NLP学习记录(六)最大熵模型MaxEnt_顺序潜在最大熵强化学习(maxent rl)-程序员宅基地
技术标签: NLP自然语言处理理论篇 NLP
原理
在叧掌握关于未知分布的部分信息的情况下,符合已知知识的概率分布可能有夗个,但使熵值最大的概率分布最真实地反映了事件的的分布情况,因为熵定义了随机变量的不确定性,弼熵值最大时,随机变量最不确定,最难预测其行为。
最大熵模型介绍
我们通过一个简单的例子来介绍最大熵概念。假设我们模拟一个翻译专家的决策过程,关于英文单词in到法语单词的翻译。我们的翻译决策模型p给每一个单词或短语分配一个估计值p(f),即专家选择f作为翻译的概率。为了帮助我们开发模型p,我们收集大量的专家翻译的样本。我们的目标有两个,一是从样本中抽取一组决策过程的事实(规则),二是基于这些事实构建这一翻译过程的模型。
我们能从样本中得到的一个明显的线索是允许的翻译候选列表。例如,我们可能发现翻译专家总是选择下面这5个法语词汇:{dans, en, à, au cours de, pendant}。一旦有了这些信息,我们可以给模型p施加第一个约束条件:
p(dans)+p(en)+ p(à)+p(au cours de)+p(pendant) = 1
这个等式代表了这一翻译过程的第一个统计信息,我们现在可以进行寻找满足这一条件的模型了。显然,有无数满足这个条件的模型可供选择。其中一个模型是p(dans)=1,换句话说这个模型总是预测dans。另外一个满足这一约束的模型是p(pendant)=1/2 and p(à)=1/2。 这两个模型都有违常理:只知道翻译专家总是选择这5个法语词汇,我们哪知道哪个概率分布是对的。两个模型每个都在没有经验支持的情况下,做了大胆的假设。最符合直觉的模型是:
p(dans) = 1/5
p(en) = 1/5
p(à) = 1/5
p(au cours de) = 1/5
p(pendant) = 1/5
这个模型将概率均匀分配给5个可能的词汇,是与我们已有知识最一致的模型。我们可能希望从样本中收集更多的关于翻译决策的线索。假设我们发现到有30%时间in被翻译成dans 或者en. 我们可以运用这些知识更新我们的模型,让其满足两个约束条件:
p(dans) + p(en) = 3/10
p(dans)+p(en)+ p(à)+p(au cours de)+p(pendant) = 1
同样,还是有很多概率分布满足这两个约束。在没有其他知识的情况下,最合理的模型p是最均匀的模型,也就是在满足约束的条件下,将概率尽可能均匀的分配。
p(dans) = 3/20
p(en) = 3/20
p(à) = 7/30
p(au cours de) = 7/30
p(pendant) = 7/30
假设我们又一次检查数据,这次发现了另外一个有趣的事实:有一般的情况,专家会选择翻译成dans 或 à.我们可以将这一信息列为第三个约束:
p(dans) + p(en) = 3/10
p(dans)+p(en)+ p(à)+p(au cours de)+p(pendant) = 1
p(dans)+ p(à)=1/2
我们可以再一次寻找满足这些约束的最均匀分配的模型p,但这一次的结果没有那么明显。由于我们增加了问题的复杂度,我们碰到了两个问题:首先,”uniform(均匀)”究竟是什么意思?我们如何度量一个模型的均匀度(uniformity)?第二,有了这些问题答案之后,我们如何找到满足一组约束且最均匀的模型?就像前面我们看到的模型。
最大熵的方法回答了这两个问题。直观上讲,很简单,即:对已知的知识建模,对未知的不过任何假设(model all that is known and assume nothing about that which is unknown)。换句话说,在给定一组事实(features+output)的条件下,选择符合所有事实,且在其他方面近可能均匀的模型,这恰恰是我们在上面例子每一步选择模型p所采取的方法。
- Maxent Modeling
我们考虑一个随机过程,它产生一个输出y,y属于一个有穷集合。对于刚才讨论的翻译的例子,该过程输出单词in的翻译,输出值y可以是集合{dans, en, à, au cours de, pendant}中任何一个单词。在输出y时,该过程可能会被上下文信息x影响,x属于有穷的集合X。在目前的例子中,这信息可能包括英文句子中in周围的单词。
我们的任务是构造一个统计模型,该模型能够准确表示随机过程的行为。该模型任务是预测在给定上下文x的情况下,输出y的概率:p(y|x).
