【爬虫实战】python文本分析库——Gensim-程序员宅基地
技术标签: 爬虫 python Python文本分析 Python爬虫 Gensim Python学习 开发语言
文章目录
01、引言
Gensim是一个用于自然语言处理和文本分析的 Python 库,提供了许多强大的功能,包括文档的相似度计算、关键词提取和文档的主题分析,要开始使用Gensim,您需要安装它,再进行文本分析和NLP任务,安装Gensim可以使用pip:
pip install gensim
02、主题分析以及文本相似性分析
Gensim是一个强大的Python库,用于执行主题建模和文本相似性分析等自然语言处理任务。使用Gensim进行主题建模(使用Latent Dirichlet Allocation,LDA)和文本相似性分析(使用 similarities 模块中的 MatrixSimilarity 或 SparseMatrixSimilarity 来计算文档相似度),代码如下:
from gensim import corpora, models, similarities
# 创建一个简单的文本数据集作为示例
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# 预处理文本数据:
# 切分文档为单词
text = [document.split() for document in documents]
# 创建一个词典,将每个单词映射到一个唯一的整数ID
dictionary = corpora.Dictionary(text)
# 使用词典将文本转化为文档-词袋(document-term)表示
corpus = [dictionary.doc2bow(doc) for doc in text]
#训练LDA模型并执行主题建模:
# 训练LDA模型
lda_model = models.LdaModel(corpus, num_topics=2, id2word=dictionary, passes=15)
# 输出主题及其词汇
for topic in lda_model.print_topics():
print(topic)
#文本相似性分析:
from gensim import similarities
# 创建一个索引
index = similarities.MatrixSimilarity(lda_model[corpus])
# 定义一个查询文本
query = "This is a new document."
# 预处理查询文本
query_bow = dictionary.doc2bow(query.split())
# 获取查询文本与所有文档的相似性得分
sims = index[lda_model[query_bow]]
# 按相似性得分降序排列文档
sims = sorted(enumerate(sims), key=lambda item: -item[1])
# 输出相似文档及其得分
for document_id, similarity in sims:
print(f"Document {document_id}: Similarity = {similarity}")
结果如下:
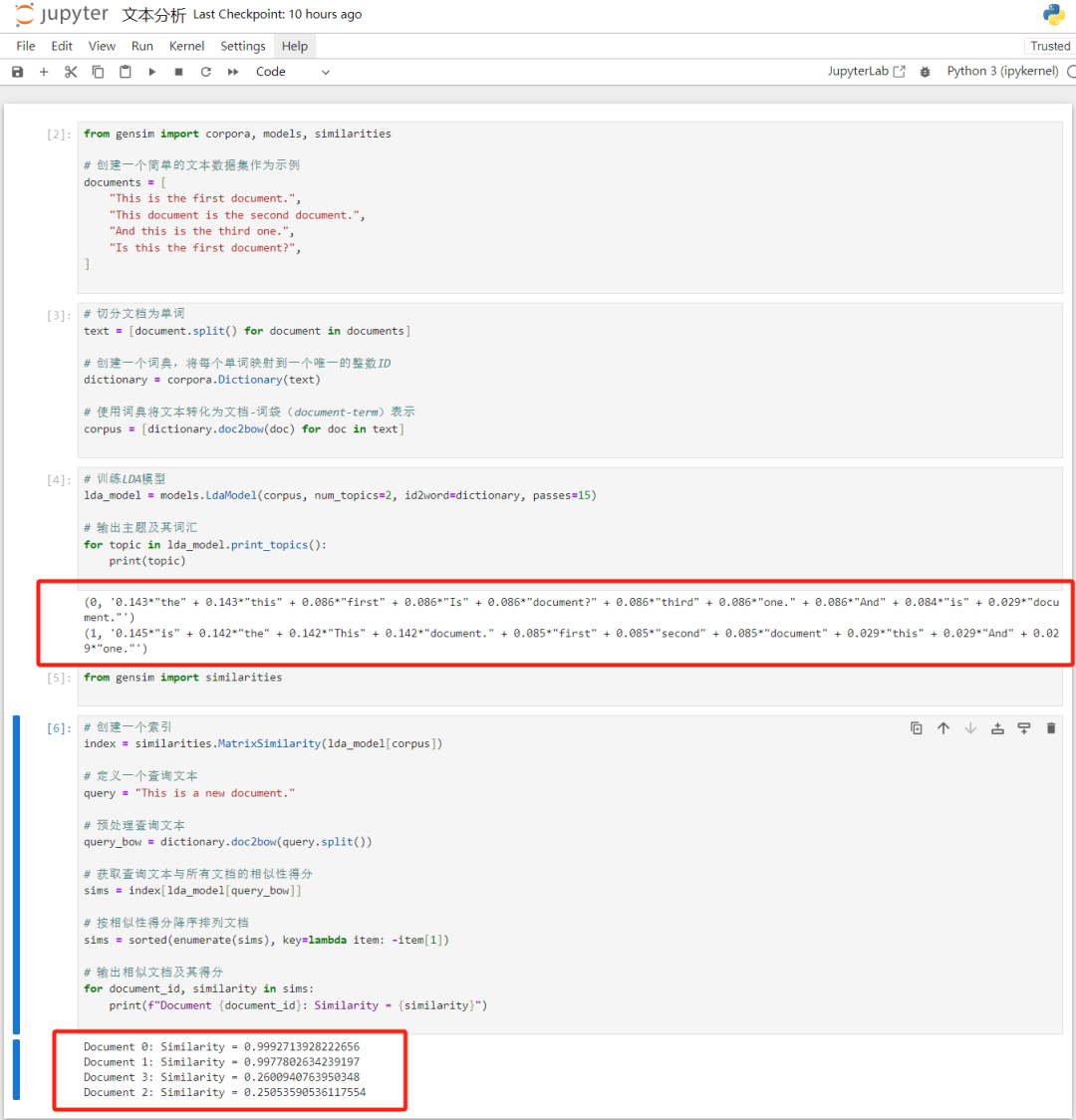
