Kafka消息中间件(一)_kafka 9095-程序员宅基地
技术标签: 开发
Kafka消息中间件
- Kafka消息组件简介
Kafka可以说是现在所有开源消息组件之中性能最高的产品,但是同时也需要认识到一个问题:Kafka是一项不断继续发展的技术,所以来说对于其的稳定性永远无法评估。Kafka官网地址:
http://kafka.apache.org/
Kafka是分布式发布-订阅消息系统(主题)。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。阿里也有RabbitMQ消息组件。两者本质一样,但kafka在性能上占优势。
对于分布式消息系统主要有两种,一种是主题,一种是队列.
Kafka是一个分布式的,可划分的,冗余备份的持久性日志服务。它主要用于处理活跃的流式数据。

什么是消息组件:
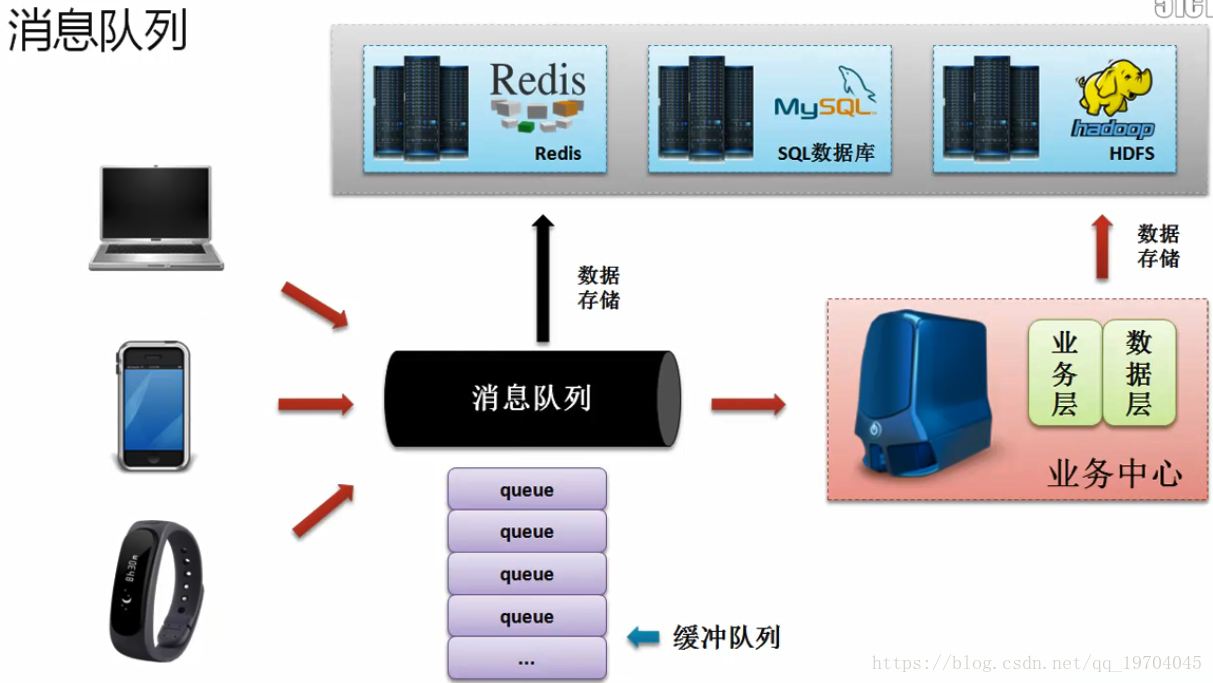
当各个设备发送的消息过多的时候,那么一定会引起数据量的暴涨,如果直接将这些消息交给处理程序,那么处理程序将无法正确处理,将导致消息数据的丢失,所以使用消息队列有一个最大的功能就是进行数据的缓冲操作。
而消息队列有两种处理消息的方式:一种是:直接将消息处理而后保存到持久化设备之中;(由于处理会造成处理速度变慢);第二种方式是利用其他的处理程序,例如:Strom进行消息的处理。
如果要说到消息队列,那么首先自然能够想到的就是JMS(JMS属于java消息服务,这就是javay原生的操作协议),其中JMS实现的代表性的开源的项目(ActiveMQ)–这种组件由于跨越的时间太长了,实际上已经不适合当前高并发的项目使用。

JMS支持多种类型,但是好比第七层实现的协议。需要去实现。
AMQP有两大著名的实现框架:Kafka、RabbitMQ
AMQP是一种协议,更准确的说是一种链接协议
AMQP不从API层进行限定,而是直接定义网络交换的数据格式,这使得AMQP的provider天然就是跨平台的。直接基于网络做的,不像JMS是基于数据接收到的处理来做的。–这是性能高的原因。
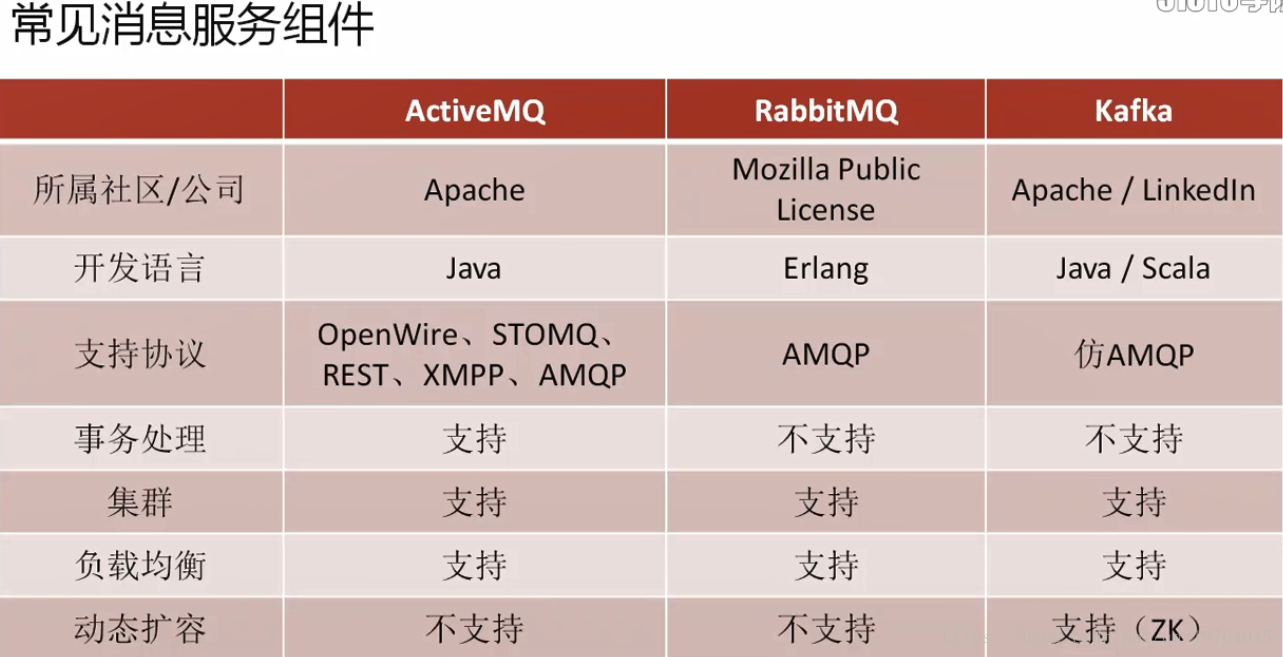
Kafka支持动态扩容(zookeeper组件支持)
AMQP是一种不受程序限制的传输的处理协议,而JMS受到程序限制。所以AMQP它的性能和适应性会更高,但是kafka作为AMQP的实现有一个最重要的特征:
RabbitMQ、ActiveMQ有一个最大的特点:消息消费完成消息就删除。
kafka特点:所有的消息会自动保存两天的时间。
- Kafka工作原理
Kafka是一款性能很高的消息组件,但是不管如何改变,对于消息组件本身其最基础的组成部分:
