metaq学习笔记-程序员宅基地
简介
metaq作为一款消息中间件,是支撑双11最为核心的系统之一,解耦收发双方,使得系统异步化,同时利用消息中间件堆积消息的功能,可以使得下游系统在可以慢慢消费消息,增强系统的缓冲能力,达到“削峰填谷”的目的
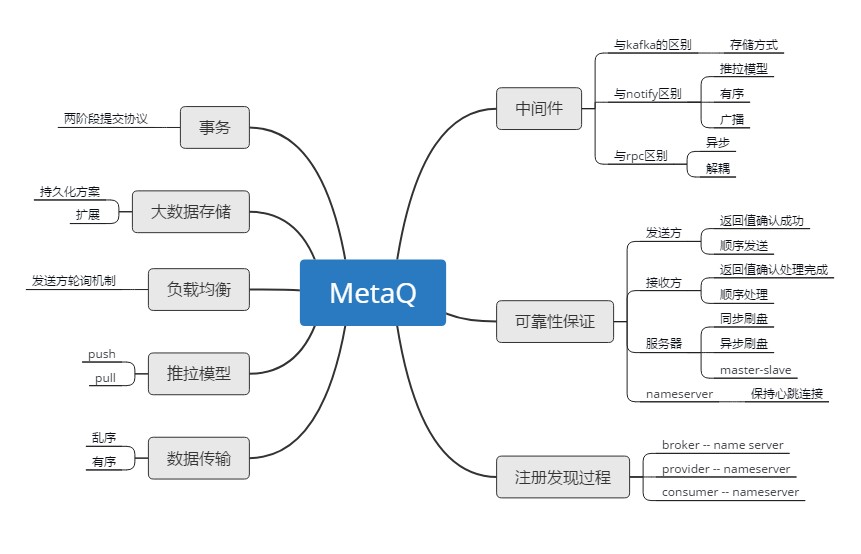
思维导图
在学习前先建立了思维导图,这样在学习过程中逐步深入,理解更加透彻
流程
发送端
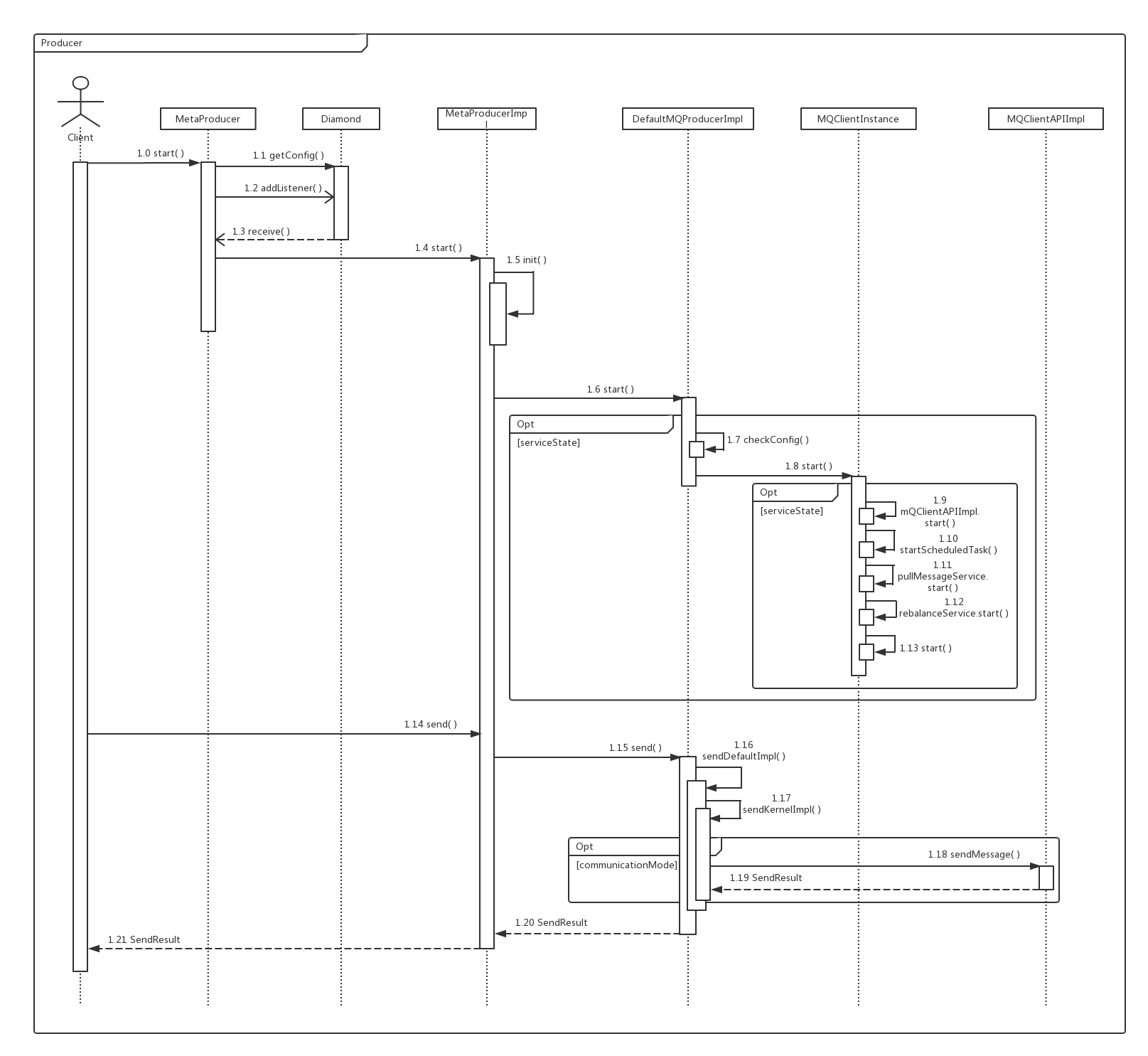
1. UML图
2. 类
2.1 MetaProducer
发送端,可通过该类实例对象指定发送端分组(producerGroup),启动程序
2.2 Diamond
持久化配置中心,用于获取配置信息
2.3 MetaProducerImpl
用于初始化、注册埋点
2.4 DefaultMQProducerImpl
检查配置,注册发送方
2.5 MQClientInstance
若程序处于初始化状态,开启定时任务、拉取消息服务、负载平衡服务
2.6 MQClientAPIImpl
调用底层的 netty client 发送数据
metaq 的代码编写风格较为清爽,基本调用顺序为 MetaProducer --> MetaProducerImpl --> DefaultMQProducerImpl --> MQClientAPIImpl
3. 流程
具体流程见UML图中操作顺序,这里只列出重要的步骤
3.1 start
开启服务,程序入口
3.2 getConfig
获取配置信息,调用的是Diamond接口,本质是通过httpGet请求,使用netty从持久化配置中心下载配置文件,定位参数是指定的分组名(producerGroup)
3.3 addListener
添加监听,如果Diamond配置中心有数据变化,可获得新的数据
3.4 receive
通过设置AllowPushInterval变量,一分钟后再响应服务器配置变化
3.5 init
初始化,设置最大消息大小、埋点,这里设置的hook在最终发送消息时会依次调用
3.6 start
DefaultMQProducerImpl 的 start 方法,根据serviceState决定执行流程;注意这里程序的入口包含参数 startFactory,boolean 类型判断是否需要开启服务,调用顺序为 DefaultMQProducerImpl.start( ) --> MQClientInstance.start( ) --> DefaultMQProducerImpl.start( ),只是在程序第二次调用时将标记位设为false
3.7 checkConfig
检查配置,判断分组名是否符合规范
3.8 start
开启MQClientInstance的服务,启动mqClientAPIImpl(底层netty通信客户端)、startScheduledTask(定时任务)、rebalanceService(负载均衡)、defaultMQProducerImpl
3.9 send
发送消息,此前需要对消息进行封装,指定消息主题topic、标签tag、内容body,其中通过topic即可实现收发双方的通信,接收方可以通过tag进行消息过滤
3.10 sendDefaultImpl
发送方法的默认实现,根据消息的发送方式选择不同的方法
3.11 sendKernelImpl
封装消息,执行之前设置的hook
3.1 sendMessage
调用底层的netty客户端发送消息,并返回SendResult
接收端
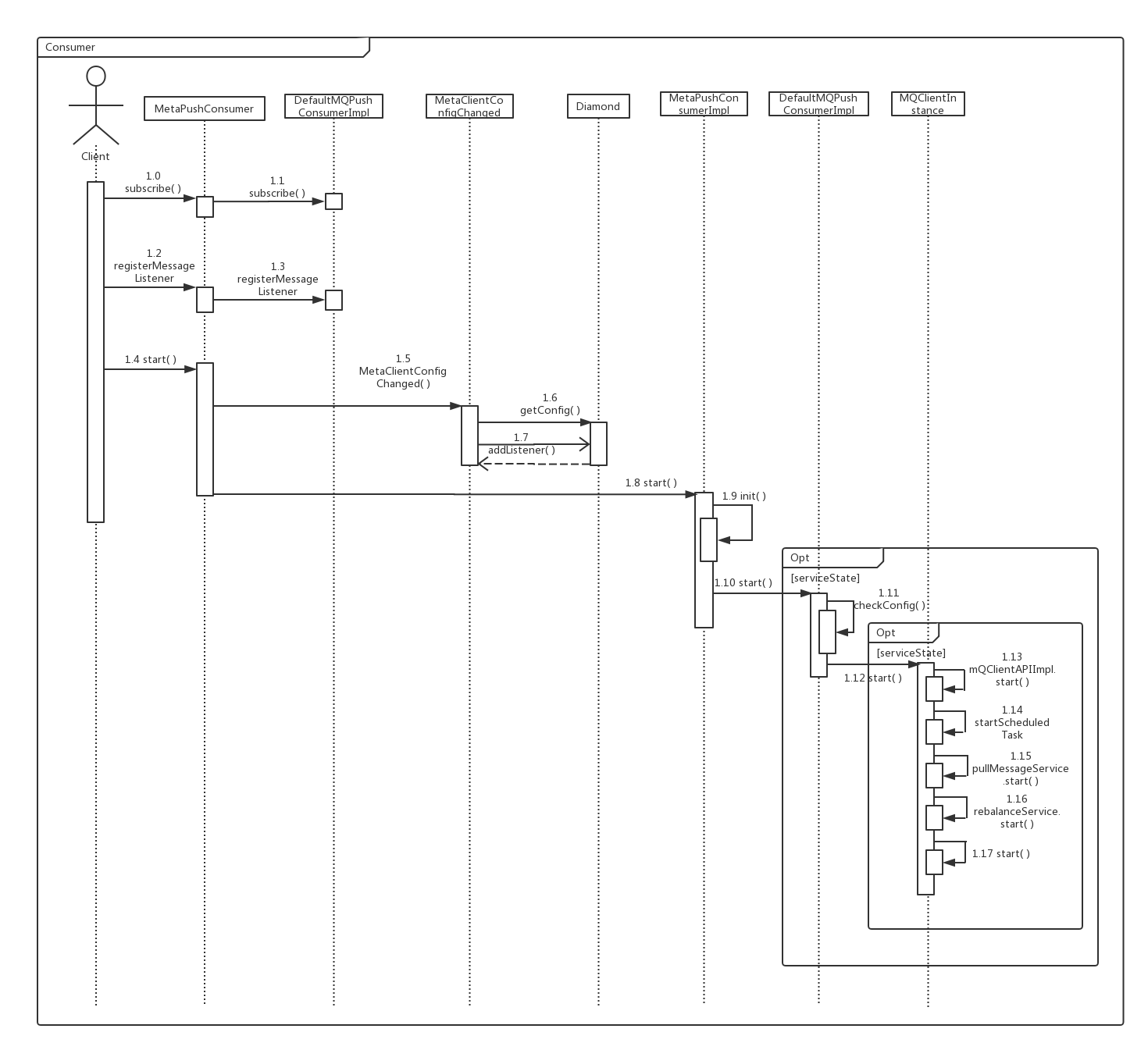
1. UML图
2. 类
2.1 MetaPushConsumer
接收方对象,程序入口,可订阅主题、设置监听、开启服务
2.2 DefaultMQPushConsumerImpl
默认实现方式,用于订阅和设置监听
2.3 MetaClientConfigChanged
用于获取配置
2.4 Diamond
调用接口,提供从持久化配置中心获取配置及设置监听的功能
2.5 MetaPushConsumerImpl
用于初始化服务
2.6 DefaultMQPushConusmerImpl
检查配置,开启服务
2.7 MQClientInstance
用于开启负载均衡、拉取消息等服务
可以看出,接收方和发送发的代码结构、类的命名方式极为相似,类的调用流程为 MetaPushConsumer --> DefaultMQPushConsumerImpl --> MetaPushConsumerImpl --> DefaultMQPushConsumerImpl --> MQClientInstance
3. 流程
具体流程见UML图中操作顺序,这里只列出重要的步骤
3.1 subscribe
程序入口,订阅相应主题,这里包含两个参数
3.1.1 topic:订阅主题,metaq发送发接收方通信的标识符,只要主题一致即可接收消息
3.1.2 subExpression:标记位tag,使用方式为“tag1 || tag2 || tag3”或者“*”,用于接收方过滤消息
3.2 registerMessageListener
注册消息监听,这里指定接受消息后的处理方式
3.3 getConfig
获取配置,与发送发方法一致
3.4 addListener
设置监听,当配置更新时获取新的信息
3.5 init
初始化,埋点
3.6 chechConfig
检查配置
3.7 mQClientAPIImpl.start( )、startScheduledtask( )、pullMessageService.start( )、rebalanceService.start( )
与发送方类似
可以看出,metaq的代码编写风格极为规整,发送方接收方结构一致,方便阅读
broker
broker的源代码暂无
源码解析
