python求解整数规划_如何用python结合cplex求解混合整数规划问题-程序员宅基地
技术标签: python求解整数规划
第一步:注册IBM id账号
第二步:下载相关系统的CPLEX(windows/linux/mac)
这里需要系统中安装有JAVA,选择 open with Java web start launcher (需要下载JAVA),打开后就开始进入下载页面。
补充JAVA安装:
备注:JAVA可以通过rpm包安装,或者是bin文件安装。Rpm安装可以直接双击就可以打开jnlp后缀的文件,bin文件安装的话,需要在图形界面的命令行下执行:javaws ***.jnlp打开。我采用的是bin文件安装。
1、下载你想要的java版本压缩包。
JRE下载:
JDK下载:
2、对下载的文件进行解压
3、修改环境变量:
vim ~/.bashrc
#加入以下内容
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_144
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#保存后使之生效
source ~/.bashrc
第三步:下载完.bin文件后,修改文件的权限chmod +x filename.bin。然后用命令执行./filename.bin。进入安装。安装过程中需要设置安装路径,所以最好使用超级权限进行安装。默认路径为:/opt/ibm/ILOG/CPLEX_Studio_Community127
第四步:设置 CPLEX 的 Python API
CPLEX 的 Python API 属于 IBM ILOG CPLEX Optimization Studio 的一部分。
与CPLEX Python API 关联的模块驻留在目录 yourCPLEXhome/python/VERSION/PLATFORM 中(或文件夹 yourCPLEXhome\python\VERSION\PLATFORM 中),此处 yourCPLEXhome 指定 CPLEX 安装为 IBM ILOG CPLEX Optimization Studio 一部分的位置,VERSION 指定与 CPLEX 兼容的 Python 版本,而 PLATFORM 表示操作系统与编译器的组合。
有两种可相互替代的方法来设置 CPLEX 的 Python API。
• 首选且最常用的方法是使用位于目录 yourCPLEXhome/python/VERSION/PLATFORM 中(或文件夹 yourCPLEXhome\python\VERSION\PLATFORM 中)的脚本 setup.py。
• 或者,也可以将环境变量 PYTHONPATH 设置为 yourCPLEXhome/python/VERSION/PLATFORM 并通过 CPLEX 来开始运行 Python 脚本。
在以下段落中对这两种方法均进行了进一步详述。
使用脚本 setup.py
要在系统上安装 CPLEX-Python 模块,请使用位于 yourCplexhome/python/VERSION/PLATFORM 中的脚本 setup.py。 如果要将 CPLEX-Python 模块安装在非缺省位置,请使用选项 --home 识别安装目录。 例如,要将 CPLEX-Python 模块安装在缺省位置,请从命令行使用以下命令:
python setup.py install
要安装在目录 yourPythonPackageshome/cplex 中,请从命令行使用以下命令:
python setup.py install --home yourPythonPackageshome/cplex
这两个命令(缺省和指定主目录)均会调用 Python 包 distutils。 有关适用于该软件包的其他选项,请参考 Python distutils 的文档。
设置环境变量 PYTHONPATH
如果并行运行 CPLEX 的多个版本,那么请使用此方法:通过环境变量 PYTHONPATH 来向 Python 安装声明 CPLEX 及其 Python API 的位置。
要开始使用 CPLEX Python API,请将 Python 路径环境变量 PYTHONPATH 设置为值 yourCplexhome/python/VERSION/PLATFORM。 通过设置此环境变量,该版本的 Python 可以找到其所需的 CPLEX 模块以运行使用 CPLEX Python API 的 Python 命令和脚本。
后续步骤
通过这些可相互替代的方法之一设置 Python 环境后,便可以前进至启动 CPLEX Python API主题。
第五步:实例

Python -- version 2.7
有3个不同求解方式:
execfile("cplexpypath.py")
import cplex
from cplex.exceptions import CplexError
import sys
# data common to all populateby functions
my_obj = [1.0, 2.0, 3.0]
my_ub = [40.0, cplex.infinity, cplex.infinity]
my_colnames = ["x1", "x2", "x3"]
my_rhs = [20.0, 30.0]
my_rownames = ["c1", "c2"]
my_sense = "LL"
def populatebyrow(prob):
prob.objective.set_sense(prob.objective.sense.maximize)
# since lower bounds are all 0.0 (the default), lb is omitted here
prob.variables.add(obj = my_obj, ub = my_ub, names = my_colnames)
# can query variables like the following bounds and names:
# lbs is a list of all the lower bounds
lbs = prob.variables.get_lower_bounds()
# ub1 is just the first lower bound
ub1 = prob.variables.get_upper_bounds(0)
# names is ["x1", "x3"]
names = prob.variables.get_names([0, 2])
rows = [[[0,"x2","x3"],[-1.0, 1.0,1.0]],