另一种方法,在gensim下用 Wasserstein 距离方法计算文档相似度,代码如下:
from gensim import corpora
from scipy.stats import wasserstein_distance
import numpy as np
# 示例文档
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# 预处理文本和创建词典
text = [document.split() for document in documents]
dictionary = corpora.Dictionary(text)
# 创建文档的词袋表示
corpus = [dictionary.doc2bow(doc) for doc in text]
# 创建文档的概率分布
document_distributions = [np.array([0] * len(dictionary)) for _ in range(len(corpus))]
for i, doc_bow in enumerate(corpus):
for word_id, count in doc_bow:
document_distributions[i][word_id] = count / len(doc_bow)
# 计算Wasserstein距离
# 这里示例计算第一个文档和其他文档之间的Wasserstein距离
for i in range(1, len(document_distributions)):
wasserstein_dist = wasserstein_distance(document_distributions[0], document_distributions[i])
print(f"Wasserstein Distance between Document 0 and Document {i}: {wasserstein_dist}")
结果如下:
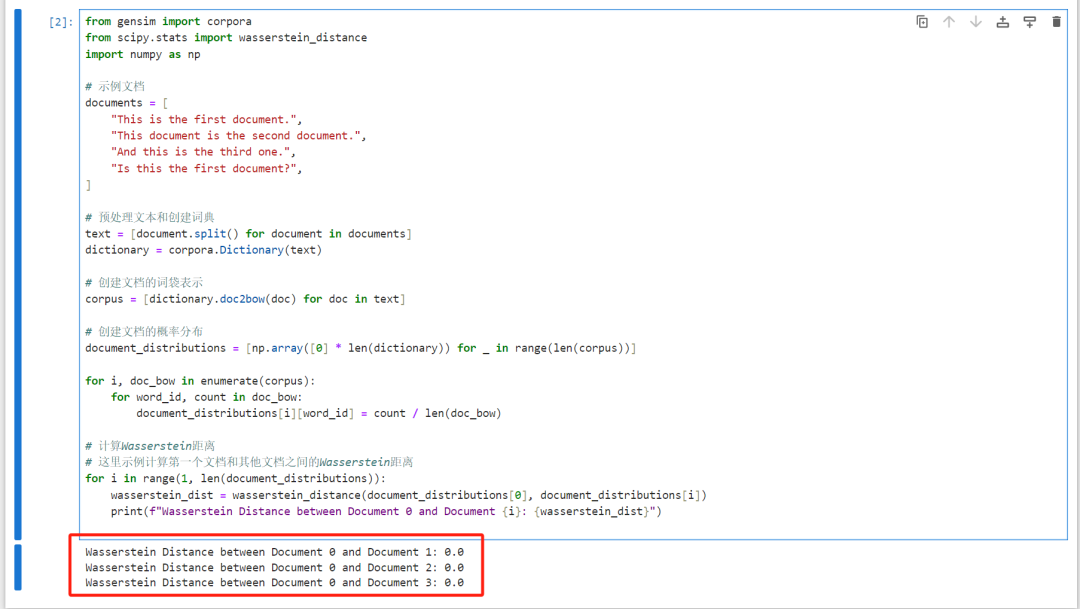
03、关键词提取
Gensim 允许你使用 TF-IDF 权重和其他算法来提取文档中的关键词。你可以使用 models.TfidfModel 来计算 TF-IDF 权重,然后使用 model.get_document_topics 来获取文档的主题分布,代码如下:
from gensim import corpora, models
from gensim.parsing.preprocessing import preprocess_string, strip_punctuation
# 示例文档
documents = [
"This is the first document. It contains important information.",
"This document is the second document. It also has important content.",
"And this is the third one. It may contain some relevant details.",
"Is this the first document? Yes, it is."
