【检测】Prime Sample Attention in Object Detection-程序员宅基地
技术标签: 目标检测
Prime Sample Attention in Object Detection
作者:CUHK SenseTime Joint Lab, NTU
在目标检测中的一个普遍认知就是应该平等的对待每个sample和目标。这篇文章研究了不同的样本对于最终结果的影响。作者认为在每个minibatch中的样本既不是独立的也不是同样重要的,所以一个平均的结果并不能意味是一个更高的mAP。作者提出了Prime Sample的概念并且提出了PISA的结果,主要关注这些样本的训练过程,实验证明关注prime sample而不是hard sample对于训练来说更加有效。在MSCOCO数据集上,PISA表现的比random sampling和hard mining超过了1个百分点。
现在的目标检测办法主要用的是region-based 方法。因此region sample的选择对于检测结果来说是很重要的,然而很多的sample位于图像的背景区域,音系简单的选择所有sample或者随意选择一些是一种不合理的办法。
已经有一些研究表明主要关注一些困难的sample是一个比较有效的办法。代表的有OHEM(?)和Focal Loss。OHEM主要选择hard samples比如说有着高的loss值。Focal Loss是给loss function换了一种形式来强调difficult samples。
然而,什么才是最重要的sample呢?
这项研究提出了2个需要被重点考虑的方面:
- Sample不应该是独立的或者是相同重要的。本文的研究西安市,应该重点关注了那些和groundtruth有着高iou的samples。
- 分类和定位是相关联的。尤其是,被很好定位的samples需要以高的confidences来分类(?)
文章重点:
- 提出了PISA
- 定义了IoU-HLR
- 加入了classification-aware regression loss
Related Work:
Improvement of NMS with localization confidence
IoU-Net并不是完全用分类结果来做NMS,定位结果也需要。 除了传统算法中的classification和regression分支,它引入了一个其他的分支来预测sample的IoU。并且用这个预测的IoU(localization confident) 来排序所有的sample。本文和IoU-Net的主要不同有:
本文是联系两个分支而不是开发出新一个。
本文的目标不是提升NMS。 而是调查sample的重要性并且重点关注prime samples。
Sampling strategies in object detection
在目标检测中最广泛被采用的sampling scheme是random sampling。因为负样本总是比正样本多很多,所以正样本负样本见一个固定的比例可能会被设置。(?)
还有的想法是选择有着高的loss值的hard samples,但是,hard mining的目的是增加classifier的的表现能力而不是探索检测和分类的差别。
Prime Samples
mAP:
mAP的工作方式反映了对于一个目标检测器来说哪个sample更重要。
所有的bounding boxes中IoU最高的那个被认为是最重要的,并且直接影响了recall。
在对于不同物体的全部最高的IoU的bounding box中,有着最高IoU的那个更加重要
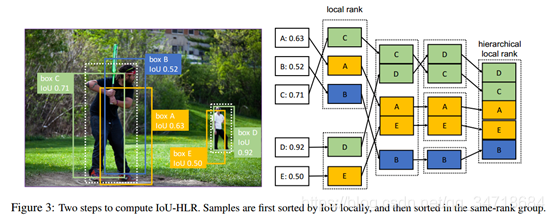
IoU Hierarchical Local Rank (IoU-HLR):
本文提出了IoU-HLR来排序在一个minibatch中sample的重要性, IoU-HLR是基于最终的sample的定位计算的,而不是regression前的bounding box的坐标,因为mAP是基于regressed sample的位置衡量的。
如下图所示,首先将所有的sample根据他们最近的objects分成不同组,然后在每个组中,根据他们的IoU降序排序得到了LoU Local Rank(IoU-LR)。然后所有的top1 LoU-LR被选出来了,然后是top2,3。。。等等。这两步的分类结果会形成在一个batch中所有样本的一个线性的命令,所以称它IoU-HLR。
Learn Detectors via Prime Sample Attention
如果我们只有top IoU-HLR samples进行训练,就像OHEM做的那样,mAP就会下降的很厉害因为大多数prime sample都是很容易训练的所以不能提供足够的梯度来优化classifier(为什么只是classifier?)