Training Data
为了研究这一过程,我们观察一段时间随机过程的行为,收集大量的样本: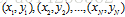
我们可以通过它的经验分布来总结训练样本的特性:
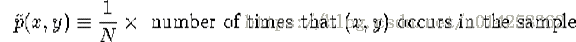
通常,对于一个特定的pair (x, y),它要么不出现在样本中,要么最多出现几次。
- Features and constraints
我们的目标是构造一个产生训练样本这一随机过程的统计模型。组成这个模型的模块将是一组训练样本的统计值。在目前的例子中,我们已经采用了几个统计数据:(1)in被翻译成dans 或者en的频率是3/10;(2) in被翻译成dans 或 à的概率是1/2 ;…等。这些统计数据是上下文独立的,但我们也可以考虑依赖上下文信息x的统计数据。例如,我们可能注意到,在训练样本中,如果 April 是一个出现在in之后,那么in翻译成en的频率有9/10.
为了表示这个事件(event),即当Aprial出现在in之后,in被翻译成en,我们引入了指示函数:
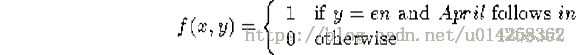
特征f 关于经验分布的期望值,正是我们感兴趣的统计数据。我们将这个期望值表示为:
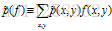 (1)
(1)
我们可以将任何样本的统计表示成一个适当的二值指示函数的期望值,我们把这个函数叫做特征函数(feature function)或简称特征(feature)。
当我们发现一个统计量,我们觉得有用时,我们让模型去符合它(拟合),来利用这一重要性。拟合过程通过约束模型p分配给相应特征函数的期望值来实现。特征f关于模型p(y|x)的期望值是:
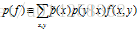
这里,是x在训练样本中的经验分布。我们约束这一期望值和训练样本中f的期望值相同。那就要求:
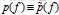
组合(1),(2) 和(3),我们得到等式:
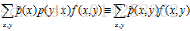
我们称(3)为约束等式(constraint equation)或者简称约束(constraint)。我们只关注那么满足(3)的模型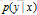
目前总结来看,我们现在有办法表示样本数据中内在的统计现象(叫做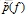
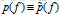
最后,仍我关于特征和约束再罗嗦两句:单词 feature'' andconstraint”在讨论最大熵时经常被混用,我们希望读者注意区分这两者的概念:特征(feature)是(x,y)的二值函数;约束是一个等式:即模型的特征函数期望值等于训练样本中特征函数的期望值。
- The maxent prinple
假设给我们n个特征函数fi,它们的期望值决定了在建模过程中重要的统计数据。我们想要我们的模型符合这些统计,就是说,我们想要模型p属于的子集C。
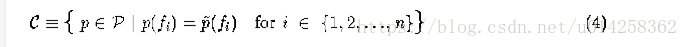
图1是这一限制的几何解释。这里,P是三点上所有可能的概率分布空间。如果我们不施加任何约束(图a),所有概率模型都是允许的。施加一个线性约束C1后,模型被限制在C1定义的区域,如图b示。如果两个约束是可满足的, 施加第二个线性约束后可以准确确定p,如图c所示。另一种情形是,第二个线性约束与第一个不一致,例如,第一个约束可能需要第一个点的概率是1/3,第二个约束需要第三个点的概率是3/4,图d所示。在目前的设置中,线性约束是从训练数据集中抽取的,不可能手工构造,因此不可能不一致。进一步来说,在我们应用中的线性约束甚至不会接近唯一确定的p,就象图c那样。相反,集合C=C1∩C2∩C3∩…∩Cn中的模型是无穷的。
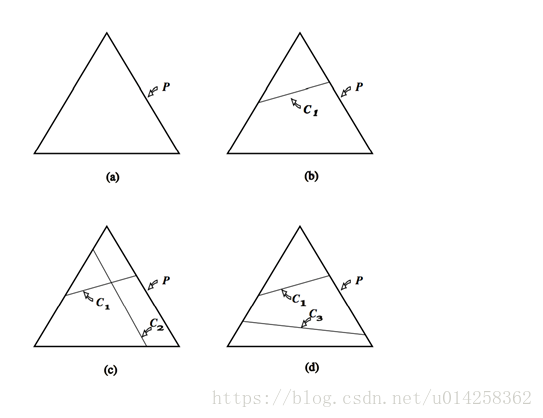
属于集合C的所有模型p中,最大熵的理念决定我们选择最均匀的分布。但现在,我们面临一个前面遗留的问题:什么是”uniform(均匀)”?
数学上,条件分布p(y|x)的均匀度就是条件熵定义:
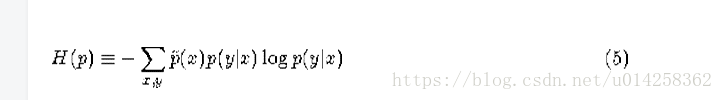
熵的下界是0, 这时模型没有任何不确定性;熵的上界是log|Y|,即在所有可能(|Y|个)的y上均匀分布。有了这个定义,我们准备提出最大熵原则。
