深度学习之快速实现数据集增强的方法-程序员宅基地
技术标签: python 计算机视觉 深度学习 人工智能 Python OpenCv 数据库
我们在深度学习训练之前准备数据集的时候,特别是打标注的数据集,需要耗费大量的人力物力打标签,在打完的基础我们还可以直接对数据集进行二次增强,即数据集增强。
一、常用的数据集增强方法
常用的数据增强方法有:
1.平移(Shift)变换:对原始图片在图像平面内以某种方式(预先定义或者随机方式确定平移的步长、范围及其方向)进行平移。
2.翻转(Flip)变换:沿竖直或者水平方向对原始图片进行翻转。
3.随机裁剪(Random Crop):随机定义感兴趣区域以裁剪图像,相当于增加随机扰动。
4.噪声扰动(Noise):对图像随机添加高斯噪声或者椒盐噪声等。
5.对比度变换(Contrast):改变图像对比度,相当于在HSV空间中,保持色调分量H不变,而改变亮度分量V和饱和度S,用于模拟现实环境的光照变化。
6.缩放变换(Zoom):以设定的比例缩小或者放大图像。
7.尺度变换(Scale):与缩放变换有点类似,不过尺度变换的对象是图像内容而非图像本身(可以参考SIFT特征提取方法),构建图像金字塔以得到不同大小、模糊程度的图像。
二、使用代码的五个修改点
以上这些方法可以用一段代码快速的实现增强,在代码中只需要改变五个地方就可直接使用,都在main函数里面:
(1)IMG_DIR :原始数据集图片的文件夹路径
(2)XML_DIR: 原始xml文件的文件夹路径
(3)AUG_XML_DIR :数据增强后的图片保存路径
(4)AUG_IMG_DIR:数据增强后的xml文件的保存路径
(5)AUGLOOP :每张图片增强多少次(我自己设的是5)
代码中的具体修改位置见下:
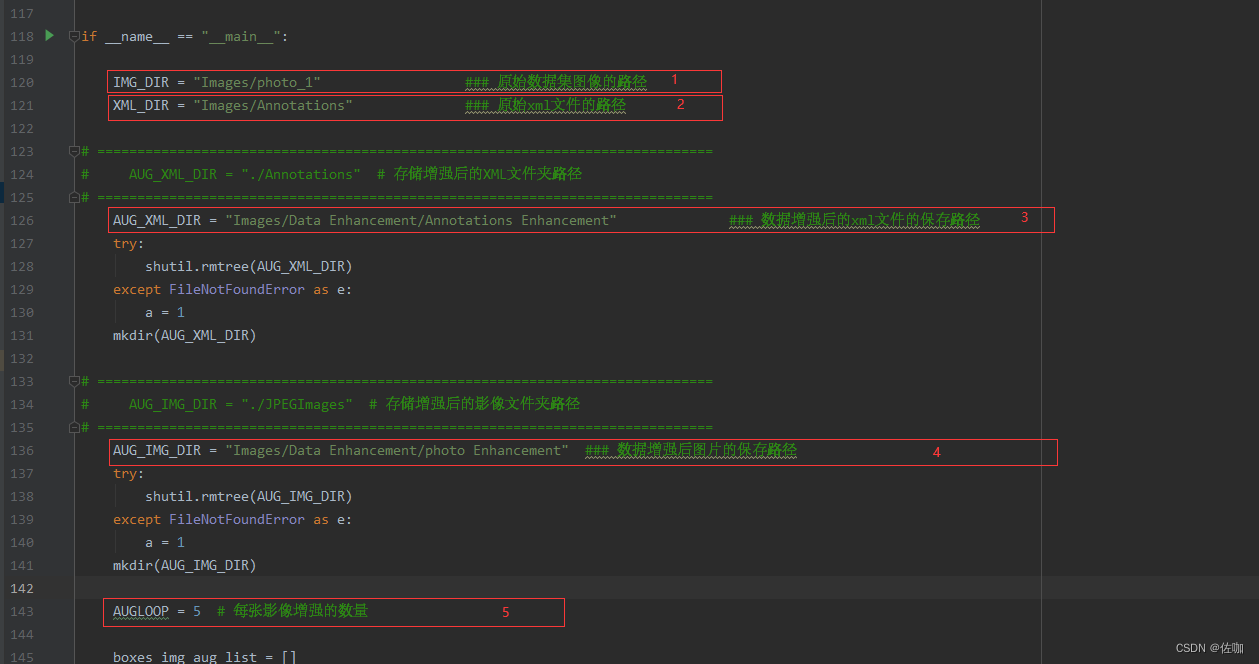
注:使用前需要先确认原始的图片和xml文件夹内的文件是不是一 一对应的,比如图片文件夹有一张abc.jpg,则xml文件夹一定有一个abc.xml文件。我这里提供的教程主要是用来增强VOC格式的数据集。
三、代码
具体代码见下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import getcwd
import numpy as np
from PIL import Image
import shutil
import matplotlib.pyplot as plt
import imgaug as ia
from imgaug import augmenters as iaa
ia.seed(1)
def read_xml_annotation(root, image_id):
in_file = open(os.path.join(root, image_id))
tree = ET.parse(in_file)
root = tree.getroot()
bndboxlist = []
for object in root.findall('object'): # 找到root节点下的所有country节点
bndbox = object.find('bndbox') # 子节点下节点rank的值
xmin = int(bndbox.find('xmin').text)
xmax = int(bndbox.find('xmax').text)
ymin = int(bndbox.find('ymin').text)
ymax = int(bndbox.find('ymax').text)
# print(xmin,ymin,xmax,ymax)
bndboxlist.append([xmin, ymin, xmax, ymax])
