SQLite 简介-程序员宅基地
SQLite简介
常见的关系型数据库有SQLite,MySQL,SQL Server等,通常学习关系型数据库时不会使用SQLite,但是SQLite 是世界上使用最广泛的数据库引擎。SQLite 内置于所有手机和大多数计算机中,并捆绑在人们每天使用的无数其他应用程序中。SQLite 是一个由C语音开发的嵌入式库,具有小型、 快速、 自包含、 高可靠、 功能齐全等特点。
文章以3.32.2版本为例讲述SQLite的一些基本知识
SQLite常用命令和示例
在命令行中使用SQLite命令,需要先执行sqlite3命令,进入SQLite提示符。
创建或打开数据库
有两种方法可以创建或打开数据库,一个是在sqlite3命令后面加上数据库路径,另一个是使用点命令.open
sqlite3 /…/xxx.db法
通过执行这个命令进入SQLite提示符时,如果数据库文件已经存在,则直接打开对应数据库,否则不会立即在对应路径创建xxx.db文件。要等到执行了添加数据表,视图等数据库对象的命令之后。
-
示例
先执行如下命令,此时没有创建出
comms_ease.db文件
sqlite3 comms_ease.db
再执行如下命令创建一张表,在当前目录出现comms_ease.db文件
.open /…/xxx.db法
使用.open是一个点命令,使用它需要先执行sqlite3命令进入SQLite提示符。.open命令的使用方式也是在命令后面追加数据库路径,不过和sqlite3 /.../xxx.db法不同的是,执行.open命令后,数据库文件会被直接创建出来,不需要再创建数据库对象。
创建表
SQLite的创建语句为CREATE TABLE,完整的创建表语句内容丰富,除了创建普通表外,还能具备判断表是否已经存在,创建临时表等能力。常见的创建普通表的句式为。
CREATE TABLE 表名 (
列1名称 列类型 以空格隔开的一个或多个列约束,
列2名称 列类型 以空格隔开的一个或多个列约束,
...
);
默认情况下,一张表的最大列数为2000,每一行能存下的最大字节数为十亿,能满足绝大多数的需求,创建普通表的示例如下
CREATE TABLE table_comms_ease (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
value VARCHAR
);
例子中,创建了一个名为table_comms_ease的数据表,包含两列,第一列是id,类型是整形,不能为空,而且是表的主键,并可以自动生成; 第二列是value,类型为字符串
在表名已经存在的情况下,调用CREATE TABLE 表名语句会报错,要避免,可以使用CREATE TABLE IF NOT EXISTS 表名语句。如果不存在,则创建表,如果存在,则什么都不做。示例如下
CREATE TABLE IF NOT EXISTS table_comms_ease (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
value VARCHAR
);
如果希望临时存储一些数据,而且只对当前连接有效,可以试试临时表。临时表的创建语句为CREATE TEMP TABLE。临时表只对当前数据库连接有效,重新建立连接或者同时存在的其他连接都无法访问到。示例如下
CREATE TEMP TABLE temp_table_comms_ease (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
value VARCHAR
);
其它常用点命令
点命令是SQLite数据库独特的命令形式,它们通常比较简单,而且不需要以分号结尾,常见的点命令如下表所示
| 命令 | 描述 | 使用示例 |
|---|---|---|
| .backup | 备份数据库到文件 | .backup comms_ease_backup |
| .databases | 列出数据库的名称及其所依附的文件 | .databases |
