一种海量数据安全分类分级架构的实现_数据安全管理分类分级、加密存储以及高效查询等应用解决方案-程序员宅基地
背景
随着《数据安全法》、《个人信息保护法》等相继出台,数据安全上升到国家安全层面和国家战略层面,数据分类分级已经成为了企业数据安全治理的必选题。然而数据分类分级的实现在行业内有很多痛点,主要体现在如下几点:
-
规则制定复杂:数据进行分类有多种维度,不同维度各有价值。在不同行业及领域,甚至具体到每个企业和部门,针对不同级别数据也各有定义。维度、级别的不清晰会导致后续基于分类分级的很多合规管控存在问题。* 协调沟通成本高:企业规模不断庞大,组织架构也随之变得复杂臃肿。数据的扫描上报关联到多个部门和事业群,甚至子公司。这涉及到多人之间的协调沟通,还需考虑网络隔离,访问权限和审批等诸多问题。* 数据容量大:互联网时代到来,企业信息化建设一直高速发展中,业务系统也越来越复杂。随之产生的海量数据,给企业带来巨大的价值。相应一旦海量数据泄漏,也会给企业造成严重的后果。如何实时,高效,全面覆盖海量数据分类分级,这对技术架构是一种考验。* 存储组件多:互联网尤其是云计算时代,企业为了应对大流量高并发业务场景,诞生关系型,非关系型,对象存储等多种存储组件。这既有开源实现,也有企业内部自研。不同的实现,有着不同的传输协议和数据结构。要覆盖多种存储组件数据分类分级,需要大量的工作量。然而查阅公司内外很多资料,往往只着重讲解数据分类分级概念与标准。目前并未有可借鉴,可落地的分类分级技术实现参考。因此本文重点不在于讨论数据分类分级的标准制定,而是从技术层面来讲述一种通用能力抽象封装,海量数据识别,跨部门和平台数据接入的分类分级架构实现。将数据分类分级技术进行赋能,避免重复造轮子。并以此为基础来从实际角度满足数据安全合规工作的落地和推展。
注:数据分类分级介绍参考数据安全治理:数据分类分级指南。

数据安全业务流程
(一)业务层面

从业务层面看,以数据分类分级作为数据安全的基石,来对数据进行安全管控,比如数据加密,数据脱敏,数据水印,权限管理,安全审计等。可见数据分类分级对数据安全的重要性。
(二)技术层面

从技术层面看,将数据扫描上报,通过数据识别引擎进行识别。然而在实际落地过程中,却发现很多问题。比如存储组件种类多,上报数据流量大,以及时效性,准确率,覆盖率等等问题。

整体架构

通过不断对数据分类分级业务分析,设计如上数据分类分级架构。架构核心由五大块组成:
-
多种存储组件数据扫描上报工具。* 数据识别服务集群,统一接收上报数据,并进行数据识别。* 识别规则引擎,统一维护识别规则的管理,在线热更新等功能。* 数据中台,依托分类分级结果,进行数据安全管控。* 依托公司的基础框架能力,保障引擎服务的高可用,比如监控,告警,日志,弹性扩缩容等。其中重点要处理前三点。

海量数据实时识别
企业规模不断庞大,海量用户,必然产生海量数据。如何满足高性能,时效性同时,又能达到高正确率和覆盖率要求,对于系统架构是一个巨大考验。
(一)数据存储
PCG目前覆盖近二十种存储组件类型和平台,三千万张表,以mdb,cdb,tredis,天穹为例:

存储选型
从表格可见,仅mdb已超过五百万张MySQL表,而cdb甚至超过一千万张MySQL表。而一张MySQL表即对应要保存一条分类分级识别结果。MySQL单表数据建议在五百万左右,超过这个数据量建议通过分库或分表处理,这在电商项目一些场景是可行,比如交易订单数据。但这也会带来经典的分布式事务等问题。
因此需要选择一种满足大容量,高并发,高可用和事务acid的数据库。
大数据hadoop
hadoop作为经典大数据存储架构,可存储pb级别以上数据,但时效性不高,通常用作T+1离线任务olap场景。且hadoop对事务acid支持有限,无法满oltp场景。
tidb
tidb是一款分布式海量容量云原生newsql。tidb底层使用raft算法,实现数据分布式存储和保证数据一致性。同时兼容MySQL协议,支持事务。因此tidb满足要求,然而公司目前没有专门团队维护tidb。
云原生tdsql-c
tdsql-c是TEG自研的一款的数据库。tdsql-c对MySQL架构做了改进,将计算和存储分离,从而实现存储和计算资源的快速扩容。因此tdsql-c支持MySQL协议和事务,同时具备高性能等特性。且公司目前有专门团队维护tdsql-c。
存储对比