上述思维导图中,通过阅读源码,重点希望解决以下问题
1. 通讯建立
全网拓扑如下
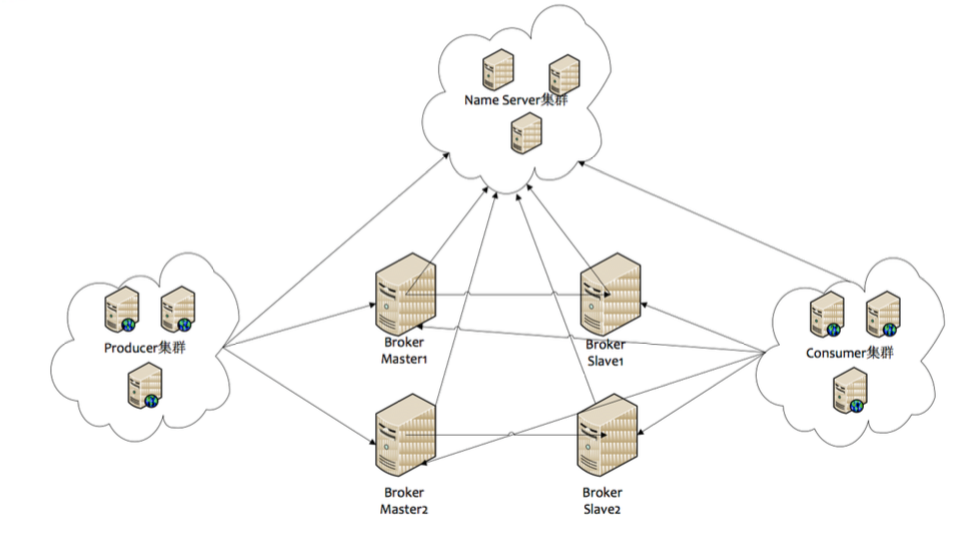
各组件功能为:
Name Server:注册服务器,需要将topic注册到上面,对应的操作是在metaq平台上发布topic(http://ons-api.taobao.net)
Broker:存储转发服务器,每个broker需要与所有的name server建立长连接,从而获取topic信息;分为master和容灾的slaver
Producer:消息发送方,需要与其中一个name server建立连接,获得路由信息,再与主题对应的broker建立长连接且定时向master发送心跳;消息由producer发送到master,再由master同步到所有broker
Consumer:消息接收方,需要与其中一个name server建立连接,获得路由信息,再向提供服务的master、slaver建立长连接,具体接收消息时刻选择broker
这里需要建立的连接包括:
| Producer | Consumer | Name Server | Broker | |
| Producer | ---- | 多对多 | 多对一 | 多对多 |
| Consumer | ---- | 多对一 | 多对多 | |
| Name Server | ---- | 多对一 | ||
| Broker | ---- |
1.1 producer <--> name server
producer在初始化阶段需要与其中一个name server建立长连接,获得broker路由信息
1.1.1 获取name server 地址
源码提供了两种获取name server的地址,,默认地址为:http://jmenv.tbsite.net:8080/rocketmq/nsaddr
MixAll
//提供两种方式来指定获取name server地址:system environment variables 和 Java option
//默认采用后者
public static String getWSAddr() {
String wsDomainName = System.getProperty("rocketmq.namesrv.domain", DEFAULT_NAMESRV_ADDR_LOOKUP);
String wsDomainSubgroup = System.getProperty("rocketmq.namesrv.domain.subgroup", "nsaddr");
String wsAddr = "http://" + wsDomainName + ":8080/rocketmq/" + wsDomainSubgroup;
if (wsDomainName.indexOf(":") > 0) {
wsAddr = "http://" + wsDomainName + "/rocketmq/" + wsDomainSubgroup;
}
return wsAddr;
}producer在初始化时通过向固定地址发送httpGet请求,从而获得name server地址
TopAddressing
public final String fetchNSAddr(boolean verbose, long timeoutMills) {
String url = this.wsAddr;
try {
if (!UtilAll.isBlank(this.unitName)) {
url = url + "-" + this.unitName + "?nofix=1";
}
HttpTinyClient.HttpResult result = HttpTinyClient.httpGet(url, null, null, "UTF-8", timeoutMills);
if (200 == result.code) {
String responseStr = result.content;
if (responseStr != null) {
return clearNewLine(responseStr);
} else {
log.error("fetch nameserver address is null");
}
} else {
log.error("fetch nameserver address failed. statusCode=" + result.code);
}
} catch (IOException e) {
if (verbose) {
log.error("fetch name server address exception", e);
}
}
if (verbose) {
String errorMsg =
"connect to " + url + " failed, maybe the domain name " + MixAll.getWSAddr() + " not bind in /etc/hosts";
errorMsg += FAQUrl.suggestTodo(FAQUrl.NAME_SERVER_ADDR_NOT_EXIST_URL);
log.warn(errorMsg);
}
return null;
}1.1.2 与name server通信,获取主题路由信息,返回值为TopicRouteData,即主题对应的broker地址
在metaq中,所有请求的封装格式统一,区别在于请求码,最终通过netty client通信
MQClientAPIImpl