消息的生产者:负责进行消息信息的推送,推送给指定的服务器
消息的消费者:负责通过服务器获取消息的内容
消息服务中间件(服务器):负责消息的存储,也就是当消费者来不及处理完全部消息的时候,可以在消息中间件之中进行消息内容的缓冲,所以消息中间件也往往被称为消息队列中间件;
影响整个程序运行的关键性因素:程序的设计要合理,CPU处理速度快,内存要大,缓存大、磁盘转速要快(磁盘的寻址是成为性能最大的瓶颈),对于消息组件最快的做法就是网络传输也要快。而Kafka设计里面将所有可能影响到程序性能的部分全部考虑到了。
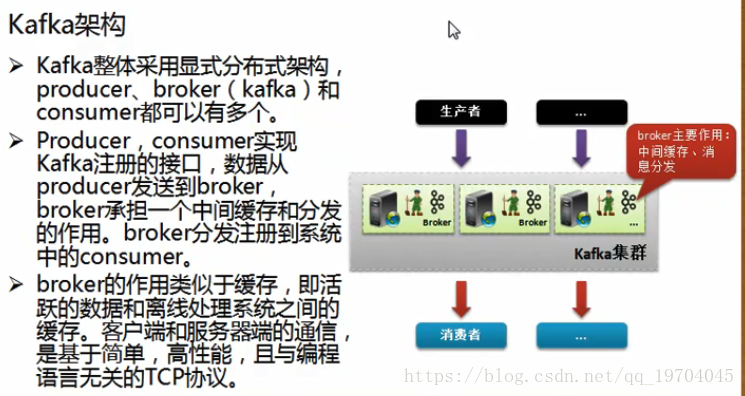
Kafka是基于zookeeper设计,所以对于Kafka的集群来讲实现就相对容易许多,同时Zookeeper可以保存所有集群主机的信息内容,也就是说在配置Kafka之前一定要首先进行zookeeper的配置。
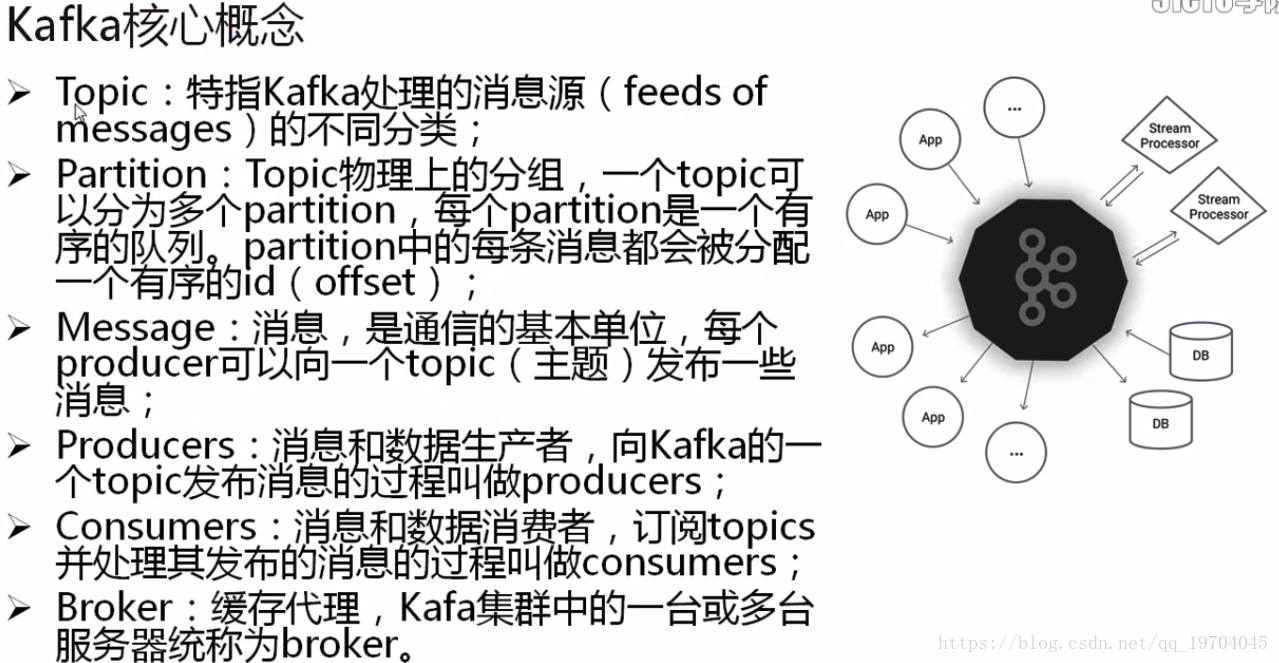
如果要想进行消息的处理,所有的消息组件都一定会提供有一个消息主题,所有的消息的生产者根据主题将自己的消息发送并且保存到服务器之中,而消费者也可以通过指定的主题获取消息的内容。这样就可以传递多种消息。
Partition:指的是分区:如果你现在配置的主机只是单核CPU,那么你能够进行的合理的分区划分只能够有一个分区,但是如果你CPU的核心数可能有16个,那么你这台服务器上可以进行的分区操作就可以划分出16个分区,在每一台服务器上可以有多个分区,而分区划分最简单的依据:根据你cpu的性能来决定
当然并不是说一核CPU无法进行多分区的配置,只不过要想发挥出最好的性能,那么一定要使用多核CPU再设置多个分区操作。(多个分区共享一个CPU,会出现轮询算法等,会有性能的瓶颈)
Message:消息,是通信的基本单位,每个producer可以向一个topic发布一些消息。
Producers:消息和数据产生者,向Kafka的一个topic发布消息的过程叫做producers
Consumers:消息和数据消费者,订阅topics并处理其发布的消息的过程叫做consumers
Borker:缓存代理,Kafka集群中的一台或多台服务器统称为Broker
在整个Kafka集群里面,所有的分区数量= 主机CPU内核数量
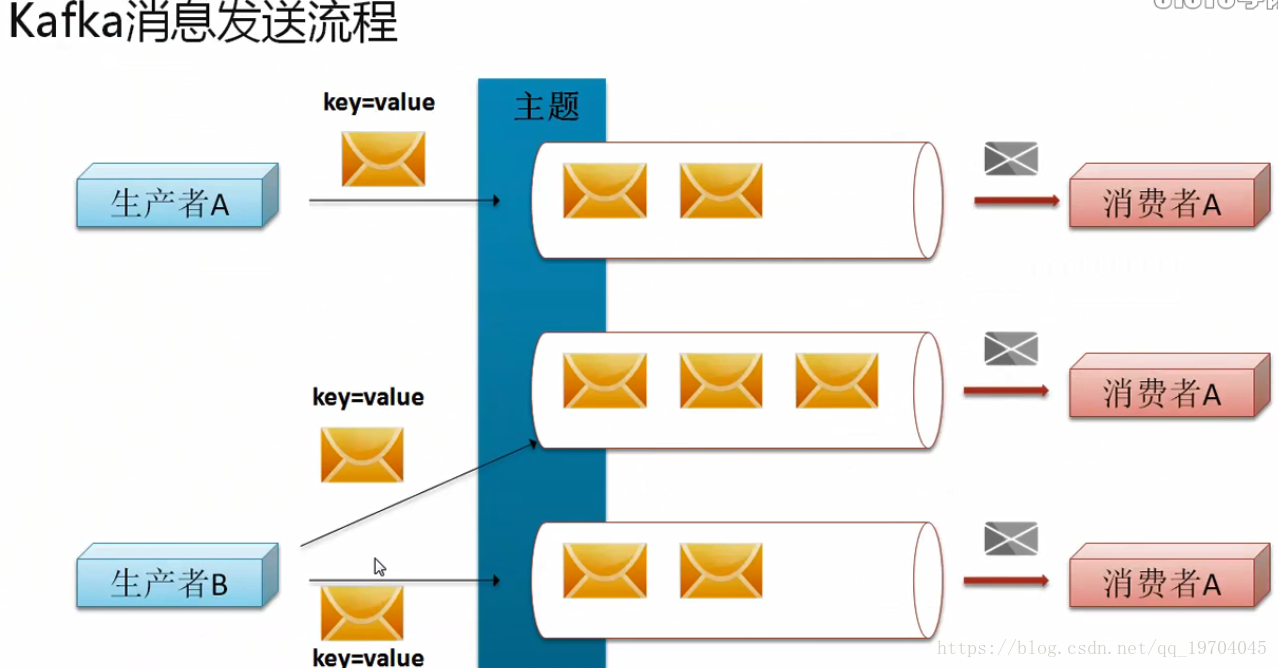
消息如何发送?
在Kafka之中消息的发送一定要依据主题进行划分,而每一个主题为了让消息处理的更快,专门设置有多个分区,就好比一件工作绝对要比三个人慢许多,同时在整个Kafka里面,最新的版本支持key-value的结构传输,这样的传输模式对于消费者而言会更加容易处理数据。在进行消费者设计的时候,你的消费者可以使用的数据数量就是你的分区数量,也就是说如果你现在设置了三个分区,那就就表示可以使用三个消费者,反之你只设置了一个分区,那么只能够有一个消费者。