| .exit | 退出SQLite提示符 |
.exit |
| .help | 帮助 | .help |
| .quit | 退出SQLite提示符 |
.quit |
| .show | 各种设置的值 | .show |
| .schema | 查看创建命令。以LIKE`的模式匹配参数,如果没有参数,则查看所有表格的创建命令 | .schema .schema table% |
| .tables | 搜索表名。以LIKE`的模式匹配参数,如果没有参数,则搜索所有表名(临时表不会出现在结果中) | .tables .tables table% |
增
向表内添加一行,即为每一列构建一个值,并填入新的一行中。添加行的命令是INSERT,添加方式有三种,一种是指定值添加;二是添加Select语句的结果;三是默认添加。
-
指定值添加就是指定部分或者所有列的值,剩下列使用默认值的方式,对于没有通过
DEFAULTE,AUTOINCREMENT等方式声明默认值的列,如果没有指定NOT NULL则填入NULL,否则报错。至少需要指定一列的值,如需全部填写默认值,可以使用默认添加方式。需要注意的是,值的顺序要和列的顺序保持一致。示例如下:INSERT INTO table_comms_ease (value) VALUES ('value of 1'); INSERT INTO table_comms_ease (value, id) VALUES ('value of 2', 2);如果需要指定填入所有列的值,也可以不把列名列举出来,将值按创建表时各个列的顺序列举出来即可。示例如下:
INSERT INTO table_comms_ease VALUES (3, 'value of 3'); -
通过添加加Select语句的结果添加一行的格式为
INSERT INTO 表名 SELECT ...通过此方法添加一行时,默认值不会被自动填充,SELECT语句查出的数据量必须和表的列数一致。假设已经存在表operator包含列key和description而且某一行的key为’.backup’,description为备份数据库到文件,给出示例如下:INSERT INTO table_comms_ease SELECT 4, description FROM operator WHERE key IS '.backup'; -
默认添加的格式为
INSERT INTO 表名 DEFAULT VALUES;为每一列都填入默认值,如果没有特别声明默认值,则填入NULL。示例如下:INSERT INTO table_comms_ease DEFAULT VALUES;
通过创建表章节的示例语句创建出数据表,再依次调用上述示例语句,则数据表内会出现5行数据,如下
| id | value |
|---|---|
| 1 | value of 1 |
| 2 | value of 2 |
| 3 | value of 3 |
| 4 | 备份数据库到文件 |
| 5 |
删
删除表内的一行,命令是DELETE,常用格式为
DELETE FROM 表名 WHERE 过滤语句
删除命令本身比较简单,指定表名和删除条件即可删除一列,如下示例表示如果value列中的值有value of开头,则删除。
DELETE FROM table_comms_ease WHERE value LIKE 'value of %';
如上命令操作后,table_comms_ease表还剩的数据为
| id | value |
|---|---|
| 4 | 备份数据库到文件 |
| 5 |
改
修改表内数据的命令为UPDATE,其常用格式为
UPDATE 表名 SET 一个或多个列的赋值 WHERE 过滤语句
修改多列内容时可以采用先写出列名,再按顺序赋值的方式,也可以采用一列一列修改的方式。如果要更新id为4的所在行的值,设置id为123,value为new value,两种修改方式分别如下
UPDATE table_comms_ease SET (id, value)= (123, 'new value') WHERE id = 4;
