自动驾驶LiDAR点云深度学习综述-程序员宅基地
技术标签: 自动驾驶 机器学习 计算机视觉 深度学习 人工智能
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达/ 导读 /
本文是滑铁卢大学CogDrive实验室和Geospatial Sensing and Data Intelligence Lab实验室联合刚发表在 IEEE Transactions On Neural Networks And Learning Systems 上的一篇综述,主要介绍基于深度学习的 LiDAR 点云在无人车上的应用。

本篇综述总结了最近五年的140多项重要参考文献,包括具有里程碑意义的3D深度学习模型,以及他们在语义分割,目标检测和分类中的出色应用。此外,本文描述了常用的点云数据集。最后,对于当前研究的局限性及未来可能的研究方向提供了自己的见解。本文的原文DOI: 10.1109/TNNLS.2020.3015992

背景
准确的环境感知和精确的定位是自动驾驶汽车在复杂动态环境中能够进行可靠导航,信息决策以及安全驾驶的关键。这两个任务需要获取和处理真实环境中的高度准确且信息丰富的数据。为了获得此类数据,无人车上或者移动测量车上通常装备多种传感器,例如LiDAR或者相机。传统上,相机捕获的图像数据能够提供二维语义和纹理信息,且低成本和高效率,是感知任务中最常用的数据之一。但是,图像数据缺少三维地理信息。因此,由LiDAR收集的密集的、准确的、具有三维地理信息的点云数据也应用于感知任务中。此外,LiDAR对照明条件的变化不敏感,可以在白天和夜晚工作,即使有强光和阴影干扰。
LiDAR点云在自动驾驶领域中的应用可以分为以下两个方面:1)基于场景理解和目标检测的实时环境感知和处理;2)基于可靠定位和参考的高精度地图和城市模型的生成和构建。这些应用具有一些类似的任务,可以大致分为三种类型:点云分割,三维目标检测和定位以及三维目标分类和识别。这项技术的发展引发了自动驾驶领域对点云数据自动处理与分析的日益迫切的需求。