Kafka消息处理流程:
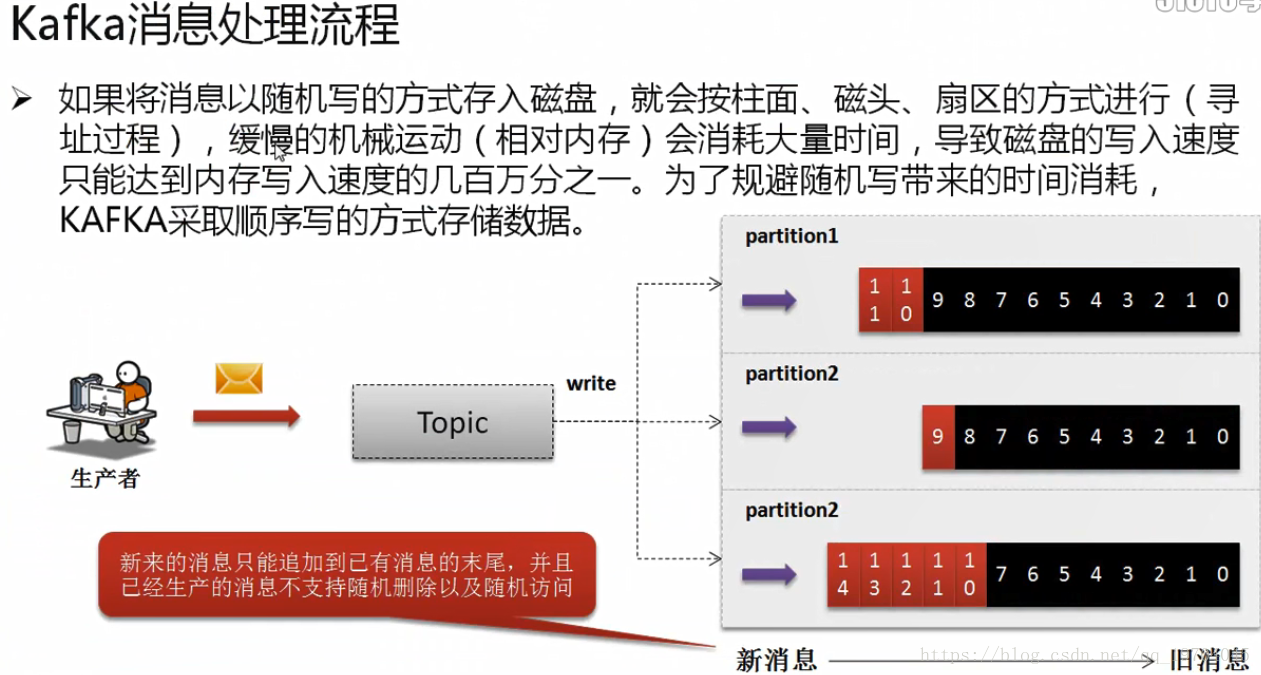
如果在进行信息写入的时候,所有磁盘中的数据保存采用随机的方式进行存储,那么在读取的时候就一定会产生性能瓶颈,因为磁盘会出现寻址变慢的情况,但是kafka采用顺序写入的方式存储数据。
新来的消息只能追加到已有消息的末尾,并且已经产生的消息不支持随机删除以及随机访问。
在整个kafka里面还有一个比较逆天的性能(也是迫切需要的),传统的JMS设计的时候存在一个缺陷:当某一个消息消费了之后,那么该消息将会被自动删除。而kafka不是,它在进行消息获取之后并不会立即删除,而是会将消息暂存2天,2天后自动删除。
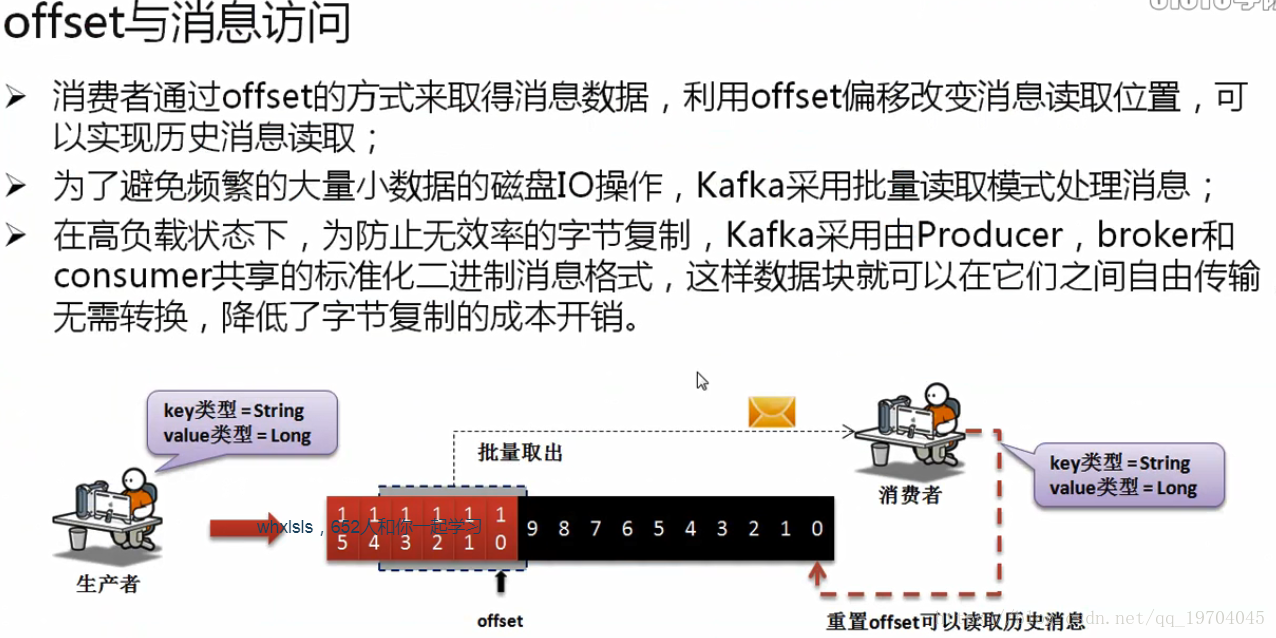
在这样的状态下为了保证kafka读取性能,单独设计了一个offset,可以理解为当前要操作的消息的下标,如果要想读取历史消息,只需要修改offset的指向即可实现。
在一些组件整合的过程中,需要考虑好offset设计,如果设计不当会造成历史消息重复读取的问题。
在磁盘之中,如果要不断进行各种细小的琐碎的操作,那么就有可能造成性能下降,所以在kafka里面专门设计有批量的数据操作,也就是说所有要消费的数据会批量读取,这样就减少了磁盘操作量,性能也会得到提升。
在很多的消息系统中,由于其可以传输的数据类型比较少,(字符串为主),所以在每一次消费的时候都需要去判断数据的类型,这样自然会造成时间复杂度的提升,那么为了解决这样的问题,Kafka约定了,你的消息的生产者一定要与消息的消费者协商好要传递的消息数据类型。

Kafka是基于JDK的实现,所以在Kafka之中 对于内存要想发挥高效,就不能纯粹的依靠JVM进行管理,所以Kafka还会使用到操作系统的内存空间,这样的好处是即使Kafka崩溃了,但是数据不在JVM里面,所以即使重新启动,数据也可以立刻重新恢复。

文件传输是整个网络操作的核心所在,毕竟消息组件之中是需要有消费者的,而所有的消费者如果想要进行消息的获取,传统的做法一定要通过CPU进行磁盘读取,而后在通过CPU进行网络传输,那么这样的处理中间会经过CPU控制,自然会造成性能的下降,
采用sendfile方式传输:
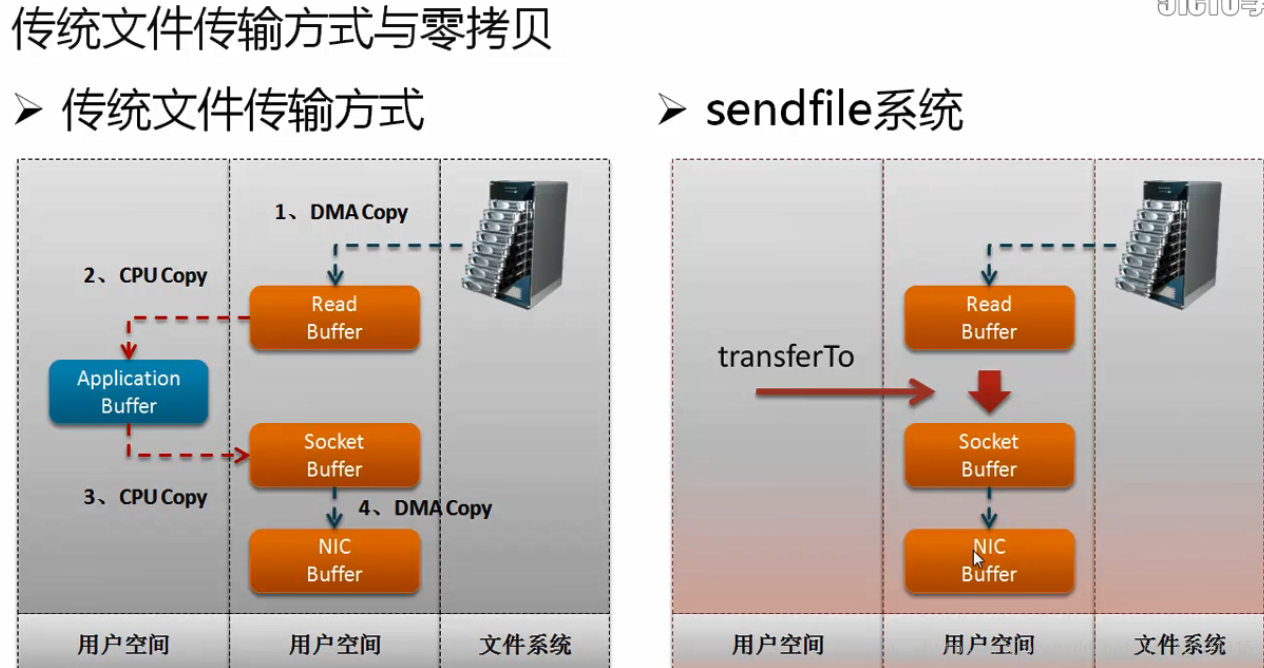
中间缺少了CPU处理环节,可以让执行性能更改。而这样的操作形式在Kafka之中称为零拷贝。
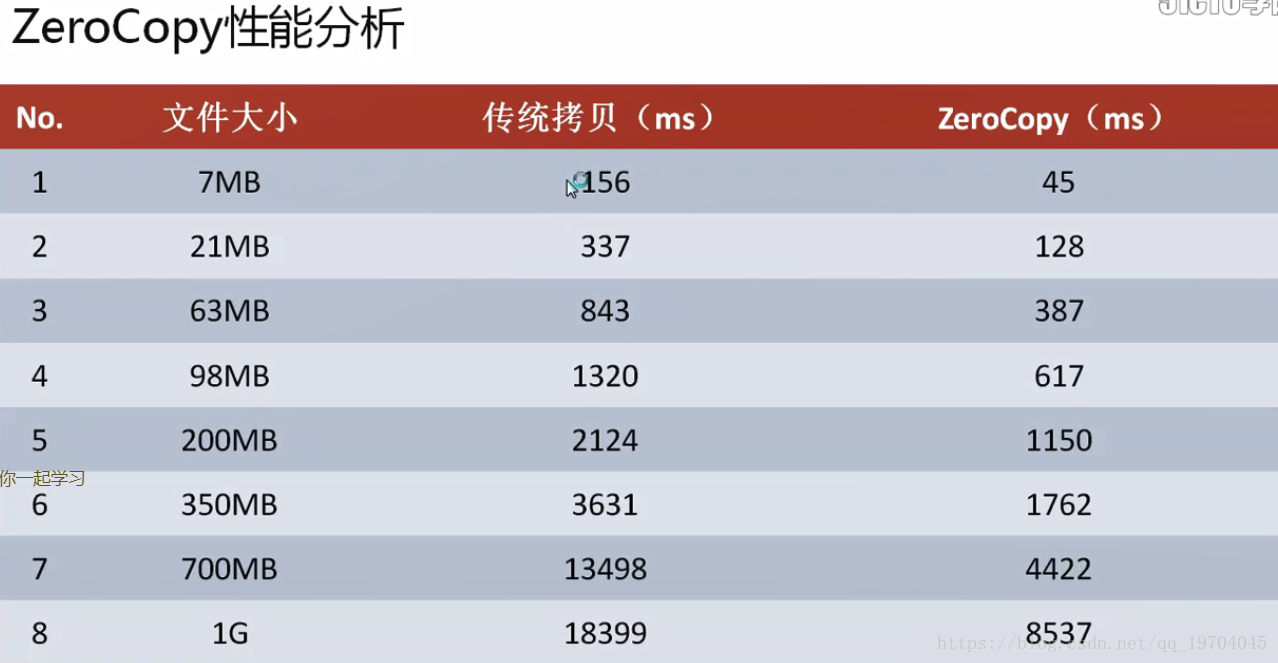
