Gandiva, using LLVM and Arrow to JIT and evaluate Pandas expressions-程序员宅基地
技术标签: 大数据
从11年前开始,我就一直是LLVM的忠实拥护者,那时我开始使用LLVM处理JIT数据结构(例如AVL),然后使用JIT限制的AST树和TensorFlow图中的JIT本机代码。从那时起,LLVM演变为最重要的编译器框架生态系统之一,如今已被许多重要的开源项目使用。
我最近意识到的一个很酷的项目是Gandiva。Gandiva由Dremio开发,然后捐赠给Apache Arrow(为此向Dremio团队表示敬意)。Gandiva的主要思想是提供一个编译器来生成LLVM IR,该LLVM IR可以在批处理的Apache Arrow上运行。Gandiva用C ++编写,并具有许多不同的功能,这些功能被实现以构建可使用LLVM进行JIT处理的表达式树。此设计的一个不错的功能是,它可以使用LLVM自动优化复杂的表达式,在对Arrow批处理进行操作时添加本机目标平台矢量化(例如AVX)并执行本机代码以计算表达式。
下图概述了Gandiva:

Gandiva工作原理概述。图片来自:https://www.dremio.com/announcing-gandiva-initiative-for-apache-arrow
在本文中,我将构建一个非常简单的表达式解析器,它支持一组有限的操作,这些操作将用于过滤Pandas DataFrame。
用Gandiva构建简单表达
在本节中,我将展示如何使用Gandiva中的树构建器手动创建一个简单的表达式。
使用Gandiva Python绑定到JIT和表达式
在为表达式构建解析器和表达式构建器之前,让我们使用Gandiva手动构建一个简单的表达式。首先,我们将创建一个简单的Pandas DataFrame,其数字范围为0.0到9.0:
import pandas as pd
import pyarrow as pa
import pyarrow.gandiva as gandiva
# Create a simple Pandas DataFrame
df = pd.DataFrame({"x": [1.0 * i for i in range(10)]})
table = pa.Table.from_pandas(df)
schema = pa.Schema.from_pandas(df)
我们将DataFrame转换为Arrow Table,重要的是要注意,在这种情况下,这是一个零复制操作,Arrow并不是从Pandas复制数据并复制DataFrame。稍后,我们schema从包含列类型和其他元数据的表中获得。
之后,我们要使用Gandiva构建以下表达式来过滤数据:
(x > 2.0) and (x < 6.0)
该表达式将使用Gandiva的节点构建:
builder = gandiva.TreeExprBuilder()
# Reference the column "x"
node_x = builder.make_field(table.schema.field("x"))
# Make two literals: 2.0 and 6.0
two = builder.make_literal(2.0, pa.float64())
six = builder.make_literal(6.0, pa.float64())
# Create a function for "x > 2.0"
gt_five_node = builder.make_function("greater_than",
[node_x, two],
pa.bool_())
# Create a function for "x < 6.0"
lt_ten_node = builder.make_function("less_than",
[node_x, six],
pa.bool_())
# Create an "and" node, for "(x > 2.0) and (x < 6.0)"
and_node = builder.make_and([gt_five_node, lt_ten_node])
# Make the expression a condition and create a filter
condition = builder.make_condition(and_node)
filter_ = gandiva.make_filter(table.schema, condition)
现在,该代码看起来有些复杂,但很容易理解。基本上,我们正在创建一棵树的节点,该节点将代表我们之前显示的表达式。这是其外观的图形表示:
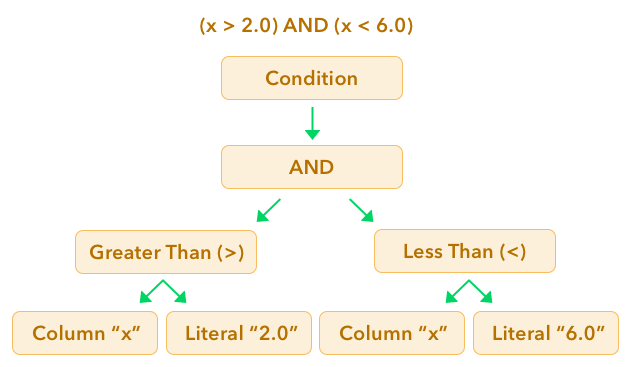
检查生成的LLVM IR
不幸的是,还没有找到一种方法来转储使用Arrow的Python绑定生成的LLVM IR,但是,我们只能使用C ++ API来构建同一棵树,然后查看生成的LLVM IR:
auto field_x = field("x", float32());
auto schema = arrow::schema({field_x});
auto node_x = TreeExprBuilder::MakeField(field_x);
auto two = TreeExprBuilder::MakeLiteral((float_t)2.0);
auto six = TreeExprBuilder::MakeLiteral((float_t)6.0);
auto gt_five_node = TreeExprBuilder::MakeFunction("greater_than",
{node_x, two}, arrow::boolean());
auto lt_ten_node = TreeExprBuilder::MakeFunction("less_than",
{node_x, six}, arrow::boolean());
auto and_node = TreeExprBuilder::MakeAnd({gt_five_node, lt_ten_node});
auto condition = TreeExprBuilder::MakeCondition(and_node);
std::shared_ptr<Filter> filter;
auto status = Filter::Make(schema, condition, TestConfiguration(), &filter);
上面的代码与Python代码相同,但使用的是C ++ Gandiva API。现在,我们用C ++构建了树,我们可以获取LLVM模块并为其转储IR代码。生成的IR充满了样板代码和来自Gandiva注册表的JIT函数,但是重要部分如下所示:
; Function Attrs: alwaysinline norecurse nounwind readnone ssp uwtable
define internal zeroext i1 @less_than_float32_float32(float, float) local_unnamed_addr #0 {
%3 = fcmp olt float %0, %1
ret i1 %3
}
; Function Attrs: alwaysinline norecurse nounwind readnone ssp uwtable
define internal zeroext i1 @greater_than_float32_float32(float, float) local_unnamed_addr #0 {
%3 = fcmp ogt float %0, %1
ret i1 %3
}
(...)
