java htmlparser 使用教程_HtmlParser基础教程-程序员宅基地
技术标签: java htmlparser 使用教程
1、相关资料
官方文档:http://htmlparser.sourceforge.net/samples.html
API:http://htmlparser.sourceforge.net/javadoc/index.html
其它HTML 解释器:jsoup等。由于HtmlParser自2006年以后就再没更新,目前很多人推荐使用jsoup代替它。
2、使用HtmlPaser的关键步骤
(1)通过Parser类创建一个解释器
(2)创建Filter或者Visitor
(3)使用parser根据filter或者visitor来取得所有符合条件的节点
(4)对节点内容进行处理
3、使用Parser的构造函数创建解释器
对于大多数使用者来说,使用最多的是通过一个URLConnection或者一个保存有网页内容的字符串来初始化Parser,或者使用静态函数来生成一个Parser对象。ParserFeedback的代码很简单,是针对调试和跟踪分析过程的,一般不需要改变。而使用Lexer则是一个相对比较高级的话题,放到以后再讨论吧。
这里比较有趣的一点是,如果需要设置页面的编码方式的话,不使用Lexer就只有静态函数一个方法了。对于大多数中文页面来说,好像这是应该用得比较多的一个方法。
4、HtmlPaser使用Node对象保存各节点信息
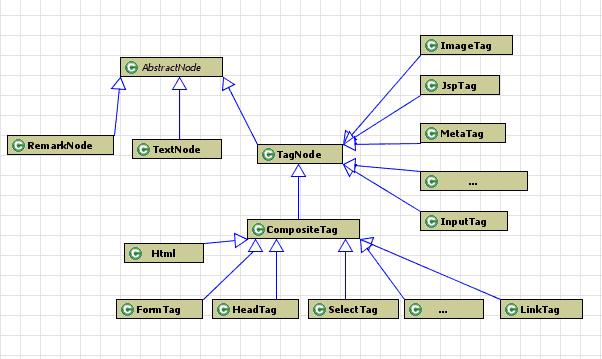
(1)访问各个节点的方法
Node getParent ():取得父节点
NodeList getChildren ():取得子节点的列表
Node getFirstChild ():取得第一个子节点
Node getLastChild ():取得最后一个子节点
Node getPreviousSibling ():取得前一个兄弟(不好意思,英文是兄弟姐妹,直译太麻烦而且不符合习惯,对不起女同胞了)
Node getNextSibling ():取得下一个兄弟节点
(2)取得Node内容的函数
String getText ():取得文本
String toPlainTextString():取得纯文本信息。
String toHtml () :取得HTML信息(原始HTML)
String toHtml (boolean verbatim):取得HTML信息(原始HTML)
String toString ():取得字符串信息(原始HTML)
Page getPage ():取得这个Node对应的Page对象
int getStartPosition ():取得这个Node在HTML页面中的起始位置
int getEndPosition ():取得这个Node在HTML页面中的结束位置
5、使用Filter访问Node节点及其内容
(1)Filter的种类
顾名思义,Filter就是对于结果进行过滤,取得需要的内容。
所有的Filter均实现了NodeFilter接口,此接口只有一个方法Boolean accept(Node node),用于确定某个节点是否属于此Filter过滤的范围。
HTMLParser在org.htmlparser.filters包之内一共定义了16个不同的Filter,也可以分为几类。
TagNameFilterHasAttributeFilter
HasChildFilter
HasParentFilter
HasSiblingFilter
IsEqualFilter
AndFilterNotFilter
OrFilter
XorFilter
NodeClassFilterStringFilter
LinkStringFilter
LinkRegexFilter
RegexFilter
CssSelectorNodeFilter
除此以外,可以自定义一些Filter,用于完成特殊需求的过滤。
(2)Filter的使用示例
以下示例用于提取HTML文件中的链接
packageorg.ljh.search.html;
importjava.util.HashSet;
importjava.util.Set;
importorg.htmlparser.Node;
importorg.htmlparser.NodeFilter;
importorg.htmlparser.Parser;
importorg.htmlparser.filters.NodeClassFilter;
importorg.htmlparser.filters.OrFilter;
importorg.htmlparser.tags.LinkTag;
importorg.htmlparser.util.NodeList;
importorg.htmlparser.util.ParserException;
//本类创建用于HTML文件解释工具
publicclassHtmlParserTool {