近些年来, 随着深度学习的不断突破和三维点云数据的可及性,3D深度学习在2D深度学习的基础上取得了一系列显著的成果。这些3D深度学习网络主要应用于自动驾驶汽车的几个相关任务,例如:语义分割和场景理解,目标检测和目标分类。因此,本文主要集中在构建基于深度学习的LiDAR点云在自动驾驶汽车分割,检测,和分类任务上的系统性综述。

问题与难点
点云语义分割:将输入点云数据聚集成几个同质区域的过程,其中相同区域中的点具有相同的属性。每个点都分配有语义标签,例如:道路,树木,建筑物等。语义分割结果可以为目标检测提供前景和背景分类信息。
3D目标检测:给定任意点云数据,目标检测能够定位和检测预定义类别的场景实例,并输出他们的三维位置,方向,和语义实例标签。这些信息可以用3D边界框粗略地表示。这些边界框通常由边界框(目标物)中心点三维坐标、边界框的长宽高、边界框的方向、以及它的语义标签表示。
3D目标分类: 给定任意一组点云,目标分类能够输出它的类别,例如:车辆,行人等。
感知条件和不受限制的环境变化会对LiDAR扫描的物体外观有着巨大影响。特别是在不同场景甚至是同一场景捕获的对象,由于扫描时间,位置,天气状况,传感器类型,感测距离和背景的不同都带来了差异。所有这些条件都会对LiDAR点云中的类间和类类对象产生显著影响:
多样化的点云密度和反射强度:由于LiDAR的扫描模式,点云物体的密度和强度变化很大。这两个特征的分布高度取决于物体与LiDAR传感器之间的距离。此外,LiDAR传感器的功能,扫描的时间限制和所需的分辨率也会影响其分布和强度。
噪声:所有传感器都有噪声。LiDAR有几种类型的噪声包括点扰动和离群值。这意味着一个点可能存在于被采样(扰动)点周围一定半径的球体内,或者它可能出现在空间中的随机位置。
不完整性:LiDAR获得的点云通常是不完整的。这主要是由于物体之间的遮挡,城市场景中背景的混乱,和材料表面反射率不理想所致。这样的问题在实时捕获运动对象时非常严重,导致这些被扫描运动对象点云数据存在较大的空洞和严重的欠采样。