或者
UPDATE table_comms_ease SET id=123, value='new value' WHERE id = 4;
修改后,table_comms_ease表中的数据为
| id | value |
|---|---|
| 5 | |
| 123 | new value |
修改单列的方法和修改多列的方法相似,比如将id为5这一行的value也修改为new value,可以如下操作
UPDATE table_comms_ease SET (value)=('new value') WHERE id = 5;
或者
UPDATE table_comms_ease SET value='new value' WHERE id = 5;
修改后,table_comms_ease表中的数据为
| id | value |
|---|---|
| 5 | new value |
| 123 | new value |
查
查询语句的命令是SELECT,它不会修改数据库,结果的行数在自然数范围内,每一行代表一个查询结果。SELECT命令的常用格式为
SELECT 去重策略 列名列表 FROM 表名或者子查询语句 WHERE 过滤语句 ORDER BY 排序策略 LIMIT 数量限制
查询语句中可用的配置比较多,但是大都不是必须的。查询table_comms_ease表的所有内容只需要如下命令即可
SELECT * FROM table_comms_ease;
上面命令中的*表示所有列,命令相当于
SELECT id,value FROM table_comms_ease;
结果为
| id | value |
|---|---|
| 5 | new value |
| 123 | new value |
另外,可以通过VALUES语句构建一个查询结果,结果的列名为column1, column2, column3等等。比如
VALUES (1,2,3),('a','b','c');
的结果为
| column1 | column2 | Column3 |
|---|---|---|
| 1 | 2 | 3 |
| a | b | c |
去重策略
去重策略有两种,一种是默认策略ALL,代表不去重;另一种是DISTINCT,代表去重。table_comms_ease表中value列的值相同,使用ALL和DISTINCT分别查询value列时,命令和结果如下:
ALL命令
SELECT ALL * FROM table_comms_ease;
结果为
| value |
|---|
| new value |
| new value |
DISTINCT命令
SELECT DISTINCT value FROM table_comms_ease;
结果为
| value |
|---|
| new value |
可以看出在有重复结果时,ALL策略会保留所有结果,而DISTINCT策略只保留其中一个
表名或者子查询语句
查询语句的FROM关键字后面可以跟表名或者子查询语句,用于限制查询范围。当填写表名时,可以填写多个表名,用逗号或者连接运算符分隔。当填写查询语句时,可以视为先查询出一张表,再从此表中查询出数据。
假设还有一张表table_comms_ease_1,列信息和table_comms_ease表相同,值为
| id | value |
|---|---|
| 1 | value of 1 in table_comms_ease_1 |
| 2 | value of 2 in table_comms_ease_1 |
则此字段填写table_comms_ease,table_comms_ease_1时得到如下命令
SELECT * FROM table_comms_ease, table_comms_ease_1;
结果为
| table_comms_ease.id | table_comms_ease.value | table_comms_ease_1.id | table_comms_ease_id.value |