]
# 预处理文本
def preprocess(text):
# 使用Gensim的文本预处理工具进行处理,包括去除标点符号
custom_filters = [strip_punctuation]
processed_text = preprocess_string(text, custom_filters)
return processed_text
# 预处理文档并创建词袋表示
text = [preprocess(document) for document in documents]
dictionary = corpora.Dictionary(text)
corpus = [dictionary.doc2bow(doc) for doc in text]
# 计算TF-IDF模型
tfidf_model = models.TfidfModel(corpus)
lda_model=models.LdaModel(corpus)
# 获取TF-IDF加权
for i, doc in enumerate(corpus):
tfidf_weights = tfidf_model[doc]
print(f"TF-IDF Weights for Document {i}: {tfidf_weights}")
# 获取文档的主题分布
for i, doc in enumerate(corpus):
document_topics = lda_model.get_document_topics(doc)
print(f"Topic Distribution for Document {i}: {document_topics}")
最终结果如下:
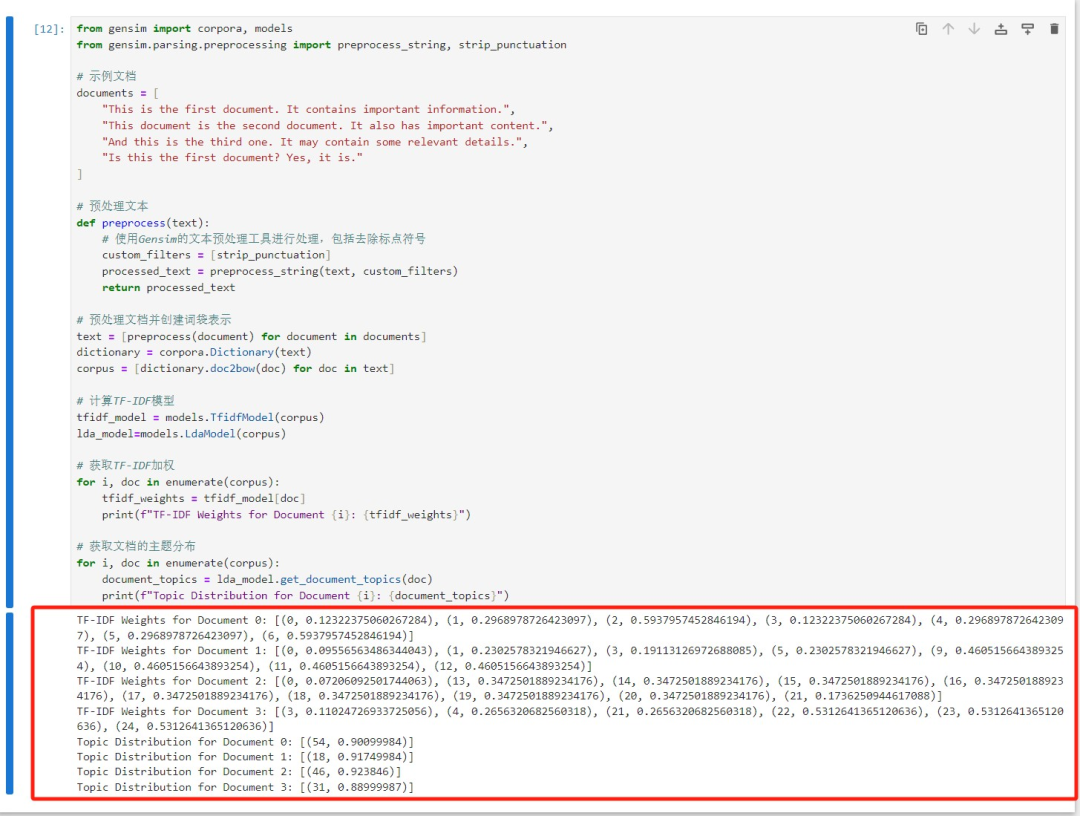
04、Word2Vec 嵌入(词嵌入 Word Embeddings)
gensim支持训练和使用 Word2Vec 模型,以将单词映射到低维向量空间。Word2Vec是一种词嵌入技术,它可以捕捉单词之间的语义关系,使得词汇可以在向量空间中表示。这对于词义相似度计算、单词聚类和其他自然语言处理任务非常有用,代码如下:
from gensim.models import Word2Vec
# 示例文本数据
sentences = [
["this", "is", "a", "sample", "sentence"],
["word2vec", "is", "used", "to", "create", "word", "embeddings"],
["it", "maps", "words", "to", "low-dimensional", "vectors"],
["these", "vectors", "capture", "semantic", "meaning", "of", "words"],
]
# 训练Word2Vec模型
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, sg=0)
# 保存模型
model.save("word2vec.model")
# 加载模型
model = Word2Vec.load("word2vec.model")