类别混乱。在自然环境中扫描的形状相似或反射性相似的物体对目标检测和分类会产生干扰。例如,一些人工制作的目标物如广告牌和路牌的相似度就很高。
不规则的点云数据格式以及对准确性和效率的要求给3D深度学习模型带来了一些新挑战。在构建一个高效且有鲁棒性的3D深度学习模型时,主要集中解决以下几个问题:
排列和方向不变挑战:与二维栅格像素相比,LiDAR点云是一组具有不规则顺序且没有特定方向的点。在同一组输入的N个点,网络应对输入的N!种排列保持不变。此外,对于缺少方向性的点云数据,目标识别面临很大的挑战。
刚性变化挑战。点集之间存在各种刚性变换,例如3D旋转和3D平移。这些转变不应影响网络的性能。
大数据挑战。LiDAR在不同城市的自然场景中收集数百万至数十亿个点,例如,在KITTI数据集中,由3D Velodyne激光扫描仪捕获的每一帧都包含10万个点,其收集的最小场景为114帧,超过1000万个点。这样的数据量给数据存储和处理带来困难。
精度挑战。准确感知道路物体对于自动驾驶汽车至关重要。但是,类类和类间对象的变化以及数据质量都对准确性提出了挑战。例如,就各种材料、形状、和大小而言,同一类别中的对象具有不同的场景实例。此外,构建的模型应对点云数据分布不均、稀疏、和缺失具有鲁棒性。
效率挑战。与二维图像相比,处理大量的点云会产生较高的计算复杂度和时间成本。此外,自动驾驶汽车上的计算设备具有有限的计算能力和存储空间。因此,构建高效且可扩展的深度网络模型至关重要。


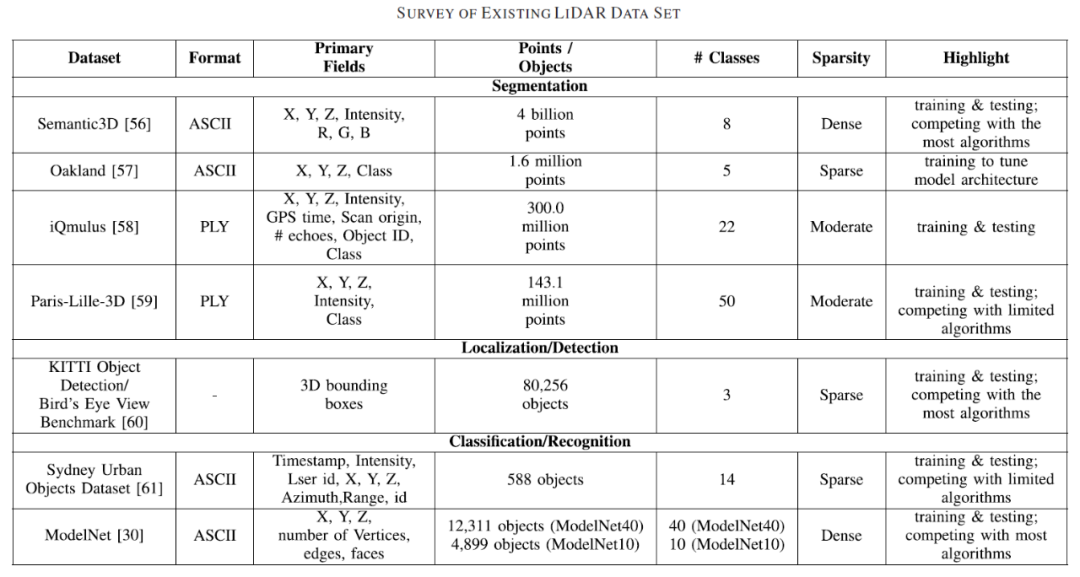
常用数据集
室外语义分割数据集:
Semantic3D
Oakland
IQmulus
Paris-Lille-3D
室外目标物检测数据集:
KITTI 3D Object Detection Evaluation 2017
KITTI Bird's Eye View Evaluation 2017
nuScenes
Waymo
Lyft
apolloscape
目标分类数据集:
SYDNEYURBAN OBJECTS DATASET
室内场景数据集:
The Stanford Large-Scale 3D Indoor Spaces Dataset (S3DIS)
Richly-annotated 3D Reconstructions of Indoor Scenes (ScanNet)
SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite
NYU Depth Dataset V2

通用3D深度学习模型
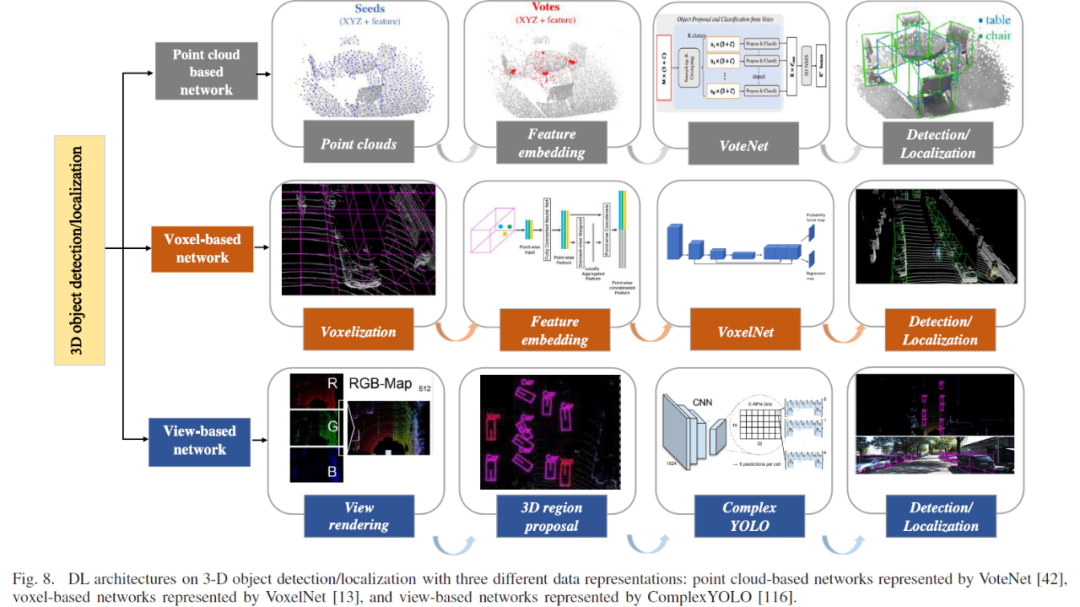
本篇综述分析了一些先驱性的3D深度学习模型,这些模型致力于解决上述的LiDAR点云所面临的问题。此外,它们稳定高效的性能使其适合用作构建分割、检测、和分类网络的backbone。尽管LiDAR采集的3D数据通常以点云的形式出现,但是如何表示点云以及用那种深度学习模型去分割,检测,和分类仍然是一个未解决的问题。目前大多数3D深度学习网络主要集中在以体素(voxel),点云(point cloud),图(graph),和视图(view)等四种点云表示方式来构建网络。
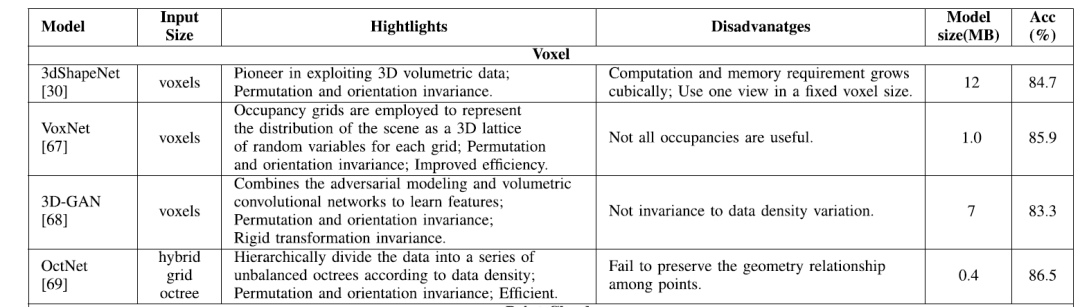
(1)基于体素(voxel)的深度学习网络
传统上,卷积神经网络(CNN)主要应用于具有规则结构的数据,例如二维像素阵列。因此,为了将CNN应用于无序3D点云,通常将点云数据划分为具有一定大小的规则网格,以描述其在三维空间中的分布。通常,网格的大小与数据的分辨率有关。基于体素的表示的优势在于,它可以通过将被占用的体素分类为几种类型(例如可见,遮挡或自遮挡)来对三维形状和视点信息进行编码。此外,还可以在体素网格中直接应用3D卷积(Conv)和池化(pooling)操作。
但是基于体素的3D数据表示存在以下局限性:
首先,并不是所有体素都有用,因为它们包含扫描环境中已占用和未占用的部分。因此,对于这种非高效的数据表示方式,对计算机存储的高需求是不必要的。
