java sql 写入万条数据_如何快速向数据库插1000万数据?4种方法对比,它简单却速度最快-程序员宅基地
技术标签: jdbctemplate常用方法 mysql 循环insert数据 mysql500万数据查询速度 Java千万级数据插入开启事务 java sql 写入万条数据 mybatis 返回50万条数据很慢
目录
- 场景介绍
- 项目配置
- Mybatis为什么慢?
- JdbcTemplate让我眼前一亮
- 原生JDBC就是快啊!
- 存储过程怎么样?
- 越简单越快
前言
一直有一种说法:批量插入大量数据到MySQL数据库,不要使用Mybatis、Hibernate之类的ORM框架,原因一般都是说性能不好,至于为什么不好好像没几个人能讲清楚的。
批量插入大量数据最优的方式是什么?网上也是众说纷纭。不如自己动手测试一下吧!
场景介绍
前几天公司项目进行压力测试,测试某个功能在大数据量(千万级)的情况下是否能够正常运行,可是项目还没有正式上线运营,数据库里只有少量开发时用的假数据。
没有数据怎么测试啊?这可愁坏测试的小姐姐们了,向我求助让我尽快往数据库中导入1000万数据给她们测试用。
于是接到任务:快速往MySQL数据库中导入1000万数据
项目配置
啥也不说了,抓紧时间开搞!
首先交代一下电脑环境:
- 操作系统:WIN10(专业版)
- 开发工具:IntelliJ IDEA Ultimate(2019.2.1)
- 项目框架:Spring Boot(2.2.5.RELEASE)
- 数据库:MySQL(5.7.27)
项目配置步骤:
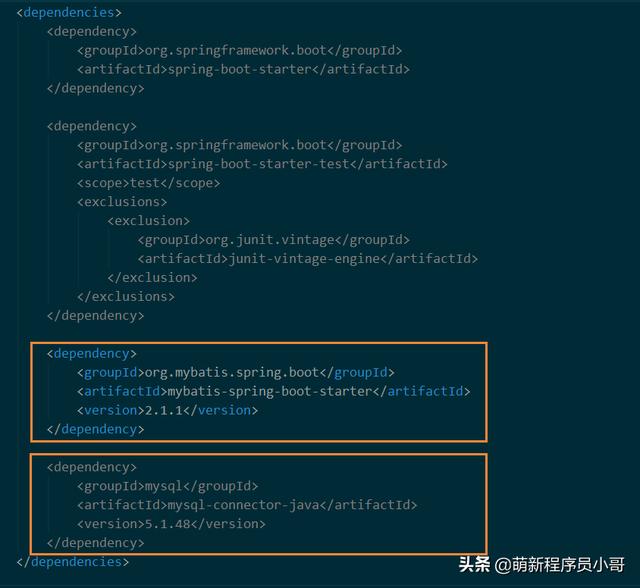
- 使用IDEA的Spring Initializr插件新建Spring Boot的项目,打开pom.xml,添加一些必要的Maven依赖,主要是mybatis-spring-boot-starter和mysql-connector-java;
- MySQL中新建一张user表,为了方便演示只保留id、昵称、年龄3个字段,建表语句;

- 再次打开pom.xml文件,添加mybatis generator插件用于自动生成mapper映射文件;

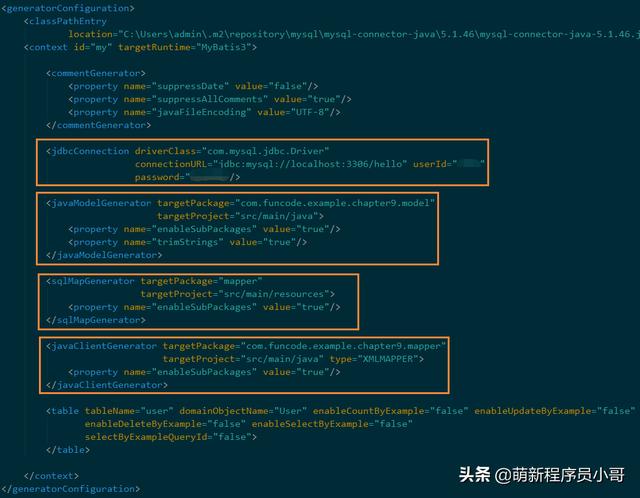
- 上一步添加了mybatis generator插件之后还不能直接使用,还需要在项目resources目录下新建一个配置文件generatorConfig.xml,里面主要需要配置数据库连接信息、Model文件生成目录、Mapper文件生成目录、以及xml文件生成目录;
- 打开resources目录下的application.properties(或是application.yml)文件,添加一下mybatis相关配置和项目数据库连接配置;

- 展示一下项目的完整结构
Mybatis为什么慢?