%x = load float, float* %11
%greater_than_float32_float32 = call i1 @greater_than_float32_float32(float %x, float 2.000000e+00)
(...)
%x11 = load float, float* %15
%less_than_float32_float32 = call i1 @less_than_float32_float32(float %x11, float 6.000000e+00)如您所见,在IR上,我们可以看到对函数的调用,less_than_float32_float_32而greater_than_float32_float32这就是(在这种情况下非常简单的)Gandiva函数进行浮点比较。通过查看函数名称前缀来注意函数的专业化。
有趣的是,LLVM将在此代码中应用所有优化,并且将为目标平台生成高效的本机代码,而Godiva和LLVM将负责确保内存对齐对于将要使用的AVX等扩展正确无误。向量化。
我显示的该IR代码实际上不是要执行的代码,而是经过优化的代码。在优化的代码中,我们可以看到LLVM内联了函数,如下面的优化代码的一部分所示:
%x.us = load float, float* %10, align 4
%11 = fcmp ogt float %x.us, 2.000000e+00
%12 = fcmp olt float %x.us, 6.000000e+00
%not.or.cond = and i1 %12, %11
您可以看到,经过优化后,该表达式现在变得更加简单,因为LLVM应用了其强大的优化功能并内联了许多Gandiva函数。
使用Gandiva构建Pandas过滤器表达式JIT
现在,我们希望能够DataFrame.query()使用Gandiva 实现类似于Pandas 函数的功能。我们将面临的第一个问题是,我们需要解析一个字符串,例如(x > 2.0) and (x < 6.0),之后我们将不得不使用来自Gandiva的树生成器来构建Gandiva表达式树,然后在箭头数据上计算该表达式。
现在,我没有使用表达式字符串的完整解析,而是使用Python AST模块来解析有效的Python代码并构建该表达式的抽象语法树(AST),稍后将使用它来发出Gandiva / LLVM节点。
解析字符串的繁重工作将委派给Python AST模块,我们的工作将主要在此树上进行,并基于该语法树发出Gandiva节点。下面显示了访问此Python AST树的节点并发出Gandiva节点的代码:
class LLVMGandivaVisitor(ast.NodeVisitor):
def __init__(self, df_table):
self.table = df_table
self.builder = gandiva.TreeExprBuilder()
self.columns = {f.name: self.builder.make_field(f)
for f in self.table.schema}
self.compare_ops = {
"Gt": "greater_than",
"Lt": "less_than",
}
self.bin_ops = {
"BitAnd": self.builder.make_and,
"BitOr": self.builder.make_or,
}
def visit_Module(self, node):
return self.visit(node.body[0])
def visit_BinOp(self, node):
left = self.visit(node.left)
right = self.visit(node.right)
op_name = node.op.__class__.__name__
gandiva_bin_op = self.bin_ops[op_name]
return gandiva_bin_op([left, right])
def visit_Compare(self, node):
op = node.ops[0]
op_name = op.__class__.__name__
gandiva_comp_op = self.compare_ops[op_name]
comparators = self.visit(node.comparators[0])
left = self.visit(node.left)
return self.builder.make_function(gandiva_comp_op,
[left, comparators], pa.bool_())
def visit_Num(self, node):
return self.builder.make_literal(node.n, pa.float64())
def visit_Expr(self, node):
return self.visit(node.value)
def visit_Name(self, node):
return self.columns[node.id]
def generic_visit(self, node):
return node
def evaluate_filter(self, llvm_mod):
condition = self.builder.make_condition(llvm_mod)
filter_ = gandiva.make_filter(self.table.schema, condition)