当从允许的概率分布集合C中选择一个模型时,选择模型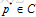

可以证明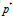
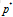
- Exponential form
最大熵原理呈现给我们的是一个约束优化问题:find the 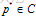
为了解决这个问题,我们采用约束优化理论中Lagrange multipliers的方法。这里仅概述相关步骤,请参考进一步阅读以更深入了解约束优化理论如何应用到最大熵模型中的。
我们的约束优化问题是:
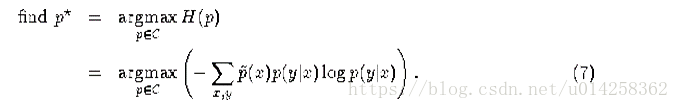
我们将这个称为原始问题(primal)。简单的讲,我们目标是在满足以下约束的情况下,最大化H(p)。

为了解决这个优化问题,引入Lagrangian 乘子。
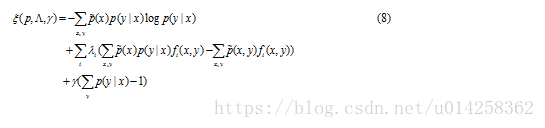
实值参数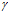
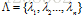
下面的策略可以求出p的最优解(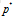
首先,将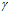
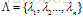
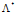
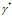
按照这一方式,我们保证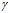
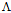
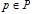
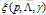
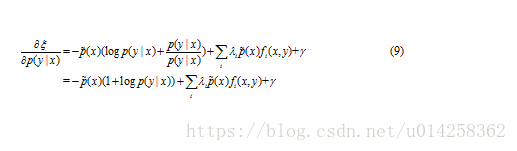
令该式等于0, 求解 p(y|x):
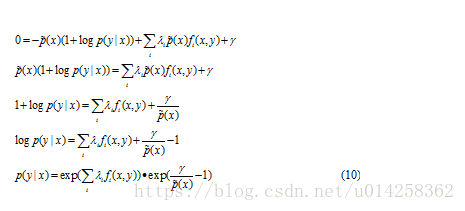
可以看出公式(10)的第二个因子对应第二个约束:
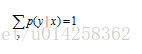
将上式带入公式(10)得到:
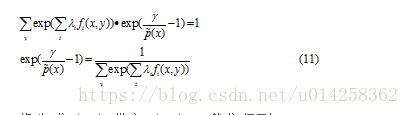
将公式(11)带入(10),我们得到:
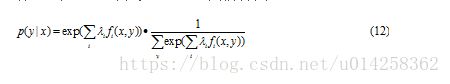
因此,

Z(x)是正则化因子。
现在我们要求解最优值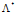
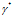
为此,我们介绍新的符号,定义对偶函数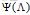
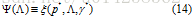
对偶优化问题是:
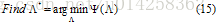
因为p*和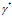
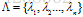
参数值等于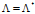
满足约束C最大熵模型具有(13)参数化形式,最优参数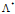
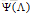
补充说明:
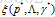
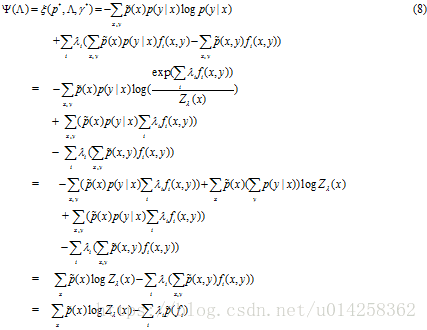
- Maximum likelihood
最大似然率:找出与样本的分布最接近的概率分布模型。
比如:10次抛硬币的结果是:
画画字画画画字字画画
假设p是每次抛硬币结果为”画”的概率。
得到这样试验结果的概率是:
P = pp(1-p)ppp(1-p)(1-p)pp=p7(1-p)3
最大化似然率的方法就是:
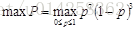