首先我们用Mybatis来测试一下,看看插入1000万条数据需要多长时间。
实现步骤:
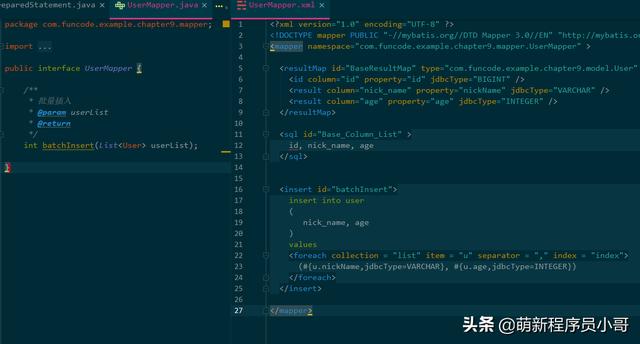
- 在UserMapper.java和UserMapper.xml文件中实现批量插入方法;
- 新建一个Test测试类实现随机生成1000万用户记录,并调用上步已经实现的批量插入方法将数据插入到MySQL数据库;
接下来就是正式测试了,没想到中间出了不少问题,在这里说明一下并附上解决方案。
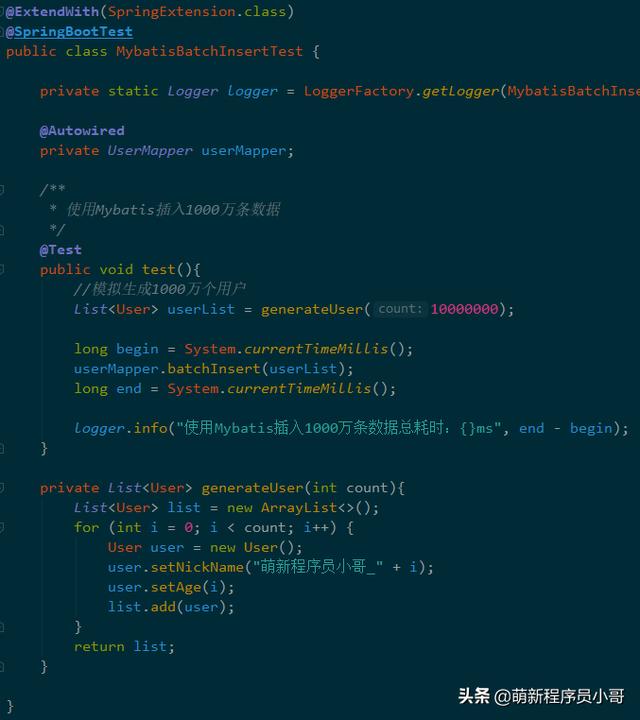
问题一:Java堆内存爆了!