现在所有的设计都是围绕Kafka服务器本身的优化,但是关键性的因素还包括有网络传输,
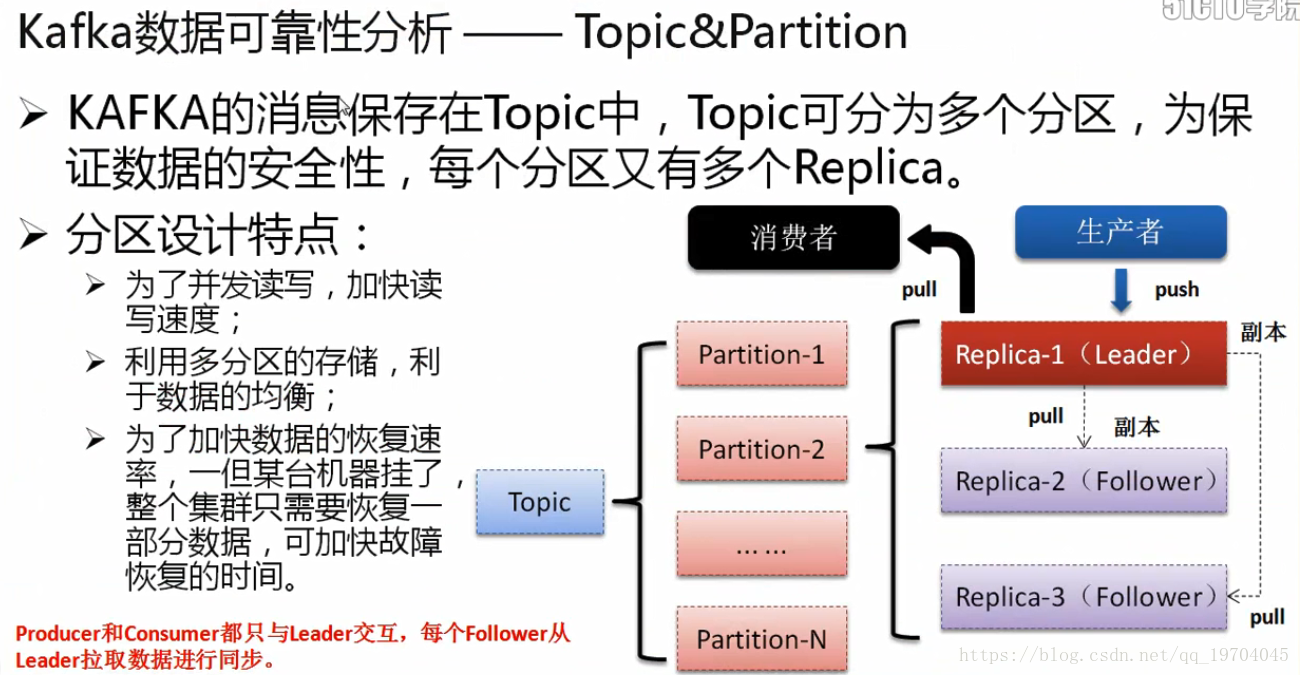
当你现在设计有多台Kafka服务器的时候,就可以进行副本的设计,如果设计了三个副本,那么这三个副本要推选出一个leader,两个follower,所有的跟随者通过leader进行数据的抓取,而所有的生产者会将数据交给leader,而我们的消费者也通过leader读取数据,这样当一个leader出现了问题之后,其它的两个fllower将自动推选出新的leader。保证数据完整性。
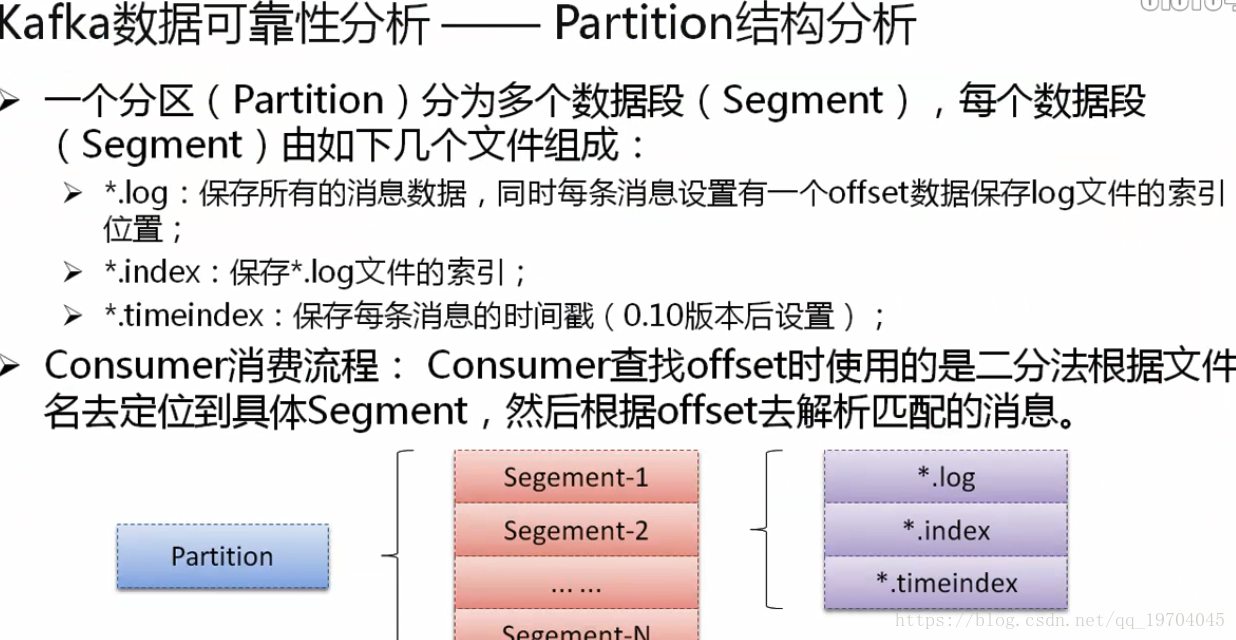
一个分区(partition)分为多个数据段(Segment),每个数据段又分为log、index、timeindex等。
消费者查找offset时使用二分法根据文件名定位到具体的Segment,然后在更具offset去解析匹配的消息。
综合来讲,可以轻松的总结出kafka所谓性能高的实现模型:
采用零拷贝技术,让数据传输更加迅速;
采用批量的数据读取,减少磁盘I/O操作,可以提升性能;
为了保证历史消息可以被继续消费,提供有一个offset指向,通过指向负责消息的读取;
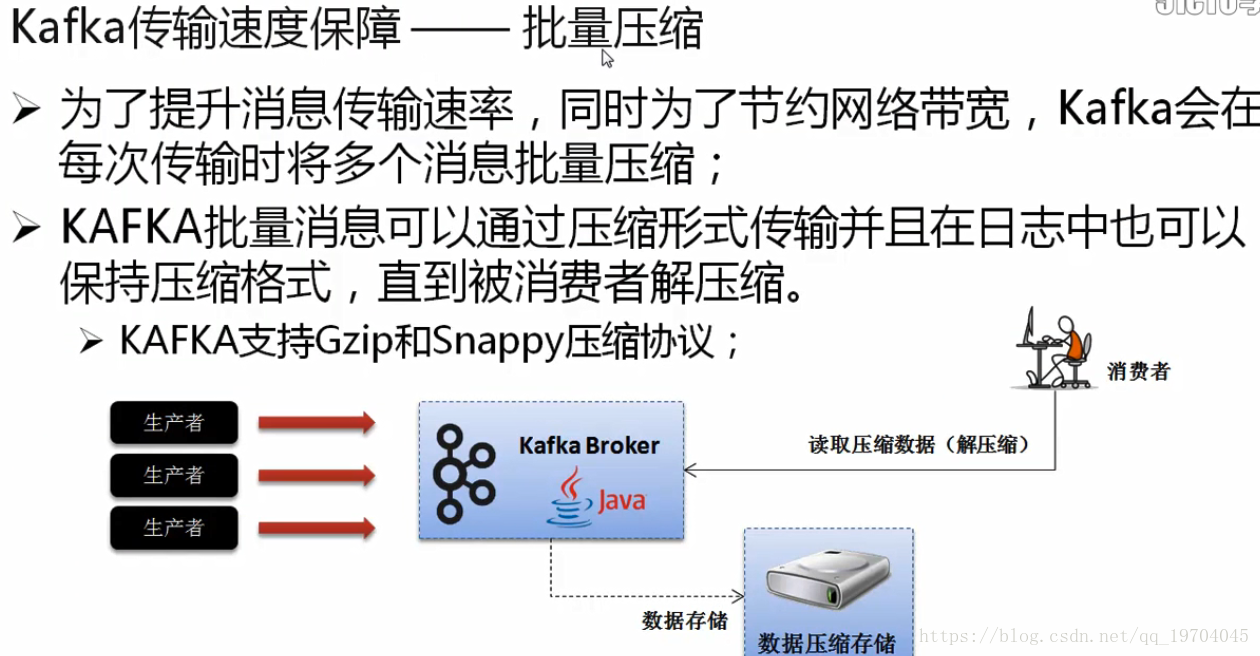
网络传输采用数据压缩的格式,所以传输更快,占用的带宽更少;
Kafka中的数据可以设置副本,这样可以保证在出现问题之后依然保证该数据的有效性(高可用性的表现)
- Kafka基础配置
本次选用的Kafka版本为:kafka_2.10-0.10.1.0.tgz,但需要知道的是Kafka是一个不断发展的技术,所以可以发现现在其版本号还不稳定,至少没有出现大的版本变化。它是不断更新的组件,可能会不断有新功能产生,也会有旧功能被淘汰。
1.将Kafka的开发包上传到Linux系统之中;
Linux系统IP地址是192.168.68.193
考虑到后期的维护方便,建议修改好系统的主机的IP地址映射:vim /etc/hosts;
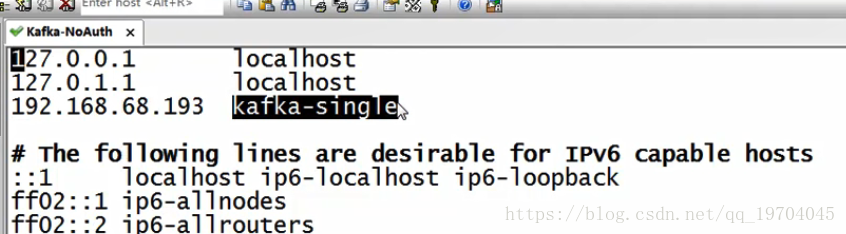
2.将kafka开发包进行解压缩:
tar xzvf /srv/ftp/kafka_2.10-0.10.1.0.tgz -C /usr/local/
3.为了方便进行管理将解压缩后的文件夹进行更名处理:
mv /usr/local/kafka_2.10-0.10.1.0/ /usr/local/kafka
4.kafka本身依赖于zookeeper,但是需要注意的是Kafka开发包中本身就提供有了ZooKeeper支持命令,但是考虑到数据保存的方便,建议建立两个文件夹