result = filter_.evaluate(self.table.to_batches()[0],
pa.default_memory_pool())
arr = result.to_array()
pd_result = arr.to_numpy()
return pd_result
@staticmethod
def gandiva_query(df, query):
df_table = pa.Table.from_pandas(df)
llvm_gandiva_visitor = LLVMGandivaVisitor(df_table)
mod_f = ast.parse(query)
llvm_mod = llvm_gandiva_visitor.visit(mod_f)
results = llvm_gandiva_visitor.evaluate_filter(llvm_mod)
return results
如您所见,代码非常简单,因为我不支持所有可能的Python表达式,而是其中的一小部分。我们在此类中所做的基本上是将诸如比较器和BinOps(二进制运算)之类的Python AST节点转换为Gandiva节点。我还更改了&和|运算符的语义,分别表示AND和OR,例如在Pandas query()函数中。
注册为Pandas扩展
下一步是使用gandiva_query()我们创建的方法创建一个简单的Pandas扩展:
@pd.api.extensions.register_dataframe_accessor("gandiva")
class GandivaAcessor:
def __init__(self, pandas_obj):
self.pandas_obj = pandas_obj
def query(self, query):
return LLVMGandivaVisitor.gandiva_query(self.pandas_obj, query)
就是这样,现在我们可以使用此扩展来执行以下操作:
df = pd.DataFrame({"a": [1.0 * i for i in range(nsize)]})
results = df.gandiva.query("a > 10.0")
由于我们已经注册了一个名为Pandas的扩展程序gandiva,该扩展程序现在是Pandas DataFrames的一等公民。
现在创建一个500万个float的DataFrame并使用新query()方法对其进行过滤:
df = pd.DataFrame({"a": [1.0 * i for i in range(50000000)]})
df.gandiva.query("a < 4.0")
# This will output:
# array([0, 1, 2, 3], dtype=uint32)
请注意,返回值是满足我们实现条件的索引,因此它与query()返回已过滤数据的Pandas不同。
我做了一些基准测试,发现Gandiva通常总是比Pandas快,但是我将在下一篇有关Gandiva的文章中留下适当的基准,因为该文章旨在展示如何将其用于JIT表达式。
而已 !我希望您喜欢我喜欢探索Gandiva的帖子。似乎我们可能会拥有越来越多的Gandiva加速工具,特别是用于SQL解析/投影/ JITing的工具。Gandiva远不止我刚刚展示的内容,但是您现在就可以开始了解它的体系结构以及如何构建表达式树。
– Christian S. Perone
智能推荐
EasyDarwin开源流媒体云平台之EasyRMS录播服务器功能设计_开源录播系统-程序员宅基地
文章浏览阅读3.6k次。需求背景EasyDarwin开发团队维护EasyDarwin开源流媒体服务器也已经很多年了,之前也陆陆续续尝试过很多种服务端录像的方案,有:在EasyDarwin中直接解析收到的RTP包,重新组包录像;也有:在EasyDarwin中新增一个RecordModule,再以RTSPClient的方式请求127.0.0.1自己的直播流录像,但这些始终都没有成气候;我们的想法是能够让整套EasyDarwin_开源录播系统
oracle Plsql 执行update或者delete时卡死问题解决办法_oracle delete update 锁表问题-程序员宅基地
文章浏览阅读1.1w次。今天碰到一个执行语句等了半天没有执行:delete table XXX where ......,但是在select 的时候没问题。后来发现是在执行select * from XXX for update 的时候没有commit,oracle将该记录锁住了。可以通过以下办法解决: 先查询锁定记录 Sql代码 SELECT s.sid, s.seri_oracle delete update 锁表问题
Xcode Undefined symbols 错误_xcode undefined symbols:-程序员宅基地
文章浏览阅读3.4k次。报错信息error:Undefined symbol: typeinfo for sdk::IConfigUndefined symbol: vtable for sdk::IConfig具体信息:Undefined symbols for architecture x86_64: "typeinfo for sdk::IConfig", referenced from: typeinfo for sdk::ConfigImpl in sdk.a(config_impl.o) _xcode undefined symbols:
项目05(Mysql升级07Mysql5.7.32升级到Mysql8.0.22)_mysql8.0.26 升级32-程序员宅基地