// 本方法用于提取某个html文档中内嵌的链接
publicstaticSet extractLinks(String url, LinkFilter filter) {
Set links = newHashSet();
try{
// 1、构造一个Parser,并设置相关的属性
Parser parser = newParser(url);
parser.setEncoding("gb2312");
// 2.1、自定义一个Filter,用于过滤标签,然后取得标签中的src属性值
NodeFilter frameNodeFilter = newNodeFilter() {
@Override
publicbooleanaccept(Node node) {
if(node.getText().startsWith("frame src=")) {
returntrue;
} else{
returnfalse;
}
}
};
//2.2、创建第二个Filter,过滤标签
NodeFilter aNodeFilter = newNodeClassFilter(LinkTag.class);
//2.3、净土上述2个Filter形成一个组合逻辑Filter。
OrFilter linkFilter = newOrFilter(frameNodeFilter, aNodeFilter);
//3、使用parser根据filter来取得所有符合条件的节点
NodeList nodeList = parser.extractAllNodesThatMatch(linkFilter);
//4、对取得的Node进行处理
for(inti =0; i
Node node = nodeList.elementAt(i);
String linkURL = "";
//如果链接类型为
if(nodeinstanceofLinkTag){
LinkTag link = (LinkTag)node;
linkURL= link.getLink();
}else{
//如果类型为
String nodeText = node.getText();
intbeginPosition = nodeText.indexOf("src=");
nodeText = nodeText.substring(beginPosition);
intendPosition = nodeText.indexOf(" ");
if(endPosition == -1){
endPosition = nodeText.indexOf(">");
}
linkURL = nodeText.substring(5, endPosition -1);
}
//判断是否属于本次搜索范围的url
if(filter.accept(linkURL)){
links.add(linkURL);
}
}
} catch(ParserException e) {
e.printStackTrace();
}
returnlinks;
}
}
程序中的一些说明:
(1)通过Node#getText()取得节点的String。
(2)node instanceof TagLink,即节点,其它还有很多的类似节点,如tableTag等,基本上每个常见的html标签均会对应一个tag。官方文档说明如下:
The nodes package has the concrete node implementations.
The tags package contains specific tags.
因此可以通过此方法直接判断一个节点是否某个标签内容。
其中用到的LinkFilter接口定义如下:
packageorg.ljh.search.html;
//本接口所定义的过滤器,用于判断url是否属于本次搜索范围。
publicinterfaceLinkFilter {
publicbooleanaccept(String url);
}
测试程序如下:
packageorg.ljh.search.html;
importjava.util.Iterator;
importjava.util.Set;
importorg.junit.Test;
publicclassHtmlParserToolTest {
@Test
publicvoidtestExtractLinks() {
String url = "http://www.baidu.com";
LinkFilter linkFilter = newLinkFilter(){
@Override
publicbooleanaccept(String url) {
if(url.contains("baidu")){
returntrue;
}else{
returnfalse;
}
}
};
Set urlSet = HtmlParserTool.extractLinks(url, linkFilter);
