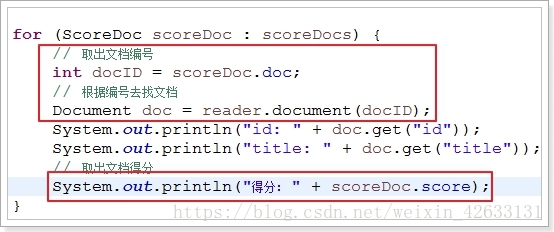
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docID = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docID);
System.out.println("id: " + doc.get("id"));
System.out.println("title: " + doc.get("title"));
// 取出文档得分
System.out.println("得分: " + scoreDoc.score);
}
}
5.2.2 核心API
5.2.2.1 QueryParser(查询解析器)
1)QueryParser(单一字段的查询解析器)

2)MultiFieldQueryParser(多字段的查询解析器)

5.2.2.2 Query(查询对象,包含要查询的关键词信息)
- 1)通过QueryParser解析关键字,得到查询对象

- 2)自定义查询对象(高级查询)
我们可以通过Query的子类,直接创建查询对象,实现高级查询(后面详细讲)
5.2.2.3 IndexSearch(索引搜索对象,执行搜索功能)
IndexSearch可以帮助我们实现:快速搜索、排序、打分等功能。
IndexSearch需要依赖IndexReader类
查询后得到的结果,就是打分排序后的前N名结果。N可以通过第2个参数来指定:

5.2.2.4 TopDocs(查询结果对象)
通过IndexSearcher对象,我们可以搜索,获取结果:TopDocs对象
在TopDocs中,包含两部分信息:
int totalHits :查询到的总条数
ScoreDoc[] scoreDocs : 得分文档对象的数组
5.2.2.5 ScoreDoc(得分文档对象)
ScoreDoc是得分文档对象,包含两部分数据:
int doc :文档的编号----lucene给文档的一个唯一编号
float score :文档的得分信息
拿到编号后,我们还需要根据编号来获取真正的文档信息
5.2. 特殊查询
抽取公用的搜索方法:
public void search(Query query) throws Exception {
// 索引目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 搜索数据,两个参数:查询条件对象要查询的最大结果条数
// 返回的结果是 按照匹配度排名得分前N名的文档信息(包含查询到的总条数信息、所有符合条件的文档的编号信息)。
TopDocs topDocs = searcher.search(query, 10);
// 获取总条数
System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据");
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docID = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docID);
System.out.println("id: " + doc.get("id"));
System.out.println("title: " + doc.get("title"));
// 取出文档得分
System.out.println("得分: " + scoreDoc.score);
}
}
5.2.3.1 TermQuery(词条查询)
/*
* 测试普通词条查询
* 注意:Term(词条)是搜索的最小单位,不可再分词。值必须是字符串!
*/
@Test
public void testTermQuery() throws Exception {
// 创建词条查询对象
Query query = new TermQuery(new Term("title", "谷歌地图"));
search(query);
}

5.2.3.2 WildcardQuery(通配符查询)
/*
* 测试通配符查询
* ? 可以代表任意一个字符
* * 可以任意多个任意字符
*/
@Test
public void testWildCardQuery() throws Exception {
// 创建查询对象
Query query = new WildcardQuery(new Term("title", "*歌*"));
search(query);
}
5.2.3.3 FuzzyQuery(模糊查询)
/*
* 测试模糊查询
*/
@Test
public void testFuzzyQuery() throws Exception {
// 创建模糊查询对象:允许用户输错。但是要求错误的最大编辑距离不能超过2
// 编辑距离:一个单词到另一个单词最少要修改的次数 facebool --> facebook 需要编辑1次,编辑距离就是1
// Query query = new FuzzyQuery(new Term("title","fscevool"));
// 可以手动指定编辑距离,但是参数必须在0~2之间
Query query = new FuzzyQuery(new Term("title","facevool"),1);
search(query);
}
5.2.3.4 NumericRangeQuery(数值范围查询)
/*
* 测试:数值范围查询
* 注意:数值范围查询,可以用来对非String类型的ID进行精确的查找
*/
@Test
public void testNumericRangeQuery() throws Exception{
// 数值范围查询对象,参数:字段名称,最小值、最大值、是否包含最小值、是否包含最大值
Query query = NumericRangeQuery.newLongRange("id", 2L, 2L, true, true);
search(query);
}
5.2.3.5 BooleanQuery(组合查询)
/*
* 布尔查询:
* 布尔查询本身没有查询条件,可以把其它查询通过逻辑运算进行组合!