其次,网格的大小难以设置,因为这会影响输入数据的尺度,并可能破坏点与点之间的空间关系。
第三,计算和存储需求随着体素分辨率的增长而立方增长。 因此,现有的基于体素的模型通常保持在低分辨率下,体素的最常用尺寸为303。
更高效的体素数据表示法是基于八叉树(octree)的网格,它们使用自适应大小将3D点云划分为不同的网格。它是一种分层数据结构,可将根体素递归分解为多个叶体素。
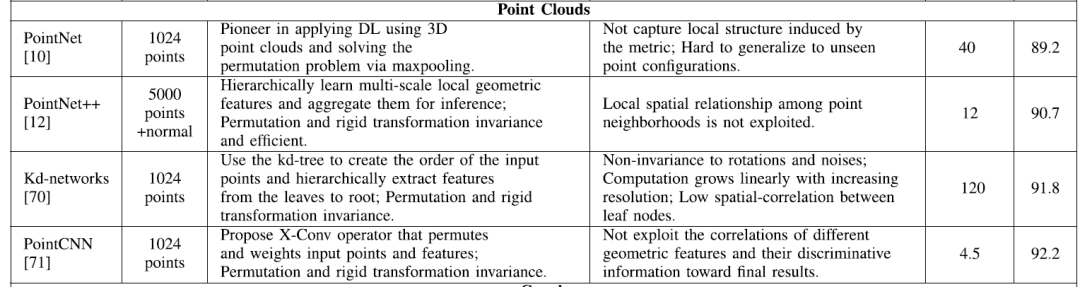
(2)基于点云(point cloud)的深度学习网络
与体素数据表示不同,点云可以保留点云的三维地理空间信息和内部局部结构。此外,以固定步幅扫描空间的基于体素的模型受局部感受野的约束。但是对于点云,输入数据及其度量方式决定了感受野的范围,具有很高的效率和准确性。
基于点云的深度模型主要集中在解决输入排列问题。尽管它们在局部尺度上独立地处理点以维持置换不变性,但是这种独立性忽略了点及其相邻点之间的几何关系,从而导致更高级的局部特征缺失。
(3)基于图(graph)的深度学习网络
图是一种非欧氏数据结构,可用于表示点云。它们的节点对应于每个输入点,并且边表示每个相邻点之间的关系。图神经网络以迭代的方式传播节点状态直到达到平衡。随着CNN的发展,越来越多的图卷积网络被应用于三维数据。这些图卷积网络在光谱和非光谱(空间)域中直接在图上定义卷积,对空间上紧密相邻的组进行操作。基于图的深度学习模型的优点是能够探索点及其相邻点之间的几何关系。但是,构建基于图的深度模型存在以下两个挑战:
首先,定义一个适合于动态邻域大小的CNN,并维护CNN的权重共享机制。
其次,探索每个节点邻域之间的空间和几何关系。
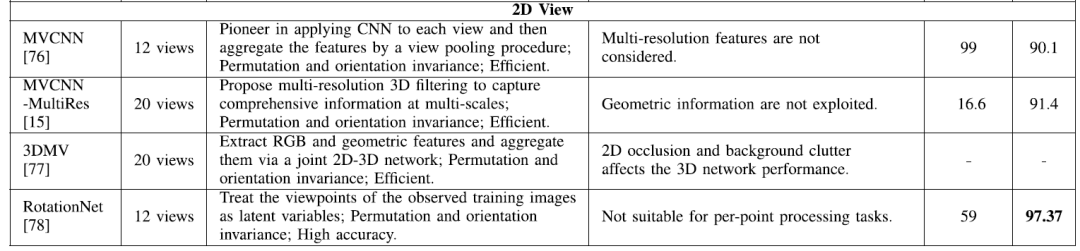
(4)基于视图(view)的深度学习网络