# print(bndboxlist)
bndbox = root.find('object').find('bndbox')
return bndboxlist
# (506.0000, 330.0000, 528.0000, 348.0000) -> (520.4747, 381.5080, 540.5596, 398.6603)
def change_xml_annotation(root, image_id, new_target):
new_xmin = new_target[0]
new_ymin = new_target[1]
new_xmax = new_target[2]
new_ymax = new_target[3]
in_file = open(os.path.join(root, str(image_id) + '.xml')) # 这里root分别由两个意思
tree = ET.parse(in_file)
xmlroot = tree.getroot()
object = xmlroot.find('object')
bndbox = object.find('bndbox')
xmin = bndbox.find('xmin')
xmin.text = str(new_xmin)
ymin = bndbox.find('ymin')
ymin.text = str(new_ymin)
xmax = bndbox.find('xmax')
xmax.text = str(new_xmax)
ymax = bndbox.find('ymax')
ymax.text = str(new_ymax)
tree.write(os.path.join(root, str("%06d" % (str(id) + '.xml'))))
def change_xml_list_annotation(root, image_id, new_target, saveroot, id,img_name):
in_file = open(os.path.join(root, str(image_id) + '.xml')) # 这里root分别由两个意思
tree = ET.parse(in_file)
elem = tree.find('filename')
elem.text = (img_name + str("_%06d" % int(id)) + '.jpg')
xmlroot = tree.getroot()
index = 0
for object in xmlroot.findall('object'): # 找到root节点下的所有country节点
bndbox = object.find('bndbox') # 子节点下节点rank的值
# xmin = int(bndbox.find('xmin').text)
# xmax = int(bndbox.find('xmax').text)
# ymin = int(bndbox.find('ymin').text)
# ymax = int(bndbox.find('ymax').text)
new_xmin = new_target[index][0]
new_ymin = new_target[index][1]
new_xmax = new_target[index][2]
new_ymax = new_target[index][3]
xmin = bndbox.find('xmin')
xmin.text = str(new_xmin)
ymin = bndbox.find('ymin')
ymin.text = str(new_ymin)
xmax = bndbox.find('xmax')