* 交集:Occur.MUST + Occur.MUST
* 并集:Occur.SHOULD + Occur.SHOULD
* 非:Occur.MUST_NOT
*/
@Test
public void testBooleanQuery() throws Exception{
Query query1 = NumericRangeQuery.newLongRange("id", 1L, 3L, true, true);
Query query2 = NumericRangeQuery.newLongRange("id", 2L, 4L, true, true);
// 创建布尔查询的对象
BooleanQuery query = new BooleanQuery();
// 组合其它查询
query.add(query1, BooleanClause.Occur.MUST_NOT);
query.add(query2, BooleanClause.Occur.SHOULD);
search(query);
}
5.4 修改索引
步骤:
//1 创建文档存储目录
//2 创建索引写入器配置对象
//3 创建索引写入器
//4 创建文档数据
//5 修改
//6 提交
//7 关闭
/* 测试:修改索引
* 注意:
* A:Lucene修改功能底层会先删除,再把新的文档添加。
* B:修改功能会根据Term进行匹配,所有匹配到的都会被删除。这样不好
* C:因此,一般我们修改时,都会根据一个唯一不重复字段进行匹配修改。例如ID
* D:但是词条搜索,要求ID必须是字符串。如果不是,这个方法就不能用。
* 如果ID是数值类型,我们不能直接去修改。可以先手动删除deleteDocuments(数值范围查询锁定ID),再添加。
*/
@Test
public void testUpdate() throws Exception{
// 创建目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建配置对象
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
// 创建索引写出工具
IndexWriter writer = new IndexWriter(directory, conf);
// 创建新的文档数据
Document doc = new Document();
doc.add(new StringField("id","1",Store.YES));
doc.add(new TextField("title","谷歌地图之父跳槽facebook ",Store.YES));
/* 修改索引。参数:
* 词条:根据这个词条匹配到的所有文档都会被修改
* 文档信息:要修改的新的文档数据
*/
writer.updateDocument(new Term("id","1"), doc);
// 提交
writer.commit();
// 关闭
writer.close();
}
5.5 删除索引
步骤:
//1 创建文档对象目录
//2 创建索引写入器配置对象
//3 创建索引写入器
//4 删除
//5 提交
//6 关闭
/*
* 演示:删除索引
* 注意:
* 一般,为了进行精确删除,我们会根据唯一字段来删除。比如ID
* 如果是用Term删除,要求ID也必须是字符串类型!
*/
@Test
public void testDelete() throws Exception {
// 创建目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建配置对象
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
// 创建索引写出工具
IndexWriter writer = new IndexWriter(directory, conf);
// 根据词条进行删除
// writer.deleteDocuments(new Term("id", "1"));
// 根据query对象删除,如果ID是数值类型,那么我们可以用数值范围查询锁定一个具体的ID
// Query query = NumericRangeQuery.newLongRange("id", 2L, 2L, true, true);
// writer.deleteDocuments(query);
// 删除所有
writer.deleteAll();
// 提交
writer.commit();
// 关闭
writer.close();
}
6 Lucene的高级使用
6.1 高亮显示
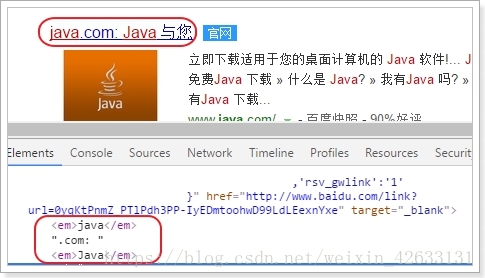
原理:
1)给所有关键字加上一个HTML标签
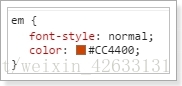
2)给这个特殊的标签设置CSS样式
实现步骤:
//1 创建目录 对象
//2 创建索引读取工具
//3 创建索引搜索工具
//4 创建查询解析器
//5 创建查询对象
//6 创建格式化器
//7 创建查询分数工具
//8 准备高亮工具
//9 搜索
//10 获取结果
//11 用高亮工具处理普通的查询结果
// 高亮显示
@Test
public void testHighlighter() throws Exception {
// 目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建读取工具
IndexReader reader = DirectoryReader.open(directory);
// 创建搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser = new QueryParser("title", new IKAnalyzer());
Query query = parser.parse("谷歌地图");
// 格式化器
Formatter formatter = new SimpleHTMLFormatter("<em>", "</em>");
QueryScorer scorer = new QueryScorer(query);
// 准备高亮工具
Highlighter highlighter = new Highlighter(formatter, scorer);
// 搜索
TopDocs topDocs = searcher.search(query, 10);