public TopicRouteData getTopicRouteInfoFromNameServer(final String topic, final long timeoutMillis, boolean allowTopicNotExist) throws MQClientException, InterruptedException, RemotingTimeoutException, RemotingSendRequestException, RemotingConnectException {
GetRouteInfoRequestHeader requestHeader = new GetRouteInfoRequestHeader();
requestHeader.setTopic(topic);
RemotingCommand request = RemotingCommand.createRequestCommand(RequestCode.GET_ROUTEINTO_BY_TOPIC, requestHeader);
RemotingCommand response = this.remotingClient.invokeSync(null, request, timeoutMillis);
assert response != null;
switch (response.getCode()) {
case ResponseCode.TOPIC_NOT_EXIST: {
if (allowTopicNotExist && !topic.equals(MixAll.DEFAULT_TOPIC)) {
log.warn("get Topic [{}] RouteInfoFromNameServer is not exist value", topic);
}
break;
}
case ResponseCode.SUCCESS: {
byte[] body = response.getBody();
if (body != null) {
return TopicRouteData.decode(body, TopicRouteData.class);
}
}
default:
break;
}
throw new MQClientException(response.getCode(), response.getRemark());
}1.2 producer <--> broker
遍历brokerAddrTable,对获取到的broker地址发送心跳sendHeartbeat建立长连接
MQClientInstance
private void sendHeartbeatToAllBroker() {
final HeartbeatData heartbeatData = this.prepareHeartbeatData();
final boolean producerEmpty = heartbeatData.getProducerDataSet().isEmpty();
final boolean consumerEmpty = heartbeatData.getConsumerDataSet().isEmpty();
if (producerEmpty && consumerEmpty) {
log.warn("sending heartbeat, but no consumer and no producer");
return;
}
if (!this.brokerAddrTable.isEmpty()) {
long times = this.sendHeartbeatTimesTotal.getAndIncrement();
Iterator<Entry<String, HashMap<Long, String>>> it = this.brokerAddrTable.entrySet().iterator();
while (it.hasNext()) {
Entry<String, HashMap<Long, String>> entry = it.next();
String brokerName = entry.getKey();
HashMap<Long, String> oneTable = entry.getValue();
if (oneTable != null) {
for (Map.Entry<Long, String> entry1 : oneTable.entrySet()) {
Long id = entry1.getKey();
String addr = entry1.getValue();
if (addr != null) {
if (consumerEmpty) {
if (id != MixAll.MASTER_ID)
continue;
}
try {
int version = this.mQClientAPIImpl.sendHearbeat(addr, heartbeatData, 3000);
if (!this.brokerVersionTable.containsKey(brokerName)) {
this.brokerVersionTable.put(brokerName, new HashMap<String, Integer>(4));
}
this.brokerVersionTable.get(brokerName).put(addr, version);
if (times % 20 == 0) {
log.info("send heart beat to broker[{} {} {}] success", brokerName, id, addr);
log.info(heartbeatData.toString());
}
} catch (Exception e) {
if (this.isBrokerInNameServer(addr)) {
log.info("send heart beat to broker[{} {} {}] failed", brokerName, id, addr);
} else {