xmax.text = str(new_xmax)
ymax = bndbox.find('ymax')
ymax.text = str(new_ymax)
index = index + 1
tree.write(os.path.join(saveroot, img_name + str("_%06d" % int(id)) + '.xml'))
def mkdir(path):
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
if __name__ == "__main__":
IMG_DIR = "Images/photo_1" ### 原始数据集图像的路径
XML_DIR = "Images/Annotations" ### 原始xml文件的路径
# =============================================================================
# AUG_XML_DIR = "./Annotations" # 存储增强后的XML文件夹路径
# =============================================================================
AUG_XML_DIR = "Images/Data Enhancement/Annotations Enhancement" ### 数据增强后的xml文件的保存路径
try:
shutil.rmtree(AUG_XML_DIR)
except FileNotFoundError as e:
a = 1
mkdir(AUG_XML_DIR)
# =============================================================================
# AUG_IMG_DIR = "./JPEGImages" # 存储增强后的影像文件夹路径
# =============================================================================
AUG_IMG_DIR = "Images/Data Enhancement/photo Enhancement" ### 数据增强后图片的保存路径
try:
shutil.rmtree(AUG_IMG_DIR)
except FileNotFoundError as e:
a = 1
mkdir(AUG_IMG_DIR)
AUGLOOP = 5 # 每张影像增强的数量
boxes_img_aug_list = []
new_bndbox = []
new_bndbox_list = []
# 影像增强
seq = iaa.Sequential([
iaa.Flipud(0.5), # vertically flip 20% of all images
iaa.Fliplr(0.5), # 镜像
iaa.Multiply((1.2, 1.5)), # change brightness, doesn't affect BBs
iaa.GaussianBlur(sigma=(0, 3.0)), # iaa.GaussianBlur(0.5),
iaa.Affine(
translate_px={
"x": 15, "y": 15},
scale=(0.8, 0.95),
rotate=(-30, 30)
) # translate by 40/60px on x/y axis, and scale to 50-70%, affects BBs
])