从表格可见tidb和tdsql-c满足需求,但tdsql-c有公司内部专人维护。因此选择tdsql-c来存储数据分类分级识别结果。
(二)数据接入
服务端需要对接多种存储组件平台的数据上报,不用平台对资源,性能,时效性有不同要求。因此实现http,trpc,kafka多种接入方式,以满足不同场景。
kafka传输大数据
kafka可以实现消费端失败重试,且可以对流量进行削峰,推荐使用kafka进行数据上报。
为了保证识别结果正确,对关系型数据库单表取200条数据上传。大数据存在一些宽表或者大字段,导致上传的数据超过1M,这超过了kafka默认配置。除了限制上传数据包大小以外,也需要对kafka配置进行优化。
kafka producer
max.request.size=1048576 (1M)
batch.size=262144 (0.25M)
linger.ms=0
request.timeout.ms=30000
由于消息数据包比较大,因此不希望消息常驻producer内存,造成producer内存压力,因此让消息尽可能快速发送到broker端。
kafka consumer
fetch.max.bytes=1048576(1M)
fetch.max.wait.ms=1000
max.partition.fetch.bytes=262144(0.25M)
max.poll.records=5
topic partion>=20
retention.ms=2
由于消息数据包比较大,且consumer消费消息需要几百秒延迟,减少批量拉取消息数量同时提高拉取消息等待时间,避免consumer频繁去broker端拉取消息,导致consumer cpu被打爆。\
优化效果

数据识别
在解决数据上报,数据存储,数据接入以后,便是数据识别。这是整个数据分类分级架构最核心也是最复杂部分。对数据识别过程主要分为数据映射,规则管理,权重计算,数据校验四大块。
数据映射
服务端对单表取200条数据进行识别,按每张表20个字段,每个字段需进行20种正则识别。每天假设跑1千万张表,一共大概要跑8千亿次正则计算。如此巨大的计算量,在流量冲击下,立马将服务端的cpu飙升到100%,从而导致服务不可用!!!
相对于io密集型,cpu密集型无法简单使用常见的缓存,异步等方式去减轻服务端压力。因此需要考虑点如下:
-
通过云上k8s弹性扩缩容,将流量分散到多个容器节点,降低单节点负载压力。* 单节点利用多核并行,将计算压力分担到多个cpu核处理器上。并且使用信号量限流,避免cpu一直处于100%。* 正则表达式优化。藏在正则表达式里的陷阱,竟让CPU飙升到100%!###### 多核并行
多核并行借鉴MapReduce编程模型,本质是一种“分而治之”的思想。

优化效果


规则管理
数据的分类分级,需更精细化的规则管理,才能对后续数据安全做到更合理的管控。规则包括不限于正则,nlp,机器学习,算法,全文匹配,模糊匹配,黑名单等。对应每种具体分类分级定义,又包括多个规则的组合使用。通过实际的运营和梳理以后,目前有近四百种分类分级定义和八百种识别规则。
因此需考虑合理的方式,将规则管理和识别逻辑解耦,以便后续的维护和升级。同时需考虑规则热更新和关闭,做到对线上服务无感知。

权重计算
数据分类分级,在不同行业和业务有不同的维度和定义。且源数据由于开发和运维人员定义不清晰,导致最终识别结果存在模糊的边界。在实际运营过程中,常会因为识别结果不准确,被业务方反馈。
假设有字段叫xid,有可能是qqid,也可能是wechatid,而qdid和wechatid对应不同的分类分级,这会影响后续的合规流程。在实际场景,xid有可能同时被qqid和wechatid识别规则命中,那么该取哪个呢?
因此引入权重的概念,权重不在于将识别结果做简单的0和1取舍,而是通过多个组合规则识别后,计算出一个权重值,并对多个识别结果的权重值进行排序,取权重最大的识别结果作为当前字段的分类分级。