mkdir -p /usr/data/{zookeeper,kafka}
分别处理zookeeper和kafka
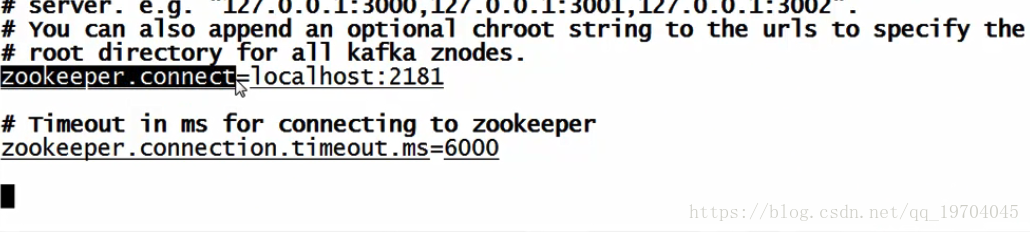
5.编辑zookeeper.properties配置文件(kafka内部的zookeeper足够使用,不要再做外接了)
vim /usr/local/kafka/config/zookeeper.properties
原来的tmp目录在linux重新启动之后会被自动清除
所以修改:
dataDir=/usr/data/zookeeper
6.随后要进行kafka配置文件的定义:
server.properties文件
vim /usr/local/kafka/config/server.properties
关键:
broker.id=0(如果要是有多台主机,这些brokerid肯定不同)
配置数据保存目录:
log.dirs=/usr/data/kafka
设置服务端口
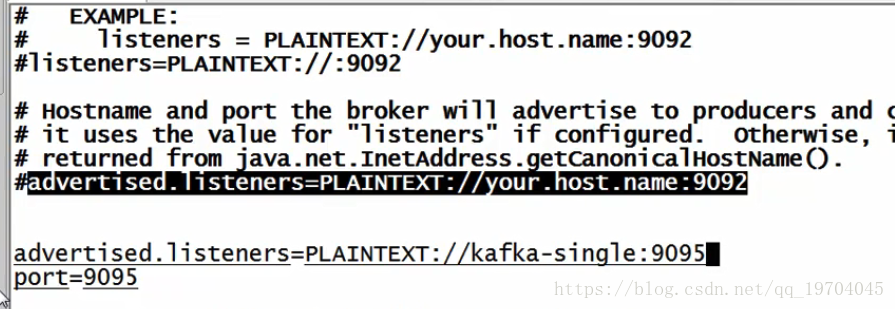
port=9095
Kafka默认的访问端口设置为9092(如果你什么都不修改,它就是9092),但是一般在实际的使用过程之中,往往会为其分配其它的开发端口,本次设置为9095(一般很少用9092,涉及到加密问题)
默认此时kafka只能被内部访问
设置外网访问IP地址(端口号相同-9095):
上述一个是内部访问listeners=plaintext://9092
如果此时设置的不是9095,那么一定访问不了(通过java程序访问不了)

7.启动kafka服务,kafka依赖于zookeeper,server.properties中有对应的设置
启动kafka内置 zookeeper服务:
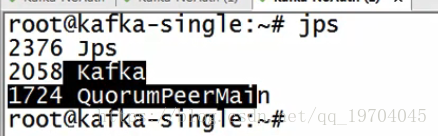
/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties
启动了zookeeper服务进程
启动kafka服务进程:
/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
8.kafka启动之后会自动在zookeeper里面进行信息的注册,但是如果你现在使用的是kafka内置的zookeeper,则这些数据要想查看比较麻烦(Kafka提供了自己的zookeeper命令-这个命令不好用)
/usr/local/kafka/bin/zookeeper-shell.sh kafka-single ls /
(列出根目录下的所有数据)

9.如果用户要想进行kafka操作,那么一定要创建若干主题(Topic)