原因分析:由于要生成1000万条用户记录,需要申请大量Java的堆内存,已经超出JVM设置的最大堆内存大小,导致OutOfMemoryError报错:
解决办法:增加堆内存。
JVM设置堆内存有两个参数:
- -Xms 用于设置堆内存初始值,一般建议设置为和最大值一样;
- -Xmx 用于设置堆内存最大值,默认值为物理内存的1/4;
因为我的电脑是32G内存,也就是说默认最大堆内存有8G,8G都不够的话,那我直接来个20G试试,IDEA菜单栏依次打开Run -> Edit Configurations:
修改步骤:
- 选中我们的测试类
- 在右边找到VM options选项,输入-Xms20480m -Xmx20480m

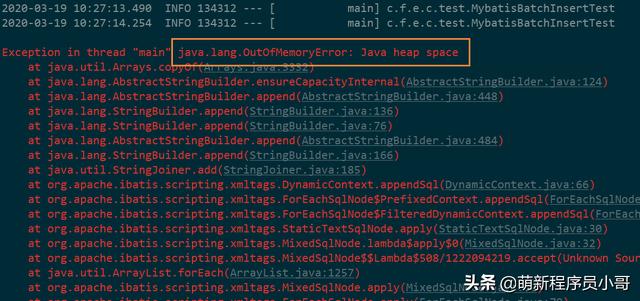
问题二:MySQL报错:Packet for query is too large
原因分析:因为发送到MySQL的数据量过大,超出了设置的最大值,导致报错:
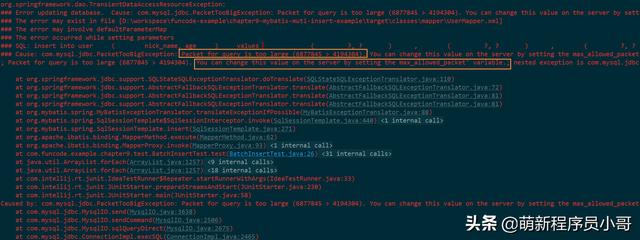
解决方案:修改MySQL服务器max_allowed_packet属性。
修改步骤:
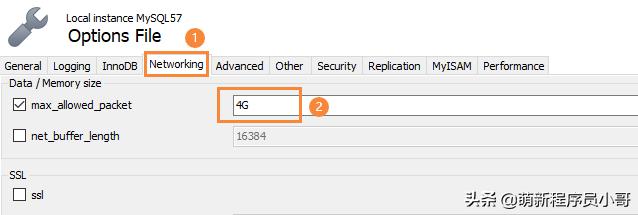
- 直接在MySQL安装目录下找到my.ini文件,在[mysqld]下面添加一行max_allowed_packet = 4G
- 通过MySQL客户端工具修改,这里以我常用的MySQL Workbench客户端来修改,菜单栏找到Server -> Options File,点击切换Networking标签:
Tip:不论哪种方式,修改完都要记得重启MySQL,否则修改不生效哦。
我们来看下执行结果:

结果:
使用Mybatis插入1000万条数据到MySQL数据库共花费了199.8秒!
这结果是快还是慢?我们来具体分析一下耗时分布情况。
分析:
方法:
JDBC驱动中有一个profileSQL属性,可以跟踪记录SQL执行时间,附上官方文档介绍:

所以我们需要将数据库连接加上profileSQL=true属性。
再次看下执行结果:

其中,duration指的是SQL执行的时间,也就是说MySQL服务器执行具体SQL语句的时间其实只有82.3秒,我们上面统计到Mybatis插入1000万条数据花了近200秒的时间,那么这中间的100多秒都干嘛去了?
分析控制台输出的日志之后我发现了蹊跷所在:从程序调用Mybatis的批量插入方法开始,到MySQL服务器执行SQL,这中间正好差了100多秒,会是巧合吗?