数据校验
数据安全合规管控,最重要一项是数据加密。为了方便运营后续进行合规追溯,需要在服务端对当前上报数据是否加密进行校验,并将校验结果保存下来。
数据是否加密需综合判断库表状态等信息,其中包括数据是否加密,表是否删除,库是否删除,实例是否下线等。状态的转换,通过以下决策树表示:


跨部门和平台接入
在重点解决数据上报和数据识别等难点以后,数据分类分级框架已可以满足大部分业务场景。因此也希望框架能服务更多的部门需求,减少大量繁琐重复的工作量。
由于数据分类分级结果属于敏感数据,对于跨部门和平台接入,需考虑将数据根据不同部门和平台进行物理隔离存储。


总结
数据分类分级很复杂,这种复杂性有业务层面,也有架构层面。本文重点在于述说架构层面的问题。这些问题有些可以提前规划设计,比如存储选型、通用扫描能力等。也有些需要在落地过程中持续优化,比如海量数据识别,除了对服务本身性能优化,也要对资源成本综合考虑。
架构没有好坏之分,只有合适一说。本文所讲述是基于个人在落地过程遇到问题的经验总结。因此反复斟酌,认真梳理写下本文,也是对本人工作的一个阶段总结。同时也希望框架能得到更多人认可,并达到数据分类分级能力复用,为公司数据安全合规工作尽到一点小小贡献。
网络安全入门学习路线
其实入门网络安全要学的东西不算多,也就是网络基础+操作系统+中间件+数据库,四个流程下来就差不多了。
1.网络安全法和了解电脑基础
 其中包括操作系统Windows基础和Linux基础,标记语言HTML基础和代码JS基础,以及网络基础、数据库基础和虚拟机使用等...
其中包括操作系统Windows基础和Linux基础,标记语言HTML基础和代码JS基础,以及网络基础、数据库基础和虚拟机使用等...
别被这些看上去很多的东西给吓到了,其实都是很简单的基础知识,同学们看完基本上都能掌握。计算机专业的同学都应该接触了解过,这部分可以直接略过。没学过的同学也不要慌,可以去B站搜索相关视频,你搜关键词网络安全工程师会出现很多相关的视频教程,我粗略的看了一下,排名第一的视频就讲的很详细。  当然你也可以看下面这个视频教程仅展示部分截图:
当然你也可以看下面这个视频教程仅展示部分截图:  学到http和https抓包后能读懂它在说什么就行。
学到http和https抓包后能读懂它在说什么就行。
2.网络基础和编程语言