主题的所有信息都在zookeeper中。


10.查看所有的主题信息:

11.kafka内部提供有测试环境,可以直接利用指定的命令进行消息的生产者和消费者的通讯测试
1)启动kafka的消息消费者 --独占进程
不接受历史消息: 去掉 from beginning
接受历史消息:保留 from beginning

12.启动消息的生产者–消息发送者

输入helloworld
消息的消费者可以接收到消息 -----测试成功
这个两个工具只是在本机的测试操作使用,实际使用之中没有任何意义,只是能保证当前的kafka运行正常。
智能推荐
响应式编程实现异步RPC,提升xxl-job调度吞吐量-程序员宅基地
文章浏览阅读1.1k次。在xxl-job中,RPC即用于调度中心请求执行器执行job、kill job,也用于执行器请求调度中心主动注册、执行结果上报。xxl-job实现的RPC类似Feign框架,是基于http..._xxljob 用的什么协议
C++ Json到对象的自动序列化和反序列化工作_c++ json序列化和反序列化-程序员宅基地
文章浏览阅读555次,点赞17次,收藏22次。JSERIALIZE_DEF_OBJECTLIST(Person,Object,objectList) //接受json中的objectList对象数组,对象数组使用此宏定义。JSERIALIZE_DEF_OBJECTTYPE(Person,Son,son) //接受json中的son对象,对象成员使用此宏定义。//输出反序列化结果。
DOSBOX 0.74模拟器安装Windows 95_dosbox imgmount-程序员宅基地
文章浏览阅读7.8k次,点赞2次,收藏6次。DosBox本身带有5.0版的DOS系统,启动后虚拟一个Z盘存放有Dosbox特有的外部指令,如config.com、imgmount.com等,经测试,可以顺利安装各版本的windows 3.1系统,但是不能安装win95,需要用原版的dos镜像启动才能安装。1. 获取启动盘镜像文件 下载Win95启动软盘镜像文件,名为boot.img,放到DosBox 0.74的目录下。2. 制作硬盘镜像文件_dosbox imgmount
呼叫转移的普适性及编程实现_电话自动转移程序开发-程序员宅基地
文章浏览阅读53次。总结来说,呼叫转移是一种方便的电话通信功能,在编程中可以通过使用电话服务提供商的API来实现。然而,实际的实现可能因具体的服务提供商而有所不同,你需要参考相应的文档或与服务提供商联系以获取准确的实现细节。在函数内部,我们构建了一个API请求的有效载荷(payload),其中包含了原始电话号码和目标电话号码。在编程中,呼叫转移的实现涉及使用电话通信协议和相应的编程语言。需要注意的是,实际的呼叫转移功能的实现可能因电话服务提供商的不同而有所差异。首先,我们需要确保已经安装了Python的开发环境和相应的库。_电话自动转移程序开发