for root, sub_folders, files in os.walk(XML_DIR):
for name in files:
print(name)
bndbox = read_xml_annotation(XML_DIR, name)
shutil.copy(os.path.join(XML_DIR, name), AUG_XML_DIR)
shutil.copy(os.path.join(IMG_DIR, name[:-4] + '.jpg'), AUG_IMG_DIR)
for epoch in range(AUGLOOP):
seq_det = seq.to_deterministic() # 保持坐标和图像同步改变,而不是随机
# 读取图片
img = Image.open(os.path.join(IMG_DIR, name[:-4] + '.jpg'))
# sp = img.size
img = np.asarray(img)
# bndbox 坐标增强
for i in range(len(bndbox)):
bbs = ia.BoundingBoxesOnImage([
ia.BoundingBox(x1=bndbox[i][0], y1=bndbox[i][1], x2=bndbox[i][2], y2=bndbox[i][3]),
], shape=img.shape)
bbs_aug = seq_det.augment_bounding_boxes([bbs])[0]
boxes_img_aug_list.append(bbs_aug)
# new_bndbox_list:[[x1,y1,x2,y2],...[],[]]
n_x1 = int(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x1)))
n_y1 = int(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y1)))
n_x2 = int(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x2)))
n_y2 = int(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y2)))
if n_x1 == 1 and n_x1 == n_x2:
n_x2 += 1
if n_y1 == 1 and n_y2 == n_y1:
n_y2 += 1
if n_x1 >= n_x2 or n_y1 >= n_y2:
print('error', name)
new_bndbox_list.append([n_x1, n_y1, n_x2, n_y2])
# 存储变化后的图片
image_aug = seq_det.augment_images([img])[0]
path = os.path.join(AUG_IMG_DIR,
name[:-4] + str( "_%06d" % (epoch + 1)) + '.jpg')
image_auged = bbs.draw_on_image(image_aug, thickness=0)
Image.fromarray(image_auged).save(path)
# 存储变化后的XML
change_xml_list_annotation(XML_DIR, name[:-4], new_bndbox_list, AUG_XML_DIR,
epoch + 1,name[:-4])
print( name[:-4] + str( "_%06d" % (epoch + 1)) + '.jpg')
new_bndbox_list = []
四、增强后与原始数据集对比