# 获取单词的向量表示
word_vector = model.wv["word2vec"]
print("Vector representation for 'word2vec':", word_vector)
# 查找与单词最相似的单词
similar_words = model.wv.most_similar("word2vec", topn=3)
print("Most similar words to 'word2vec':", similar_words)
最终结果如下:
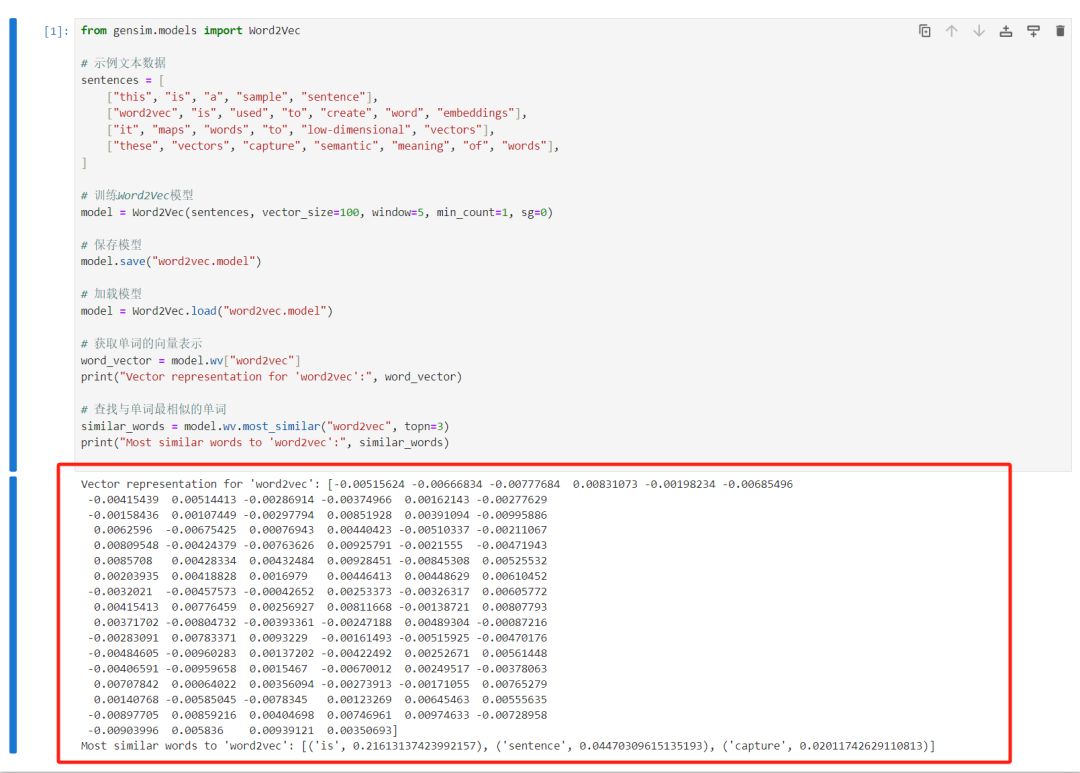
05、FastText 嵌入(子词嵌入 Subword Embeddings)
Gensim支持 FastText 模型,这是一个基于子词的嵌入模型,可以捕获单词的内部结构和形态,FastText在许多自然语言处理任务中表现出色,尤其在处理具有丰富形态变化的语言时非常有用,代码如下:
from gensim.models.fasttext import FastText
# 示例文本数据
sentences = [
["this", "is", "a", "sample", "sentence"],
["fasttext", "is", "used", "to", "capture", "word", "subword", "embeddings"],
["it", "can", "handle", "morphological", "variations", "in", "words"],
["fasttext", "embeddings", "are", "useful", "for", "NLP", "tasks"],
]
# 训练FastText模型
model = FastText(sentences, vector_size=100, window=5, min_count=1, sg=0)
# 保存模型
model.save("fasttext.model")
# 加载模型
model = FastText.load("fasttext.model")
# 获取单词的向量表示
word_vector = model.wv["fasttext"]
print("Vector representation for 'fasttext':", word_vector)
# 查找与单词最相似的单词
similar_words = model.wv.most_similar("fasttext", topn=3)
print("Most similar words to 'fasttext':", similar_words)
最终结果如下:

06、文档向量化
使用Gensim将文档表示为词袋模型和TF-IDF向量,从而将文档转化为数值表示形式,以便用于文本分类、文本检索和文本聚类等任务代码如下:
from gensim import corpora
# 示例文档
documents = [
"This is the first document. It contains important information.",