|---|---|---|---|
| 5 | new value | 1 | value of 1 in table_comms_ease_1 |
| 5 | new value | 2 | value of 2 in table_comms_ease_1 |
| 123 | new value | 1 | value of 1 in table_comms_ease_1 |
| 123 | new value | 2 | value of 2 in table_comms_ease_1 |
当此字段填写两个子查询语句,如一个是id为5,另一个是id为123时,则得到如下命令
SELECT * FROM (SELECT * FROM table_comms_ease WHERE iD=5), (SELECT * FROM table_comms_ease WHERE iD=123);
结果为
| table_comms_ease.id | table_comms_ease.value | table_comms_ease.id | table_comms_ease.value |
|---|---|---|---|
| 5 | new value | 123 | new value |
将子查询语句的结果视为一张表,则可以统一对两种填写格式的理解。另外查询命令也支持混合填写表名和查询语句。
排序条件
排序条件决定了结果的排列顺序,常用格式如下
ORDER BY 列名 COLLATE 比较方式 排序方式 NULL值的排序方式
比较方式有三种,分别为BINARY, NOCASE和 RTRIM
- BINARY:使用标准C库中的memcmp()函数逐字节比较
- NOCASE:先把ASC II码中的大写字母转为小写字母,再按照BINARY方式比较
- RTRIM:去掉末尾空格后按照BINARY方式比较
通过下面命令为表table_comms_ease添加几条数据,
INSERT INTO table_comms_ease VALUES (6, 'A'), (7, 'new value '), (8, 'Z');
则表中的数据变为
| id | value |
|---|---|
| 5 | new value |
| 6 | A |
| 7 | new value |
| 8 | Z |
| 123 | new value |
注意:id为7的一行对应的value的末尾有一个空格
如下示例展示了三种不同比较方式的区别
BINARY命令
SELECT * FROM table_comms_ease ORDER BY table_comms_ease.value COLLATE BINARY;
结果:
| id | value |
|---|---|
| 6 | A |
| 8 | Z |
| 5 | new value |
| 123 | new value |
| 7 | new value |
NOCASE命令
SELECT * FROM table_comms_ease ORDER BY table_comms_ease.value COLLATE NOCASE;
结果:
| id | value |
|---|---|
| 6 | A |
| 5 | new value |
| 123 | new value |
| 7 | new value |
| 8 | Z |
RTRIM命令
SELECT * FROM table_comms_ease ORDER BY table_comms_ease.value COLLATE RTRIM;
结果:
| id | value |
|---|---|
| 6 | A |
| 8 | Z |
| 5 | new value |
| 7 | new value |
| 123 | new value |
数量限制
数量限制语句可以限制查询结果的行数,常用格式如下
LIMIT 数量 OFFET 偏移量
设数量为n,偏移量为o,则上面格式的意义是从第o+1条开始,取最多n条数据,如果没有符合条件的数据,则结果为空。