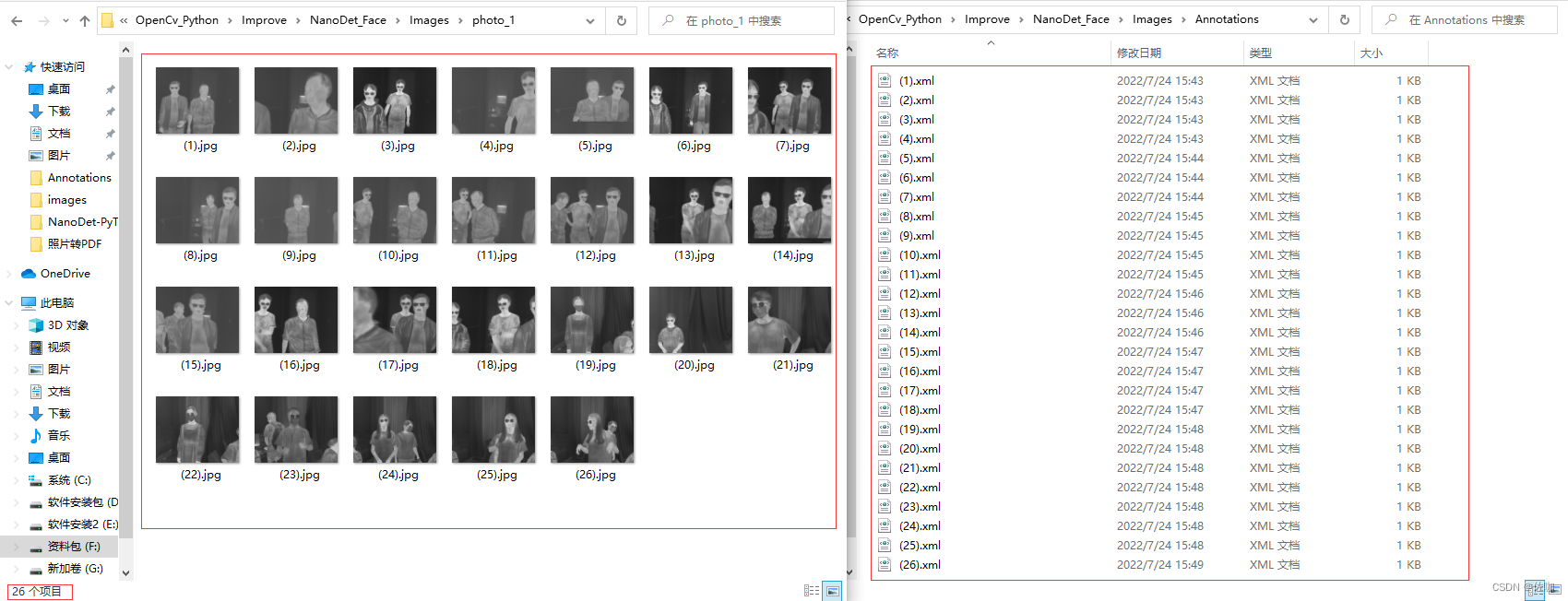
1、原始数据集
原始的数据集和原始对应的xml文件,原始的数据集中有26张图像:
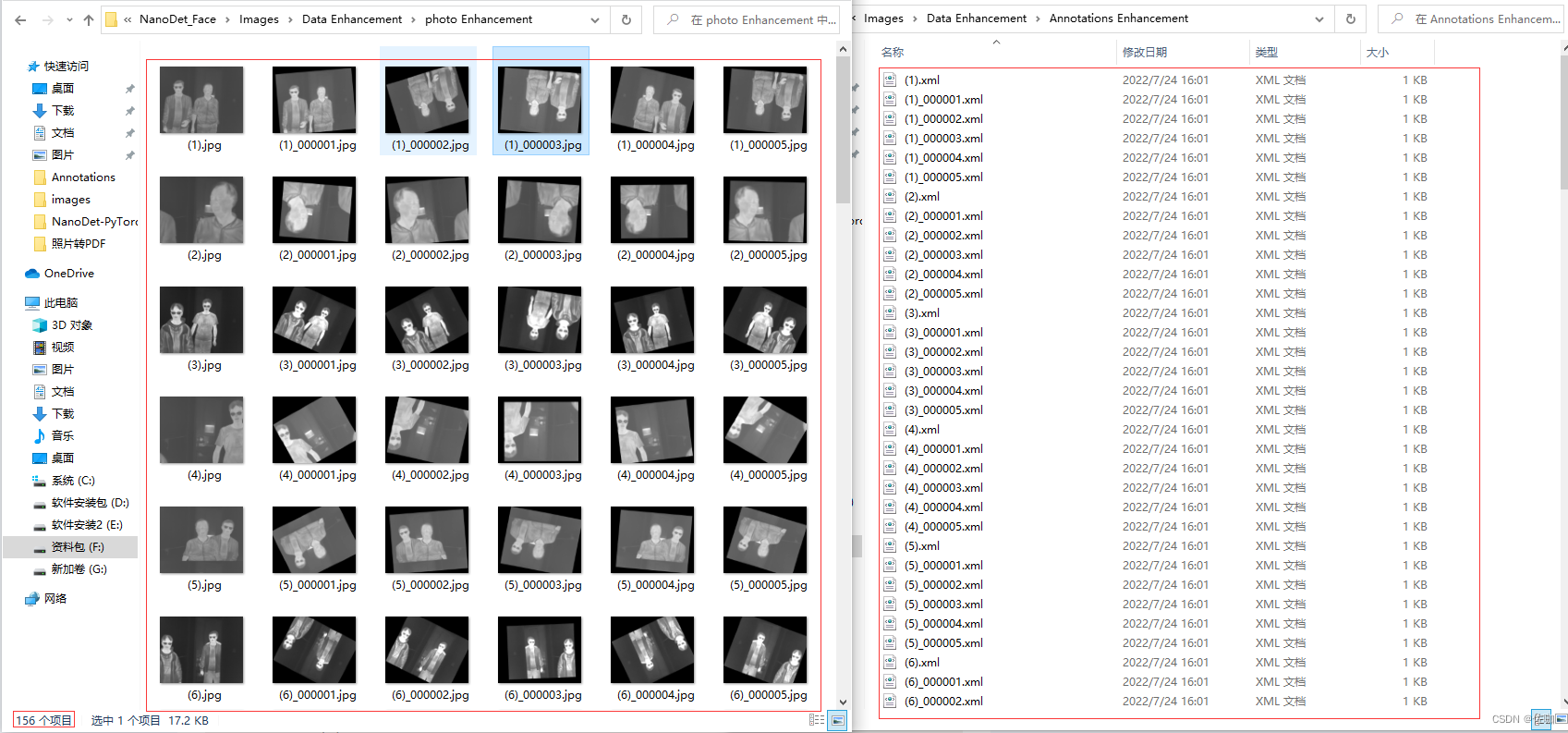
2、增强后数据集
数据增强后的数据集和数据集增强后的xml文件,增强后的图片有156张,对应的xml文件有156个:
以上就是深度学习之VOC格式数据集实现数据集增强的方法,希望此方法能帮助到你,多多支持,谢谢。
智能推荐
艾美捷Epigentek DNA样品的超声能量处理方案-程序员宅基地
文章浏览阅读15次。空化气泡的大小和相应的空化能量可以通过调整完全标度的振幅水平来操纵和数字控制。通过强调超声技术中的更高通量处理和防止样品污染,Epigentek EpiSonic超声仪可以轻松集成到现有的实验室工作流程中,并且特别适合与表观遗传学和下一代应用的兼容性。Epigentek的EpiSonic已成为一种有效的剪切设备,用于在染色质免疫沉淀技术中制备染色质样品,以及用于下一代测序平台的DNA文库制备。该装置的经济性及其多重样品的能力使其成为每个实验室拥有的经济高效的工具,而不仅仅是核心设施。
11、合宙Air模块Luat开发:通过http协议获取天气信息_合宙获取天气-程序员宅基地
文章浏览阅读4.2k次,点赞3次,收藏14次。目录点击这里查看所有博文 本系列博客,理论上适用于合宙的Air202、Air268、Air720x、Air720S以及最近发布的Air720U(我还没拿到样机,应该也能支持)。 先不管支不支持,如果你用的是合宙的模块,那都不妨一试,也许会有意外收获。 我使用的是Air720SL模块,如果在其他模块上不能用,那就是底层core固件暂时还没有支持,这里的代码是没有问题的。例程仅供参考!..._合宙获取天气
EasyMesh和802.11s对比-程序员宅基地
文章浏览阅读7.7k次,点赞2次,收藏41次。1 关于meshMesh的意思是网状物,以前读书的时候,在自动化领域有传感器自组网,zigbee、蓝牙等无线方式实现各个网络节点消息通信,通过各种算法,保证整个网络中所有节点信息能经过多跳最终传递到目的地,用于数据采集。十多年过去了,在无线路由器领域又把这个mesh概念翻炒了一下,各大品牌都推出了mesh路由器,大多数是3个为一组,实现在面积较大的住宅里,增强wifi覆盖范围,智能在多热点之间切换,提升上网体验。因为节点基本上在3个以内,所以mesh的算法不必太复杂,组网形式比较简单。各厂家都自定义了组_802.11s
线程的几种状态_线程状态-程序员宅基地
文章浏览阅读5.2k次,点赞8次,收藏21次。线程的几种状态_线程状态
stack的常见用法详解_stack函数用法-程序员宅基地
文章浏览阅读4.2w次,点赞124次,收藏688次。stack翻译为栈,是STL中实现的一个后进先出的容器。要使用 stack,应先添加头文件include<stack>,并在头文件下面加上“ using namespacestd;"1. stack的定义其定义的写法和其他STL容器相同, typename可以任意基本数据类型或容器:stack<typename> name;2. stack容器内元素的访问..._stack函数用法
2018.11.16javascript课上随笔(DOM)-程序员宅基地
文章浏览阅读71次。<li> <a href = "“#”>-</a></li><li>子节点:文本节点(回车),元素节点,文本节点。不同节点树: 节点(各种类型节点)childNodes:返回子节点的所有子节点的集合,包含任何类型、元素节点(元素类型节点):child。node.getAttribute(at...