"This document is the second document. It also has important content.",
"And this is the third one. It may contain some relevant details.",
"Is this the first document? Yes, it is.",
]
# 预处理文本并创建词袋表示
text = [document.split() for document in documents]
dictionary = corpora.Dictionary(text)
corpus = [dictionary.doc2bow(doc) for doc in text]
# 文档向量表示
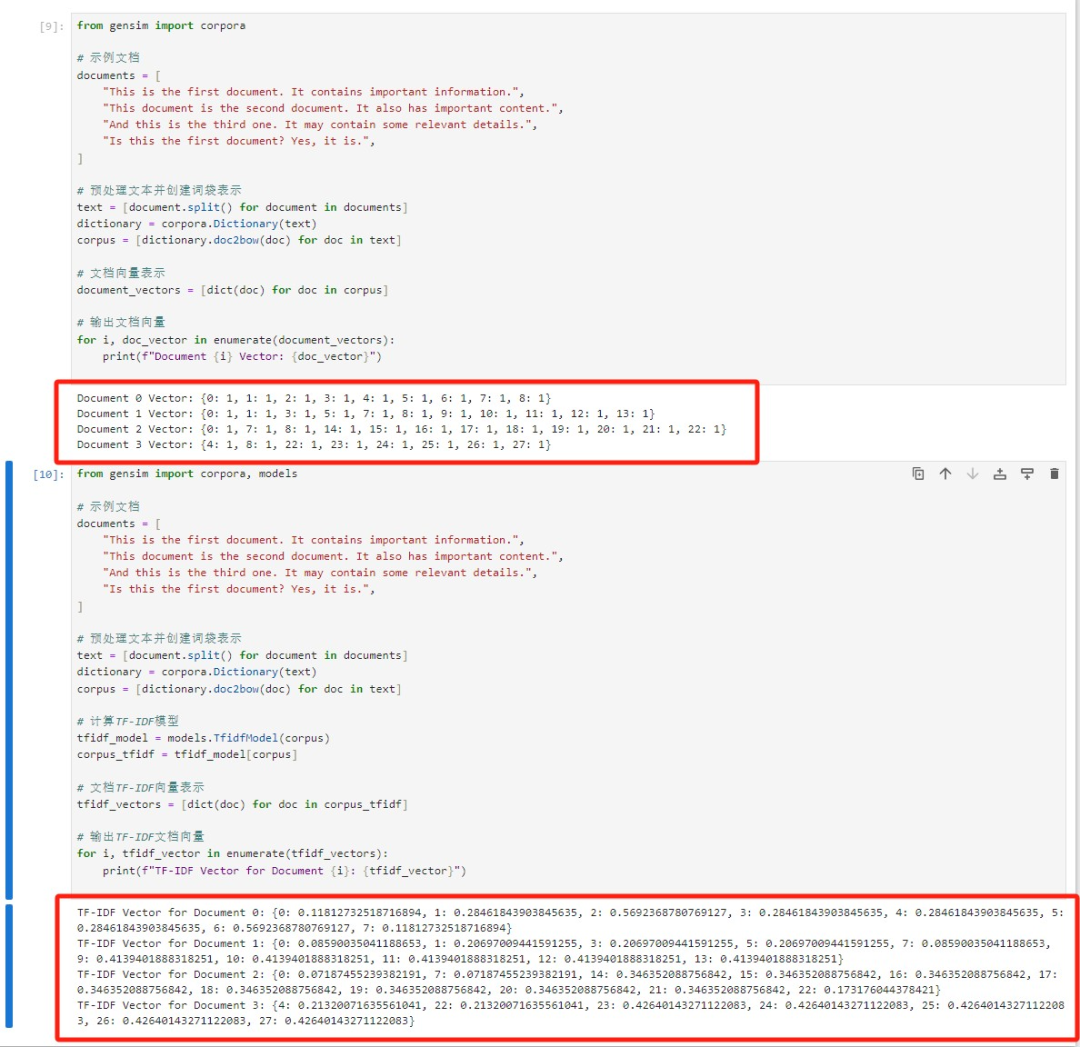
document_vectors = [dict(doc) for doc in corpus]
# 输出文档向量
for i, doc_vector in enumerate(document_vectors):
print(f"Document {i} Vector: {doc_vector}")
from gensim import corpora, models
# 示例文档
documents = [
"This is the first document. It contains important information.",
"This document is the second document. It also has important content.",
"And this is the third one. It may contain some relevant details.",
"Is this the first document? Yes, it is.",
]
# 预处理文本并创建词袋表示
text = [document.split() for document in documents]
dictionary = corpora.Dictionary(text)
corpus = [dictionary.doc2bow(doc) for doc in text]
# 计算TF-IDF模型
tfidf_model = models.TfidfModel(corpus)
corpus_tfidf = tfidf_model[corpus]
# 文档TF-IDF向量表示
tfidf_vectors = [dict(doc) for doc in corpus_tfidf]
# 输出TF-IDF文档向量
for i, tfidf_vector in enumerate(tfidf_vectors):
print(f"TF-IDF Vector for Document {i}: {tfidf_vector}")
最终结果如下:
以上就是本文对Gensim库文本分析的 方法介绍,希望能够帮助大家处理解决文本分析问题,感兴趣的小伙伴可以亲自去试试!
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
若有侵权,请联系删除
智能推荐