打断点Debug追踪到Mybatis解析SQL语句的方法:
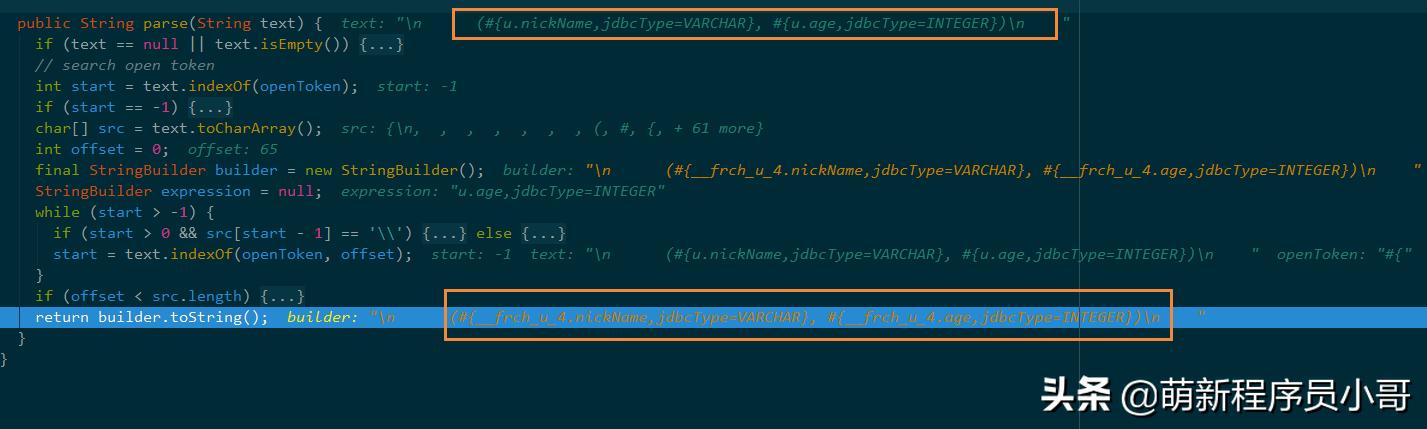
这parse方法首先会读取我们xml文件里的SQL模版拿到参数及参数类型信息,拼接生成SQL语句。
每条数据循环一次,那1000W条数据就要循环解析1000万次,不慢才怪!
JdbcTemplate让我眼前一亮
接下来使用Spring框架的JdbcTemplate来测试一下。
实现步骤:
- 同样的我们新建一个测试类,并用JdbcTemplate实现一个批量插入方法;
接下来就可以开始测试了,果然中间又出现了了问题。
问题一:调用JdbcTemplate的batchUpdate批量操作方法,结果却一条条的插数据?
首先看下控制台输出日志:
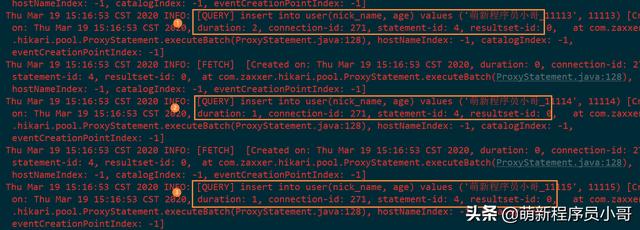
可以看到JdbcTemplate是将我们的数据一条条的发送到MySQL服务器的,每个插入耗时1毫秒,那么1秒钟可以插入1000条记录,那么1000万条数据就需要10000秒,大约需要2.78个小时。
原因分析:JDBC驱动默认不支持批量操作,会将SQL语句分拆再一条条发往MySQL服务器执行,打断点跟踪一下代码,看看是不是这样:
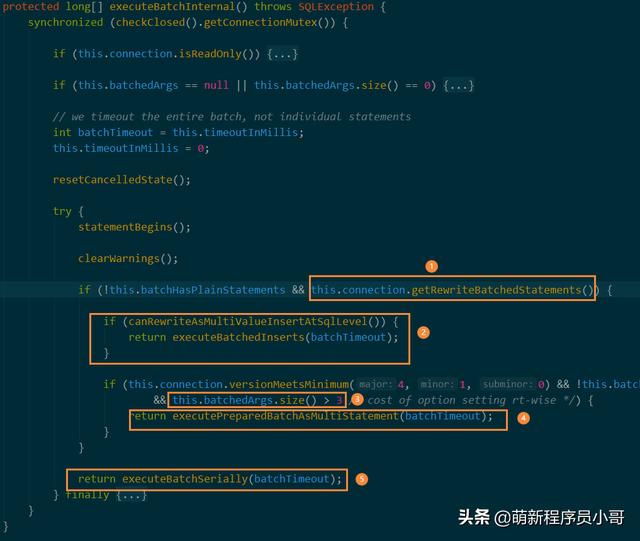
分析一下代码:
- 首先执行步骤1判断rewriteBatchedStatements属性,为false的话直接执行步骤5的逻辑:串行执行SQL语句,也就是一条条顺序执行;