log.info("send heart beat to broker[{} {} {}] exception, because the broker not up, forget it", brokerName, id, addr);
}
}
}
}
}
}
}
}consumer端连接建立过程和发送发相同,包含consumer <--> name server 和 consumer <--> broker,源码中consumer最终调用的是与producer相同的方法(MQClientInstance),这里就不再重复
broker需要与所有name server建立连接,从而获得topic信息,这里没有broker端源码,详细过程略
2. 存储方案
ata上不少文章都有对metaq物理存储的讲解,但这些内容大都混淆了metaq和kafka的存储结构,经过查阅相关资料,总结如下
2.1 kafka
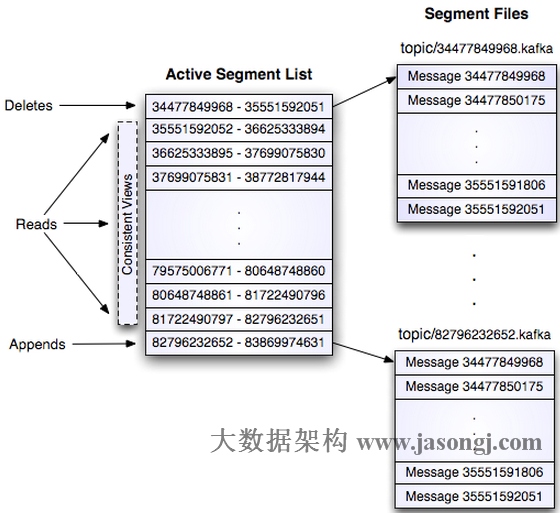
kafka采取的是分区+分段的方式,参考自Kafka设计解析(一)- Kafka背景及架构介绍
分区:partition,将物理broker映射为逻辑分区,实现了水平拓展,这样在传输时只需指定分区号即可,而broker可对应多个分区,这样就实现了分布式的存储
分段:segment,实际存储结构,包含数据文件和索引文件,顺序存储加快了速度,数据文件命名采用偏移量的方式,这样索引文件只需记录偏移量就可以二分查找快速定位
简单来说,kafka使用分区的方式实现了物理存储到逻辑分区的映射,能够轻松实现存储空间的扩展,而对用户透明;实际采用顺序存储的方式,用户只需指定索引(偏移量),就能快速查找;存储结构如下图所示
2.2 metaq
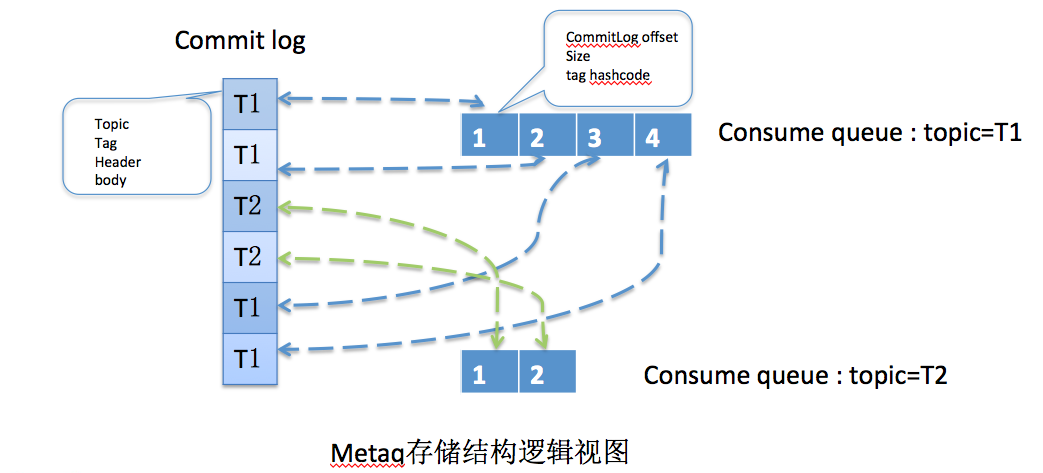
metaq借鉴了kafka的思想(致敬kafka名作变形记),即一个topic对应一个顺序存储队列sequence,但是原有的分区的数量随着topic的增大而明显增大,本来高性能的顺序写文件会变成随机写,吞吐量会有较大的下降,因此在kafka的基础上进行了改进,取消 分区物理划分主题,而采用consume queue逻辑划分的方式,参考自阿里消息中间件架构演进之路:notify和metaq
2.1.1 commit log
CommitLog属于物理队列,存储完整的消息数据,所有topic的消息都会写入到同一个CommitLog,这样就避免分区带来的影响,而划分主题的功能则交由consume queue实现
2.1.2 consume queue
metaq对客户端暴露的主要是consume queue逻辑视图,提供队列访问接口,消费者通过指定consume queue的位点来读取消息,通过提交consume queue的位点来维护消费进度
2.1.3 改进
可以看出,kafka采用的是分区+分段的方式,即物理分区,分区划分主题、逻辑扩展,分段实际存储、索引查找;而metaq采取的是commitLog+consumeQueue,逻辑分区,即commitLog按照偏移量顺序存储,consumeQueue划分主题、索引查找,同时一个 broker对应多个队列,也可以达到存储拓展的功能;metaq的存储结构如下图所示
3. 推拉模式
3.1 pull 流程
程序初始化时启动pullMessageService服务,pullRequestQueue阻塞队列存储所有的pull任务,线程不停地从队列中获取新的任务并拉取消息
PullMessageService
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
PullRequest pullRequest = this.pullRequestQueue.take();
if (pullRequest != null) {
this.pullMessage(pullRequest);
}
} catch (InterruptedException e) {
} catch (Exception e) {
log.error("Pull Message Service Run Method exception", e);
}
}
log.info(this.getServiceName() + " service end");
} netty client 收到消息后,触发 processMessageReceived 方法,最终调用 ConsumeConcurrentlyStatus status = this.messageListener.consumeMessage(msgs, content);这里的messageListener就是我们在main函数里设置的监听处理方法,同时在处理完一条消息后需要返回,只有确认正确处理才能继续传输,下面代码是处理和返回逻辑
ClientRemotingProcess
private RemotingCommand consumeMessageDirectly(ChannelHandlerContext ctx,
RemotingCommand request) throws RemotingCommandException {
final RemotingCommand response = RemotingCommand.createResponseCommand(null);
final ConsumeMessageDirectlyResultRequestHeader requestHeader =
(ConsumeMessageDirectlyResultRequestHeader) request
.decodeCommandCustomHeader(ConsumeMessageDirectlyResultRequestHeader.class);