[["x1",1,2],[ 1.0,-3.0,1.0]]]
prob.linear_constraints.add(lin_expr = rows, senses = my_sense,
rhs = my_rhs, names = my_rownames)
# because there are two arguments, they are taken to specify a range
# thus, cols is the entire constraint matrix as a list of column vectors
cols = prob.variables.get_cols("x1", "x3")
def populatebycolumn(prob):
prob.objective.set_sense(prob.objective.sense.maximize)
prob.linear_constraints.add(rhs = my_rhs, senses = my_sense,
names = my_rownames)
c = [[[0,1],[-1.0, 1.0]],
[["c1",1],[ 1.0,-3.0]],
[[0,"c2"],[ 1.0, 1.0]]]
prob.variables.add(obj = my_obj, ub = my_ub, names = my_colnames,
columns = c)
def populatebynonzero(prob):
prob.objective.set_sense(prob.objective.sense.maximize)
prob.linear_constraints.add(rhs = my_rhs, senses = my_sense,
names = my_rownames)
prob.variables.add(obj = my_obj, ub = my_ub, names = my_colnames)
rows = [0,0,0,1,1,1]
cols = [0,1,2,0,1,2]
vals = [-1.0,1.0,1.0,1.0,-3.0,1.0]
prob.linear_constraints.set_coefficients(zip(rows, cols, vals))
# can also change one coefficient at a time
# prob.linear_constraints.set_coefficients(1,1,-3.0)
# or pass in a list of triples
# prob.linear_constraints.set_coefficients([(0,1,1.0), (1,1,-3.0)])
def lpex1(pop_method):
try:
my_prob = cplex.Cplex()
if pop_method == "r":
handle = populatebyrow(my_prob)
if pop_method == "c":
handle = populatebycolumn(my_prob)
if pop_method == "n":
handle = populatebynonzero(my_prob)
my_prob.solve()
except CplexError, exc:
print exc
return
numrows = my_prob.linear_constraints.get_num()
numcols = my_prob.variables.get_num()
# solution.get_status() returns an integer code
print "Solution status = " , my_prob.solution.get_status(), ":",
# the following line prints the corresponding string
print my_prob.solution.status[my_prob.solution.get_status()]
print "Solution value = ", my_prob.solution.get_objective_value()
slack = my_prob.solution.get_linear_slacks()
pi = my_prob.solution.get_dual_values()
x = my_prob.solution.get_values()
dj = my_prob.solution.get_reduced_costs()
for i in range(numrows):
print "Row %d: Slack = %10f Pi = %10f" % (i, slack[i], pi[i])
for j in range(numcols):
print "Column %d: Value = %10f Reduced cost = %10f" % (j, x[j], dj[j])
my_prob.write("lpex1.lp")
if __name__ == "__main__":
if len(sys.argv) != 2 or sys.argv[1] not in ["-r", "-c", "-n"]:
print "Usage: lpex1.py -X"
print " where X is one of the following options:"
print " r generate problem by row"
print " c generate problem by column"
print " n generate problem by nonzero"
print " Exiting..."
sys.exit(-1)
lpex1(sys.argv[1][1])
else:
prompt = """Enter the letter indicating how the problem data should be populated:
r : populate by rows
c : populate by columns
n : populate by nonzeros\n ? > """
r = 'r'
c = 'c'
n = 'n'
lpex1(input(prompt))
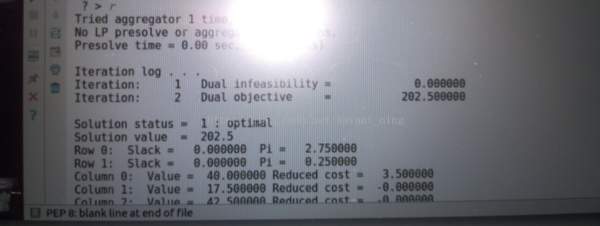
选择r参数,求解结果如下:
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象