- 如果rewriteBatchedStatements为true,那么首先会执行步骤2:判断是否为insert语句,结果为true则会改写SQL执行批量插入操作;
- 如果不是insert语句,再继续根据JDBC驱动版本以及数据量大小判断是否需要执行批量操作;
Tip:对于非insert的批量操作语句,如果数据量小于3条,那也只会一条条顺序执行,不会进行合并批量执行。
附上rewriteBatchedStatements官方文档:

大概看了一下,跟我们上面分析的一样,标示是否让JDBC驱动使用批量模式去改写SQL语句。
解决方案:数据库连接上加上rewriteBatchedStatements=true属性,开启批量操作支持。
再次看下执行结果:
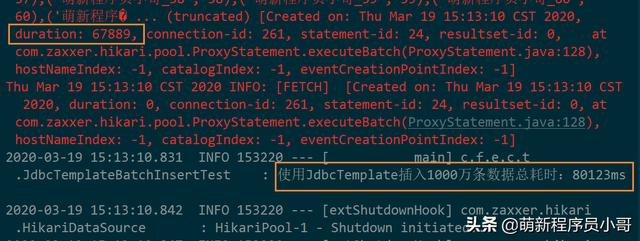
结果:
使用JdbcTemplate插入1000万条数据到MySQL数据库共花费了80.1秒!
分析:
一开始由于没有开启批量操作支持,所以导致MySQL只能一条条插入数据,原因在于我对JDBC驱动不够了解,看来以后还得加强学习。
开启批量操作支持后,通过日志可以观察到真正的SQL执行时间只有67.9秒,但整个插入操作用了80.1秒,中间差的10多秒中应该就是消耗在了改写SQL语句上了。
总得来说,JdbcTemplate批量插入大量数据的效率还不错,让我有眼前一亮的感觉。
原生JDBC就是快啊!
早有耳闻批量插入大量数据必须使用原生JDBC,百闻不如一见,接下来我就使用原生JDBC的方式来测试一下。
实现步骤:
- 同样的,我们新建一个测试类,并使用原生JDBC的方式实现一个批量插入方法;