Iterator it = urlSet.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
输出结果如下:
http://www.hao123.com
http://www.baidu.com/
http://www.baidu.com/duty/
http://v.baidu.com/v?ct=301989888&rn=20&pn=0&db=0&s=25&word=
http://music.baidu.com
http://ir.baidu.com
http://www.baidu.com/gaoji/preferences.html
http://news.baidu.com
http://map.baidu.com
http://music.baidu.com/search?fr=ps&key=
http://image.baidu.com
http://zhidao.baidu.com
http://image.baidu.com/i?tn=baiduimage&ct=201326592&lm=-1&cl=2&nc=1&word=
http://www.baidu.com/more/
http://shouji.baidu.com/baidusearch/mobisearch.html?ref=pcjg&from=1000139w
http://wenku.baidu.com
http://news.baidu.com/ns?cl=2&rn=20&tn=news&word=
https://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F
http://www.baidu.com/cache/sethelp/index.html
http://zhidao.baidu.com/q?ct=17&pn=0&tn=ikaslist&rn=10&word=&fr=wwwt
http://tieba.baidu.com/f?kw=&fr=wwwt
http://home.baidu.com
https://passport.baidu.com/v2/?reg®Type=1&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F
http://v.baidu.com
http://e.baidu.com/?refer=888
;
http://tieba.baidu.com
http://baike.baidu.com
http://wenku.baidu.com/search?word=&lm=0&od=0
http://top.baidu.com
http://map.baidu.com/m?word=&fr=ps01000
智能推荐
分布式光纤传感器的全球与中国市场2022-2028年:技术、参与者、趋势、市场规模及占有率研究报告_预计2026年中国分布式传感器市场规模有多大-程序员宅基地
文章浏览阅读3.2k次。本文研究全球与中国市场分布式光纤传感器的发展现状及未来发展趋势,分别从生产和消费的角度分析分布式光纤传感器的主要生产地区、主要消费地区以及主要的生产商。重点分析全球与中国市场的主要厂商产品特点、产品规格、不同规格产品的价格、产量、产值及全球和中国市场主要生产商的市场份额。主要生产商包括:FISO TechnologiesBrugg KabelSensor HighwayOmnisensAFL GlobalQinetiQ GroupLockheed MartinOSENSA Innovati_预计2026年中国分布式传感器市场规模有多大
07_08 常用组合逻辑电路结构——为IC设计的延时估计铺垫_基4布斯算法代码-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏12次。常用组合逻辑电路结构——为IC设计的延时估计铺垫学习目的:估计模块间的delay,确保写的代码的timing 综合能给到多少HZ,以满足需求!_基4布斯算法代码
OpenAI Manager助手(基于SpringBoot和Vue)_chatgpt网页版-程序员宅基地
文章浏览阅读3.3k次,点赞3次,收藏5次。OpenAI Manager助手(基于SpringBoot和Vue)_chatgpt网页版
关于美国计算机奥赛USACO,你想知道的都在这_usaco可以多次提交吗-程序员宅基地
文章浏览阅读2.2k次。USACO自1992年举办,到目前为止已经举办了27届,目的是为了帮助美国信息学国家队选拔IOI的队员,目前逐渐发展为全球热门的线上赛事,成为美国大学申请条件下,含金量相当高的官方竞赛。USACO的比赛成绩可以助力计算机专业留学,越来越多的学生进入了康奈尔,麻省理工,普林斯顿,哈佛和耶鲁等大学,这些同学的共同点是他们都参加了美国计算机科学竞赛(USACO),并且取得过非常好的成绩。适合参赛人群USACO适合国内在读学生有意向申请美国大学的或者想锻炼自己编程能力的同学,高三学生也可以参加12月的第_usaco可以多次提交吗