所以本文提出了Prime Sample Attention,一个简单有效并且可以更关注于prime samples。 PISA包括2个部分,Importancebased Sample Reweighting (ISR) and Classification Aware
Regression Loss (CARL)。 在PISA的作用下,训练进程更加偏向于prime samples而被平均对待的samples。 首先,prime sample的loss weight比其他的大,所以在这些sample上,classifier往往可以预测出更好的分数(为什么是classifier?)。第二,因为classior和regressor是通过共同的目标进行学习的,所以prime samples的分数和不重要的那些比会增加(??)。
Importance-based Sample Reweighting
在被给相同的classifier的情况下,performance的分布总是于训练样本的分布相匹配的。如果一些sample在训练数据中出现的更频繁,那么在这些sample的分类正确率就会更好(为什么是分类正确率?)hard sampling和soft sampling时改变训练数据分布的两种不同方式。Hard sampling是从所有的候选中选择一些samples来训练一个模型,然而,soft sampling是给所有的samples分配不同的权重(?)。hard可以被看作是soft的一种特殊形式,每个sample都被分配一个是0或1的loss weight(?)。
这篇文章提出了一种soft Sampling 的方法—— Importance-based Sample Reweighting (ISR), 它根据重要程度给samples分配了不同的loss weights
用线性方程可以将r_i转换为u_i,如下所示:u_i代表了class j的第i个sample的重要性值。
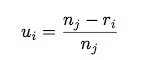
u_i 和w_i存在着一个简单的递增的关系:
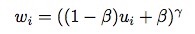
之后,cross entropy classification loss可以被改写为:
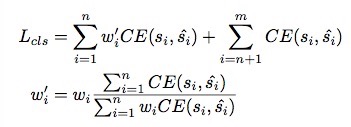
n和m分别是正样本和全部样本的总量。注意到简单的增加loss weights将会改变loss的全部值和正样本负样本之间的比例,所以我们将w_i归一化到 w_i’为了保证全部正样本的loss不变。(w_i为什么不能加到regression loss中?)
Classification-Aware Regression Loss
除了re-weight classification loss 来重点关注prime samples,作者还提出了一个联合优化两个分支通过Classification-Aware Regression Loss (CARL)。CARL可以增加prime sample的分数同时降低其他的分数。Regression的质量确定了sample的重要性,并且我们希望classifier可以输出对于重要sample的更高的分数。两个分支的优化应该是相关的而不是独立的。
解决方法是让regression loss关注到classification score以至于梯度可以从regression反传到classification
p_i代表了预测到相关class的概率,
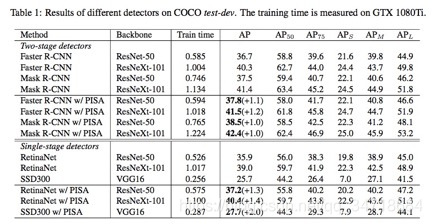
实验:
智能推荐
音频分离Spleeter的安装_2stems.tar.gz-程序员宅基地
文章浏览阅读3.5k次,点赞5次,收藏13次。音频分离Spleeter的安装1.环境依赖及建立(需要已安装anaconda)1.0 项目源地址(github地址)1.1 创建虚拟环境1.2 激活虚拟环境1.3 conda 安装spleeter1.4 下载一个示例音乐1.5 将该音乐分离为两部分1.5.1 报错:No module named numba.decorators1.5.2 解决方案:1.6 下载分类模型1.6.1报错ValueError:Can't load save_path when it is None.1.6.2 解决方案:1.6._2stems.tar.gz
让你的软件飞起来:RGB转为YUV-程序员宅基地
文章浏览阅读64次。朋友曾经给我推荐了一个有关代码优化的pdf文档《让你的软件飞起来》,看完之后,感受颇深。为了推广其,同时也为了自己加深印象,故将其总结为word文档。下面就是其的详细内容总结,希望能于己于人都有所帮助。速度取决于算法同样的事情,方法不一样,效果也不一样。比如,汽车引擎,可以让你的速度超越马车,却无法超越音速;涡轮引擎,可以轻松超越音障,却无法飞出地球;如果有火箭发动机,就可以到达火..._bao.yuv
PX4装机教程(五)无人船(车)_在px4固体中如何设置差速船-程序员宅基地
文章浏览阅读2.5k次,点赞3次,收藏33次。文章目录前言一、载具设置二、电机接线三、PWM输出设置四、航点设置前言一个人可以走的更快,一群人才能走的更远,交流学习加qq:2096723956更多保姆级PX4+ROS学习视频:https://b23.tv/ZeUDKqy分享知识,传递正能量,如有疏漏或不当之处,恳请指出.PX4固件版本:1.10.0硬件:淘宝竞速船或者打窝船实验录屏https://www.bilibili.com/video/BV1wA411c7p3?spm_id_from=333.999.0.0一、载具设置单电机_在px4固体中如何设置差速船