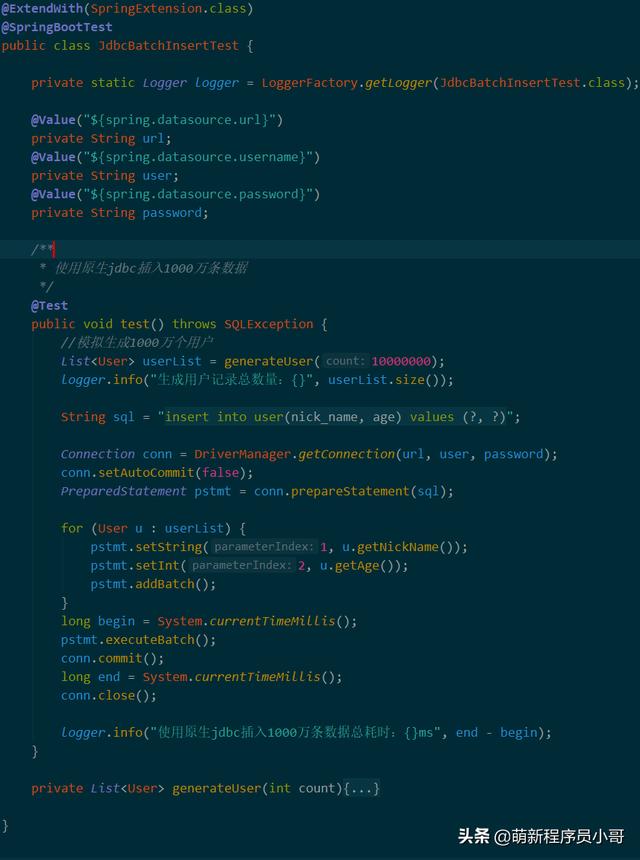
接下来就可以测试了,别担心,这次肯定不会再出问题了。
来看下执行结果:
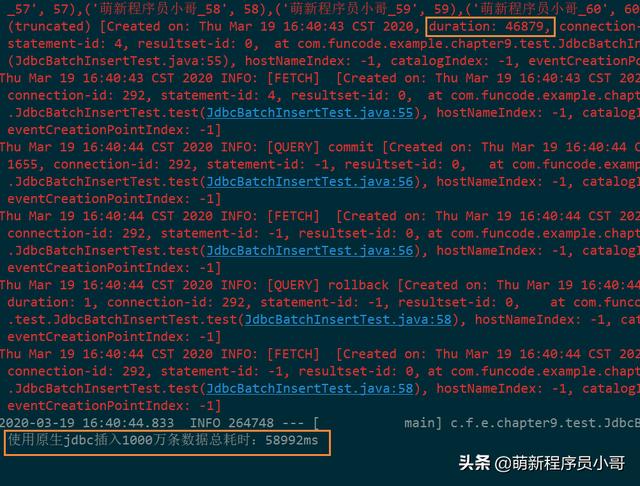
结果:使用原生JDBC的方式插入1000万条数据到MySQL数据库共花费了58.9秒!
分析:
原生JDBC写起来还是既简单又舒适啊,都多少年没写过了,但是越是简单的东西它越好用。
通过输出日志,我们可以看到整个方法执行时间为58.9秒,而SQL真正的执行时间为46.8秒,中间同样相差了10多秒,同样也是花在了改写SQL语句上,这一结果正好与上面JdbcTemplate的执行结果互相佐证,证明了我们的分析是正确的。
存储过程行不行?
最后使用存储过程的方式来试一下,说实话工作以来很少写存储过程,只好临时恶补了一波知识。
实现步骤:
- 首先编写批量插入的存储过程,功能其实很简单,接收一个外部传入的表示循环次数的参数,进行循环插入数据;
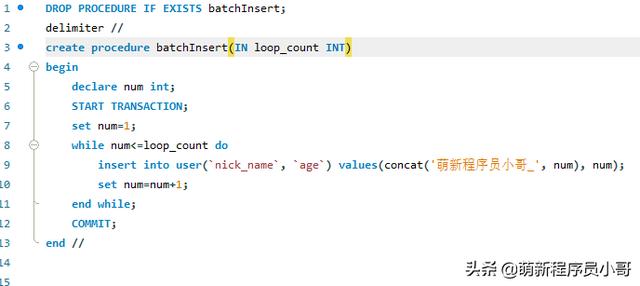
接下来我们调用存储过程,执行命令:
CALL batchInsert(10000000);等待执行完成,看下耗时情况:
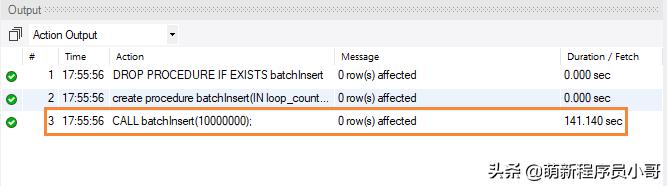
结果:
调用存储过程向MySQL数据库中批量插入1000万数据需要141.1秒。
分析:
存储过程需要141.1秒的时间我还是比较惊讶的,本来我对存储过程还是比较期待的。
仔细想想,其实存储过程用在这个场景并没有发挥出它的优势,时间长点也不奇怪。
为什么这么说?