FLink聚合性能优化--MiniBatch分析_flink mini-batch-程序员宅基地
文章浏览阅读5.4k次,点赞4次,收藏15次。[@ TOC]一、MiniBatch的演进思路1、MiniBatch版本Flink 1.9.0 SQL(Blink Planner) 性能优化中一项重要的改进就是升级了微批模型,即 MiniBatch(也称作MicroBatch或MiniBatch2.0),在支持高吞吐场景发挥了重要作用。MiniBatch与早期的MiniBatch1.0在微批的触发机制略有不同。原理同样是缓存一定的数据后..._flink mini-batch
EasyExcel导入_easyexcel 对接multipartfile-程序员宅基地
文章浏览阅读808次,点赞6次,收藏6次。导入依赖<dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> <version>2.1.6</version></dependency>Controllerimport java.text.ParseException;import org.springframework._easyexcel 对接multipartfile
随便推点
C++--继承基本概念、对象赋值转换、作用域_什么是赋值转换-程序员宅基地
文章浏览阅读254次,点赞5次,收藏2次。继承1. 继承的基本概念1.1 继承的定义1.2 继承基类成员访问方式的变化2. 基类和派生类对象赋值转换3. 继承中的作用域1. 继承的基本概念继承是面向对象程序设计使代码复用的最重要的手段,允许在保持原有类特性的基础上进行扩展,增加功能,产生新的类,称为派生类/子类。继承是类设计层次的复用。1.1 继承的定义派生类 : 继承方式 基类class Student : public Person1.2 继承基类成员访问方式的变化父类成员在子类中的访问权限(除过父类中的私有成员):_什么是赋值转换
模式识别(2)KNN分类_usps数据集是在哪里提出的-程序员宅基地
文章浏览阅读2.3k次,点赞10次,收藏36次。基于USPS和UCI数据集的近邻法分类一、问题描述 使用近邻算法进行分类问题的研究,并在USPS手写体数据集和UCI数据集上的iris和sonar数据上验证算法的有效性,并分别对近邻法中k近邻算法、最近邻算法和Fisher线性判别进行对比分析。二、数据集说明2.1 USPS手写体 USPS,美国邮政署,是美国联邦政府的独立机构,其中的手_usps数据集是在哪里提出的