LiDAR点云数据的最后一种表示类型是从不同方向的3D点云获得的2D视图。借助投影的二维视图,可以利用传统完善的CNN和图像数据集上的预训练网络,例如AlexNet、VGG、GoogLeNet、和ResNet 等。与基于体素的模型相比,这些方法可以通过对感兴趣的对象或场景进行多视图查看,然后对输出进行融合或投票以进行最终预测,从而提高不同3D任务的性能。与上述三种不同的点云数据表示相比,基于视图的模型可以实现近乎最佳的结果。与点云和体素数据表示模型相比,即使不使用预训练模型,多视图方法也具有最佳的泛化能力。基于视图的模型的优势可以归纳如下:
效率。与点云或体素网格等3D数据表示相比,减少的一维信息可以大大降低计算成本,但分辨率更高。
可以利用已有的2D CNN和数据集。现有的2D深度学习网络可以更好地利用投影的2D视图图像中的局部和全局信息。此外,现有的图像数据集(如ImageNet)可用于训练2D深度网络。
但是,基于视图的模型存在一些限制:
首先,从3D空间到2D视图的投影可能会丢失一些几何相关的空间信息。
第二个是多个视图之间存在冗余信息。


点云深度学习在无人车中的应用
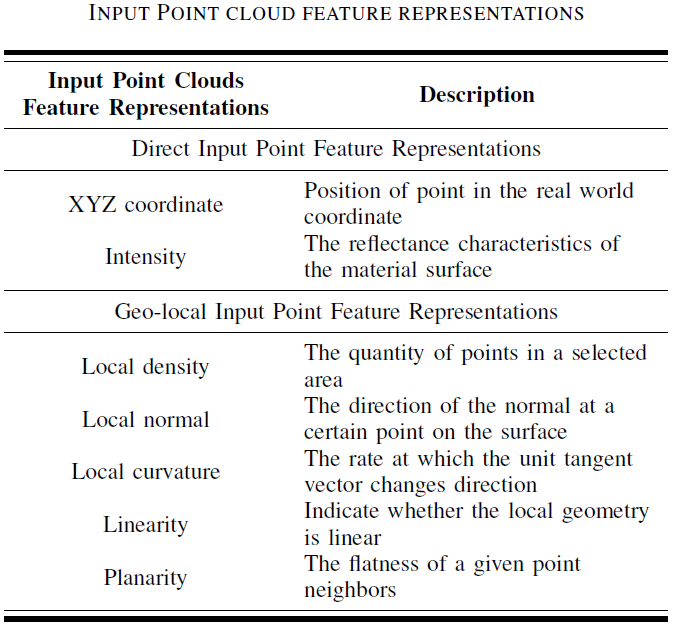
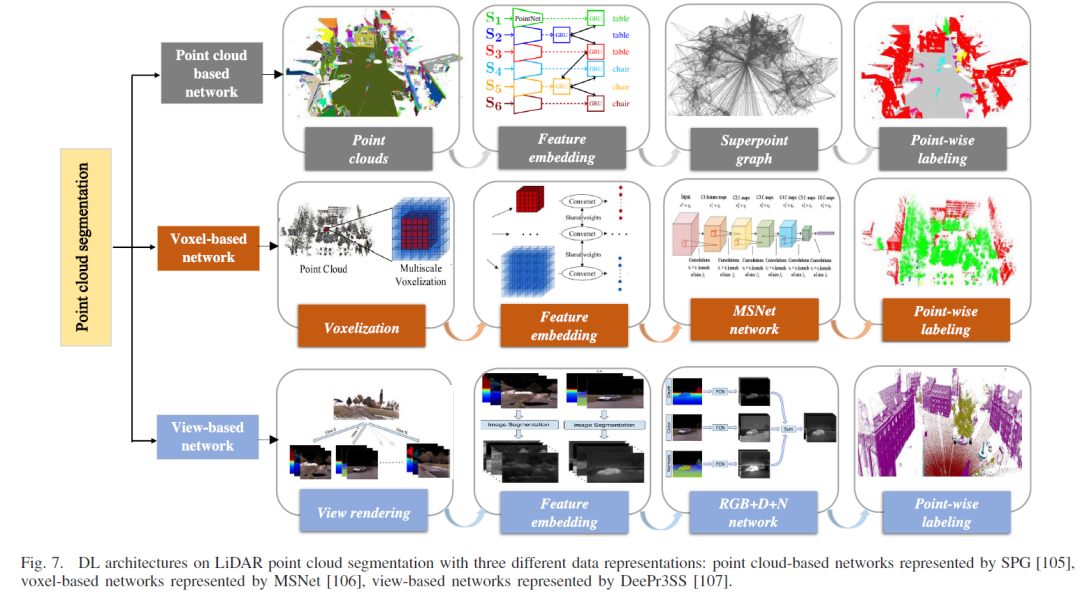
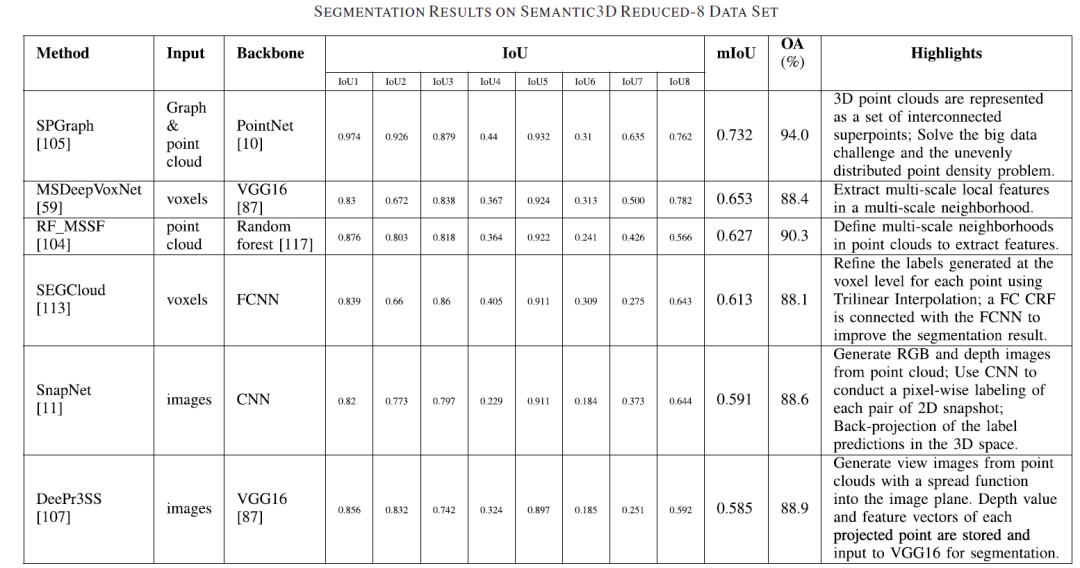
1.点云语义分割
2.目标检测
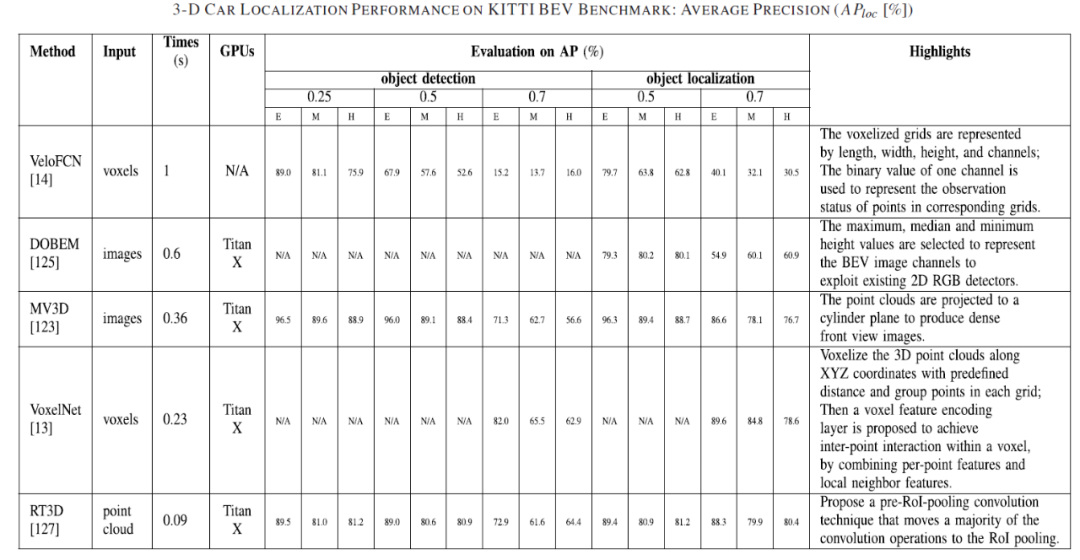
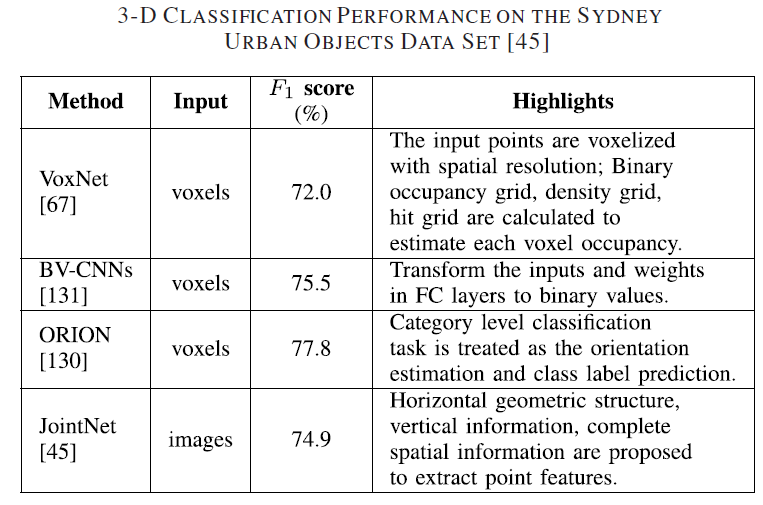
3.目标分类

点云研究挑战与机遇
(1) 多源数据融合:为了弥补3D点云中语义和纹理信息的缺失和弥补不完整的点云信息,图像、LiDAR点云、和radar数据可以融合在一起为自动驾驶汽车导航和决策提供准确、具有地理参考、和信息丰富的提示。此外,低端LiDAR(例如Velodyne HDL-16E)和高端LiDAR(例如Velodyne HDL-64E)采集的数据之间也存在融合问题。但是,融合这些数据存在一些挑战。首先是点云的稀疏性导致融合多源数据时数据不一致和丢失。第二个问题是,现有的基于深度学习数据融合方案是在单独的流程中处理的,而不是端到端方案。