限制数量为3,得到如下表达式
SELECT * FROM table_comms_ease LIMIT 3;
结果为
| id | value |
|---|---|
| 5 | new value |
| 6 | A |
| 7 | new value |
由于表的总行数是5,所以如果限制数量≥5,则会查出整张表。
如果限制数量为3,同时指定偏移量为1,得到如下表达式
SELECT * FROM table_comms_ease LIMIT 3 OFFSET 1;
结果过滤掉第一条数据(5, newvalue),并向后取3条,得到
| id | value |
|---|---|
| 6 | A |
| 7 | new value |
| 8 | Z |
如果限制数量为3,同时指定偏移量为3,得到如下表达式
SELECT * FROM table_comms_ease LIMIT 3 OFFSET 3;
结果过滤掉前三条数据,并向后取3条,但是后面只有2条,所以得到
| id | value |
|---|---|
| 8 | Z |
| 123 | new value |
如果偏移量≥5,则什么都查不到
SQLite常见限制
| 类别 | 限制 | 备注 |
|---|---|---|
| 字符串长度 | 1亿 | 由宏SQLITE_MAX_LENGTH定义,可以提高或降低限制,最大到231-1 |
| 单行最大字节数 | 1亿 | 由宏SQLITE_MAX_LENGTH定义 |
| 最大列数 | 2000 | 由宏SQLITE_MAX_COLUMN定义,可以提高或降低限制,最大到32767 |
| 语句最大长度 | 10亿 | 由宏SQLITE_MAX_SQL_LENGTH定义,可以降低限制 |
| 连接中最大表数 | 64 | 不可改变 |
| 表达式树的最大深度 | 1000 | 由宏SQLITE_MAX_EXPR_DEPTH定义,可以降低或消除限制 |
| 函数的最大参数数 | 100 | 由宏SQLITE_MAX_FUNCTION_ARG定义,可以提高,最大到 127 |
| 复合 SELECT 语句中的SELECT数 | 500 | 由宏SQLITE_MAX_COMPOUND_SELECT定义,可以降低 |
| 库文件最大页数 | 1073741823 | 由宏SQLITE_MAX_PAGE_COUNT定义,可以提高或降低限制,最大到4294967294。 |
| 最大数据库大小 | 281TB | 结合最大页数4294967294和最大页面大小65536,得到最大数据库大小为281TB,但是这是个理论值,未经官方验证过。 |
| 表中的最大行数 | 2^64 | 无法达到,会先达到281TB的数据库大小限制 |
数据库中的B树
B树与B+树简介
B树是一种平衡多路查找树,每个结点包含三个部分:键,值,指向子结点的指针。假设一个B树结点中有n个键,则它同时有n个值。如果这是一个叶子结点,则它没有指向子结点的指针,否则有n+1个指向子结点的指针。下图为n==2时的结点情况。
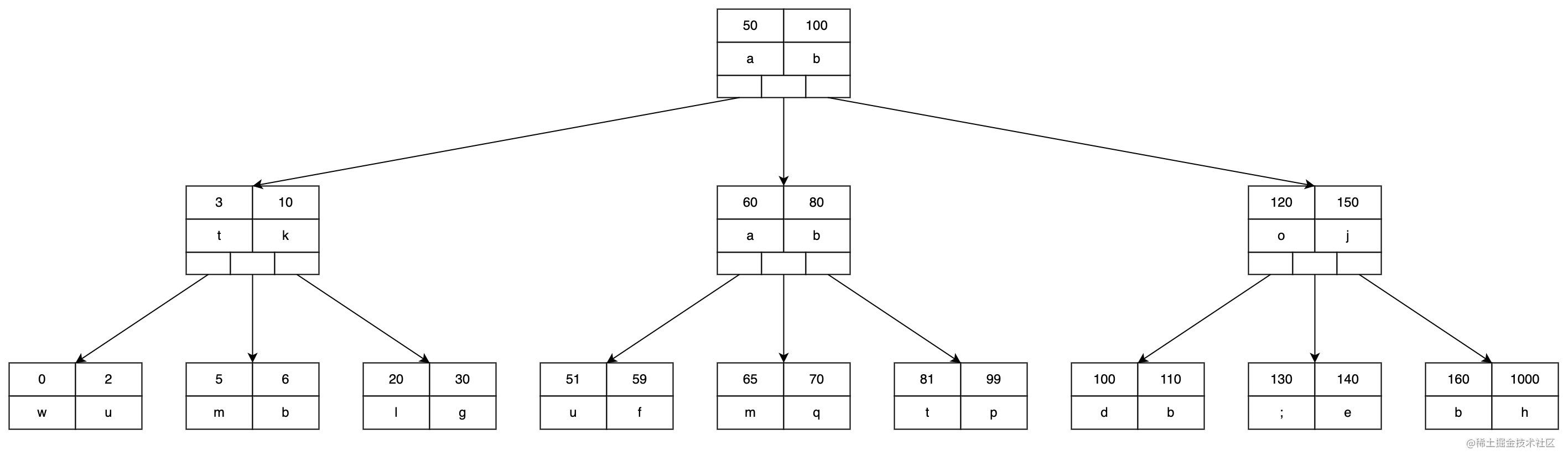
图中键1和键2两个值需要满足键1<键2。 值1和值2分别与键1和键2对应;三个指向子结点的指针,分别指向具有不同范围的键的子结点。子结点1中的键都小于键1;子结点2中的键都大于键1,且小于键2;子结点3中的键都大于键2。如下图提供了一个3路B树的示例。
上图中每个结点有三排,第一排是键;第二排是值;第三排是指向子结点的指针。根节点有50和100两个键,因此它的左子树中结点的键都小于50;中子树中结点的键都大于50且小于100;右子树中结点的键都大于100。
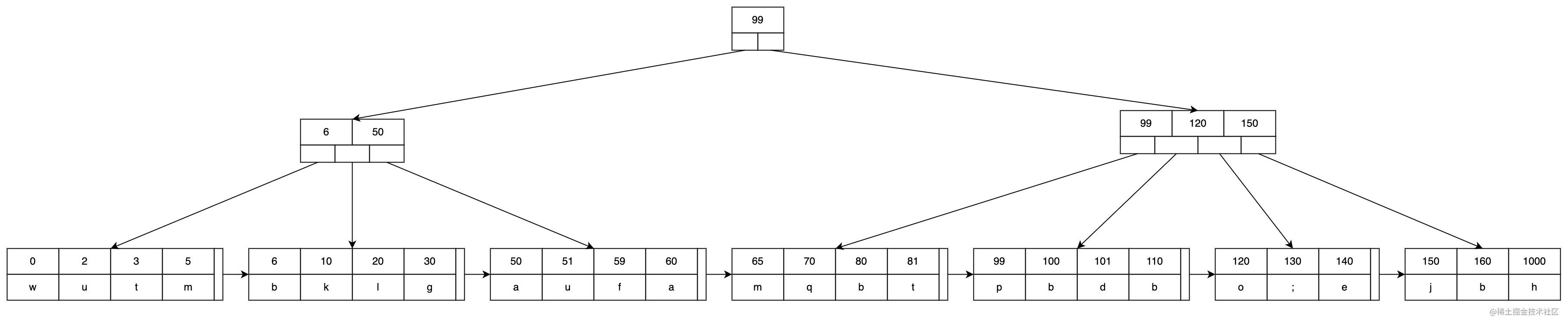
B+树和B树类似,但是B+树的内部结点中只有键和指向子结点的指针,而叶子结点具有键、值和指向下一组值的指针,即只在叶子结点上存储数据。因此父结点中的键还会再出现在子结点上。而且B+树的叶子结点的指向下一组值的指针,将所有值都串成了一个链表。由于内部结点不需要存储值,B+树可以存储更多的键。下图用5路B+树存储了上面3路B树的内容。