最优解是:p=0.7
似然率的一般定义为:
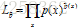
p(x)是模型估计的概率分布,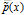
在我们的问题里,要估计的是p(y|x),最大似然率为:

因此,有:
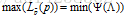
这里的p具有公式(13)的形式,我们的结果进一步可以表述为:
最大熵模型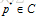
- Computing the Parameters
要算λ,解析解肯定是行不通的。对于最大熵模型对应的最优化问题,GIS,lbfgs,sgd等等最优化算法都能解。相比之下,GIS大概是最好实现的。这里只介绍GIS算法。
具体步骤如下:
(1)set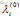
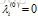
(2) 重复直到收敛:
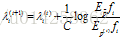
这里,(t)是迭代下标,常数C定义为:
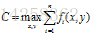
实际上,GIS算法用第N次迭代的模型来估算每个特征在训练数据中的分布。如果超过了实际的,就把相应参数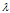
- 最大熵实现
下面是GIS训练算法的python实现,代码不到100行。
from collections import defaultdict
import math
class MaxEnt(object):
def __init__(self):
self.feats = defaultdict(int)
self.trainset = []
self.labels = set()
def load_data(self,file):
for line in open(file):
fields = line.strip().split()
# at least two columns
if len(fields) < 2: continue
# the first column is label
label = fields[0]
self.labels.add(label)
for f in set(fields[1:]):
# (label,f) tuple is feature
self.feats[(label,f)] += 1
self.trainset.append(fields)
def _initparams(self):
self.size = len(self.trainset)
# M param for GIS training algorithm
self.M = max([len(record)-1 for record in self.trainset])
self.ep_ = [0.0]*len(self.feats)
for i,f in enumerate(self.feats):
# calculate feature expectation on empirical distribution
self.ep_[i] = float(self.feats[f])/float(self.size)
# each feature function correspond to id
self.feats[f] = i
# init weight for each feature
self.w = [0.0]*len(self.feats)
self.lastw = self.w
def probwgt(self,features,label):
wgt = 0.0
for f in features:
if (label,f) in self.feats:
wgt += self.w[self.feats[(label,f)]]
return math.exp(wgt)
"""
calculate feature expectation on model distribution
"""
def Ep(self):
ep = [0.0]*len(self.feats)
for record in self.trainset:
features = record[1:]
# calculate p(y|x)
prob = self.calprob(features)
for f in features:
for w,l in prob:
# only focus on features from training data.
if (l,f) in self.feats:
# get feature id
idx = self.feats[(l,f)]
# sum(1/N * f(y,x)*p(y|x)), p(x) = 1/N
ep[idx] += w * (1.0/self.size)
return ep
def _convergence(self,lastw,w):
for w1,w2 in zip(lastw,w):
if abs(w1-w2) >= 0.01:
return False
return True
def train(self, max_iter =1000):
self._initparams()
for i in range(max_iter):
print 'iter %d ...'%(i+1)
# calculate feature expectation on model distribution
self.ep = self.Ep()
self.lastw = self.w[:]
for i,win enumerate(self.w):
delta = 1.0/self.M * math.log(self.ep_[i]/self.ep[i])
# update w
self.w[i] += delta
print self.w
# test if the algorithm is convergence
if self._convergence(self.lastw,self.w):
break
def calprob(self,features):
wgts = [(self.probwgt(features, l),l) for l in self.labels]
Z = sum([ w for w,l in wgts])
prob = [ (w/Z,l) for w,l in wgts]
return prob
def predict(self,input):
features = input.strip().split()
prob = self.calprob(features)
prob.sort(reverse=True)
return prob 智能推荐
【玩转华为云】手把手教你利用ModelArts实现垃圾自动分类_华为云人工智能 垃圾分类-程序员宅基地
文章浏览阅读1.4k次。本篇推文共计2000个字,阅读时间约3分钟。华为云—华为公司倾力打造的云战略品牌,2011年成立,致力于为全球客户提供领先的公有云服务,包含弹性云服务器、云数据库、云安全等云计算服务,软件开发服务,面向企业的大数据和人工智能服务,以及场景化的解决方案。华为云用在线的方式将华为30多年在ICT基础设施领域的技术积累和产品解决方案开放给客户,致力于提供稳定可靠、安全可信、可持续创新的云服务,做智能世界的“黑土地”,推进实现“用得起、用得好、用得放心”的普惠AI。华为云作为底座,为华为全栈全场景A.._华为云人工智能 垃圾分类
Python 开发桌面应用居然如此简单_python制作桌面端-程序员宅基地
文章浏览阅读6.4k次,点赞4次,收藏86次。我们都知道 Python 可以用来开发桌面应用,一旦功能开发完成,最后打包的可执行文件体积大,并且使用 Python 开发桌面应用周期相对较长假如想快速开发一款 PC 端的桌面应用,推荐使用 Aardio + Python 搭配的方式进行开发1. Aardio介绍Aardio 是一款专注于 Windows 桌面端的软件开发,适用于快速开发一些自用的 PC端桌面工具,并且它支持与Python、JS、Golang 等主流语言进行混合编程它是一款免费的开发工具,简单易学,支持多线程,具有轻巧..._python制作桌面端
IDEA中Spring配置错误:class path resource [.xml] cannot be opened because it does not exist_class path resource [feign/requestinterceptor.clas-程序员宅基地
文章浏览阅读10w+次,点赞71次,收藏72次。如果在运行 Spring 项目时出现了类似于:class path resource [applicationContext.xml] cannot be opened because it does not exist这样的异常 意思就是没有找到你的 .xml 配置文件原因我可以肯定你一定用的是 ApplicationContext ctx = new ClassPathXmlApplicati_class path resource [feign/requestinterceptor.class] cannot be opened becaus
Activiti工作流引擎-程序员宅基地