System.out.println("本次搜索共" + topDocs.totalHits + "条数据");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取文档编号
int docID = scoreDoc.doc;
Document doc = reader.document(docID);
System.out.println("id: " + doc.get("id"));
String title = doc.get("title");
// 用高亮工具处理普通的查询结果,参数:分词器,要高亮的字段的名称,高亮字段的原始值
String hTitle = highlighter.getBestFragment(new IKAnalyzer(), "title", title);
System.out.println("title: " + hTitle);
// 获取文档的得分
System.out.println("得分:" + scoreDoc.score);
}
}
6.2 排序
// 排序
@Test
public void testSortQuery() throws Exception {
// 目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建读取工具
IndexReader reader = DirectoryReader.open(directory);
// 创建搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser = new QueryParser("title", new IKAnalyzer());
Query query = parser.parse("谷歌地图");
// 创建排序对象,需要排序字段SortField,参数:字段的名称、字段的类型、是否反转如果是false,升序。true降序
Sort sort = new Sort(new SortField("id", SortField.Type.LONG, true));
// 搜索
TopDocs topDocs = searcher.search(query, 10,sort);
System.out.println("本次搜索共" + topDocs.totalHits + "条数据");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取文档编号
int docID = scoreDoc.doc;
Document doc = reader.document(docID);
System.out.println("id: " + doc.get("id"));
System.out.println("title: " + doc.get("title"));
}
}
6.3 分页
// 分页
@Test
public void testPageQuery() throws Exception {
// 实际上Lucene本身不支持分页。因此我们需要自己进行逻辑分页。我们要准备分页参数:
int pageSize = 2;// 每页条数
int pageNum = 3;// 当前页码
int start = (pageNum - 1) * pageSize;// 当前页的起始条数
int end = start + pageSize;// 当前页的结束条数(不能包含)
// 目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建读取工具
IndexReader reader = DirectoryReader.open(directory);
// 创建搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser = new QueryParser("title", new IKAnalyzer());
Query query = parser.parse("谷歌地图");
// 创建排序对象,需要排序字段SortField,参数:字段的名称、字段的类型、是否反转如果是false,升序。true降序
Sort sort = new Sort(new SortField("id", Type.LONG, false));
// 搜索数据,查询0~end条
TopDocs topDocs = searcher.search(query, end,sort);
System.out.println("本次搜索共" + topDocs.totalHits + "条数据");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (int i = start; i < end; i++) {
ScoreDoc scoreDoc = scoreDocs[i];
// 获取文档编号
int docID = scoreDoc.doc;
Document doc = reader.document(docID);
System.out.println("id: " + doc.get("id"));
System.out.println("title: " + doc.get("title"));
}
}
6.4 得分算法
l Lucene会对搜索结果打分,用来表示文档数据与词条关联性的强弱,得分越高,表示查询的匹配度就越高,排名就越靠前!其算法公式是:


智能推荐
设计模式-原型模式(Prototype)-程序员宅基地
文章浏览阅读67次。原型模式是一种对象创建型模式,它采用复制原型对象的方法来创建对象的实例。它创建的实例,具有与原型一样的数据结构和值分为深度克隆和浅度克隆。浅度克隆:克隆对象的值类型(基本数据类型),克隆引用类型的地址;深度克隆:克隆对象的值类型,引用类型的对象也复制一份副本。UML图:具体代码:浅度复制:import java.util.List;/*..._prototype 设计模式
个性化政府云的探索-程序员宅基地
文章浏览阅读59次。入选国内首批云计算服务创新发展试点城市的北京、上海、深圳、杭州和无锡起到了很好的示范作用,不仅促进了当地产业的升级换代,而且为国内其他城市发展云计算产业提供了很好的借鉴。据了解,目前国内至少有20个城市确定将云计算作为重点发展的产业。这势必会形成新一轮的云计算基础设施建设的**。由于云计算基础设施建设具有投资规模大,运维成本高,投资回收周期长,地域辐射性强等诸多特点,各地在建...