python宝典 宋强 pdf_Python宝典/宝典丛书:杨佩璐//宋强 : 电子电脑 :计算机技术 :程序与语言 ...-程序员宅基地
文章浏览阅读279次。导语《Python宝典》由杨佩璐、宋强等编著,本书内容共分三篇26章,分别为入门篇、高级篇和案例篇,针对Python的常用扩展模块给出了详细的语法介绍,并且给出了典型案例,通过对本书的学习,读者能够很快地使用Python进行编程开发。本书以PVthon 3.x为基础进行讲解,并在与Python 2.x有区别的地方加上了相关介绍,使Pvthon 2.x和Pvthon 3.x的读者都能使用本书。内容提..._python宝典杨佩璐
js对象遍历输出的时候真的是按照顺序输出吗?_map循环遍历对象数据是顺序的吗-程序员宅基地
文章浏览阅读1.3w次。js对象遍历输出的时候真的是按照顺序输出吗? 下边就来实践一下:var obj={'3':'ccc',name:'abc',age:23,school:'sdfds',class:'dfd',hobby:'dsfd'};Object.keys(obj)输出:["3", "name", "age", "school", "class", "hobby"];换一下对象顺序,var obj=_map循环遍历对象数据是顺序的吗
HDU--4305(生成树计数)-程序员宅基地
文章浏览阅读176次。2015-09-0722:23:26【传送门】题意:平面上300个点,如果两点之间距离<=R,且两点形成的线段上没有另外的点,那么两点之间有一条无向边。问生成树的方案数。思路:暴力n^2建图,关于判断两点形成线段上是否有其他点,比如判断 k 点知否在 i ,j 之间,首先看斜率是否相等,不能直接求斜率,而应该转化为乘式;再判断 dis(i,k)+dis(k,j)是否等..._hdu4305
阿里云OSS请求文件跨域问题Access-Control-Allow-Origin_oss预签名url access-control-allow-origin-程序员宅基地
文章浏览阅读2.2k次。跨域问题网上很多解决方案提示到这里配置但是不生效,一定要勾选Vary:Origin这个选项,请求的时候浏览器记得请求在控制台要清理缓存。_oss预签名url access-control-allow-origin
OpenCV - C++ - cv::setWindowProperty-程序员宅基地
文章浏览阅读4k次,点赞2次,收藏2次。OpenCV - C++ - cv::setWindowPropertyHigh-level GUI#include <opencv2/highgui.hpp>1. setWindowProperty()void cv::setWindowProperty(const String &winname, int prop_id, double prop_value) - C++None = cv.setWindowProperty(winname, prop_id, prop__setwindowproperty
Qt Creator 4.13中的CMake项目配置_qt cmake configuration-程序员宅基地