final MessageExt msg = MessageDecoder.decode(ByteBuffer.wrap(request.getBody()));
ConsumeMessageDirectlyResult result = this.mqClientFactory.consumeMessageDirectly(msg,
requestHeader.getConsumerGroup(), requestHeader.getBrokerName());
if (null != result) {
response.setCode(ResponseCode.SUCCESS);
response.setBody(result.encode());
} else {
response.setCode(ResponseCode.SYSTEM_ERROR);
response.setRemark(String.format("The Consumer Group <%s> not exist in this
consumer", requestHeader.getConsumerGroup()));
}
return response;
}3.2 push 流程
metaq采用长轮询的方式模拟push,即在代码中将pull请求放入阻塞队列中,通过线程不停地从队列中take获取任务,达到push实时推送的功能;代码见3.1 pull 流程
4. 可靠性保证
4.1 producer可靠性保证
发送方与broker建立连接,使用netty传输消息message,同步传输确保消息能够到达服务器;源码如下,在得到response后需要调用processSendResponse方法对其进行分析,会根据response状态码更改responseCode,只有返回值的状态码正确才继续传输
private SendResult sendMessageSync(
final String addr,
final String brokerName,
final Message msg,
final long timeoutMillis,
final RemotingCommand request
) throws RemotingException, MQBrokerException, InterruptedException {
RemotingCommand response = this.remotingClient.invokeSync(addr, request, timeoutMillis);
assert response != null;
return this.processSendResponse(brokerName, msg, response);
}4.2 consumer可靠性保证
消费者顺序消费,只有在前一条消息成功后才会继续,如果持续失败(最多5次),则会将该条消息保存到本地,有后台进程继续尝试;具体消费流程见上述3.1 pull 流程
4.3 broker可靠性保证
notify服务器通过持久化保证消息的可靠性,但这样会带来io读写耗时大的问题,metaq对此进行了优化
4.3.1 master -- slaver
采用slaver的结构,一方面可以做到容灾,当master出现异常时可以自动顶替上去;另一方面,master--slaver的结构优化了读写操作,producer与master建立长连接,写操作进入master,再进行备份处理,而consumer与master和所有的slaver建立长连接,在读取时也可以对slaver的队列进行操作,优化了读取操作
4.3.2 持久化
metaq采用mmap(将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系)内存映射文件的方法,将消息持久到文件,提高了性能
4.4 总结
producer --> broker 、broker --> consumer 都依靠返回值的确认机制来保障,而broker端可靠性则依赖于本地文件持久化、容灾机制
5. 有序消息
metaq采用的是逻辑分区,即消息按序存储,但索引号是根据consumer queue决定,因此,只需保证producer单线程发送消息,且指定相同队列号即可保证消息的顺序性,源码中采用大小为1的semaphore信号量确保单线程传输
NettyRemotingAbstract
public void invokeOnewayImpl(final Channel channel, final RemotingCommand request, final long timeoutMillis)throws InterruptedException, RemotingTooMuchRequestException, RemotingTimeoutException, RemotingSendRequestException {
request.markOnewayRPC();
boolean acquired = this.semaphoreOneway.tryAcquire(timeoutMillis, TimeUnit.MILLISECONDS);
if (acquired) {
final SemaphoreReleaseOnlyOnce once = new SemaphoreReleaseOnlyOnce(this.semaphoreOneway);
try {
channel.writeAndFlush(request).addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture f) throws Exception {
once.release();
if (!f.isSuccess()) {
log.warn("send a request command to channel <" + channel.remoteAddress() + "> failed.");