STM32问题集之BOOT0和BOOT1的作用_stm32boot0和boot1作用-程序员宅基地
文章浏览阅读9.4k次,点赞2次,收藏20次。一、功能及目的 在每个STM32的芯片上都有两个管脚BOOT0和BOOT1,这两个管脚在芯片复位时的电平状态决定了芯片复位后从哪个区域开始执行程序。BOOT1=x BOOT0=0 // 从用户闪存启动,这是正常的工作模式。BOOT1=0 BOOT0=1 // 从系统存储器启动,这种模式启动的程序_stm32boot0和boot1作用
C语言函数递归调用-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏22次。C语言函数递归调用_c语言函数递归调用
明日方舟抽卡模拟器wiki_明日方舟bilibili服-明日方舟bilibili服下载-程序员宅基地
文章浏览阅读410次。明日方舟bilibili服是一款天灾驾到战斗热血的创新二次元废土风塔防手游,精妙的二次元纸片人设计,为宅友们源源不断更新超多的纸片人老婆老公们,玩家将扮演废土正义一方“罗德岛”中的指挥官,与你身边的感染者们并肩作战。与同类塔防手游与众不同的几点,首先你可以在这抽卡轻松获得稀有,同时也可以在战斗体系和敌军走位机制看到不同。明日方舟bilibili服设定:1、起因不明并四处肆虐的天灾,席卷过的土地上出..._明日方舟抽卡模拟器
基于图像的目标检测与定位方法概述_图像定位算法-程序员宅基地
文章浏览阅读1.4w次,点赞15次,收藏97次。目录1. 目标检测与定位概念2. 目标检测与定位方法2.1 传统目标检测流程2.2 two-stage检测算法2.2.1 R-CNN2.2.2 two-stage其他算法2.2.2.1 Spatial Pyramid Pooling(空间金字塔池化)2.2.2.2 Fast-RCNN2.2.2.3 P11 Faster RCNN2.3 One-Stage2.3.1 YOLO2.3.2 SSD参考本文简单介绍基于图像的目标检测与定位相关概念,R-CNN和YOLO等算法基本思想。本文为学习笔记,参考了许多优_图像定位算法
随便推点
PHP必会面试题_//该层循环用来控制每轮 冒出一个数 需要比较的次数-程序员宅基地
文章浏览阅读363次。PHP必会面试题1. 基础篇1. 用 PHP 打印出前一天的时间格式是 2017-12-28 22:21:21? //>>1.当前时间减去一天的时间,然后再格式化echo date('Y-m-d H:i:s',time()-3600*24);//>>2.使用strtotime,可以将任何字符串时间转换成时间戳,仅针对英文echo date('Y-m-d H:i:s',str..._//该层循环用来控制每轮 冒出一个数 需要比较的次数
windows用mingw(g++)编译opencv,opencv_contrib,并install安装_opencv mingw contrib-程序员宅基地
文章浏览阅读1.3k次,点赞26次,收藏26次。windows下用mingw编译opencv貌似不支持cuda,选cuda会报错,我无法解决,所以没选cuda,下面两种编译方式支持。打开cmake gui程序,在下面两个框中分别输入opencv的源文件和编译目录,build-mingw为你创建的目录,可自定义命名。1、如果已经安装Qt,则Qt自带mingw编译器,从Qt安装目录找到编译器所在目录即可。1、如果已经安装Qt,则Qt自带cmake,从Qt安装目录找到cmake所在目录即可。2、若未安装Qt,则安装Mingw即可,参考我的另外一篇文章。_opencv mingw contrib
5个高质量简历模板网站,免费、免费、免费_hoso模板官网-程序员宅基地
文章浏览阅读10w+次,点赞42次,收藏309次。今天给大家推荐5个好用且免费的简历模板网站,简洁美观,非常值得收藏!1、菜鸟图库https://www.sucai999.com/search/word/0_242_0.html?v=NTYxMjky网站主要以设计类素材为主,办公类素材也很多,简历模板大部个偏简约风,各种版式都有,而且经常会更新。最重要的是全部都能免费下载。2、个人简历网https://www.gerenjianli.com/moban/这是一个专门提供简历模板的网站,里面有超多模板个类,找起来非常方便,风格也很多样,无须注册就能免费下载,_hoso模板官网
通过 TikTok 联盟提高销售额的 6 个步骤_tiktok联盟-程序员宅基地
文章浏览阅读142次。你听说过吗?该计划可让您以推广您的产品并在成功销售时支付佣金。它提供了新的营销渠道,使您的产品呈现在更广泛的受众面前并提高品牌知名度。此外,TikTok Shop联盟可以是一种经济高效的产品或服务营销方式。您只需在有人购买时付费,因此不存在在无效广告上浪费金钱的风险。这些诱人的好处是否足以让您想要开始您的TikTok Shop联盟活动?如果是这样,本指南适合您。_tiktok联盟
Mysql递归调用,报错:Subquery returns more than 1 row-程序员宅基地
文章浏览阅读2.1k次。Mysql递归调用,报错:Subquery returns more than 1 row_subquery returns more than 1 row
割线定理-程序员宅基地
文章浏览阅读3.2k次。文字表达:从圆外一点引圆的两条割线,这一点到每条割线与圆交点的距离的积相等。数学语言:从圆外一点L引两条割线与圆分别交于A.B.C.D 则有 LA·LB=LC·LD=LT²。几何语言:∵割线LDC和LBA交于圆O于ABCD点∴LA·LB=LC·LD=LT²证明过程:证1:已知:如图直线ABP和CDP是自点P引的⊙O的两条割线求证:PA·PB=PC·PD证明:连接AD、BC∵∠A和∠C都对弧BD∴由圆周角定理,得 ∠DAP=∠BCP又∵∠P=∠P∴△ADP._割线定理