B树页
数据库文件由一页或多页组成。同一个数据库中,每页的大小相同,都是 在512 和 65536 之间,并且为2的整数次幂。数据库的页分为锁定字节(lock-byte)页、freelist页、B树页、负载溢出页和指针映射页。
B树算法为SQLite提供了键值存储模式,而且保证了键的有序性和唯一性。SQLite数据库中B树的结点就是一个页面,所以指向的子结点的指针实际上是对应页面的页码。SQLite数据库使用了两种B树变体,在叶子节点存储数据的表B树和不存储数据的索引B树。一颗完整的树只能是完全的表B树或者完全的索引B树。
表B树和索引B树
表B树类似B+树,只将值存放在叶子结点中;索引B树是一颗没有值的树,键就是数据本身,因此索引B树其实类似于B树。下表列出了它们之间的一些差异。
| 对比项 | 表B树 | 索引B树 |
|---|---|---|
| 键长度(byte) | 8 | 最长2147483647的随机值 |
| 值存放点 | 叶子结点 | 没有值,键就是数据 |
| 值长度 | 最长2147483647 | 没有值,键就是数据 |
| 叶子结点结构 | 键 | 键和值 |
| 主要使用场景 | rowid表 | 索引、WITHOUT_ROWID表 |
智能推荐
飞机大战项目源码_text文本飞机大战源码-程序员宅基地
文章浏览阅读410次。back.h#pragma once#include "Sys.h"class CBack{public: CBack(void); ~CBack(void);public: HBITMAP m_hBmpBackDown;// 图片 HBITMAP m_hBmpBackUp; int x; int y;public: void InitBack(HINSTANCE hIns); // 初始化背景 void ShowBack(HDC hMemDC); // 显_text文本飞机大战源码
CTF加密题型解析:RSA算法的CTF解法之一-程序员宅基地
文章浏览阅读410次。RSA介绍根据加密原理,可以将大部分的加密算法分为两大类:对称加密算法和非对称加密算法。对称加密算法的加密和解密采用的是同一套算法规则。而非对称加密算法加密时用的是公钥(公开给所有人),解密时用的是私钥(只有相关人员拥有),非对称加密算法中使用最广泛的就是RSA算法。RSA算法非常可靠,密钥越长,就越难破解。当今互联网中已经纰漏的破解方法是针对768位密钥。所以一般认为1024位的密钥加密..._p = 3487583947589437589237958723892346254777 q = 876786784356893476598347658
PCL学习:点云分割-圆柱体模型分割_sacsegmentationfromnormals-程序员宅基地
文章浏览阅读4.2k次,点赞6次,收藏27次。pcl::SACSegmentationFromNormals< PointT, PointNT >类 SACSegmentationFromNormals< PointT, PointNT >是利用采样一致性方法进行点云分割的类,与其父类 SACSegmentation 不同之处在于其在算法实现时采用了法线信息,即该类在进行运算输出之前需要设定法线信息 ,其继承关系如图所示..._sacsegmentationfromnormals
解决Ubuntu下nvcc版本与CUDA版本不对应问题_linux安装了cuda,但是nvcc -v没有这个命令apt install nvidia-cud-程序员宅基地
文章浏览阅读9.5k次。最近在linux上安装了CUDA 8.0,但是在安装pycuda时却提示找不到nvcc命令。在terminal中输入nvcc,也是提示找不到command。但是可以确定的是,CUDA8.0,以及nvidia-cuda-toolkit已经从官方网站下载并正确安装。于是网上找了教程,说是需要在terminal中输入sudo apt-get install nvidia-cuda-toolkit安装..._linux安装了cuda,但是nvcc -v没有这个命令apt install nvidia-cuda-toolkit