}
}
});
} catch (Exception e) {
once.release();
log.warn("write send a request command to channel <" + channel.remoteAddress() + "> failed.");
throw new RemotingSendRequestException(RemotingHelper.parseChannelRemoteAddr(channel), e);
}
} else {
if (timeoutMillis <= 0) {
throw new RemotingTooMuchRequestException("invokeOnewayImpl invoke too fast");
} else {
String info = String.format("invokeOnewayImpl tryAcquire semaphore timeout, %dms, waiting thread nums: %d semaphoreAsyncValue: %d", timeoutMillis, this.semaphoreOneway.getQueueLength(), this.semaphoreOneway.availablePermits()
);
log.warn(info);
throw new RemotingTimeoutException(info);
}
}
}
6. 负载均衡
由于消费者只需根据topic从broker拉取消息即可,这里只讨论消生产者的负载均衡,broker端采用逻辑分区,在生产者看来所有的分区组成了分区列表依次使用,本质就是发送消息时合理选择分区的问题,metaq在初始化时从配置中心获取publish的topic对应的broker和分区列表,生产者在发送消息的时候必须选择一台broker上的一个分区来发送消息,默认的策略是一个轮询的路由规则,以此达到负载均衡的效果
代码演示
1. 发布topic
这里是将topic发布到name server上,便于构建TopicRouteData,为主题分配broker
2. 添加maven依赖
<dependency>
<groupId>com.taobao.metaq.final</groupId>
<artifactId>metaq-client</artifactId>
<version>4.2.0.Final</version>
</dependency>3. Producer
public class Producer {
public static void main(String[] args) throws MQClientException, InterruptedException {
MetaProducer producer = new MetaProducer("intern-metaq-demo-normal-consumer");
producer.start();
for (int i = 0; i < 1000; i++) {
try {
Message msg = new Message("intern-demo-sc",// topic
"TagA",// tag
("sc " + i).getBytes()// body
);
SendResult sendResult = producer.send(msg);
System.out.println(sendResult.getSendStatus());
//Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
Thread.sleep(1000);
}
}
producer.shutdown();
}
}4. Consumer
public class Consumer {
public static void main(String[] args) throws InterruptedException, MQClientException, MQClientException {
MetaPushConsumer consumer = new MetaPushConsumer("CID-sc");
consumer.subscribe("intern-demo-sc", "*");
consumer.registerMessageListener(new MessageListenerConcurrently() {
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, //监听消息
ConsumeConcurrentlyContext context) {
for (MessageExt msg : msgs) { //处理消息
System.out.println("ReceivedMsgId: " + new String(msg.getMsgId()) + " ReceivedMsgBody: " + new String(msg.getBody()));
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
System.out.println("Consumer Started.");
}
}总结
1. 中间件与 rpc区别
1.1 业务逻辑层面
rpc:远程过程调用,强调的是解耦,将不同的功能模块拆分,但程序运行上还是作为一个整体,各个模块内部由不同平台根据具体业务场景开发,彼此之间通过rpc远程调用
中间件:解耦+异步,达到了1+1 > 2 的效果,遵循的主旨是最终一致性原则
参考自Notify和Metaq ——学习总结,以用户注册为例,需要的流程如下