3.入手Web安全
web是对外开放的,自然成了的重点关照对象,有事没事就来入侵一波,你说不管能行吗! 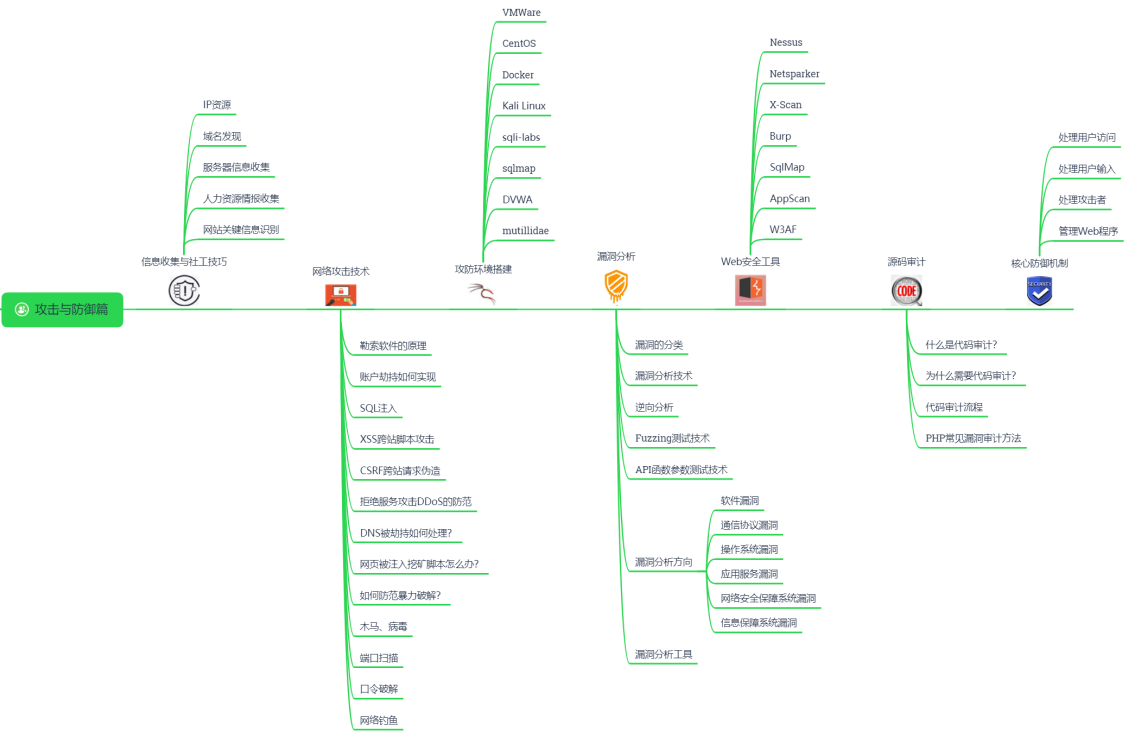 想学好Web安全,咱首先得先弄清web是怎么搭建的,知道它的构造才能精准打击。所以web前端和web后端的知识多少要了解点,然后再学点python,起码得看懂部分代码吧。
想学好Web安全,咱首先得先弄清web是怎么搭建的,知道它的构造才能精准打击。所以web前端和web后端的知识多少要了解点,然后再学点python,起码得看懂部分代码吧。
最后网站开发知识多少也要了解点,不过别紧张,只是学习基础知识。
等你用几周的时间学完这些,基本上算是具备了入门合格渗透工程师的资格,记得上述的重点要重点关注哦!  再就是,要正式进入web安全领域,得学会web渗透,OWASP TOP 10等常见Web漏洞原理与利用方式需要掌握,像SQL注入/XSS跨站脚本攻击/Webshell木马编写/命令执行等。
再就是,要正式进入web安全领域,得学会web渗透,OWASP TOP 10等常见Web漏洞原理与利用方式需要掌握,像SQL注入/XSS跨站脚本攻击/Webshell木马编写/命令执行等。
这个过程并不枯燥,一边打怪刷级一边成长岂不美哉,每个攻击手段都能让你玩得不亦乐乎,而且总有更猥琐的方法等着你去实践。