文章浏览阅读5.1k次,点赞3次,收藏4次。在Qt Creator中配置中型到大型CMake项目可能是一个挑战。这是因为您需要给CMake传递正确配置项目的选项太多了。让我们以Qt Creator的CMake为例。不同于qmake构建,CMake构建可配置你想要构建的插件。_qt cmake configuration
随便推点
程序员,30岁,还没有做管理层?你应该看看这篇文章_33岁一直做it,还没到管理层-程序员宅基地
文章浏览阅读1k次。如果你30岁,你是一名程序员,那么你就要好好把握接下来的黄金5年。_33岁一直做it,还没到管理层
AMOS分析技术:二阶验证性因子分析-程序员宅基地
文章浏览阅读4.8w次,点赞5次,收藏90次。基础准备草堂君在前面介绍了验证性因子分析的内容,包括验证性因子分析与探索性因子分析的区别联系,斜交验证性因子分析和正交验证性因子分析,可以点击下方文章链接回顾:AMOS分析技术:验证性因子分析介绍;信度与效度指标详解AMOS分析技术:斜交验证性因子分析;介绍如何整理出能够放入论文的模型信效度结果AMOS分析技术:正交验证性因子分析;模型拟合质量好,模型就一定好吗?今天草堂君要介绍的是二阶验证性因子_二阶验证性因子分析
读jQuery之二十(Deferred对象)-程序员宅基地
文章浏览阅读55次。为什么80%的码农都做不了架构师?>>> ...
C++代码实现Top-K问题最优解决办法_c++用优先队列解决topk-程序员宅基地
文章浏览阅读1.6k次。Top-K问题Top-K问题1、问题描述2、解法思想和实现Top-K问题1、问题描述Top-K问题是一个十分经典的问题,一般有以下两种方式来描述问题:在10亿的数字里,找出其中最大的100个数;或者在一个包含n个整数的数组中,找出最大的100个数。前边两种问题描述稍有区别,但都是说的Top-K问题,前一种描述方式是说这里也许没有足够的空间存储大量的数字或其他东西,我们最好可以在一边输入数据,一边求出结果,而不需要存储数据;后一种说法则表示可以存储数据,这种情况下,最简单直观的想法就是对数组进行排序,_c++用优先队列解决topk
怎么用matlab剔除数据的异常值(3σ准则)_3sigma原则matlab-程序员宅基地
文章浏览阅读5.2w次,点赞27次,收藏379次。参考:https://blog.csdn.net/weixin_30633405/article/details/951770093σ准则又称为拉依达准则,它是先假设一组检测数据只含有随机误差,对其进行计算处理得到标准偏差,按一定概率确定一个区间,认为凡超过这个区间的误差,就不属于随机误差而是粗大误差,含有该误差的数据应予以剔除。且3σ适用于有较多组数据的时候。这种判别处理原理及方法仅局限于对正态或近似正态分布的样本数据处理,它是以测量次数充分大为前提的,当测量次数较少的情形用准则剔除粗大误_3sigma原则matlab
导入PYQT5不能使用的坑_pdroid3已经导入pyqt5怎么不管用-程序员宅基地
文章浏览阅读5.1k次,点赞4次,收藏17次。如图:import进来之后里面的类全都不能用是因为这个引用路径下面有中文。改成英文的就不报错了,如果还是报错,那就新建一个项目命名成英文_pdroid3已经导入pyqt5怎么不管用