Access根据出生日期计算年龄_Excel表格中怎么用出生日期计算年龄?这些方法好用哟...-程序员宅基地
文章浏览阅读1.9k次。 平时工作中用到Excel表格的几率特别大,也积累了一些小技巧,今天就给大家分享一下计算年龄的方法。 在Excel表格中利用“系统时间”和“出生年月”来计算“周岁年龄”、“虚岁年龄”和“实际年龄”是非常方便的,特别是人事管理和工资的统计中遇到的可能性比较大,一起来看一下计算年龄的方法吧。 方法一 第一步,如下图所示,先把需要计算年龄的出生日期输入到表格中。 第二步,然后在B2单元格中输..._access计算年龄
【EJB】异步方法调用-程序员宅基地
文章浏览阅读641次,点赞23次,收藏18次。虽然我个人也经常自嘲,十年之后要去成为外卖专员,但实际上依靠自身的努力,是能够减少三十五岁之后的焦虑的,毕竟好的架构师并不多。架构师,是我们大部分技术人的职业目标,一名好的架构师来源于机遇(公司)、个人努力(吃得苦、肯钻研)、天分(真的热爱)的三者协作的结果,实践+机遇+努力才能助你成为优秀的架构师。如果你也想成为一名好的架构师,那或许这份Java成长笔记你需要阅读阅读,希望能够对你的职业发展有所帮助。《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》点击传送门即可获取!
如何构建知识体系_网络智能知识体系的构建方法-程序员宅基地
文章浏览阅读286次。分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请轻击http://www.captainbed.net先说一件值得思考的事情:高考的时候大家都是一样的教科书,同一个教室,同样的老师辅导,时间精力基本差不多,可是最后别人考的是清华北大或者一本,而你的实力只能考个三本,为什么?当然这里主要是智商的影响,那么其他因素呢?智商解决的问题能不能后天用其他方式来补位一下?大家平时都看过很多方法论的文章,看的时候很爽觉得非常有用,但是一两周后基本还是老样子了。其中有很大_网络智能知识体系的构建方法
超全的数组去重12种方法_数组去重方法-程序员宅基地
文章浏览阅读2.7w次,点赞33次,收藏349次。前言数组去重,可以说是一个比较常见的面试题,今天来盘点一下都有哪些方法可以实现数组去重。方法1、双重for循环这是一个最笨的方法,双重循环。var arr = [1, 2, 3,4 ,5,6, 4, 3, 8, 1] // 数组去重: // 方法1: 双重for 循环 function newArrFn (arr) { // 创建一个新的空数组 let newArr = [] for(let i = 0;i<arr.length;i+_数组去重方法