学完web渗透还不算完,还得掌握相关系统层面漏洞,像ms17-010永恒之蓝等各种微软ms漏洞,所以要学习后渗透。可能到这里大家已经不知所云了,不过不要紧,等你学会了web渗透再来看会发现很简单。
其实学会了这几步,你就正式从新手小白晋升为入门学员了,真的不算难,你上你也行。
4.安全体系
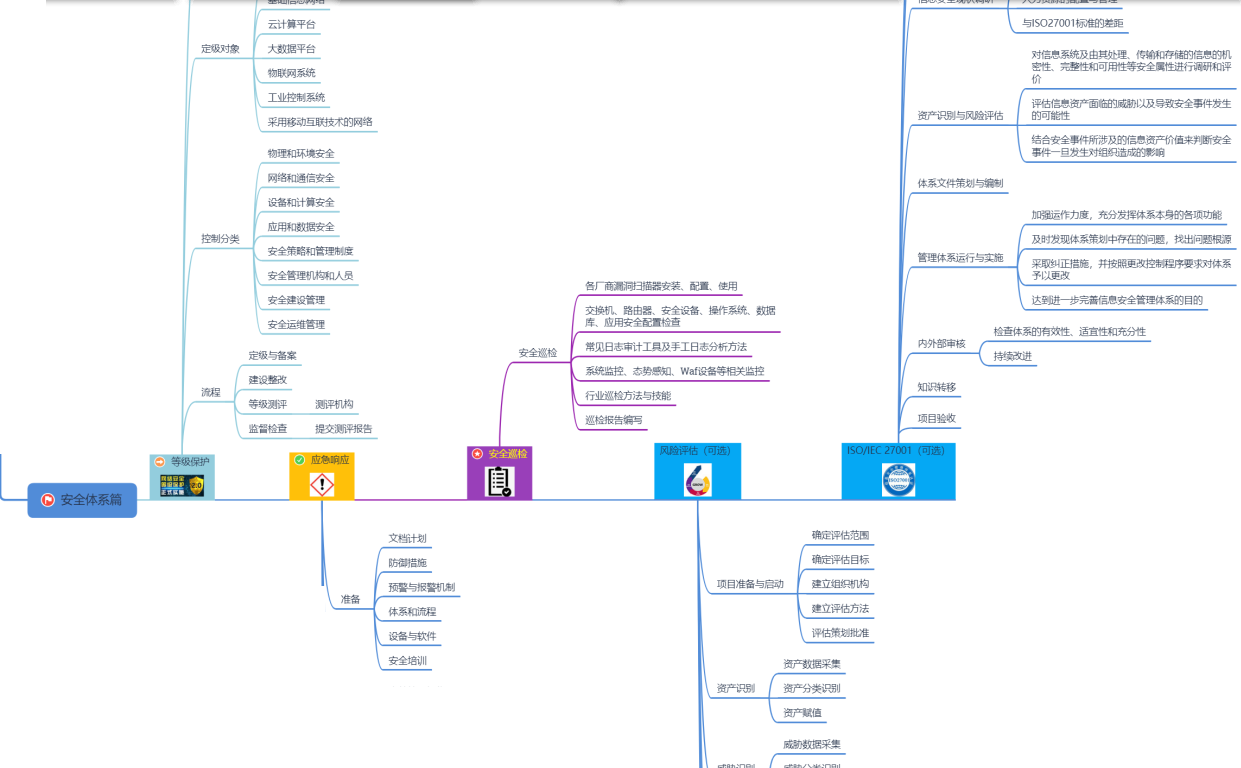 不过我们这个水平也就算个渗透测试工程师,也就只能做个基础的安全服务,而这个领域还有很多业务,像攻防演练、等保测评、风险评估等,我们的能力根本不够看。
不过我们这个水平也就算个渗透测试工程师,也就只能做个基础的安全服务,而这个领域还有很多业务,像攻防演练、等保测评、风险评估等,我们的能力根本不够看。
所以想要成为一名合格的网络工程师,想要拿到安全公司的offer,还得再掌握更多的网络安全知识,能力再更上一层楼才行。即便以后进入企业,也需要学习很多新知识,不充实自己的技能就会被淘汰。
从时代发展的角度看,网络安全的知识是学不完的,而且以后要学的会更多,同学们要摆正心态,既然选择入门网络安全,就不能仅仅只是入门程度而已,能力越强机会才越多。
尾言
因为入门学习阶段知识点比较杂,所以我讲得比较笼统,最后联合CSDN整理了一套【282G】网络安全从入门到精通资料包,需要的小伙伴可以点击链接领取哦! 网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!