win7和linux mint双系统安装总结_linux mint和win7双系统-程序员宅基地
文章浏览阅读2.9k次。先安装好win7,之后再安装好linux mint,安装好之后,再使用U盘的winPE,进行一下引导操作就可以了_linux mint和win7双系统
暑假总结_网络中心暑假总结-程序员宅基地
文章浏览阅读622次。暑假总结学到的新知识对几次考试的总结对这次暑假补课的看法学到的新知识对几次考试的总结对这次暑假补课的看法_网络中心暑假总结
随便推点
HBase--Snapshot(快照)的使用_hbase snapshot-程序员宅基地
文章浏览阅读2.5k次。基于Hbase snapshot数据快速备份方法及常用命令_hbase snapshot
SparkSQL_"spark.sql(\"update usr_info set 'age_range'=-1 wh-程序员宅基地
文章浏览阅读733次。1. 预览2. 开始入门2.1 起始点: SparkSession2.2 创建数据框2.3 DataFrame相关操作2.4 运行SQL查询2.5 全局临时视图2.6 创建Datasets(Java and Scala) pass2.7 将RDD转化为DataFrame的两种方式2.8 Aggregations(Java and Scala) pass3. 数据源3..._"spark.sql(\"update usr_info set 'age_range'=-1 where 'age_range' is null;\")"
Flutter GridView网格布局_flutter布局grid-程序员宅基地
文章浏览阅读3.1k次,点赞2次,收藏3次。目录参数详解代码示例特别说明效果图完整代码在这里介绍两种实现网格布局方法:1、通过 GridView.count 实现网格布局2、通过 GridView.builder 实现网格布局参数详解属性 说明 scrollDirection 滚动方向 reverse 组件反向排序 controller 滚动控制(滚动监听) pri..._flutter布局grid
stm32 UART接收方式_stm32串口 判断 接收 接收 数组-程序员宅基地
文章浏览阅读1.3k次。1. 直接接收在主函数 main 中操作/** * @brief The application entry point. * @retval int */int main(void){ /* USER CODE BEGIN 1 */ unsigned char uRx_Data = 0; /* USER CODE END 1 */ /* MCU Configuration----------------------------------------.._stm32串口 判断 接收 接收 数组
【Spring MVC】Spring MVC启动过程源码分析_springmvc启动过程-程序员宅基地
文章浏览阅读4k次,点赞3次,收藏19次。Spring MVC启动时,Spring容器和Spring MVC组件的启动过程源码分析_springmvc启动过程
python如何删除代码_科学网—我的第一个Python程序——删除代码前行号的小工具 - 闫小勇的博文...-程序员宅基地
文章浏览阅读892次。(根据我在博客园上连载的四篇文章整理,见http://yanxy.cnblogs.com,转载请注明出处)近两天内的目标是在我博的每个栏目发一篇文章,先都占个坑再说,空着不好看:) 《程序设计》这个栏目里,就从我刚开始学的Python开始吧。一、引言Python是一种简单却又强大的语言,我觉得它很适合非专业程序员(特别是科研人员)使用。比如作一些科学计算、数据处理工作等,Python简单的语法和丰..._python怎么删除前面的代码