(2) 鲁棒性的点云数据表示:非结构化和无序的数据格式对3D深度学习的应用产生了巨大的挑战。尽管有几种有效的数据表示,例如体素、点云、图、视图或新颖的3D数据表示方式,但目前尚未就鲁棒且高效存储的3D数据表示达成共识。例如,尽管体素解决了排序问题,但是计算成本随着体素分辨率的增加而立方增加。对于点云和图,置换不变性和计算能力限制了点的可处理数量,这不可避免地限制了深层模型的性能。
(3) 有效且高效的3D深度学习框架:由于自动驾驶汽车计算能力的限制,有效和高效的深度学习网络结构构建至关重要。尽管现有3D模型中有重大改进,例如PointNet,PointNet ++,PointCNN,DGCNN,RotationNet等。但很少有模型可以同时实现鲁棒性的实时分割、检测和分类任务。
(4) 上下文知识提取:由于点云的稀疏性和所扫描对象的不完整性,目标对象的详细上下文信息没有被深度学习网络充分利用。例如,交通标志中的语义信息是自动驾驶汽车导航的关键线索,但是现有的深度模型无法完全从点云中提取此类信息。因而,有些方法利用多尺度特征融合策略以进行上下文信息提取。此外,生成式对抗网络(GAN)也可以用来提高3D点云的完整性。但是,这些框架无法以端到端的可训练方式解决上下文信息提取的稀疏性和不完整性问题。
(5) 多任务学习:LiDAR点云可以应用在自动驾驶汽车相关的几个任务,例如场景分割,目标检测(例如汽车,行人,交通信号灯等)和分类(例如道路标记和交通标志)。这些结果通常被融合在一起报告给决策系统以进行最终控制。尽管有一些深度学习模型将这些任务组合在一起完成。但它们之间的信息没有得到充分利用,并不能以更少的计算来生成更好的模型。
(6)弱监督/无监督学习:现有的深度学习模型通常是在监督模式下使用带有3D对象边界框或带标签的点进行训练测试。但是,这是基于监督学习的模型存在一些限制。首先是高质量、大规模、庞大的通用对象数据集的有限可用性。其次是,监督学习的模型对非常见或未经训练的对象的泛化能力较弱。
好消息!