在早期的业务处理流程中,会采用串行的执行方式,这样程序运行逻辑和业务处理流程相一致,但带来的问题很多,一方面程序总体耗时是单纯的线性叠加,另一方面,若果业务流程中某一环节出错,就不得不全部rollback,这样的代价太大;而中间件的着 眼点在于业务层面的解耦,仔细分析,我们可以发现该业务的主要逻辑是用户注册,而后续的准备支付宝,通知sns等操作虽然必须要完成,但却是不需要让用户等待的,经过分拆的流程如下
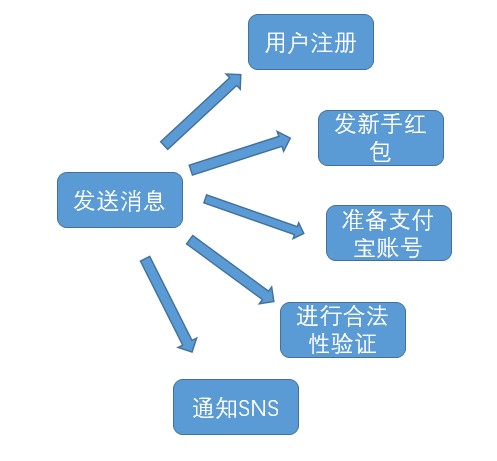
这样采取异步并行的方式来完成业务,极大的减少延迟,但带来的问题就是如果某一环节出错,整体流程不会因此rollback,比如用户注册成功但是却没有通过合法性验证,这样带来的就是数据上的危害,因此需要确保拆分模块运行的可靠性,经过中间件分 拆的最终模块如下
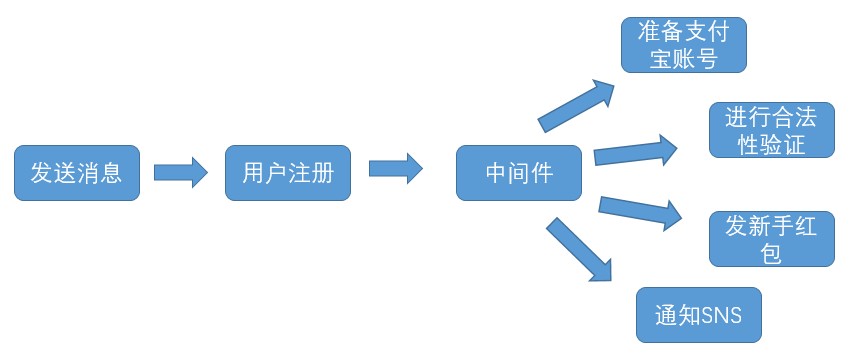
可以看出,中间件在业务逻辑优化的过程中起到了:1. 异步:解耦功能模块,并行执行缩短耗时;2. 可靠性保证:通过内部机制确保并行模块运行的可靠性
1.2 使用方式
在代码使用方面,hsf采用的是本地代理,最终通过invoke反射调用方法并返回结果;metaq则是producer -- broker、broker -- consumer 直接传输消息
2. metaq 与 notify 区别
最本质的区别就是notify采用push方式,broker不停地向consumer推送消息,这样确保了消息的可达性但却牺牲了服务器的性能,而metaq采用pull方式(pull模拟push),服务端只保存一定时间内的消息,提升了broker的性能,各方面对比见下表,可见在绝大 多数领域metaq性能更加优秀,因此notify正逐渐合并到metaq项目中
| 性能 | metaq | notify |
| 消息推送方式 | pull | push |
| 顺序性 | 局部有序 | 不提供 |
| 消息重复 | 部分避免 | 不提供 |
| 实时性 | 较高 | 高 |
| 消息堆积能力 | 强 | 较强 |
| 分布式 | 不支持 | 支持 |
| 过滤机制 | 单一 | 多种过滤机制 |
| 广播 | 支持 | 不支持 |
3. 削峰填谷
在metaq的介绍中,开始看到这个名词时感觉很高深,但随着深入学习,metaq的功能逐渐清晰起来。简单来说,削峰填谷是概括了中间件的功能,即异步并发,阻挡前端的数据洪峰,舒缓下游机器压力。试想这样的情景,在双11等业务场景下,用户瞬间的请 求量是爆炸式的,如果采用传统的同步顺序执行逻辑,所有的请求在没有完成前都需要挂载在服务端,服务器的压力可想而知,但采用中间件解耦业务逻辑,则用户请求在完成主体需求后可以直接退出,由中间件堆积消息并确保剩余业务的完成,这就可以容纳更多 的用户请求,因此,一个设计规范,运行良好的中间件系统对于公司业务的拓展骑着极为重要的作用
参考文章
http://www.jasongj.com/2015/03/10/KafkaColumn1/
https://www.atatech.org/articles/95456
https://www.atatech.org/articles/36160#5
https://www.atatech.org/articles/102577
https://www.atatech.org/articles/108048
https://www.atatech.org/articles/110786
https://www.cnblogs.com/huxiao-tee/p/4660352.html
智能推荐
在windows系统调试ydlidar详细记录(物联网机器人方向)_物联网windows系统调试-程序员宅基地
文章浏览阅读2.3k次,点赞2次,收藏8次。这篇博文详细记录在windows系统调试ydlidar的全过程ydlidar采用全无线连接方式,测距雷达放在迷你机器人(型号tianbotmini,中文名天宝迷你)上如下图所示,需要usb无线设备接受雷达信息:装配雷达的机器人和接收器由于使用机器人操作系统(ROS1和ROS2),需要安装机器人操作系统的请参考如下: 在Windows系统安装ROS机器人操作系统(更新日期2020年10月,附官网链接) 下面开始操作,使用SDK版本为1.4.7,发布日期为2020年3月31日。Linux_物联网windows系统调试
iOS内购-防越狱破解刷单_software-version-external-identifier-程序员宅基地
文章浏览阅读3.8k次。---------------------------2018.10.16更新---------------------------最近我们公司丢单率上涨,尤其是10月份比9月份来说丢单率翻了3倍,和一些同行交流了一下,发现他们也是丢单量增加,初步推断可能是苹果iOS12的原因,某些情况下会有用户内购成功后,却返回的是订单失败,错误类型为SKErrorUnknown。目前客户端好像没办法去解决。如果有小伙伴和我一样也遇到过相同的问题话,请私信我下,我们都多互相交流一下。--------------._software-version-external-identifier
Multi-Scale Guided Concurrent Reflection Removal Network_reflection network-程序员宅基地
文章浏览阅读364次。gradient inference network(GiN):输入是4通道张量,它是输入混合图像及其对应梯度的组合.The image inference network (IiN):以混合图像为输入,提取描述全局结构和高层语义信息的背景特征表示来估计B和R。GIN网络用的是一个镜像框架结构,即首尾结构对称(分别对应编码和解码结构)。编码结构由五个卷积层构成,先一个步长1..._reflection network