一键批量查询快递单号,一键批量查询,共享备份物流,快递物流尽在掌控_批量快递查询-程序员宅基地
文章浏览阅读370次。每天都有大量的快递单号需要查询,如果一个个手动查询,不仅费时费力,还容易出错。为了解决这个问题,我们教您如何批量查询快递单号,并将快递物流信息进行备份并共享,实现高效管理。弹出一个对话框,文件名和保存类型不变,直接点“保存”,会提示备份成功,那么这个数据库就备份在电脑上了,也可以用第三方工具发送到其他电脑上。第四步,查询速度很快,我们就可以在主页面看到该批单号的运件信息了,比如:发出时间,状态,最后更新的物流时间,等等。第二步,在弹出来的文件框里,将需要查询的德邦快递单号都一一导入,并点击保存。_批量快递查询
敏捷开发(scrum)简介-程序员宅基地
文章浏览阅读7.7k次,点赞6次,收藏61次。敏捷开发(scrum)是一种软件开发的流程,强调快速反应、快速迭代、价值驱动。Scrum的英文意思是橄榄球运动的一个专业术语,表示“争球”的动作;运用该流程,你就能看到你团队高效的工作。一、四大价值观(特点)敏捷开发的特点就是下面4句话:「个体与交互」胜过「过程与工具」「可以工作的软件」胜过「面面俱到的文挡」「客户协作」胜过「合同谈判」「响应变化」胜过「遵循计划」说明:(1)敏捷开发(scrum)适用于竞争激烈,快速变化的市场。 敏捷的客户协作观念,快速迭代能帮助团队以最小成本,最快速_敏捷开发
string.h头文件和strings.h的区别-程序员宅基地
文章浏览阅读3.5k次。首先我们看一下man string 里面的内容:可见,strings 头文件中包含了部分函数,没有在 string.h 中出现的。上图的环境是 macOS Sierra 版本号为:10.12.6包括; index, rindex, strcasecmp, strncasecmp 这四个函数。为了一探这个头文件是不是只有macos 这种 Unix-like 系统中才出现。我在Linu..._strings.h
随便推点
Qt 22 布局管理器1 - QLayout,QBoxLayout,布局管理器的相互嵌套_qt layout可以嵌套layout吗-程序员宅基地
文章浏览阅读464次。布局管理器提供相关的类对界面组件进行布局管理能够自动排布窗口中的界面组件窗口变化后自动更新界面组件的大小QLayoutQLayout 是Qt 中布局管理器的抽象基类通过继承QLayout实现了功能各异且互补的布局管理器Qt中可以根据需要自定义布局管理器布局管理器不是界面部件,而是界面部件的定位策略QBoxLayout 布局管理器以水平或者垂直的方式管理界面组件水平:QHBoxLayout 水平布局管理器垂直:QVBoxLayout 垂直布局管理器sizePolicy:QSize_qt layout可以嵌套layout吗
error MSB6006 rc exe 已退出,代码为 5_vs2010报警 error msb6006: “rc.exe”已退出,代码为 5。-程序员宅基地
文章浏览阅读2.6k次。error MSB6006 rc exe 已退出,代码为 5_vs2010报警 error msb6006: “rc.exe”已退出,代码为 5。
如何用NAS打造私有协同办公系统?-程序员宅基地
文章浏览阅读6.2k次。对于人数不多的小型初创企业、工作室、SOHO人群来说,能够拥有自有的协同办公系统无疑是提高工作效率的好方法,同时将文件放在自己的服务器中,显然会更加安心,不用担心重要内容的泄露问题。因此,大家有没有这样想过,自己动手搭一套私有的、云端化的协同办公系统,搞定文件异地同步的同时,实现云端化的办公软件,并提升数据安全性。理想虽好,不过要亲手搞定这样的协同办公系统一定很困难吧?如果你真这样
假设你们的社团要精选社长,有两名候选人分别是A和B,社团每名同学必须并且只能投一票,最终的票多的人为社长。-程序员宅基地
文章浏览阅读33次。输出描述:一行,一个字符,A或B或E,输出A表示A得票数多,输出B表示B得票数多,输出E表示二人得票数相等。输入描述:一行,字符序列,包含A或B,输入以字符0结束。
BeanFactory和ApplicationContext有什么区别?_beanfactory和applicationcontext是干什么的-程序员宅基地
文章浏览阅读2.2k次,点赞2次,收藏2次。BeanFactory和ApplicationContext有什么区别? BeanFactory和ApplicationContext是Spring的两大核心接口,都可以当做Spring的容器。其中ApplicationContext是BeanFactory的子接口。(1)BeanFactory:是Spring里面最底层的接口,包含了各种Bean的定义,读取bean配置文档,管理..._beanfactory和applicationcontext是干什么的
java 项目管理 maven2.0学习笔记 _apt fml fr-程序员宅基地
文章浏览阅读4.5k次。转贴:http://blog.csdn.net/shiqiang1234/archive/2006/10/12/1331725.aspxMaven简介Maven最初的目的是在Jakarta Turbine项目中使构建处理简单化。几个项目之间使用到的Ant build文件差异很小,各个JAR都存入CVS。因此希望有一个标准的方法构建各个工程,清晰的定义一个工程的组成,一个容易的方法去发布项目_apt fml fr