小白学视觉知识星球
开始面向外开放啦

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~智能推荐
前端开发之vue-grid-layout的使用和实例-程序员宅基地
文章浏览阅读1.1w次,点赞7次,收藏34次。vue-grid-layout的使用、实例、遇到的问题和解决方案_vue-grid-layout
Power Apps-上传附件控件_powerapps点击按钮上传附件-程序员宅基地
文章浏览阅读218次。然后连接一个数据源,就会在下面自动产生一个添加附件的组件。把这个控件复制粘贴到页面里,就可以单独使用来上传了。插入一个“编辑”窗体。_powerapps点击按钮上传附件
C++ 面向对象(Object-Oriented)的特征 & 构造函数& 析构函数_"object(cnofd[\"ofdrender\"])十条"-程序员宅基地
文章浏览阅读264次。(1) Abstraction (抽象)(2) Polymorphism (多态)(3) Inheritance (继承)(4) Encapsulation (封装)_"object(cnofd[\"ofdrender\"])十条"
修改node_modules源码,并保存,使用patch-package打补丁,git提交代码后,所有人可以用到修改后的_修改 node_modules-程序员宅基地
文章浏览阅读133次。删除node_modules,重新npm install看是否成功。在 package.json 文件中的 scripts 中加入。修改你的第三方库的bug等。然后目录会多出一个目录文件。_修改 node_modules
【】kali--password:su的 Authentication failure问题,&sudo passwd root输入密码时Sorry, try again._password: su: authentication failure-程序员宅基地
文章浏览阅读883次。【代码】【】kali--password:su的 Authentication failure问题,&sudo passwd root输入密码时Sorry, try again._password: su: authentication failure
整理5个优秀的微信小程序开源项目_微信小程序开源模板-程序员宅基地
文章浏览阅读1w次,点赞13次,收藏97次。整理5个优秀的微信小程序开源项目。收集了微信小程序开发过程中会使用到的资料、问题以及第三方组件库。_微信小程序开源模板
随便推点
Centos7最简搭建NFS服务器_centos7 搭建nfs server-程序员宅基地
文章浏览阅读128次。Centos7最简搭建NFS服务器_centos7 搭建nfs server
Springboot整合Mybatis-Plus使用总结(mybatis 坑补充)_mybaitis-plus ruledataobjectattributemapper' and '-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏3次。前言mybatis在持久层框架中还是比较火的,一般项目都是基于ssm。虽然mybatis可以直接在xml中通过SQL语句操作数据库,很是灵活。但正其操作都要通过SQL语句进行,就必须写大量的xml文件,很是麻烦。mybatis-plus就很好的解决了这个问题。..._mybaitis-plus ruledataobjectattributemapper' and 'com.picc.rule.management.d
EECE 1080C / Programming for ECESummer 2022 Laboratory 4: Global Functions Practice_eece1080c-程序员宅基地
文章浏览阅读325次。EECE 1080C / Programming for ECESummer 2022Laboratory 4: Global Functions PracticePlagiarism will not be tolerated:Topics covered:function creation and call statements (emphasis on global functions)Objective:To practice program development b_eece1080c
洛谷p4777 【模板】扩展中国剩余定理-程序员宅基地
文章浏览阅读53次。被同机房早就1年前就学过的东西我现在才学,wtcl。设要求的数为\(x\)。设当前处理到第\(k\)个同余式,设\(M = LCM ^ {k - 1} _ {i - 1}\) ,前\(k - 1\)个的通解就是\(x + i * M\)。那么其实第\(k\)个来说,其实就是求一个\(y\)使得\(x + y * M ≡ a_k(mod b_k)\)转化一下就是\(y * M ...
android 退出应用没有走ondestory方法,[Android基础论]为何Activity退出之后,系统没有调用onDestroy方法?...-程序员宅基地
文章浏览阅读1.3k次。首先,问题是如何出现的?晚上复查代码,发现一个activity没有调用自己的ondestroy方法我表示非常的费解,于是我检查了下代码。发现再finish代码之后接了如下代码finish();System.exit(0);//这就是罪魁祸首为什么这样写会出现问题System.exit(0);////看一下函数的原型public static void exit (int code)//Added ..._android 手动杀死app,activity不执行ondestroy
SylixOS快问快答_select函数 导致堆栈溢出 sylixos-程序员宅基地
文章浏览阅读894次。Q: SylixOS 版权是什么形式, 是否分为<开发版税>和<运行时版税>.A: SylixOS 是开源并免费的操作系统, 支持 BSD/GPL 协议(GPL 版本暂未确定). 没有任何的运行时版税. 您可以用她来做任何 您喜欢做的项目. 也可以修改 SylixOS 的源代码, 不需要支付任何费用. 当然笔者希望您可以将使用 SylixOS 开发的项目 (不需要开源)或对 SylixOS 源码的修改及时告知笔者.需要指出: SylixOS 本身仅是笔者用来提升自己水平而开发的_select函数 导致堆栈溢出 sylixos