文章浏览阅读249次。背景《承接上文,项目05(Mysql升级06Mysql5.6.51升级到Mysql5.7.32)》,写在前面需要(考虑)检查和测试的层面很多,不限于以下内容。参考文档https://dev.mysql.com/doc/refman/8.0/en/upgrade-prerequisites.htmllink推荐阅读以上链接,因为对应以下问题,有详细的建议。官方文档:不得存在以下问题:0.不得有使用过时数据类型或功能的表。不支持就地升级到MySQL 8.0,如果表包含在预5.6.4格_mysql8.0.26 升级32
高通编译8155源码环境搭建_高通8155 qnx 源码-程序员宅基地
文章浏览阅读3.7k次。一.安装基本环境工具:1.安装git工具sudo apt install wget g++ git2.检查并安装java等环境工具2.1、执行下面安装命令#!/bin/bashsudoapt-get-yinstall--upgraderarunrarsudoapt-get-yinstall--upgradepython-pippython3-pip#aliyunsudoapt-get-yinstall--upgradeopenjdk..._高通8155 qnx 源码
firebase 与谷歌_Firebase的好与不好-程序员宅基地
文章浏览阅读461次。firebase 与谷歌 大多数开发人员都听说过Google的Firebase产品。 这就是Google所说的“ 移动平台,可帮助您快速开发高质量的应用程序并发展业务。 ”。 它基本上是大多数开发人员在构建应用程序时所需的一组工具。 在本文中,我将介绍这些工具,并指出您选择使用Firebase时需要了解的所有内容。 在开始之前,我需要说的是,我不会详细介绍Firebase提供的所有工具。 我..._firsebase 与 google
随便推点
k8s挂载目录_kubernetes(k8s)的pod使用统一的配置文件configmap挂载-程序员宅基地
文章浏览阅读1.2k次。在容器化应用中,每个环境都要独立的打一个镜像再给镜像一个特有的tag,这很麻烦,这就要用到k8s原生的配置中心configMap就是用解决这个问题的。使用configMap部署应用。这里使用nginx来做示例,简单粗暴。直接用vim常见nginx的配置文件,用命令导入进去kubectl create cm nginx.conf --from-file=/home/nginx.conf然后查看kub..._pod mount目录会自动创建吗
java计算机毕业设计springcloud+vue基于微服务的分布式新生报到系统_关于spring cloud的参考文献有啥-程序员宅基地
文章浏览阅读169次。随着互联网技术的发发展,计算机技术广泛应用在人们的生活中,逐渐成为日常工作、生活不可或缺的工具,高校各种管理系统层出不穷。高校作为学习知识和技术的高等学府,信息技术更加的成熟,为新生报到管理开发必要的系统,能够有效的提升管理效率。一直以来,新生报到一直没有进行系统化的管理,学生无法准确查询学院信息,高校也无法记录新生报名情况,由此提出开发基于微服务的分布式新生报到系统,管理报名信息,学生可以在线查询报名状态,节省时间,提高效率。_关于spring cloud的参考文献有啥
VB.net学习笔记(十五)继承与多接口练习_vb.net 继承多个接口-程序员宅基地
文章浏览阅读3.2k次。Public MustInherit Class Contact '只能作基类且不能实例化 Private mID As Guid = Guid.NewGuid Private mName As String Public Property ID() As Guid Get Return mID End Get_vb.net 继承多个接口
【Nexus3】使用-Nexus3批量上传jar包 artifact upload_nexus3 批量上传jar包 java代码-程序员宅基地
文章浏览阅读1.7k次。1.美图# 2.概述因为要上传我的所有仓库的包,希望nexus中已有的包,我不覆盖,没有的添加。所以想批量上传jar。3.方案1-脚本批量上传PS:nexus3.x版本只能通过脚本上传3.1 批量放入jar在mac目录下,新建一个文件夹repo,批量放入我们需要的本地库文件夹,并对文件夹授权(base) lcc@lcc nexus-3.22.0-02$ mkdir repo2..._nexus3 批量上传jar包 java代码
关于去隔行的一些概念_mipi去隔行-程序员宅基地
文章浏览阅读6.6k次,点赞6次,收藏30次。本文转自http://blog.csdn.net/charleslei/article/details/486519531、什么是场在介绍Deinterlacer去隔行处理的方法之前,我们有必要提一下关于交错场和去隔行处理的基本知识。那么什么是场呢,场存在于隔行扫描记录的视频中,隔行扫描视频的每帧画面均包含两个场,每一个场又分别含有该帧画面的奇数行扫描线或偶数行扫描线信息,_mipi去隔行
ABAP自定义Search help_abap 自定义 search help-程序员宅基地
文章浏览阅读1.7k次。DATA L_ENDDA TYPE SY-DATUM. IF P_DATE IS INITIAL. CONCATENATE SY-DATUM(4) '1231' INTO L_ENDDA. ELSE. CONCATENATE P_DATE(4) '1231' INTO L_ENDDA. ENDIF. DATA: LV_RESET(1) TY_abap 自定义 search help