首先我们来看看存储过程的一些特点:
- 可以封装一些复杂的业务逻辑,外部直接调用存储过程即可;
- 存储过程只在创建时编译一次,以后每次执行存储过程都不需再重新编译,使用存储过程可提高执行速度;
- 将操作直接放到数据库端执行,可以减少客户端与服务端进行网络通讯开销,提高通信效率;
其次我们再来看看存储过程用在我们场景是否合适:
- 我们使一次性提交所有数据,所以不存在多次通信增加耗时的操作,在这里存储过程的优势没有发挥出来;
- 在存储过程的insert语句中,我们使用了concat函数来拼接字符串,函数运算会降低SQL执行效率;
所以说存储过程在我们这个业务场景并没有发挥出它的优势。
越简单越快
面对快速往MySQL数据库中导入1000万数据这个问题,我们通过Mybatis、JdbcTemplate、原生JDBC以及存储过程4种方式分别进行测试,得出了最终结果:
插入速度:原生JDBC > JdbcTemplate > 存储过程 > Mybatis
结果分析:
Mybatis由于封装程度较高,底层有一个SQL模版解析和SQL拼接的过程,所以导致速度较慢;
存储过程一来由于本应用场景不太适合没有发挥出优势,二来由于SQL语句中加入了函数运算拖累了执行效率;
JdbcTemplate是Spring框架为了方便开发者调用对原生JDBC的一个轻度封装,虽然有点小插曲,但整体来看插入效率还可以;
原生JDBC是最最最基础的插入方式了,每个人刚学Java的时候应该都学过,没有过多花里胡哨的封装,简单实用。
总结:
越简单越实用,原生JDBC第一名实至名归!
“分享干货,收获快乐”
我是萌新程序员小哥,喜欢我的文章欢迎 转发 及 关注,我会经常与大家分享工作当中的实用技巧与经验。
智能推荐
微信小程序入门教程 --(保姆级)-程序员宅基地
文章浏览阅读6.7k次,点赞24次,收藏92次。小程序入门保姆级教程_微信小程序入门
计算机毕设 深度学习猫狗分类 - python opencv cnn_毕业设计可以用猫狗大战吗-程序员宅基地
文章浏览阅读559次。 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是 **基于深度学习猫狗分类 **学长这里给一个题目综合评分(每项满分5分)难度系数:3分工作量:3分创新点:3分。_毕业设计可以用猫狗大战吗
手把手教你安装Eclipse最新版本的详细教程 (非常详细,非常实用)_eclipse安装教程-程序员宅基地
文章浏览阅读4.4k次,点赞2次,收藏16次。写这篇文章的由来是因为后边要用这个工具,但是由于某些原因有部分小伙伴和童鞋们可能不会安装此工具,为了方便小伙伴们和童鞋们的后续学习和不打击他们的积极性,因为80%的人都是死在工具的安装这第一道门槛上,这门槛说高也不高说低也不是太低。所以就抽时间水了这一篇文章。_eclipse安装教程
分享11个web前端开发实战项目案例+源码_前端项目实战案例-程序员宅基地
文章浏览阅读4.1w次,点赞12次,收藏193次。小编为大家收集了11个web前端开发,大企业实战项目案例+5W行源码!拿走玩去吧!1)小米官网项目描述:首先选择小米官网为第一个实战案例,是因为刚开始入门,有个参考点,另外站点比较偏向目前的卡片式设计,实现常见效果。目的为学者练习编写小米官网,熟悉div+css布局。学习资料的话可以加下web前端开发学习裙:600加上610再加上151自己去群里下载下。项目技术:HTML+CSS+Div布局2)迅雷官网项目描述:此站点特效较多,所以通过练习编写次站点,学生可以更多练习CSS3的新特性过渡与动画的实_前端项目实战案例
计算质数-埃里克森筛法(间隔黄金武器)-程序员宅基地
文章浏览阅读73次。素数,不同的质数,各种各样的问题总是遇到的素数。以下我们来说一下求素数的一种比較有效的算法。就是筛法。由于这个要求得1-n区间的素数仅仅须要O(nloglogn)的时间复杂度。以下来说一下它的思路。思路:如今又1-n的数字。素数嘛就是除了1和本身之外没有其它的约数。所以有约数的都不是素数。我们从2開始往后遍历,是2的倍数的都不是素数。所以我们把他们划掉然后如...