select2 下拉选择后首次未触发change事件_select2 change-程序员宅基地
文章浏览阅读7.5k次。问题现象: select2 下拉选择框,首次切换到“全部”选项不会触发change事件。问题背景: select2 下拉选择框,有设置默认值(非全部),在加载数据时,改动后端返回数据,加了一条“全部”的下拉选择内容:list.unshift({'id':'','text':'全部'}); 问题分析: 首次切换到“全部”选项后,并未触发change事件; 而首次切换到其他..._select2 change
python升序降序_python 根据两个字段排序, 一个升序, 一个降序-程序员宅基地
文章浏览阅读867次。给定一个字符串, 输出出现次数最多的前三个字符, 若两字符出现次数相同, 则按字典顺序排列.# 样例输入aabbbccde# 样例输出b 3a 2c 2就是先将第二字段降序排序, 再将第一字段升序排序, 关键就是sorted函数key的指定, 可以用 lambda 或operator.itemgetter开始我是这样做的:from collections import Counterc = Cou..._py 多字段排序先升序再降序
红帽 RHEL power8 rhel-server-7.2-ppc64le-dvd.iso-程序员宅基地
文章浏览阅读3.1k次。红帽 RHEL power8 服务器小端版本,找了很久才找到,官方不提供下载了,放这里给大家对于没有HMC,没有显卡的小机运维,不想搭一堆环境的人来说是福音,SUSE11没有小端版本,12用的引导界面在SMS下全是乱码,只能用吐血两字来形容,centos 7 装上会出现IOA口驱动失败的情况,目前找不到原因,这个是官方支持带驱动的,rhel-server-7.2-ppc64le-dvd.i_rhel-server-7.2-ppc64le-dvd.iso
随便推点
树遍历(BFS+DFS(递归+非递归))-python代码整理_bfs算法递归遍历树 python-程序员宅基地
文章浏览阅读1.1k次,点赞5次,收藏13次。数据结构算法-树最近再刷leetcode的树,整理了常用遍历代码包含树的层次遍历(广度优先遍历)与前中后序遍历(深度优先遍历):#########################################层次遍历(广度优先遍历)★★★★★#BFS通用模板,层次遍历通用:#使用队列实现def levelOrder(root): if not root: return [] queue=[root] ans=[] while queue: a=[] #方便保存每一层的_bfs算法递归遍历树 python
有关java.sql.SQLException: Io 异常: Connection refused(DESCRIPTION=(TMP=)(VSNNUM=186646784)的解决方法-程序员宅基地
文章浏览阅读1.6k次。问题描述:在用Java访问数据库时,出现以下提示:java.sql.SQLException: Io 异常: Connection refused(DESCRIPTION=(TMP=)(VSNNUM=186646784)(ERR=12505)(ERROR_STACK=(ERROR=(CODE=12505)(EMFI=4))))原因:在连接数据库时,所连接的url的地址格式输入有误解决方法..._connection refused(description=(tmp=)(vsnnum=186646784)(err=12505)(error_sta
Servlet--Request生命周期_tomcat中request的生命周期-程序员宅基地
文章浏览阅读5k次,点赞4次,收藏13次。Servlet--Request生命周期一、Request、Response对象的生命周期1、浏览器像servlet发送请求2、tomcat收到请求后,创建Request和Response两个对象的生命周期,并且将浏览器请求的参数传递给Servlet3、Servlet接收到请求后,调用doget或者dopost方法。处理浏览器的请求信息,然后通过Response返回_tomcat中request的生命周期
解决GitHub不能访问的几个办法_github打不开-程序员宅基地
文章浏览阅读7.9w次,点赞16次,收藏80次。GitHub页面时而能访问,时而不能。不是慢,而是不能访问。当然,下载它的比如仓库Release下的压缩包比较慢则是另一回事。蛋疼的影响不限于打不开页面,更多的在于不能git pull和git push等操作。范围方面,凡国内不管是家宽、移动网络还是云上的,都受到一致的影响。_github打不开
经纬恒润测试开发面经_经纬恒润 面试-程序员宅基地
文章浏览阅读4.5k次,点赞3次,收藏21次。9.24 15:00 电话一面 35min面试官是一个声音巨好听的小哥哥......,迷恋ing,而且也超级温柔,嘻嘻嘻嘻嘻嘻1.自我介绍2.讲项目是不是自己做的 怎么做的 项目分工 担任角色 项目测试(全程死抠测试,单元测试死抠.....) 为什么做这个项目3.对软件测试的理解4.针对我的专业有疑问,主修课程有哪些,5.为什么做测试6.你觉得互..._经纬恒润 面试
19款最好用的免费数据挖掘工具大汇总(干货)_)好用(19)-程序员宅基地
文章浏览阅读6.7k次,点赞2次,收藏14次。数据在当今世界意味着金钱。随着向基于app的世界的过渡,数据呈指数增长。然而,大多数数据是非结构化的,因此需要一个过程和方法从数据中提取有用的信息,并将其转换为可理解的和可用的形式。数据挖掘或“数据库中的知识发现”是通过人工智能、机器学习、统计和数据库系统发现大数据集中的模式的过程。免费的数据挖掘工具包括从完整的模型开发环境如Knime和Orange,到各种用Java、c++编写的库,最常..._)好用(19)