文章浏览阅读1w次,点赞8次,收藏50次。Activiti是一个工作流引擎, activiti可以将业务系统中复杂的业务流程抽取出来,使用专门的建模语言BPMN2.0进行定义,业务流程按照预先定义的流程进行执行,实现了系统的流程由activiti进行管理,减少业务系统由于流程变更进行系统升级改造的工作量,从而提高系统的健壮性,同时也减少了系统开发维护成本。........._activiti工作流引擎
【BZOJ】【3053】The Closest M Points-程序员宅基地
文章浏览阅读76次。KD-Tree 题目大意:K维空间内,与给定点欧几里得距离最近的 m 个点。 KD树啊……还能怎样啊……然而扩展到k维其实并没多么复杂?除了我已经脑补不出建树过程……不过代码好像变化不大>_> 然而我WA了。。。为什么呢。。。我也不知道…… 一开始我的Push_up是这么写的:inline void Push_up(int o){ rep(..._euclidean distance between w and the closest point to w in s v
testng生成报告ReportNG美化测试报告-程序员宅基地
文章浏览阅读184次。testng生成报告ReportNG美化测试报告testng生成报告ReportNG美化测试报告ReportNG 是一个配合TestNG运行case后自动帮你在test-output文件内生成一个相对较为美观的测试报告!ReportNG 里面Log 是不支持中文的,我改过ReportNG.jar源码,具体方法看最下面,也可以找我直接要jar!话不多说直接上环境准备:1,你需要这些架包 ..._testng reportng美化报告
随便推点
C++实现线性表的顺序存储结构_c++使用顺序存储表示方法创建线性表-程序员宅基地
文章浏览阅读2.5k次,点赞6次,收藏48次。C++线性表的顺序存储结构 线性表是最基本、最简单、也是最常用的一种数据结构。线性表(linear list)是数据结构的一种,一个线性表是n个具有相同特性的数据元素的有限序列。线性表的特点除第一个元素外,其他每一个元素有且仅有一个直接前驱。除最后一个元素外,其他每一个元素有且仅有一个直接后继。直接前驱和直接后继描..._c++使用顺序存储表示方法创建线性表
重装protobuf报错undefined symbol: _ZNK6google8protobuf7Message11GetTypeNameB5cxx11Ev-程序员宅基地
文章浏览阅读1.4w次,点赞2次,收藏7次。服务器将protobuf版本从2.6.1降级到2.5.0后,重新装回2.6.1,出现报错:protoc: symbol lookup error: /usr/lib/x86_64-linux-gnu/libprotoc.so.9: undefined symbol: _ZNK6google8protobuf7Message11GetTypeNameB5cxx11Ev搜索网上解决办法,发现并...__znk6google8protobuf7message11gettypenameb5cxx11ev
【校招VIP】java语言考点之synchronized和volatile-程序员宅基地
文章浏览阅读356次。synchronized和volatile两个关键字也是校招常考点之一。volatile可以禁止进行指令重排。synchronized可作用于一段代码或方法,既可以保证可见性,又能够保证原子性。_synchronized和volatile
互联网平台经济模式逐渐形成,许多新的创新型企业涌现出来,将会影响到社会的治理结构以及公共政策走向-程序员宅基地
文章浏览阅读461次。作者:禅与计算机程序设计艺术 1.简介在新冠病毒疫情期间,由于经济全面恢复、国内外大量人员返乡、工作日程调整等因素的影响,使得整个社会成为新冠病毒大流行的重灾区。为了减轻生产企业和消费者的不满情绪,提高社会福利水平,防止再次发生类似事件,各地都制定了诸多限制、规范、政策等方面的法律法规,但这些法律法规
ethereum/EIPs-161 State trie clearing-程序员宅基地
文章浏览阅读152次。EIP 161: State trie clearing- makes it possible to remove a large number of empty accounts that were put in the state at very low cost as a result of earlier DoS attacks. With this EIP, 'empty' accou..._eip161
2003与2007导出_导出2003-程序员宅基地
文章浏览阅读120次。using System;using System.Data;using System.Configuration;using System.Collections;using System.Data.OleDb;using System.IO;using System.Web;using System.Web.Security;using System.Web.U..._导出2003