探索Keras DCGAN:深度学习中的创新图像生成-程序员宅基地
文章浏览阅读532次,点赞9次,收藏14次。探索Keras DCGAN:深度学习中的创新图像生成项目地址:https://gitcode.com/jacobgil/keras-dcgan在数据驱动的时代,图像生成模型已经成为人工智能的一个重要领域。其中,Keras DCGAN 是一个基于 Keras 的实现,用于构建和训练 Deep Convolutional Generative Adversarial Networks(深度卷积生...
随便推点
WebSphere MQ6.0 for redhat4.6 setup_websphere mq6.0下载-程序员宅基地
文章浏览阅读956次。WebSphere MQ6.0 for redhat4.6 setup分类: WebSphere 2010-04-12 14:45650人阅读 评论(0)收藏举报websphereredhatmanageribm消息中间件statisticsWebsphere MQ是IBM的商业消息中间件(Commercial Messaging Middlewar_websphere mq6.0下载
Spring——Bean 的生命周期_spring bean的生命周期-程序员宅基地
文章浏览阅读1.1w次,点赞11次,收藏49次。目录一、Bean 的生命周期二、代码演示三、主要步骤简述一、Bean 的生命周期 对于普通的 Java 对象,new 的时候会去创建对象,而当它没有任何引用的时候则被垃圾回收机制回收。相较于前者,由Spring IoC 容器托管的对象,它们的生命周期完全由容器控制。Spring 中每个 Bean 的生命周期如下:对于 ApplicationContext 容器,当容器启动结束后,实例化所有的 Bean。设置对象属性,即依赖注入,动态将依赖关系注入到对象中。紧接着,Spring 会检测该对象_spring bean的生命周期
matlab_matlab fat-程序员宅基地
文章浏览阅读94次。为什么logical==0?_matlab fat
HTML标签分类及转义字符_ol是单标记还是双标记-程序员宅基地
文章浏览阅读302次。一. HTML标签分类1.根据标签个数分类。 单标签:只有一个标签。 <br>, <hr>,<img>,<meta>, 实现一个特定的功能。 双标签:既有开始标签,也有结束标签。 Html,head,Body,title,h1~h6,p,a,ul,li,ol,strong,em。2.根据标签特性分类(网页效果)。 2.1行属性..._ol是单标记还是双标记
什么是配置_基于配置是什么意思-程序员宅基地
文章浏览阅读1.6k次。应用程序在启动和运行的时候往往需要读取一些配置信息,配置基本上伴随着应用程序的整个生命周期,比如:数 据库连接参数、启动参数等。配置主要有以下几个特点:配置是独立于程序的只读变量配置对于程序是只读的,程序通过读取配置来改变自己的行为,但是程序不应该去改变配置配置伴随应用的整个生命周期配置贯穿于应用的整个生命周期,应用在启动时通过读取配置来初始化,在运行时根据配置调整行为。比如:启动时需要读取服务的端口号、系统在运行过程中需要读取定时策略执行定时任务等。配置可以有多种加载方式常见的有程序内部_基于配置是什么意思
二、使用GObject——一个简单类的实现-程序员宅基地
文章浏览阅读170次。Glib库实现了一个非常重要的基础类--GObject,这个类中封装了许多我们在定义和实现类时经常用到的机制: 引用计数式的内存管理 对象的构造与析构 通用的属性(Property)机制 Signal的简单使用方式 很多使用GObject..._