随便推点
layui.extend的一点知识 第三方模块base 路径_layui extend-程序员宅基地
文章浏览阅读3.4k次。//config的设置是全局的layui.config({ base: '/res/js/' //假设这是你存放拓展模块的根目录}).extend({ //设定模块别名 mymod: 'mymod' //如果 mymod.js 是在根目录,也可以不用设定别名 ,mod1: 'admin/mod1' //相对于上述 base 目录的子目录}); //你也可以忽略 base 设定的根目录,直接在 extend 指定路径(主要:该功能为 layui 2.2.0 新增)layui.exten_layui extend
5G云计算:5G网络的分层思想_5g分层结构-程序员宅基地
文章浏览阅读3.2k次,点赞6次,收藏13次。分层思想分层思想分层思想-1分层思想-2分层思想-2OSI七层参考模型物理层和数据链路层物理层数据链路层网络层传输层会话层表示层应用层OSI七层模型的分层结构TCP/IP协议族的组成数据封装过程数据解封装过程PDU设备与层的对应关系各层通信分层思想分层思想-1在现实生活种,我们在喝牛奶时,未必了解他的生产过程,我们所接触的或许只是从超时购买牛奶。分层思想-2平时我们在网络时也未必知道数据的传输过程我们的所考虑的就是可以传就可以,不用管他时怎么传输的分层思想-2将复杂的流程分解为几个功能_5g分层结构
基于二值化图像转GCode的单向扫描实现-程序员宅基地
文章浏览阅读191次。在激光雕刻中,单向扫描(Unidirectional Scanning)是一种雕刻技术,其中激光头只在一个方向上移动,而不是来回移动。这种移动方式主要应用于通过激光逐行扫描图像表面的过程。具体而言,单向扫描的过程通常包括以下步骤:横向移动(X轴): 激光头沿X轴方向移动到图像的一侧。纵向移动(Y轴): 激光头沿Y轴方向开始逐行移动,刻蚀图像表面。这一过程是单向的,即在每一行上激光头只在一个方向上移动。返回横向移动: 一旦一行完成,激光头返回到图像的一侧,准备进行下一行的刻蚀。
算法随笔:强连通分量-程序员宅基地
文章浏览阅读577次。强连通:在有向图G中,如果两个点u和v是互相可达的,即从u出发可以到达v,从v出发也可以到达u,则成u和v是强连通的。强连通分量:如果一个有向图G不是强连通图,那么可以把它分成躲个子图,其中每个子图的内部是强连通的,而且这些子图已经扩展到最大,不能与子图外的任一点强连通,成这样的一个“极大连通”子图是G的一个强连通分量(SCC)。强连通分量的一些性质:(1)一个点必须有出度和入度,才会与其他点强连通。(2)把一个SCC从图中挖掉,不影响其他点的强连通性。_强连通分量
Django(2)|templates模板+静态资源目录static_django templates-程序员宅基地
文章浏览阅读3.9k次,点赞5次,收藏18次。在做web开发,要给用户提供一个页面,页面包括静态页面+数据,两者结合起来就是完整的可视化的页面,django的模板系统支持这种功能,首先需要写一个静态页面,然后通过python的模板语法将数据渲染上去。1.创建一个templates目录2.配置。_django templates
linux下的GPU测试软件,Ubuntu等Linux系统显卡性能测试软件 Unigine 3D-程序员宅基地
文章浏览阅读1.7k次。Ubuntu等Linux系统显卡性能测试软件 Unigine 3DUbuntu Intel显卡驱动安装,请参考:ATI和NVIDIA显卡请在软件和更新中的附加驱动中安装。 这里推荐: 运行后,F9就可评分,已测试显卡有K2000 2GB 900+分,GT330m 1GB 340+ 分,GT620 1GB 340+ 分,四代i5核显340+ 分,还有写博客的小盒子100+ 分。relaybot@re...