MySQL存储过程和自定义函数_mysql自定义函数和存储过程-程序员宅基地
文章浏览阅读394次。1.1 存储程序1.2 创建存储过程1.3 创建自定义函数1.3.1 示例1.4 自定义函数和存储过程的区别1.5 变量的使用1.6 定义条件和处理程序1.6.1 定义条件1.6.1.1 示例1.6.2 定义处理程序1.6.2.1 示例1.7 光标的使用1.7.1 声明光标1.7.2 打开光标1.7.3 使用光标1.7.4 关闭光标1.8 流程控制的使用1.8.1 IF语句1.8.2 CASE语句1.8.3 LOOP语句1.8.4 LEAVE语句1.8.5 ITERATE语句1.8.6 REPEAT语句。_mysql自定义函数和存储过程
半导体基础知识与PN结_本征半导体电流为0-程序员宅基地
文章浏览阅读188次。半导体二极管——集成电路最小组成单元。_本征半导体电流为0
随便推点
【Unity3d Shader】水面和岩浆效果_unity 岩浆shader-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏18次。游戏水面特效实现方式太多。咱们这边介绍的是一最简单的UV动画(无顶点位移),整个mesh由4个顶点构成。实现了水面效果(左图),不动代码稍微修改下参数和贴图可以实现岩浆效果(右图)。有要思路是1,uv按时间去做正弦波移动2,在1的基础上加个凹凸图混合uv3,在1、2的基础上加个水流方向4,加上对雾效的支持,如没必要请自行删除雾效代码(把包含fog的几行代码删除)S..._unity 岩浆shader
广义线性模型——Logistic回归模型(1)_广义线性回归模型-程序员宅基地
文章浏览阅读5k次。广义线性模型是线性模型的扩展,它通过连接函数建立响应变量的数学期望值与线性组合的预测变量之间的关系。广义线性模型拟合的形式为:其中g(μY)是条件均值的函数(称为连接函数)。另外,你可放松Y为正态分布的假设,改为Y 服从指数分布族中的一种分布即可。设定好连接函数和概率分布后,便可以通过最大似然估计的多次迭代推导出各参数值。在大部分情况下,线性模型就可以通过一系列连续型或类别型预测变量来预测正态分布的响应变量的工作。但是,有时候我们要进行非正态因变量的分析,例如:(1)类别型.._广义线性回归模型
HTML+CSS大作业 环境网页设计与实现(垃圾分类) web前端开发技术 web课程设计 网页规划与设计_垃圾分类网页设计目标怎么写-程序员宅基地
文章浏览阅读69次。环境保护、 保护地球、 校园环保、垃圾分类、绿色家园、等网站的设计与制作。 总结了一些学生网页制作的经验:一般的网页需要融入以下知识点:div+css布局、浮动、定位、高级css、表格、表单及验证、js轮播图、音频 视频 Flash的应用、ul li、下拉导航栏、鼠标划过效果等知识点,网页的风格主题也很全面:如爱好、风景、校园、美食、动漫、游戏、咖啡、音乐、家乡、电影、名人、商城以及个人主页等主题,学生、新手可参考下方页面的布局和设计和HTML源码(有用点赞△) 一套A+的网_垃圾分类网页设计目标怎么写
C# .Net 发布后,把dll全部放在一个文件夹中,让软件目录更整洁_.net dll 全局目录-程序员宅基地
文章浏览阅读614次,点赞7次,收藏11次。之前找到一个修改 exe 中 DLL地址 的方法, 不太好使,虽然能正确启动, 但无法改变 exe 的工作目录,这就影响了.Net 中很多获取 exe 执行目录来拼接的地址 ( 相对路径 ),比如 wwwroot 和 代码中相对目录还有一些复制到目录的普通文件 等等,它们的地址都会指向原来 exe 的目录, 而不是自定义的 “lib” 目录,根本原因就是没有修改 exe 的工作目录这次来搞一个启动程序,把 .net 的所有东西都放在一个文件夹,在文件夹同级的目录制作一个 exe._.net dll 全局目录
BRIEF特征点描述算法_breif description calculation 特征点-程序员宅基地
文章浏览阅读1.5k次。本文为转载,原博客地址:http://blog.csdn.net/hujingshuang/article/details/46910259简介 BRIEF是2010年的一篇名为《BRIEF:Binary Robust Independent Elementary Features》的文章中提出,BRIEF是对已检测到的特征点进行描述,它是一种二进制编码的描述子,摈弃了利用区域灰度..._breif description calculation 特征点
房屋租赁管理系统的设计和实现,SpringBoot计算机毕业设计论文_基于spring boot的房屋租赁系统论文-程序员宅基地
文章浏览阅读4.1k次,点赞21次,收藏79次。本文是《基于SpringBoot的房屋租赁管理系统》的配套原创说明文档,可以给应届毕业生提供格式撰写参考,也可以给开发类似系统的朋友们提供功能业务设计思路。_基于spring boot的房屋租赁系统论文