智能推荐
超高速PCIe实时运动控制卡与应用方案将亮相深圳慕尼黑华南电子展,激发产业新活力!-程序员宅基地
文章浏览阅读84次。超值大奖等你来拿!
SQL盲注_sql盲注分别有几种类型-程序员宅基地
文章浏览阅读1.1k次。说明学习思路,源自《白帽子讲Web安全》,lcamry《MySQL注入天书》1、盲注注入漏洞不显示来自数据库的报错信息,报错信息中只包含通用的错误提示,此时SQL注入将不能通过报错信息直观获取注入语句的执行结果,既是盲注(Blind Injection)。盲注时不能直观获取结果,但可以通过基于逻辑真假的不同页面表现,来进行结果的判断,从而达到数据获取的目的。盲注的大致分类有三种1、基于布尔的SQL盲注2、基于时间的SQL盲注3、基于报错的SQL盲注2、基于布尔的MySQL盲注基本思路是对获_sql盲注分别有几种类型
Flutter状态管理4-flutter_bloc使用和原理学习总结-程序员宅基地
文章浏览阅读5.4k次,点赞2次,收藏10次。flutter_bloc今天发布了4.0.0版本,现关于其使用和原理做一个简单的总结。flutter_bloc官网:https://github.com/felangel/blochttps://bloclibrary.dev/#/flutterbloccoreconcepts?id=flutter-bloc-core-conceptspub.dev上的介绍,包括了多个Examples:...
视频监控安防平台-国标28181-2016(GB28181-2016)平台全项检测_怎么验证是否符合28181-2016标准-程序员宅基地
文章浏览阅读1w次,点赞4次,收藏18次。视频监控安防平台-国标28181 2016 GB28181 2016平台全项检测_怎么验证是否符合28181-2016标准
In Defense of Nearest-Neighbor Based Image Classification-程序员宅基地
文章浏览阅读1.4k次。OrenBoiman, Eli Shechtman, Michal Irani. In Defense of Nearest-Neighbor Based ImageClassification. IEEE Conference on Computer Vision & Pattern Recognition,2008, 69(4): 1~8这篇文章是我在做本科毕业设计《基于视频的运动目标检测_in defense of nearest-neighbor based image classification
史上最全量化交易资源整理_量化交易 交易费用 对比-程序员宅基地
文章浏览阅读2.5w次,点赞48次,收藏435次。开源量化交易框架整理: https://www.oschina.net/p/samaritan https://www.oschina.net/p/vn-py https://www.oschina.net/p/abu https://www.oschina.net/p/abuquant https://github.com/sun0x00/RedTorch ..._量化交易 交易费用 对比
随便推点
了解layui框架_layui框架的特性-程序员宅基地
文章浏览阅读3.8k次。layui简介layui(谐音:类UI) 是一款采用自身模块规范编写的前端 UI 框架,遵循原生 HTML/CSS/JS 的书写与组织形式,门槛极低,拿来即用。其外在极简,却又不失饱满的内在,体积轻盈,组件丰盈,从核心代码到 API 的每一处细节都经过精心雕琢,非常适合界面的快速开发。layui 首个版本发布于 2016 年金秋,她区别于那些基于 MVVM 底层的 UI 框架,却并非逆道而行,而是信奉返璞归真之道。准确地说,她更多是为服务端程序员量身定做,你无需涉足各种前端工具的复杂配置,只需面对浏_layui框架的特性
滤波器的Q值与带宽、滤波器_滤波器q值-程序员宅基地
文章浏览阅读3.4k次。那么,_滤波器q值
python下载jieba、无法识别pip_Python online无法PIP安装Jieba或其他包,显示超时超时,在线,pipinstalljieba,或者,package,timeout...-程序员宅基地
文章浏览阅读433次。问题:python在线pin无法安装package,如执行pip install jieba,显示红色错误:read time out原因分析:连接服务器,网速慢,文件大,导致下载连接超时,无法完成下载。解决一:添加参数:--default-timeout=100,执行命令为:pip --default-timeout=100 install jieba解决二:1、用迅雷等工具下载到*.tar.g..._jieba包下载超时
音频基础知识-程序员宅基地
文章浏览阅读1.7k次,点赞5次,收藏25次。本节对音频相关知识进行了详细的介绍及讲解。降低传输所需要的信道带宽, 同时保持输入语音的高质量。语音编码的目标在于:设计低复杂度的编码器以尽可能低的比特率实现高品质数据传输。_音频基础知识
Elasticsearch:路由 - routing_elasticsearch路由机制-程序员宅基地
文章浏览阅读1.2k次。路由是确定文档属于哪个分片以便检索它或将其存储在它所属的位置的过程。当 Elasticsearch 索引文档时,它会进行各种计算以确定将其放在哪个分片上。默认情况下,“_routing” 等于文档的 ID。这表明 Elasticsearch 查找文档的 ID 以确定它属于哪个分片。当我们更新或删除文档时也是如此。因此,当我们要求 Elasticsearch 通过其 ID 检索文档时,Elasticsearch 使用该 ID 来定位存储文档的分片。如果文档存在,几乎可以肯定它在路由公式对应的分片上。_elasticsearch路由机制
产品经理(22) #运营_史莱姆商家运营-程序员宅基地
文章浏览阅读247次。目录运营岗位分工解决问题活动内容运营运营究竟在做什么拉新 acquisition 用户增长 增长黑客促活&留存 activation&retention转化 revenueCASE1:公众号底栏设置新媒体运营导论流量获取平台流量:基础(主要借由内容手段在各个平台做粉丝累积,用户累积)社区流量:流量沉淀微信生态:流量变现流量循环体系流量循环抖音平台简介相关概念知乎运营新平台运营通用方法论选问题——._史莱姆商家运营